칼만 필터(Kalman Filter)
1. 칼만 필터란?
칼만 필터는 센서로부터 얻은 데이터에 포함된 노이즈(불확실성)를 줄여서, 시스템의 상태(예: 로봇의 위치, 속도 등)를 보다 정확하게 추정하는 알고리즘이다.
SLAM 시스템에서는 로봇이 움직이면서 센서(카메라, 라이다, IMU 등)로부터 데이터를 받아오는데, 이 데이터는 항상 오차가 포함되어 있다. 칼만 필터는 이 오차를 보정하여 실시간으로 로봇의 상태를 업데이트한다.
2. 칼만 필터의 핵심 용어: 예측, 측정, 추정
칼만 필터는 세 가지 주요 과정을 반복한다.
2.1 예측 (Prediction)
- 목적:
이전에 알고 있던 상태(예: 위치, 속도)를 바탕으로 앞으로의 상태를 예측한다. - 방법:
- 상태 전이 모델:
로봇의 운동 모델(예: 일정한 속도로 이동한다고 가정)을 이용해, 현재 상태에서 다음 상태를 계산한다.
예를 들어, 이전 위치와 속도를 알고 있다면 다음 위치는 “이전 위치 + (속도 × 시간)”으로 예측할 수 있다. - 불확실성 고려:
예측 과정에서도 오차가 있을 수 있으므로, 이 오차(공분산 행렬)를 함께 예측한다.
- 상태 전이 모델:
추가 설명:
예측은 "미래를 미리 계산"하는 과정이다. 이때 사용되는 모델은 물리 법칙이나 시스템의 동작 특성을 반영하지만, 시간이 지날수록 오차가 누적될 수 있으므로 보정이 필요하다.
2.2 측정 (Measurement)
- 목적:
센서를 통해 실제 환경에서 측정된 데이터를 사용해 현재 상태를 확인한다. - 방법:
- 센서는 로봇의 위치나 주변 환경의 정보를 제공하지만, 이 데이터는 노이즈를 포함한다.
- 측정값은 보통 실제 값과 약간의 차이가 있으므로, 이를 그대로 사용하지 않고 보정해야 한다.
추가 설명:
센서의 측정값은 전파 간섭, 기계적 진동, 환경 변화 등 다양한 요인에 의해 왜곡될 수 있다. 이러한 불확실성 때문에, 칼만 필터는 단순히 측정값에 의존하지 않고 예측값과 함께 결합한다.
2.3 추정 (Estimation / Update)
- 목적:
예측된 상태와 실제 측정된 데이터를 추정(보정)하여, 실제 상태에 더 가까운 값을 산출한다. - 방법:
- 칼만 이득 (Kalman Gain):
예측한 상태와 측정값 중 어느 쪽의 신뢰도가 높은지를 판단해, 두 값을 적절히 결합하는 계수를 계산한다. - 보정 단계:
칼만 이득을 이용해 예측값과 측정값의 차이를 보정하고, 이를 통해 추정된 상태를 업데이트한다.
- 칼만 이득 (Kalman Gain):
추가 설명:
- 예측과 추정의 구분:
예측은 모델을 통해 "미리 계산"한 값이고, 추정은 실제 측정값과 비교하여 보정한 값이다.
단순히 측정값을 100% 신뢰하지 않는 이유는 센서 노이즈나 간섭 등으로 인해 측정값이 항상 정확하지 않기 때문이다. 예측값은 모델에 기반하므로 노이즈가 없지만, 오차가 누적될 수 있다. 칼만 필터는 이 두 값을 최적의 방식으로 결합하여 가장 신뢰할 만한 추정 값을 도출한다.- 결국 칼만 필터는 예측과 측정을 결합해 "최종적으로 정확한 상태"를 추정해내는 알고리즘이다.
3. 칼만 필터의 알고리즘 흐름
칼만 필터의 동작은 크게 예측 단계와 추정(갱신) 단계로 나뉜다.
-
초기화:
- 초기 상태 ( \hat{x}_0 )와 초기 불확실성(오차 공분산 ( P_0 ))를 설정한다.
-
예측 단계:
- 예측 상태: 여기서,
- ( A )는 상태 전이 행렬(예: 위치와 속도의 관계)
- ( B )는 제어 입력에 대한 행렬(예: 가속도 등이 포함될 경우)
- ( u_k )는 제어 입력(예: 가속도, 방향 전환 등)
- 예측 오차 공분산: ( Q )는 프로세스 노이즈(예측 오차의 불확실성)를 나타낸다.
- 예측 상태:
-
추정 (갱신) 단계:
-
칼만 이득 계산:
여기서,
- ( H )는 측정 행렬(어떤 상태가 어떻게 측정되는지를 나타냄)
- ( R )은 측정 노이즈 공분산(센서의 오차 정도)
-
상태 추정 (업데이트):
- ( z_k )는 실제 측정값,
는 예측값과 측정값의 오차 (innovation)이다.
