지금까지 인공지능 개요, NumPy와 Pandas를 활용한 데이터 처리, 그리고 Matplotlib을 통해 데이터 시각화를 공부했다.
참고 : 인공지능 개요
참고 : 인공지능 개요 파이썬 실습
이번에는 인공지능(AI)에서 가장 기초적이면서도 중요한 알고리즘 중 하나인 선형 회귀(Linear Regression)에 대해 공부하기.
선형 회귀(Linear Regression)을 공부해야하는 이유
선형 회귀는 머신러닝과 인공지능에서 데이터와 예측 모델을 이해하는 첫걸음이다.
데이터를 분석하고 미래 값을 예측하기 위한 가장 기본적인 모델이기 때문에, 복잡한 알고리즘을 배우기 전에 반드시 익혀야 할 개념이다.
이번 포스팅에서는 다음의 내용을 순차적으로 공부하도록 한다.
선형 회귀의 기본 개념
- 최소 제곱법(Least Squares Method)을 사용해 최적의 회귀선을 찾는 방법
- 평균 제곱 오차(MSE)를 통해 모델의 성능을 평가하는 방법
- 경사 하강법(Gradient Descent)을 통해 모델을 최적화하는 과정
이 흐름은 인공지능의 기본적인 알고리즘을 이해하는 데 필수적인 요소들이며, 복잡한 모델을 다루기 전에 필수적으로 학습해야 한다.
1. 선형 회귀(Linear Regression)
선형 회귀는 데이터를 기반으로 독립 변수와 종속 변수 사이의 선형 관계를 찾는 방법이다.
선형 회귀는 데이터 사이의 관계를 파악하는 데 매우 유용하다.
이를 통해, 주어진 데이터를 기반으로 미래 값을 예측할 수 있다.
선형 회귀는 다른 머신러닝 알고리즘, 특히 로지스틱 회귀나 서포트 벡터 머신(SVM)과 같은 모델의 기초가 되는 알고리즘이다.
2. 최소 제곱법(Least Squares Method)
선형 회귀에서 최적의 직선을 찾는 방법이 바로
최소 제곱법이다.
데이터 포인트와 회귀선 사이의 오차(잔차)의 제곱 합을 최소화하는 방향으로 직선을 그리는 방법이다.
최소 제곱법을 통해 모델의 가중치(기울기와 절편)를 계산할 수 있으며, 이는 모델의 정확도를 결정짓는 중요한 요소이다.
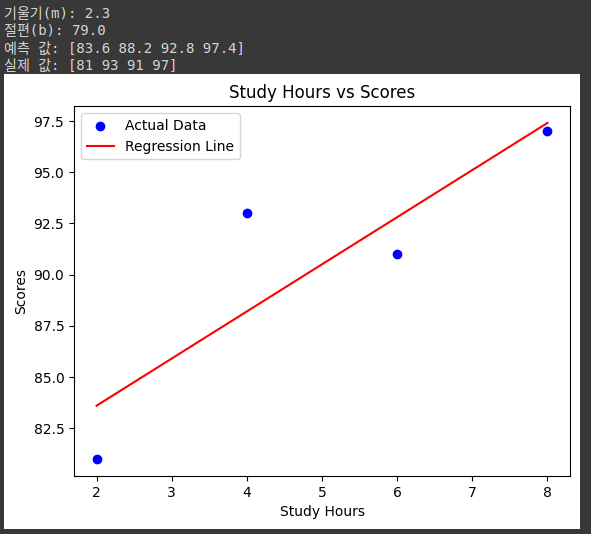
import numpy as np
import matplotlib.pyplot as plt
# 공부 시간(x)과 시험 점수(y) 데이터
x = np.array([2, 4, 6, 8])
y = np.array([81, 93, 91, 97])
# 데이터의 개수
n = len(x)
# 기울기(m) 계산
m = (n * np.sum(x * y) - np.sum(x) * np.sum(y)) / (n * np.sum(x**2) - np.sum(x)**2)
# 절편(b) 계산
b = (np.sum(y) - m * np.sum(x)) / n
# 구한 기울기와 절편 출력
print(f"기울기(m): {m}")
print(f"절편(b): {b}")
# 회귀선을 기반으로 예측한 값 계산
y_pred = m * x + b
print(f"예측 값: {y_pred}")
print(f'실제 값: {y}')
# 실제 값과 회귀선을 시각화
plt.scatter(x, y, color='blue', label='Actual Data') # 실제 데이터
plt.plot(x, y_pred, color='red', label='Regression Line') # 회귀선
plt.xlabel('Study Hours')
plt.ylabel('Scores')
plt.title('Study Hours vs Scores')
plt.legend()
plt.show()
3. 평균 제곱 오차(MSE, Mean Squared Error)
모델이 잘 작동하는지 평가하려면 평가 지표가 필요하다.
