K-디지털트레이닝(빅데이터) 30일차
서울시 범죄 데이터와 자동차 데이터를 분석했다.
서울시 범죄 데이터 분석
- 데이터 불러오기
import pandas as pd
# crime_df = pd.read_csv('../data/crimeSeoul.csv', encoding='cp949')
crime_df = pd.read_csv('../data/crimeSeoul.csv',sep=',',engine='python',encoding='euc-kr')
police_df = pd.read_csv('../data/police.csv', sep=',',engine='python',encoding='euc-kr')- 필요한 데이터만 가져옴
police_df1 = police_df[police_df['청'] == '서울청']
police_df1- 관서명 컬럼을 수정한다.
nameresult = []
for temp in crime_df['관서명']:
nameresult.append('서울'+ temp[:-1] + '경찰서')
crime_df['관서명'] = nameresult- 지도만들기 위해서 따로 저장한다.
crimepolicedf = crime_df- 지구대파출소의 주소를 구만 가져온다.
gudata = []
for temp in crime_df['관서명']:
gudata.append(police_df1.loc[police_df1['지구대파출소']==temp, :].주소.str.split(' ').values[0][0])- 구 컬럼을 새로 만든다.
crime_df['구'] = gudata- 자료형을 바꾼다.
crime_df['절도 발생'] = crime_df['절도 발생'].str.replace(',','')
crime_df['절도 발생'] = crime_df['절도 발생'].astype('int')
crime_df['절도 검거'] = crime_df['절도 검거'].str.replace(',','')
crime_df['절도 검거'] = crime_df['절도 검거'].astype('int')
crime_df['폭력 발생'] = crime_df['폭력 발생'].str.replace(',','')
crime_df['폭력 발생'] = crime_df['폭력 발생'].astype('int')
crime_df['폭력 검거'] = crime_df['폭력 검거'].str.replace(',','')
crime_df['폭력 검거'] = crime_df['폭력 검거'].astype('int')- 그룹으로 구를 묶어 더한다.
crime_df = crime_df.groupby('구').sum()- 살인 발생, 살인 검거 컬럼만 저장한다.
a = crime_df[['살인 발생','살인 검거']]- 그래프 그리기위해서 필요한 것들 import
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import matplotlib
import platform
if platform.system() == 'Windows':
matplotlib.rc('font', family='NanumGothic')
#Malgun
%matplotlib inline- 막대그래프로 그리기
a.plot(kind='bar', title='서울시 구별 살인 발생 및 검거 현황')12.지도에 그리기위해서 x,y 좌표를 저장한다.
xlist = []
ylist = []
for temp in crimepolicedf['관서명']:
temp1 = police_df1.loc[police_df1['지구대파출소']==temp,:]['X좌표'].values[0]
temp2 = police_df1.loc[police_df1['지구대파출소']==temp,:]['Y좌표'].values[0]
xlist.append(temp1)
ylist.append(temp2)
crimepolicedf['X좌표'] = xlist
crimepolicedf['Y좌표'] = ylist- 지도에 그린다.
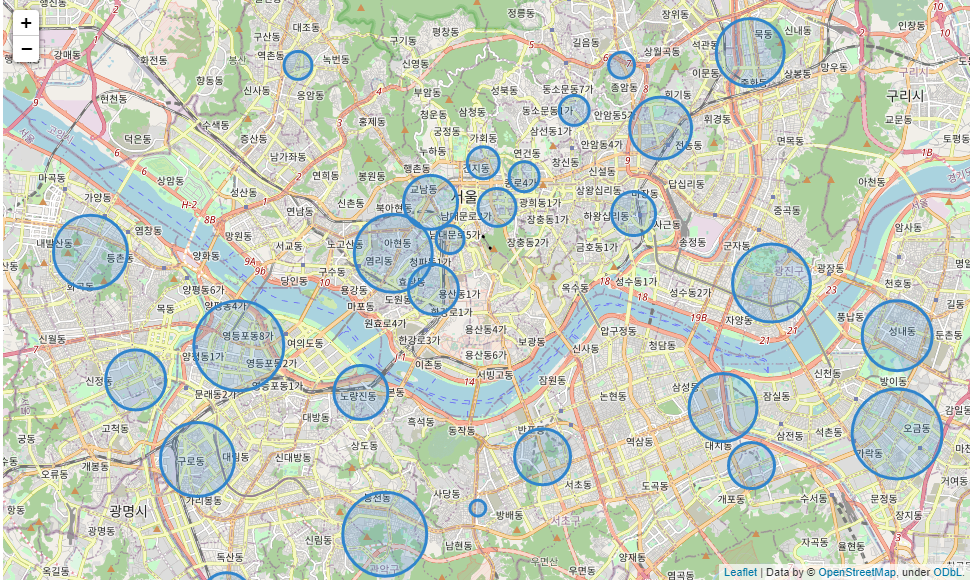
import folium
center = [37.541 , 126.986]#지도의 중심을 넣어준다.