-
오차 공분산 업데이트:
이를 통해 추정된 상태의 불확실성을 보정한다.
-
이 과정을 반복하면서, 칼만 필터는 로봇의 상태를 지속적으로 예측하고, 센서로부터 받은 측정값을 반영하여 보다 정확한 추정을 수행한다.
4. 칼만 이득(Kalman Gain)의 자세한 이해
- 정의:
칼만 이득 ( K_k )는 예측 단계에서 도출한 상태와 오차 공분산, 그리고 측정값의 신뢰도를 반영해, 두 값을 얼마나 결합할지를 결정하는 계수이다. - 역할:
- 높은 칼만 이득:
측정값의 노이즈가 작고 신뢰할 수 있을 때, ( K_k )가 높아져 측정값에 더 큰 비중을 두어 보정한다. - 낮은 칼만 이득:
측정값에 노이즈가 많거나 신뢰도가 낮을 때, ( K_k )가 낮아져 예측값에 더 큰 비중을 두게 된다.
- 높은 칼만 이득:
- 수학적 표현: 여기서,
- ( P_{k|k-1} )는 예측 단계에서의 오차 공분산,
- ( H )는 측정 행렬,
- ( R )은 측정 노이즈 공분산이다.
추가 설명:
칼만 이득은 "신뢰도 가중치"라고 생각할 수 있다. 예측값이 오차가 많이 누적된 경우, 즉 불확실성이 클 때는 ( P_{k|k-1} )가 크므로 ( K_k )가 커져 측정값을 더 반영한다. 반대로, 예측이 비교적 정확하다면 ( K_k )가 작아 측정값의 노이즈 영향을 줄인다.
5. 선형 시스템 vs. 비선형 시스템
선형 시스템
- 특징:
시스템의 동작이 선형 방정식으로 표현되는 경우이다. - 칼만 필터 적용:
- 표준 칼만 필터 (Standard Kalman Filter):
선형 시스템에 최적화되어 있으며, 위의 예측 및 추정 단계 공식을 그대로 적용할 수 있다.
- 표준 칼만 필터 (Standard Kalman Filter):
- 예시:
1차원 위치와 속도 추정, 또는 일정한 속도로 이동하는 차량의 상태 추정 등.
비선형 시스템
- 특징:
시스템의 동작이 비선형 관계를 따르며, 상태 전이나 측정 모델이 선형이 아니다. - 문제점:
표준 칼만 필터는 선형 가정을 기반으로 하기 때문에, 비선형 시스템에서는 직접 적용할 경우 부정확한 결과가 나올 수 있다. - 해결 방법:
- 확장 칼만 필터 (Extended Kalman Filter, EKF):
비선형 함수를 테일러 전개(1차 근사)를 통해 선형화한 후 칼만 필터를 적용한다. - 무향 칼만 필터 (Unscented Kalman Filter, UKF):
확률 분포의 샘플링(시그마 포인트)을 통해 비선형성을 보다 정확하게 반영하는 방식이다.
- 확장 칼만 필터 (Extended Kalman Filter, EKF):
- 예시:
드론의 자세 추정이나 카메라 영상에서 특징점을 추출할 때, 비선형 모델을 사용하는 경우 EKF나 UKF가 활용된다.
6. 칼만 필터의 사용 배경 및 SLAM과의 연관성
사용 배경:
- 센서 데이터의 노이즈 보정:
센서에서 측정된 데이터는 항상 불확실성과 노이즈가 섞여 있다. 칼만 필터는 이러한 노이즈를 확률적으로 모델링해 실제 값에 근접한 상태를 추정할 수 있도록 도와준다. - 실시간 처리:
SLAM 시스템에서는 로봇이 움직이는 동안 빠르게 위치와 상태를 업데이트해야 하므로, 계산 효율성이 높은 칼만 필터가 적합하다. - 센서 융합:
카메라, 라이다, IMU 등 여러 센서의 데이터를 결합해 최적의 상태를 추정하는 데 효과적이다.
SLAM과의 연관성:
- SLAM 시스템에서 칼만 필터는 로봇의 Localization (자기 위치 추정)에 핵심적으로 사용된다.
- 예측과 측정의 결합을 통해, 센서의 불확실성을 보정하고, 로봇의 경로와 자세를 보다 정확하게 추정할 수 있게 한다.
