- 이번에 다룰 데이터는 클래스 (y값)가 2개가 아닌 3개이다
참(1)과 거짓(0)으로 해결하는게 아닌, 여러 개 중에 어떤 것이 답인지 예측하는 문제
1. 다중 분류 (Multi classification)
다중 분류는 둘 중에 하나를 고르는이진 분류와는 접근 방식이 다르다
1-1. 데이터 확인해보기 (아이리스 품종 예측)
import pandas as pd
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/iris3.csv')
df.head()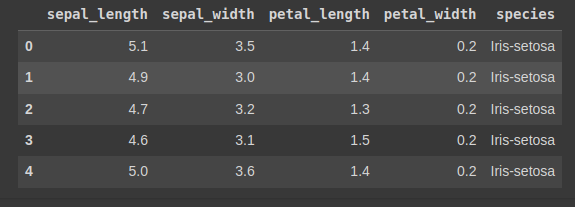
1-2. 전체 상관도 확인해보기
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df, hue='species')
plt.show()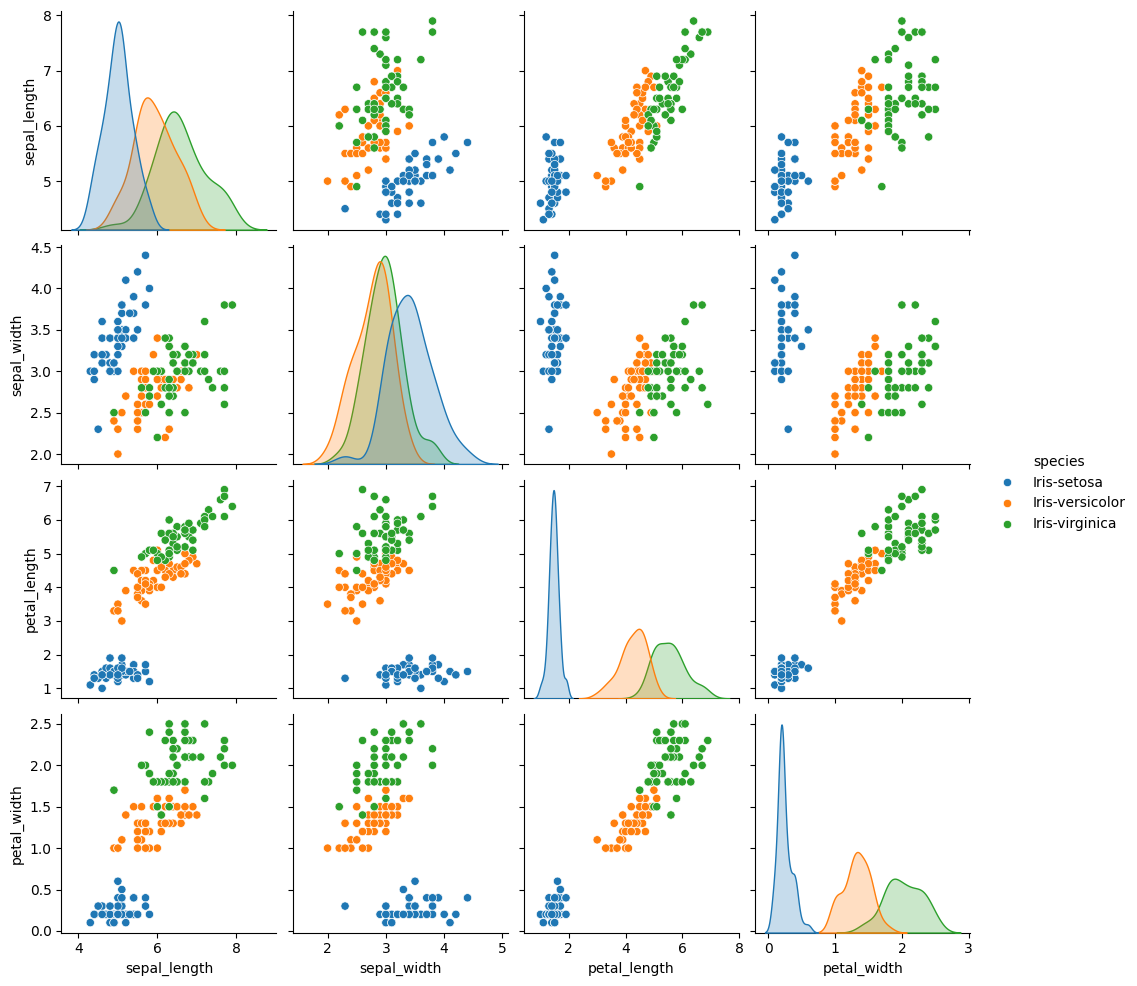
pairplot():hue옵션은 어떤 카테고리를 중심으로 그래프를 그릴지 정하는 것
(여기서는 품종 (species)에 따라 보여지게 지정함)- 속성에 따라 품종이 어떻게 분포되는지 확인가능
1-3. 원-핫 인코딩 (one-hot encoding)
- 데이터 프레임 확인하기
X = df.iloc[:, 0:4] # 특성은 0~ 3열까지 존재
y = df.iloc[:, 4] # 품종은 4열에 존재
print(X[0:5])
print(y[0:5])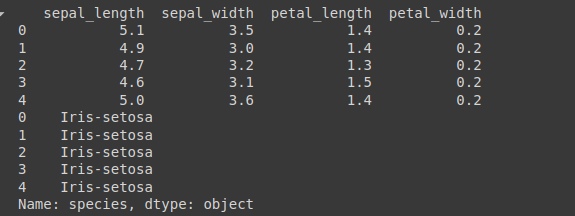
- 저장한
X,y값이 숫자가 아닌 문자이다- 딥러닝에서 계산을 위해서는 문자를 모두 숫자로 바꾸어야함
원-핫 인코딩(one-hot encoding): 여러 개의 값으로 된 문자열을 0과 1로만 이루어진 형태로 만들어주는 과정
get_dummies()함수 사용
y = pd.get_dummies(y)
print(y[0:5]) 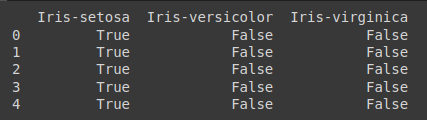
1-4. 소프트맥스(sotfmax)
- 이전에 피마 인디언의 당뇨병 예측과 어떤 코드가 달라졌는지 확인해보기