평균 제곱 오차(MSE)는 예측 값과 실제 값 사이의 차이를 제곱하여 평균을 구한 값으로, 선형 회귀 모델의 성능을 평가하는데 자주 사용된다.
- 차이점: 최소 제곱법 vs. 평균 제곱 오차
- 최소 제곱법(Least Squares Method)
기울기(m)와 절편(b)를 구하여 최적의 직선(회귀선)을 찾는 방법
수학적인 공식을 통해 기울기와 절편을 최적화함으로써 데이터를 가장 잘 설명하는 직선을 구하는 것이 목적- 최소 제곱법을 사용하여 기울기(a)와 절편(b)을 쉽게 구할 수 있었지만, 이 방법만으로는 다변량 문제를 해결하기 어렵다.
예를 들어, 입력 변수가 하나뿐인 간단한 문제는 최소 제곱법으로 해결할 수 있지만, 입력 변수가 여러 개인 상황에서는 새로운 방법이 필요
- 최소 제곱법을 사용하여 기울기(a)와 절편(b)을 쉽게 구할 수 있었지만, 이 방법만으로는 다변량 문제를 해결하기 어렵다.
- 평균 제곱 오차(MSE)
구한 회귀선이 실제 데이터를 얼마나 잘 설명하는지 평가하는 성능 지표
MSE는 예측 값과 실제 값의 차이(오차)를 제곱하여 그 평균을 구하는 방식으로, MSE가 작을수록 모델이 잘 작동하고 있음을 의미
- 최소 제곱법(Least Squares Method)
- 평균 제곱 오차(Mean Squared Error, MSE)에서 말하는 기울기(Gradient)는, 모델이 최적의 예측을 하기 위해 가중치(weight)와 절편(bias) 같은 파라미터를 어떻게 조정해야 하는지를 알려주는 값이다.
- 기울기(Gradient)는 손실 함수가 어떻게 변하는지를 나타내며, 손실 함수가 최소화되는 방향으로 파라미터를 조정하는 것이 경사 하강법의 핵심이다.
-
가중치 w에 대한 기울기
-
절편 b에 대한 기울기
-
왜 기울기가 필요한가?
