1. 인공지능 실습을 위한 필수 라이브러리: NumPy, Pandas, Matplotlib
인공지능 모델을 구축하고 훈련하기 위해서는 데이터를 처리하고, 분석하며, 시각화하는 과정이 매우 중요하다.
이를 위해 파이썬에서는 여러 강력한 라이브러리를 제공한다.
그 중 NumPy, Pandas, Matplotlib는 필수적인 도구로 사용된다.
각 라이브러리는 인공지능 실습을 시작하기 전에 기본적으로 익혀야 할 중요한 기능들을 제공한다.
NumPy는 다차원 배열과 고성능 수치 연산을 처리하기 위해 사용된다.
수학적 계산이 빠르고 효율적으로 이루어지며, 인공지능 모델의 기본 데이터를 다루는 데 핵심적이다.Pandas는 데이터 프레임을 통해 복잡한 데이터를 간단하게 관리하고 분석할 수 있게 해준다.
특히, CSV 파일이나 데이터베이스에서 데이터를 불러오고 변환하는 데 필수적이다.Matplotlib는 데이터 시각화를 담당한다.
데이터를 차트나 그래프로 표현하여 분석 과정에서 중요한 인사이트를 얻는 데 도움을 준다.
2. Numpy란?
NumPy는 Numerical Python의 약자로, 파이썬에서 수치 계산을 효율적으로 수행할 수 있도록 돕는 라이브러리이다.
특히, 다차원 배열(배열 또는 행렬)을 처리하는 데 강력한 기능을 제공한다.
인공지능 모델은 대개 큰 규모의 데이터를 다루게 되므로, 이를 빠르고 효율적으로 처리하기 위해 NumPy의 기능을 활용해야 한다.
2.1 배열 생성 (array)
import numpy as np
# 1차원 배열 생성
arr1 = np.array([1, 2, 3, 4, 5])
# 2차원 배열 생성
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr1)
print(arr2)
# [1 2 3 4 5]
# [[1 2 3]
# [4 5 6]]
2.2 배열 결합
- NumPy에서는 여러 배열을 쉽게 결합할 수 있다.
concatenate: 배열을 축을 기준으로 연결한다.
vstack: 배열을 세로로 쌓는다.
hstack: 배열을 가로로 쌓는다.
# 배열 생성
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 배열 연결 (concatenate)
concatenated = np.concatenate((arr1, arr2))
# 세로로 쌓기 (vstack)
vertical = np.vstack((arr1, arr2))
# 가로로 쌓기 (hstack)
horizontal = np.hstack((arr1, arr2))
print("concatenate:", concatenated)
print("vstack:\n", vertical)
print("hstack:", horizontal)
# concatenate: [1 2 3 4 5 6]
# vstack:
# [[1 2 3]
# [4 5 6]]
# hstack: [1 2 3 4 5 6]
- 배열 결합: concatenate와 axis의 역할
NumPy에서 배열을 결합하는 함수인 concatenate는 여러 배열을 특정 축(axis)을 기준으로 이어붙인다.
axis는 결합할 차원(축)을 지정하는데, 이를 통해 배열이 어떻게 결합될지를 결정할 수 있다.각 축의 개념을 쉽게 설명하자면:
axis=0은 배열에서의 행(row)에 해당하고,
axis=1은 배열에서의 열(column)에 해당한다.Default 는 axis = 0으로 행 간의 결합이다.
import numpy as np
# 두 배열 생성
a = np.array([[1, 2], [3, 4]]) # 2x2 배열
b = np.array([[5, 6]]) # 1x2 배열
# axis=0, 행 기준으로 배열을 이어붙이기
result_axis_0 = np.concatenate((a, b), axis=0)
# b 배열을 전치(행과 열을 바꿈)하여 열 기준으로 배열을 이어붙이기 (axis=1)
result_axis_1 = np.concatenate((a, b.T), axis=1)
print("axis=0 (행 기준으로 결합):\n", result_axis_0)
print(" ")
print("axis=1 (열 기준으로 결합):\n", result_axis_1)
'''
axis=0 (행 기준으로 결합):
[[1 2]
[3 4]
[5 6]]
=> 3 x 2 배열
axis=1 (열 기준으로 결합):
[[1 2 5]
[3 4 6]]
=> 2 x 3 배열
'''
2.3 배열의 모양 변경: reshape, shape
reshape: 배열의 형태를 변경한다.
shape: 배열의 현재 모양을 확인한다.
