K-디지털트레이닝(빅데이터) 31일차
장바구니 분석, 웹툰 타이틀 크롤링을 했다.
- 데이터셋 만들기
#데이터 셋의 형태는 이런 구조여야 장바구니 분석이 가능하다.
dataset = [
['커피','녹차','얼음'], #1인 구매 리스트
['커피','얼음','우유'],
['커피','딸기'],
['바나나','녹차','딸기'],
['커피','얼음'],
['우유','커피'],
['우유','딸기'],
['커피'],
['얼음','커피']
]- 패키지 불러오기
import pandas as pd
#장바구니 분석을 하기위해 필요한 패키지들
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori- 학습
#학습
te = TransactionEncoder()
#데이터셋을 fit으로 맞추고 transform으로 바꿔준다.
te_ary = te.fit(dataset).transform(dataset)
te_ary- 데이터프레임으로 만들기
#그냥써도 되지만 데이터프레임으로 넣어주면 보기좋아진다.
df = pd.DataFrame(te_ary, columns=te.columns_)- apriori 알고리즘 사용
f_data = apriori(df,use_colnames=True)
#min_support옵션을 주지않으면 기본 지지도는 0.5로 설정된다.
#0.2이상만 보여줘
f_data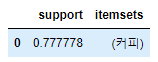
6. 지지도를 낮춰본다.
f_data = apriori(df,min_support=0.1, use_colnames=True)
f_data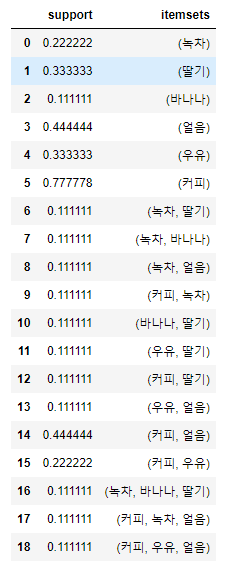
- 지지도, 신뢰도, 향상도 출력
from mlxtend.frequent_patterns import association_rules
#지지도(support) 전체거래항목중 a,b를 포함하는 비율
#신뢰도(confidence) a를 포함하는 거래중에 a,b가 동시에 거래되는 비중
#향상도(Lift) a와 b사이에 상호관계가 없으면 1 //// 1보다 큰값 연관성이 낮다
#threshold = 신뢰도
#
#min_threshold의 기본은 0.8이다.
association_rules(f_data, metric='confidence', min_threshold= 0.6)
# association_rules(f_data, metric='lift', min_threshold= 0.3)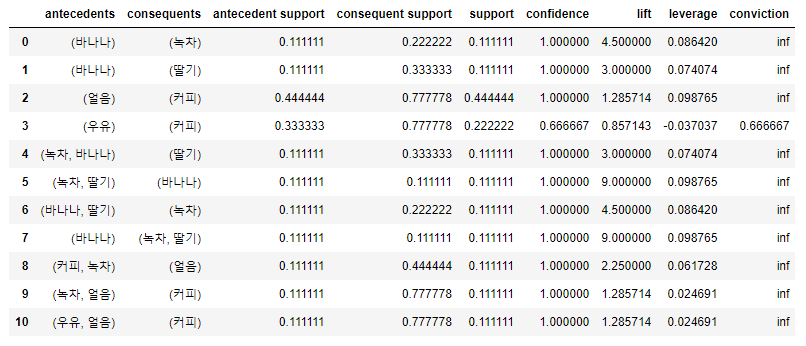
내가 찾아본 표 분석방법
lift(향상도) 수치가 1보다 큰 것들이 있는데, 1보다 클수록 우연히 일어나지 않는다는 뜻
1이면 아무관계없다는 뜻
위의 표를 해석해보면 바나나 구매하면 녹차, 딸기를 구매하는 경우가 있다. 둘의 신뢰도가 0.111111로 같다
바나나-녹차 : 0.111111
바나나-딸기 : 0.111111
이중 녹차와 딸기 둘다 향상도가 1보다 크기때문에 높은 인기를 가진다.