기울기를 계산하는 이유는, 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘이 손실 함수의 기울기를 사용해 파라미터를 업데이트하기 때문이다.- 즉, 기울기가 있는 방향으로 가중치 𝑤와 절편 𝑏를 조정하여 손실 함수(MSE)를 최소화하는 것이 목표
-
기울기 계산의 직관적인 의미
- 기울기 값이 크다
손실 함수의 변화가 크며, 파라미터를 빠르게 조정할 필요가 있음을 의미 - 기울기 값이 0에 가까워진다
이때는 손실 함수가 최소화되고 있음을 나타내며, 더 이상 큰 변화를 할 필요가 없다는 것을 의미
- 기울기 값이 크다
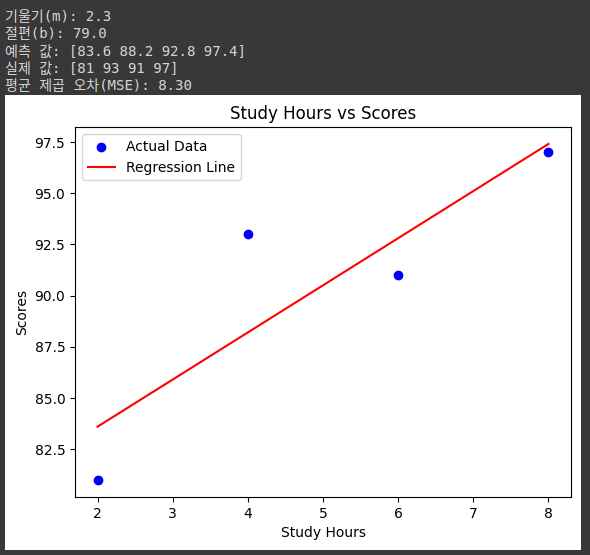
import numpy as np
import matplotlib.pyplot as plt
# 주어진 데이터: 공부 시간(x)과 시험 점수(y)
x = np.array([2, 4, 6, 8])
y = np.array([81, 93, 91, 97])
# 기울기(m)와 절편(b)에 임의의 값 대입
m = 2.3
b = 79.0
# 구한 기울기와 절편으로 예측 값 계산
y_pred = m * x + b
# 평균 제곱 오차(MSE) 계산
mse = np.mean((y - y_pred)**2)
# 결과 출력
print(f"기울기(m): {m}")
print(f"절편(b): {b}")
print(f"예측 값: {y_pred}")
print(f'실제 값: {y}')
print(f"평균 제곱 오차(MSE): {mse:.2f}")
# 실제 값과 회귀선을 시각화
plt.scatter(x, y, color='blue', label='Actual Data') # 실제 데이터
plt.plot(x, y_pred, color='red', label='Regression Line') # 회귀선
plt.xlabel('Study Hours')
plt.ylabel('Scores')
plt.title('Study Hours vs Scores')
plt.legend()
plt.show()
- 기울기와 절편에 임의의 값을 대입하면서 평균 제곱 오차가 가장 낮아지는 지점을 찾을 수 있다
4. 경사 하강법(Gradient Descent)
- 경사 하강법은 최소 제곱법을 사용할 수 없는 복잡한 데이터나 고차원 문제에서 손실 함수(MSE)를 최소화하는 데 사용되는 최적화 알고리즘