# 1차원 배열을 2차원 배열로 변형
arr = np.array([1, 2, 3, 4, 5, 6])
reshaped = arr.reshape((2, 3))
# 배열의 차원 확인
print("원본 배열:", arr)
print("변형된 배열:\n", reshaped)
print("배열의 모양:", reshaped.shape)
'''
원본 배열: [1 2 3 4 5 6]
변형된 배열:
[[1 2 3]
[4 5 6]]
배열의 모양: (2, 3)
'''3. Pandas란?
Pandas는 파이썬에서 데이터 분석 및 조작을 쉽게 할 수 있게 도와주는 라이브러리이다. 특히
데이터 프레임(DataFrame)이라는 강력한 데이터 구조를 제공하여 표 형식의 데이터를 다루는 데 매우 유용하다.
Pandas는 CSV, 엑셀, 데이터베이스에서 데이터를 불러와 쉽게 처리하고 분석할 수 있도록 해준다.
- Pandas를 배워야 하는 이유
1) 데이터 조작: 데이터를 쉽게 필터링, 집계, 변환 가능
2) 데이터 불러오기 및 저장: CSV, 엑셀, SQL 등 다양한 포맷의 데이터를 불러오고 저장 가능
3) 결측치 처리: 결측치나 이상치를 쉽게 찾아내고 처리 가능
4) 인덱싱과 슬라이싱: 데이터 프레임의 특정 열이나 행을 쉽게 선택하여 분석 가능
3.1 pandas 실습 (타이타닉 데이터 분석)
데이터 참고 : https://www.kaggle.com/c/titanic/data
import pandas as pd
# 파일의 경로 지정에 주의하기
df = pd.read_csv('/content/drive/MyDrive/train.csv')
df # df => dataframe을 의미한다
3.2 특정 행과 열 선택: loc을 사용한 인덱싱
Pandas의 loc은 라벨 기반 인덱싱을 지원하여, 행과 열을 기준으로 데이터를 쉽게 선택할 수 있다.
기본 구조:
df.loc[행 인덱싱 값, 열 인덱싱 값]
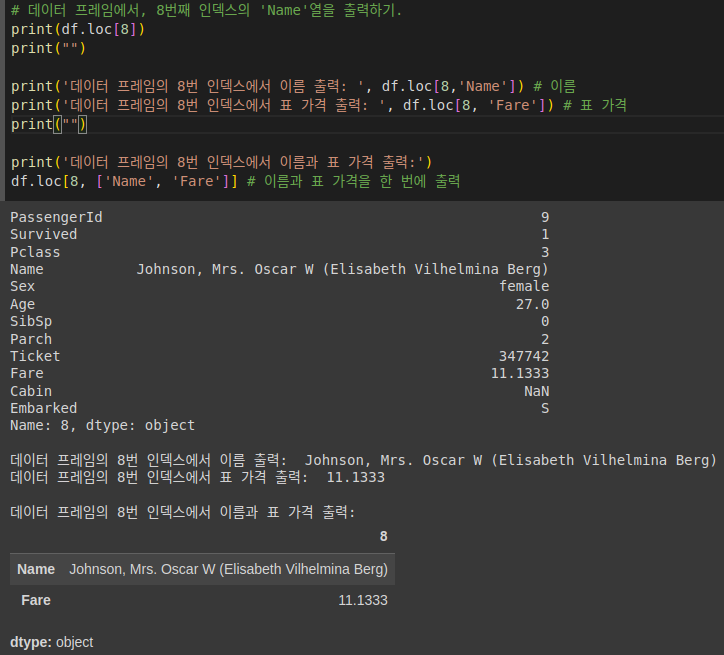
# 8번째 인덱스의 'Name' 열 값 출력
print(df.loc[8, 'Name'])
# 8번째 인덱스의 'Fare' 열 값 출력
print(df.loc[8, 'Fare'])
# 'Name'과 'Fare' 열 값을 한 번에 출력
print(df.loc[8, ['Name', 'Fare']])
3.3 여러 열을 선택하고 슬라이싱
여러 열을 선택하거나 슬라이싱을 사용하여 원하는 구간의 데이터를 선택할 수 있다.