# 피마 인디언 당뇨병 예측 모델 구성
model = Sequential()
model.add(Dense(12, input_dim = 8, activation = 'relu', name = 'Dense_1'))
model.add(Dense(8, activation = 'relu', name = 'Dense_2'))
model.add(Dense(1, activation = 'sigmoid', name = 'Dense_3'))
model.summary()
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# 붓꽃 품종 예측 모델 구성
model = Sequential()
model.add(Dense(12, input_dim = 4, activation = 'relu', name = 'Dense_1'))
model.add(Dense(8, activation = 'relu', name = 'Dense_2'))
model.add(Dense(3, activation = 'softmax', name = 'Dense_3'))
model.summary()
model.compile(loss = 'categorial_crossentropy', optimizer = 'adam', metrics = ['accuracy'])차이점
1. 출력층의 노드 수가 3으로 바뀌었음
2. 활성화함수가softmax로 바뀌었음
3. 손실함수(loss)가categorial_crossentropy로 바뀌었음
-
당뇨병 예측의 경우, 출력이 0~1사이의 값 중 하나로 변환되어 0.5 이상이면 당뇨로, 이하이면 정상으로 판단하였음
- 이진 분류일 경우출력 값이 하나면 되었음
-
붓꽃 품종 예측의 경우에는 예측해야할 값이 3개임
-
따라서 아래와 같이 세가지 확률을 모두 구해야하므로 시그모이드 함수가 아닌, 다른 함수인
소프트맥스(softmax)가 필요하다.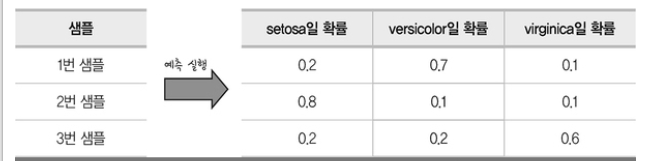
-
소프트맥스(softmax)
각 항목당 예측 확률을 0과 1사이의 값으로 나타내어, 확률의 총 합이 1인 형태로 바꾸어줌
- 손실함수
이진 분류 :binary_crossentropy사용