- 단순하게 MSE를 최소화하기 위해 기울기와 절편을
업데이트하는 최적화 기법이라고 생각하면 된다.
4.1 경사 하강법의 핵심 아이디어
- 처음에는 임의의 기울기(m)와 절편(b) 값을 설정하고 시작
- 경사 하강법은 반복적인 계산을 통해 기울기와 절편을 업데이트하며, MSE를 최소화하는 방향으로 나아간다
- 각 단계마다 오차를 기반으로 기울기와 절편을 조금씩 이동시키며 최적의 값을 찾는다
4.2 경사 하강법의 주요 개념
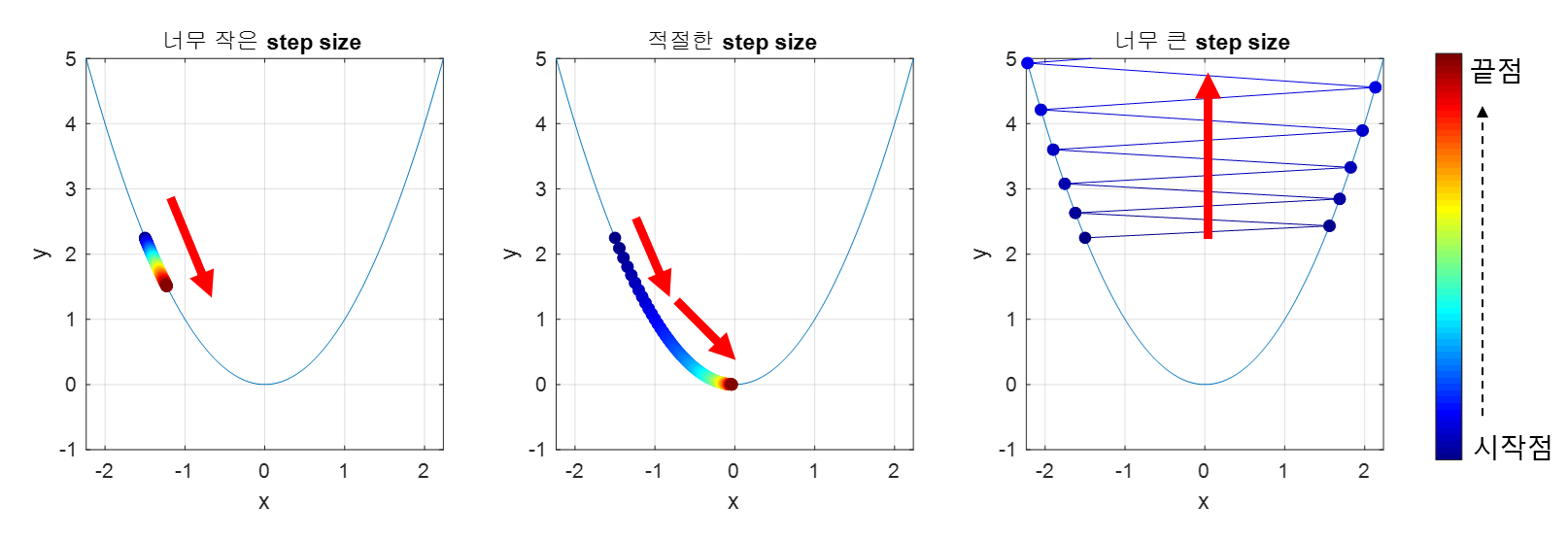
- 학습률(Learning Rate)
학습률은 경사 하강법에서 기울기와 절편을 얼마나 크게 업데이트할지를 결정하는 매우 중요한 파라미터이다
학습률이 너무 크거나 작을 경우, 최적화 과정에서 문제가 발생할 수 있다
- 학습률이 너무 크면
모델이 최적점(손실 함수의 최소값)을 넘어설 수 있다
즉, 기울기와 절편이 너무 많이 업데이트되어 모델이 최적 값을 찾지 못하고 발산한다- 학습률이 너무 작으면
학습 속도가 매우 느려지고, 모델이 최적의 값에 도달하는 데 오랜 시간이 걸릴 수 있다
(이미지 출처: https://angeloyeo.github.io/2020/08/16/gradient_descent.html#google_vignette )
-
최적의 학습률을 찾는 과정:
딥러닝에서는 적절한 학습률을 찾는 것이 매우 중요한 과정
학습률은 모델의 학습 효율성과 성능에 직접적인 영향을 미치기 때문에, 다양한 학습률을 시도해 최적의 값을 찾아야 한다 -
절편(b) 값의 최적화:
절편(b)도 기울기(m)와 마찬가지로 경사 하강법을 통해 최적화된다
절편이 너무 크거나 너무 작으면 오차가 커질 수 있기 때문에, 최적의 절편 값을 찾는 것도 경사 하강법의 중요한 역할
4.3 경사 하강법(Gradient Descent) 예시 코드
# 경사하강법 코딩해보기
x = np.array([2,4,6,8])
y = np.array([81,93,91,97])
# 기울기와 절편의 값을 0으로 초기화
a = 0
b = 0
lr = 0.03 # 학습률
ephocs = 2001 # 몇 번 반복될지 설정
n = len(x) # x값이 몇 개인지
for i in range(ephocs):
y_pred = a * x + b # 예측값 구하는 식
error = y - y_pred # 실제 값과 비교한 오차