mapdata = folium.Map(location=center, zoom_start = 12)
for temp in crimepolicedf.index:
folium.Circle(
[crimepolicedf['Y좌표'][temp], crimepolicedf['X좌표'][temp]],
radius = int(crimepolicedf.loc[temp,['범죄 합계']].values[0] / 5),color='#3185cc',fill_color='#3185cc'
).add_to(mapdata) #지도에 원을 다 더해라
mapdata결과
자동차 분석
- 데이터 불러오기
import pandas as pd
df = pd.read_csv('../data/auto-mpg.csv')
df = pd.read_csv('../data/auto-mpg.csv',header=None)
- 필요없는 데이터 삭제
df.drop(0, inplace=True)- 열 이름 지정 : 연비, 실린더수, 배기량, 출력, 차중, 가속능력, 출시년도, 제조국, 모델명
df.columns=['연비','실린더수','배기량','출력','차중','가속능력','출시년도','제조국','모델명']- 물음표 값을 0으로 바꿔준다.
df[(df['출력'] == '?')] = '0' - 자료형 변환
df = df.astype({'출력':'float64','연비':'float64','실린더수':'int64','배기량':'float64','차중':'float64','가속능력':'float64','출시년도':'int64','제조국':int})- 각종 정보 및 arg 쓰는법
df.info()
df.describe()
df.count()
df.mean()
df['연비'].mean()
df[['연비','차중']].mean()
df.연비.median()
df.max()
df.std()- 예외처리 하는 방법
#오류가나면 예외처리를 해준다.
for temp in df.columns:
try:#밑에있는 코드가 문제없이 돌아가면 처리하고
df[temp] = df[temp].str.replace('?','0')
except:#오류나면
print('오류났어요' + temp)- 상관관계분석
df.corr() #상관관계 분석
#숫자끼리만 상관관계를 분석해준다.
#0에 가까울수록 상관관계가 없다.- 히트맵으로 그려보기
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import matplotlib
import platform
if platform.system() == 'Windows':
matplotlib.rc('font', family='NanumGothic')
#Malgun
%matplotlib inline
import seaborn as sns
colormap = plt.cm.PuBu#컬러값을 지정해준다.
plt.figure(figsize=(10,8))
plt.title('자동차 상관관계 분석',y=1.05,size=15)
sns.heatmap(df.corr(),linewidths=0.1, vmax=1.0, square=True,cmap=colormap, linecolor='white',annot=True,annot_kws={"size":16})
#default는 cmap=colormap이걸 뺴야한다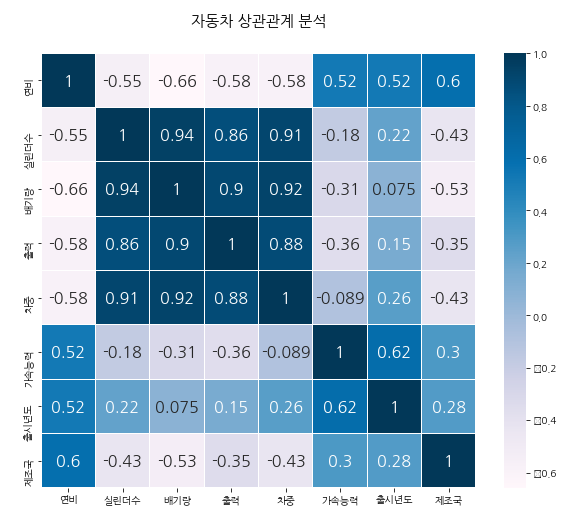

smilegate