# 모든 행에서 'Name' 열만 선택
print(df.loc[:, 'Name'])
# 처음부터 'Name' 열까지의 모든 열 선택
print(df.loc[:, :'Name'])
# 인덱스 0부터 4까지의 'Survived'와 'Age' 열 선택
print(df.loc[:4, ['Survived', 'Age']])
'''
Survived Age
0 0 22.0
1 1 38.0
2 1 26.0
3 1 35.0
4 0 35.0
'''3.4 조건부 데이터 선택
조건식을 사용하여 데이터프레임에서 특정 조건을 만족하는 행을 선택할 수 있다.
예를 들어, 3등급(Pclass가 3) 승객 중 생존자와 사망자를 필터링할 수 있다.
# 3등급 승객 중 생존자 필터링
condition = (df['Pclass'] == 3) & (df['Survived'] == 1)
print(df.loc[condition]) # 총 119명에 대한 모든 정보 출력
print(df.loc[condition].shape)
# (119, 12)를 출력하므로 119명이 출력된다는 의미이다.
# 3등급 승객 중 사망자 필터링
condition2 = (df['Pclass'] == 3) & (df['Survived'] == 0)
print(df.loc[condition2]) # 총 372명에 대한 모든 정보 출력
print(df.loc[condition2].shape)