a_diff = (2/n) * sum(-x*(error)) # a에 대한 편미분
b_diff = (2/n) * sum(-(error)) # b에 대한 편미분
a = a - lr*a_diff # 학습률을 곱해 기존의 a 값 업데이트
b = b - lr*b_diff # 학습률을 곱해 기존의 b 값 업데이트
if i % 100 == 0: #100번 반복될 때마다 현재의 a,b 값 출력
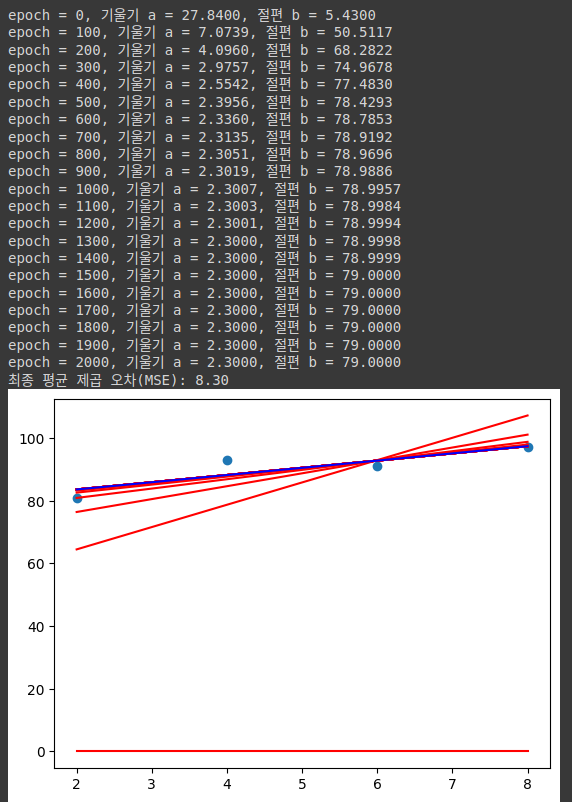
print("epoch = %.f, 기울기 a = %.04f, 절편 b = %.04f" % (i, a, b))
plt.plot(x,y_pred,'r')
y_pred = a*x + b
# 평균 제곱 오차(MSE) 계산
mse = np.mean((y - y_pred)**2)
print(f"최종 평균 제곱 오차(MSE): {mse:.2f}")
plt.scatter(x,y)
plt.plot(x,y_pred,'b') # 최종 그래프는 파란색으로
plt.show()
- 업데이트가 반복됨에 따라 기울기와 절편이 수렴하는 결과를 확인할 수 있다
다음 결과는 수렴과정을 plot한 figure이다임의의 값으로 설정한 주황색 그래프가 기울기와 절편이 업데이트 되며 최종적으로 파란색 그래프로 나타난다
경사하강법을 통해 구한 가장 낮은 평균 제곱 오차(MSE) 값은 8.3이다.
Summary
- 최소 제곱법을 통해 최적의 회귀선을 구하고, 평균 제곱 오차(MSE)로 모델의 성능을 평가하는 방법을 알아보았다.
이후, 경사 하강법(Gradient Descent)을 통해 복잡한 문제에서도 기울기와 절편을 반복적으로 업데이트하여 MSE를 최소화하는 최적화 과정을 설명하였다.
선형 회귀는 가장 기본적인 머신러닝 알고리즘으로, 독립 변수와 종속 변수 사이의 선형 관계를 찾아 미래 값을 예측하는 데 사용된다.최소 제곱법을 통해 기울기와 절편을 구하는 방법을 배웠으며, 이 방법은 단순한 문제에서는 유용하지만, 변수가 많거나 복잡한 데이터에서는 한계가 있다.평균 제곱 오차(MSE)는 예측 값과 실제 값의 차이를 수치화하여 모델 성능을 평가하는 데 사용되며, MSE가 작을수록 모델의 예측력이 높다는 것을 의미한다.경사 하강법은 MSE를 최소화하기 위해 기울기와 절편을 반복적으로 업데이트하는 최적화 알고리즘이다.