7. 칼만 필터 코드 예시 (Python)
다음은 1차원 시스템에서 칼만 필터를 구현한 예시 코드이다.
import numpy as np
import matplotlib.pyplot as plt
# 시간 간격 설정 (예: 1초)
dt = 1.0
# 선형 시스템 가정을 위한 상태 전이 행렬 A와 측정 행렬 H 정의
A = np.array([[1, dt],
[0, 1]])
H = np.array([[1, 0]])
# 프로세스 노이즈 공분산 Q와 측정 노이즈 공분산 R 설정
# Q가 크면 시스템의 예측이 더 불확실하다고 판단하여 측정값에 민감하게 반응하고,
# Q가 작으면 예측을 더 신뢰하여 측정값의 변화가 추정값에 덜 반영됨
# R이 크면 측정값에 노이즈가 많다고 판단해 예측값에 무게를 두며,
# R이 작으면 측정값을 적극적으로 반영함
Q = np.array([[1, 0],
[0, 3]])
R = np.array([[10]])
# 초기 상태 (위치와 속도) 및 초기 오차 공분산 P 초기화
x = np.array([[0], # 초기 위치
[1]]) # 초기 속도
P = np.eye(2) * 500 # 큰 불확실성을 반영한 초기 오차 공분산
# 예시 측정 데이터 (노이즈가 포함된 실제 위치 측정값)
measurements = [1, 2, 3, 2, 1]
# 칼만 필터 추정 결과를 저장할 리스트
estimates = []
for z in measurements:
# 1) 예측 단계 (Prediction)
# 이전 상태를 기반으로 다음 상태를 예측
x_pred = A @ x
# 예측 단계에서의 오차 공분산 업데이트 (모델에 의한 불확실성 포함)
P_pred = A @ P @ A.T + Q
# 2) 측정 단계 (Measurement)
z_meas = np.array([[z]]) # 센서로부터 받은 실제 측정값 (노이즈 포함)
# 3) 추정 단계 (Update)
# 칼만 이득 계산: 예측값과 측정값 중 신뢰도가 높은 쪽을 결정하는 가중치
K = P_pred @ H.T @ np.linalg.inv(H @ P_pred @ H.T + R)
# 예측값과 측정값의 차이(innovation)를 보정하여 상태 업데이트 (추정)
x = x_pred + K @ (z_meas - H @ x_pred)
# 오차 공분산 업데이트: 추정된 상태의 불확실성을 재계산
P = (np.eye(2) - K @ H) @ P_pred
estimates.append(x[0, 0])
# 결과 시각화
plt.plot(measurements, 'ro-', label='Measurements')
plt.plot(estimates, 'b^-', label='Kalman filter estimations')
plt.xlabel('Time')
plt.ylabel('Position')
plt.title('Position estimation using kalman fiter')
plt.legend()
plt.show()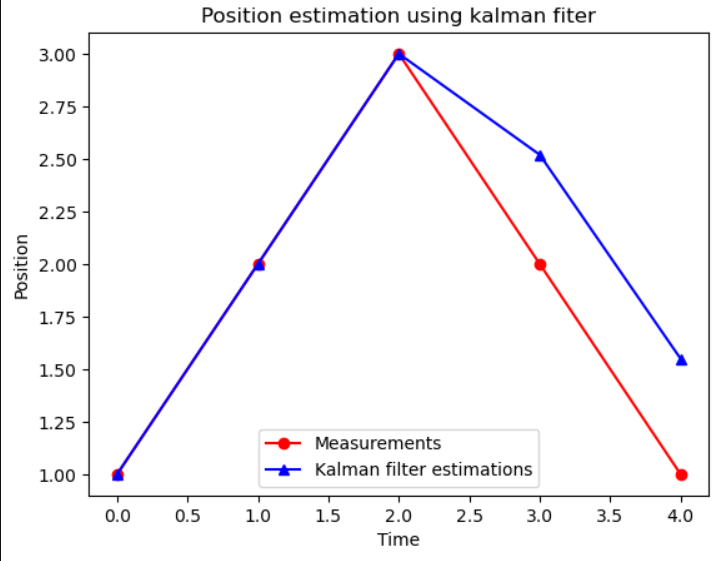
코드 설명:
- 예측 단계:
이전 상태와 모델(행렬 ( A ))을 사용해 다음 상태와 오차 공분산을 예측한다. - 측정 단계:
센서에서 측정한 실제 값 ( z )를 가져온다. - 추정 단계:
칼만 이득 ( K )를 계산해 예측값과 측정값의 차이를 보정하며 최종 상태를 추정한다.
Summary
칼만 필터는 SLAM 시스템에서 매우 중요한 역할을 하며, 로봇이나 자율 주행 차량이 센서 데이터를 기반으로 예측한 후, 실제 측정값을 반영하여 상태를 추정하는 과정을 반복한다.
- 핵심 포인트 정리:
- 예측 (Prediction):
이전 상태와 모델을 이용해 미래 상태를 미리 계산한다. - 측정 (Measurement):
센서로부터 실제 데이터를 받아오지만, 노이즈가 섞여 있다. - 추정 (Estimation):
예측값과 측정값을 칼만 이득으로 결합하여 최종적으로 최적의 상태를 보정한다. - 칼만 이득:
두 정보(예측 vs. 측정) 중 어느 쪽에 더 무게를 둘지 결정하는 중요한 가중치로, 시스템의 신뢰도와 노이즈 특성을 반영한다. - 선형/비선형 시스템:
표준 칼만 필터는 선형 시스템에, 비선형 시스템에는 EKF나 UKF 등 확장 버전을 사용한다.
- 예측 (Prediction):