# (372, 12)를 출력하므로 119명이 출력된다는 의미이다.
# 생존자 필터링
condition3 = (df['Survived'] == 1)
print(df.loc[condition3]) # 총 342명
3.5 iloc을 사용한 행과 열의 위치 기반 인덱싱
Pandas의 iloc은 위치 기반 인덱싱을 지원하여 숫자 인덱스로 행과 열을 선택할 수 있다.
print(df.iloc[1,3])
# 0부터 시작이므로, 2행과 4열의 정보 출력 (위의 표 참고) => 이름이 출력된다
print("")
print(df.iloc[5,9])
# 0부터 시작이므로, 6행과 10열의 정보 출력 (위의 표 참고)
print("")
print(df.iloc[4, 3:6])
# 0부터 시작이므로, 5행과 3열~ 5열의 정보 출력 (위의 표 참고) => 이름, 성별, 나이가 출력된다.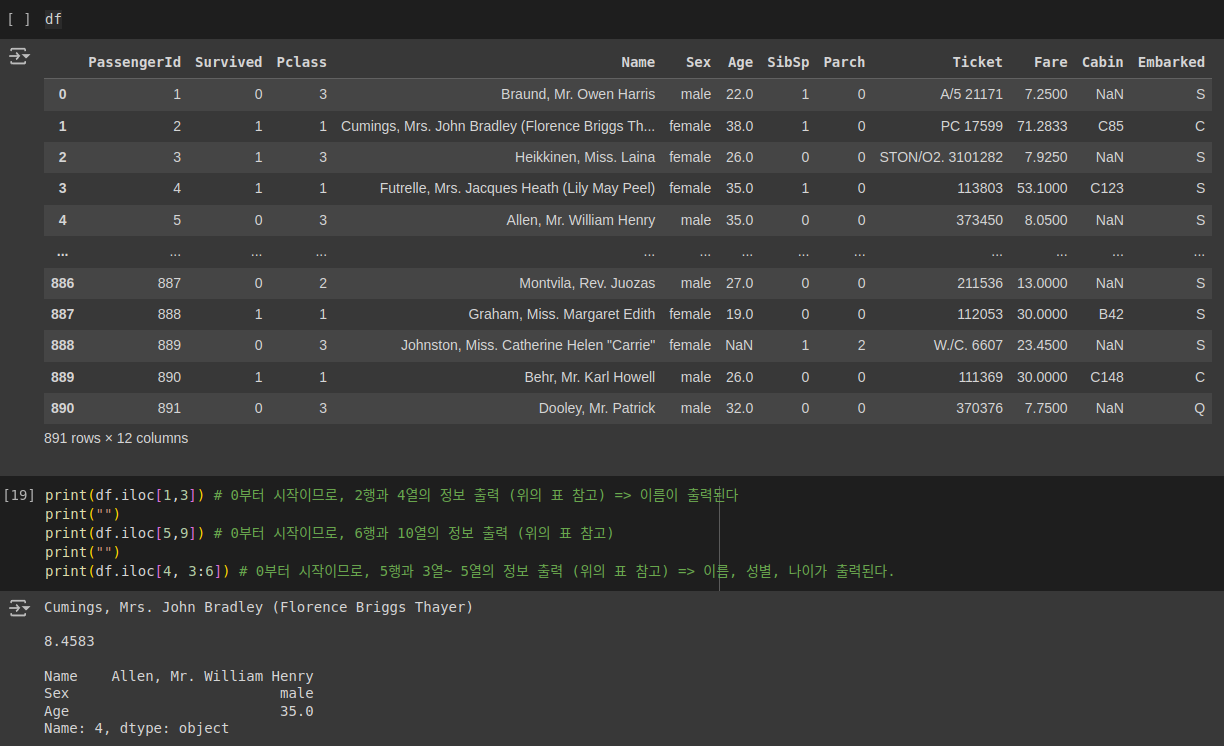
4. Seaborn과 Matplotlib을 활용한 타이타닉 데이터 분석
Seaborn과Matplotlib라이브러리를 활용해 타이타닉 데이터를 시각적으로 분석하는 과정을 실습해보기.
Seaborn은 시각적 표현을 더 간결하고 쉽게 만들어 주고, Matplotlib은 파이썬에서 데이터 시각화를 기본으로 제공하는 강력한 라이브러리이다.
4.1 데이터 준비 및 결측치 처리
먼저 타이타닉 데이터를 불러온 후, 결측치를 처리한다.
결측치는 데이터 분석에 방해가 될 수 있으므로, 평균 또는 최빈값 등으로 채워준다.