이 과정에서 학습률(Learning Rate)이 중요한 역할을 하며, 적절한 값을 설정해야 최적의 기울기와 절편을 찾을 수 있다.
기울기와 절편을 구하는 공식을 암기해야 하는가?
- 기울기와 절편을 구하는 공식은 매우 중요하다
하지만 머신러닝에서는 이를 직접 암기할 필요는 없고 이해하는 것이 더 중요하다.- 실제 모델을 구현할 때는
Scikit-learn같은 라이브러리를 사용하여 쉽게 기울기와 절편을 구할 수 있다.- 경사 하강법 역시 라이브러리를 통해 손쉽게 구현할 수 있으므로, 핵심 개념을 파악하고 실제 코드 구현을 통해 학습하는 것이 더 효율적이다.
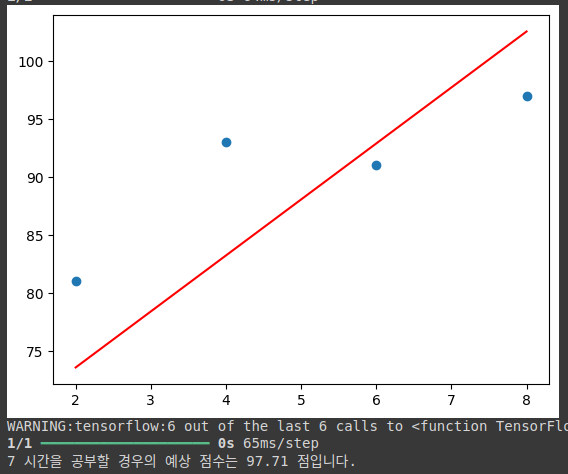
예시 : 텐서플로우(tensorflow)를 한 코드 작성
# 텐서플로우 사용하기
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
x = np.array([2,4,6,8])
y = np.array([81,93,91,97])
# 모델 정의
model = Sequential()
model.add(Dense(1, input_dim = 1, activation = 'linear'))
# 출력되는 값이 1개이므로 Dense의 첫 인자는 1, 입력될 변수도 1개이므로 input_dim도 1, 선형 회귀 모델 = linear
model.compile(optimizer = 'sgd', loss = 'mse')
# 경사하강법 optimizer => sgd, 평균 제곱 오차의 손실함수 => mse
model.fit(x,y,epochs = 100) # 모델 학습
plt.scatter(x,y)
plt.plot(x,model.predict(x),'r')
plt.show()
hour = 7 #임의의 시간을 넣어 점수를 예측해보기
prediction = model.predict(np.array([hour]))
print('%.f 시간을 공부할 경우의 예상 점수는 %.02f 점입니다.' %(hour, prediction))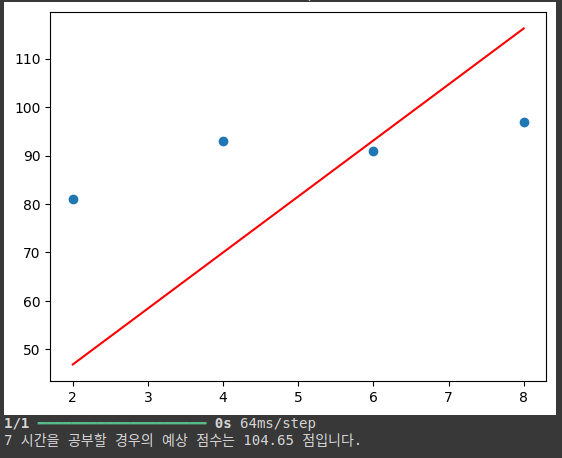
-
예상 점수가 이상한 점은 모델 학습(반복)이 제대로 되지 않았기 때문
epochs를 높여서 돌려보면 적합한 결과가 나올 것이라고 생각함 -
epochs를 500으로 설정하였을때 결과