웹툰 타이틀 크롤링
- 주소
#https://comic.naver.com/webtoon/genre- 필요한 패키지 불러오기
import requests
from bs4 import BeautifulSoup방법
div or ul
최상단까지 올라가는게 처음
처음에 맨위에 있는 태그를 검색해서 데이터 들어있는지 안들어있는지 확인
그리고 밑에가서 확인
마지막에 최종데이터 가져오기
- 주소를 저장하고 가져와서 출력해보기
#페이지를 적어주고
#이 주소의 html 데이터를 한꺼번에 불러온다.
page = requests.get('https://comic.naver.com/webtoon/genre.nhn')
#가져와서 화면에 출력을 해봄,,, 원하는 데이터가 있는지?
#여기에서 안보이면 과감하게 크롤링 포기하기
#여기서 없으면 막혀있는거임
html = page.text
soup = BeautifulSoup(html,'lxml')BeautifulSoul에는 가져온걸 나눠주는애가 두가지 있는데 html과 lxml 이 있다. 그 중에 가장 빠른게 lxml이다.
첫번째가 가져온 데이터, 두번째는 html 태그 값을 찾을 떄 쓰는 파싱할때 쓰는 패키지를 선언해준다.
html.parser => 안깔아도 된다. 하지만 속도가 느리다.
lxml(pip install 로 따로 설치해서 써야함) => 속도가 빠르다.
html5lib => html5형식으로 할수있따...? 잘안쓰나봄
soup.find() => 태그 한개를 찾을 때
soup.find_all => 모든 태그를 찾아서 가져옴 /// 저장형태 : 리스트 ['<div ...>']
soup.find('div', class_='클래스명') //// soup.find('div',{'class or id':'list_area'}) 방법이 여러가지
-
클래스명으로 찾기
result = bs4.find('div',class_='ex_class')
print(result) -
id명으로 찾기
result = bs4.find('div', id='ex_id')
print(result)
참고사이트 https://brownbears.tistory.com/414
딕셔너리 형식으로도 찾는게 가능하다
- 원하는 데이터 가져오기
data1 = soup.find('div', {'class' : 'list_area'})앞에서 저장한 데이터 에서 찾는다
저장 방법은 csv파일로 저장하는게 가장좋다.
- 태그 찾아와서 제목만 출력
data2 = data1.find_all('dt')
result = []
for temp in data2:
result.append(temp.find('a').attrs['title'])
print(result)- csv로 저장 -1
import pandas as pd
df = pd.DataFrame(result)
#한글 저장이기 때문에 인코딩해주고 인덱스 없애야한다.
#저장할때 옵션값을 줄 수 있다.
#mode = 'w' : 새로만들 때, 'a' : 뒤에 이어붙임
# header = False 하면 헤더값도 안들어간다.
df.to_csv('이어서 저장.csv', index = False, encoding='euc-kr', mode='a', header = False)
df1 = pd.read_csv('제목.csv',encoding='euc-kr')- csv로 저장 -2
#열었으면 닫아줘야한다.
f = open('웹툰제목크롤링 데이터.csv', 'w')
for temp in result:
print(temp)
f.write(temp + ',')# \n 쓰면 한줄마다 띄어쓰기
f.close- 제목 저장하기 연습
ydata = [
['타이틀',2,2],
['타이틀2', 100, 300],
['타이틀3', 200, 400],
]
f = open('유투브데이터.csv','w')
f.write('채널명' + ',' + '조회수' + ',' + '좋아요' + '\n')
for temp in ydata:
f.write(temp[0].replace(',','') + ',' + str(temp[1]) + ',' + str(temp[2]) + '\n')
f.close()
#구분자를 컴마로 하면 문제가 많이 생긴다. replace를 해준다.- 특수문자 제거
#한글, 영어, 숫자만 남기고 특수문자를 제거하는 방법
import re
string = 'abcd가나다라마바사12345[]!#!#!$!$$'
#정규표현식
re.sub('[^A-Za-z0-9가-힣]','',string)
smilegate