import seaborn as sns
import pandas as pd
# 타이타닉 데이터셋 불러오기
titanic = sns.load_dataset('titanic')
# 결측치 확인
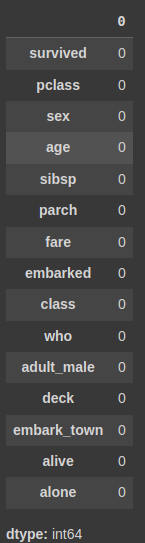
titanic.isnull().sum()-
타이타닉 데이터셋 확인
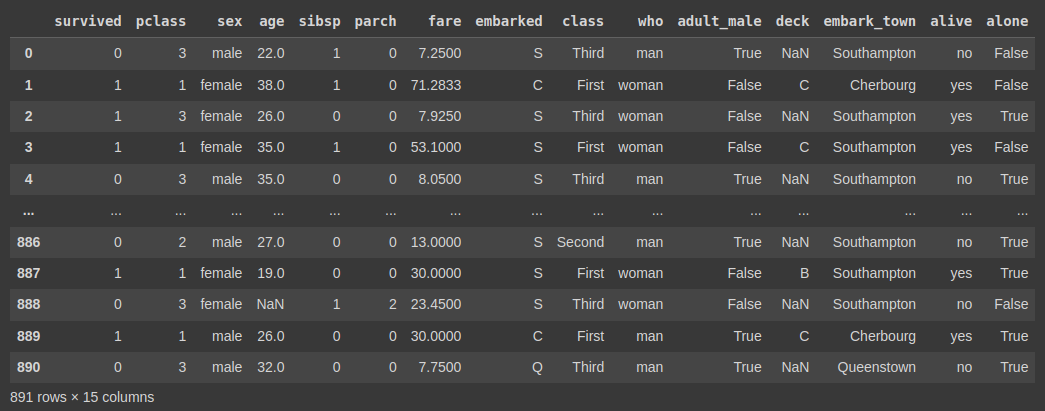
-
타이타닉 데이터넷 결측치 확인
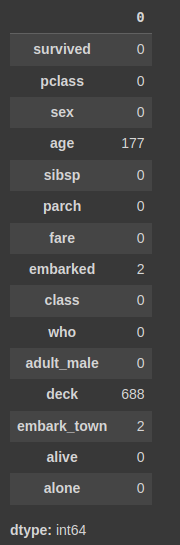
-
결측치 데이터 중 'age'를 중간값으로 채워넣기
titanic['age'] = titanic['age'].fillna(titanic['age'].median())
# null 값을 median값으로 채우기
titanic.isnull().sum()
# null이 총 177에서 0으로 줄어들었다.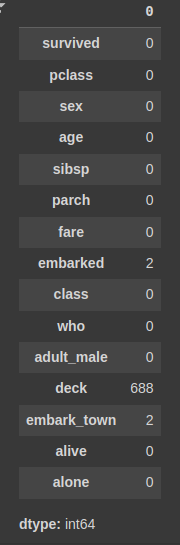
- 다른 결측치 데이터인 'embarked', 'deck', 'embark_tonw' 도 값 채워주기
각 데이터의 값을 살펴보고, 최빈값을 사용하여 결측치를 채우기
다음 결과를 살펴보면,
embarked 에서는 'S' , deck 에서는 'C', embark_town 에서는 'Southampton'이 최빈값이다.
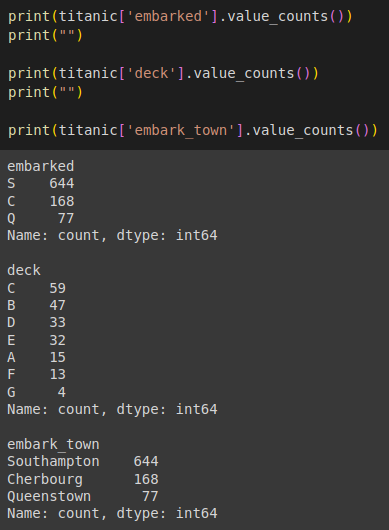
# embarked 열의 결측치를 'S'로 채우기
titanic['embarked'] = titanic['embarked'].fillna('S')
# embark_town 열의 결측치를 'Southampton'으로 채우기
titanic['embark_town'] = titanic['embark_town'].fillna('Southampton')
# deck 열의 결측치를 'C'로 채우기
titanic['deck'] = titanic['deck'].fillna('C')
# 결측치 처리 후 확인
titanic.isnull().sum()모든 결측치(NULL) 값이 사라진 걸 확인할 수 있다.