다항 분류 :categorial_crossentropy사용
1-5. 아이리스 품종 예측하기 최종 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/iris3.csv')
X = df.iloc[:, 0:4] # 특성은 0~ 3열까지 존재
y = df.iloc[:, 4] # 품종은 4열에 존재
y = pd.get_dummies(y)
#모델 설정
model = Sequential()
model.add(Dense(12, input_dim = 4, activation = 'relu'))
model.add(Dense(8, activation = 'relu'))
model.add(Dense(3, activation = 'softmax'))
model.summary()
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
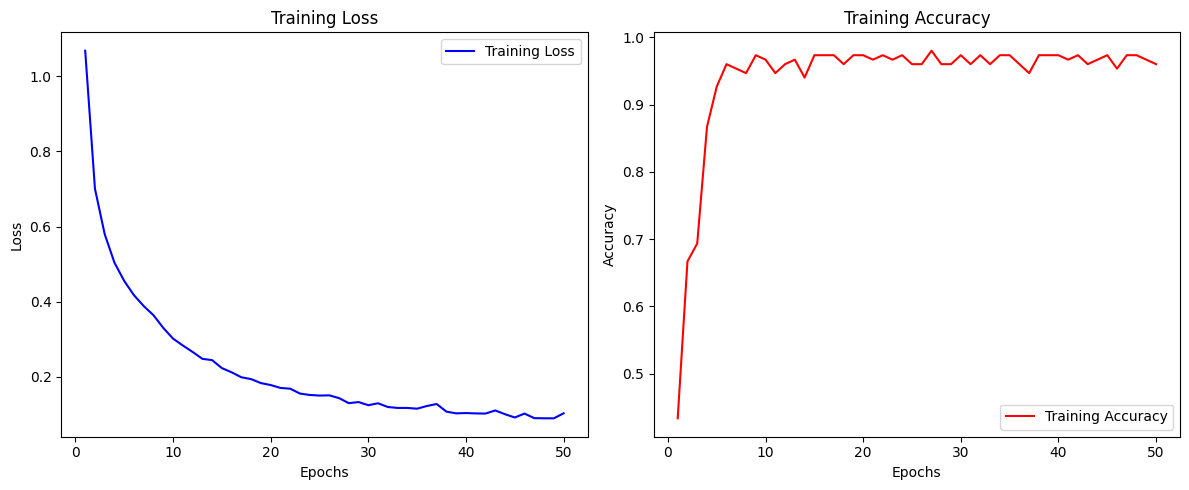
history = model.fit(X, y, epochs = 50, batch_size = 5)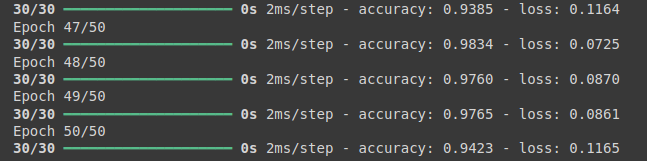
50번 반복시 정확도 : 94.23 %
- accuracy 및 loss 확인하기
import matplotlib.pyplot as plt
# 학습 결과 저장된 history 객체에서 손실값과 정확도 값 가져오기
loss = history.history['loss']
accuracy = history.history['accuracy']
epochs = range(1, len(loss) + 1)
# 손실 그래프 그리기
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 정확도 그래프 그리기
plt.subplot(1, 2, 2)
plt.plot(epochs, accuracy, 'r', label='Training Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
# 그래프 출력
plt.tight_layout()
plt.show()