4.2 matplotlib를 사용하여 시각화하기
import matplotlib.pyplot as plt # Matplotlib을 사용하여 그래프를 그리기 위한 라이브러리
import seaborn as sns # Seaborn을 사용하여 데이터 시각화와 데이터셋 로드
# 타이타닉 데이터셋 불러오기
titanic = sns.load_dataset('titanic')
# 서브플롯(1행 2열)을 만들고, 전체 그림 크기를 가로 10인치, 세로 5인치로 설정
f, ax = plt.subplots(1, 2, figsize=(10, 5))
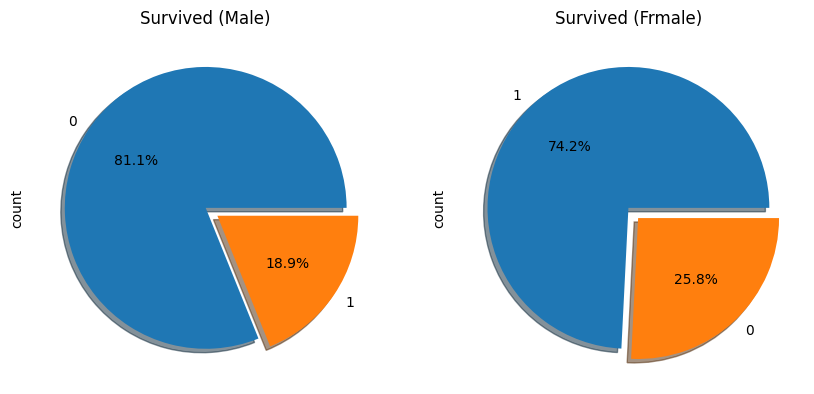
# 남성의 생존 여부 빈도를 구하고, 파이 차트를 그려 첫 번째 서브플롯(ax[0])에 추가
titanic['survived'][titanic['sex'] == 'male'].value_counts().plot.pie(
explode=[0, 0.1], # 두 번째 파이 조각을 0.1만큼 분리하여 강조
autopct='%1.1f%%', # 파이 조각에 비율을 소수점 첫째 자리까지 표시
ax=ax[0], # 첫 번째 서브플롯에 그래프를 그림
shadow=True # 파이 차트에 그림자를 추가하여 입체감 부여
)
# 여성의 생존 여부 빈도를 구하고, 파이 차트를 그려 두 번째 서브플롯(ax[1])에 추가
titanic['survived'][titanic['sex'] == 'female'].value_counts().plot.pie(
explode=[0, 0.1], # 두 번째 파이 조각을 0.1만큼 분리하여 강조
autopct='%1.1f%%', # 파이 조각에 비율을 소수점 첫째 자리까지 표시
ax=ax[1], # 두 번째 서브플롯에 그래프를 그림
shadow=True # 파이 차트에 그림자를 추가하여 입체감 부여
)
# 첫 번째 서브플롯에 'Survived (Male)'이라는 제목 설정
ax[0].set_title('Survived (Male)')
# 두 번째 서브플롯에 'Survived (Female)'이라는 제목 설정
ax[1].set_title('Survived (Female)')
# 그래프를 화면에 출력
plt.show()
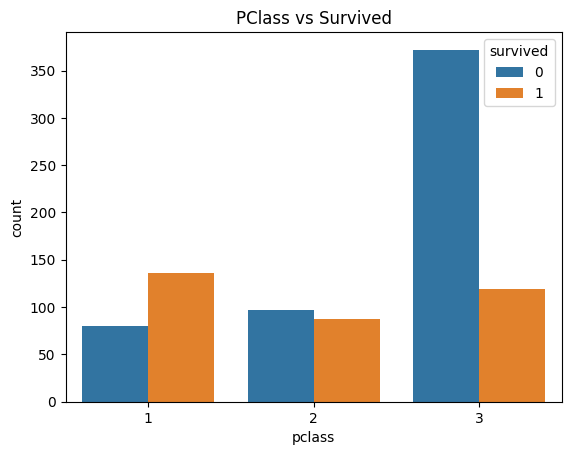
# 등급별 생존자 수를 차트로 나타내기
sns.countplot(x = 'pclass', hue = 'survived', data = titanic)
plt.title('PClass vs Survived')
plt.show()