Instruction decode란?
지난 글에서 CPU가 메모리를 참조해 명령을 받아오고, 실행하는 대략적인 과정에 대해 살펴보았다.

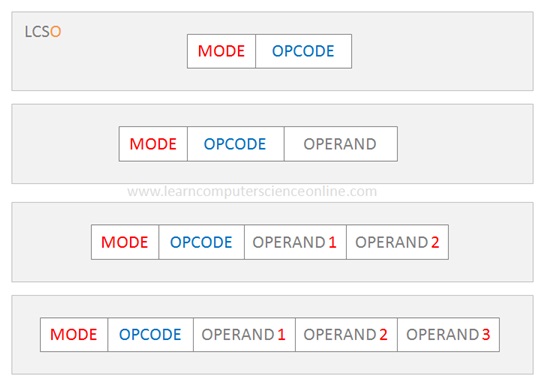
위 그림이 CPU가 인식하는 Instruction의 구조이다.
여기서 Opcode는 연산의 종류. 즉, operator라 볼 수 있다.
Operands는 연산의 대상. 즉, 피연산자를 뜻한다.
위 그림에서는 2개의 피연산자가 있지만,
실제로는 아래와 같이 Insturction code마다 0~3개의 피연산자를 가질 수 있다.
Mode는 이전글에서 다루었던 Addressing mode(direct/Indirect)를 표시해주는 비트이다.
이유는 각 연산마다 필요한 피연산자의 개수가 다르기 때문이다.
Load A라는 연산과
C = A + B라는 연산의 피연산자 개수는 다르다.
물론 High language로 작성된 모든 연산에 대한 opcode가 존재하는 것은 아니다.
예를 들어, F = ((A+B) * C + D) / E 같은 명령은 결코 그대로 CPU에게 넘어가지 않는다는 소리이다.
무슨 말인가 하면,
C = A + B라는 연산이 있다고 해보자.
모든 연산은 CPU가 하기 때문에 이는 이렇게 분할 될 수 있다.
load a,reg1->add b,reg1->store reg1,c
시스템에 따라서는 이렇게도 분할 될 수 있다.
load a,reg1->load b,reg2->add reg1,reg2->store reg2,c
여기서 볼 수 있는 load, add, store 등이 바로 Opcode들이다.
이 Opcode와 Operands를 참조해서 무엇을 가지고 무엇을해야 하는지 결정하는 과정이 바로 Instruction Decode라고 할 수 있다.
Instruction의 종류는 크게 4가지로 나눌 수 있는데
1. 메모리와 CPU 레지스터 사이에 데이터를 옮긴다
2. 데이터에 대해 산술, 논리 연산을 수행한다
3. 명령의 실행 순서를 제어한다.
4. I/O devices로 데이터를 전달한다.기능 별로 나누면 대강 이런식으로 나뉘고,
Opcode 목록
상호작용하는 컴포넌트별로 나누면 3가지 분류로 나눌 수가 있는데 아래와 같다.
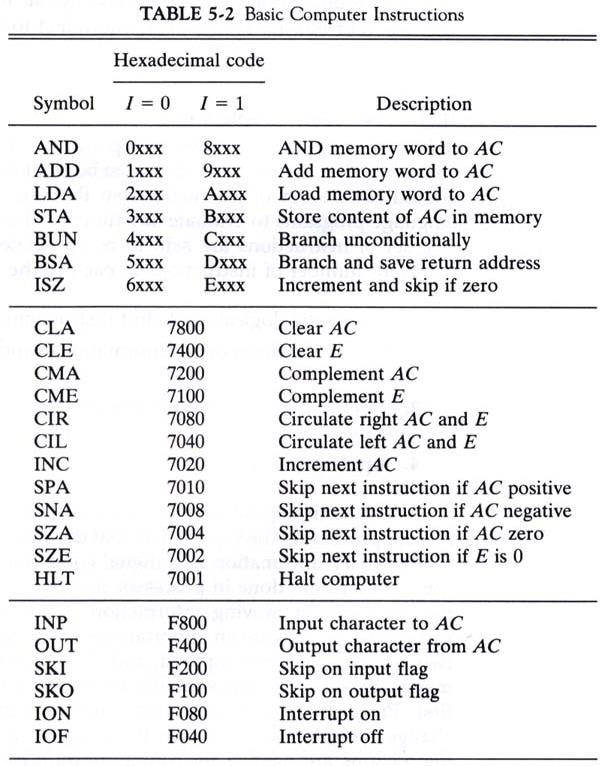
가장 위의 Symbol은 Addressing mode를 뜻한다.
(0 = 직접 모드, 1 = 간접 모드)
메모리 참조 명령어
아래 그림은 내부 로직이다.
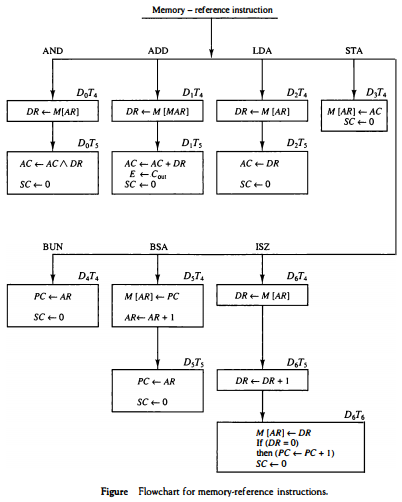
공통적으로 나오는 SC <- 0은 SC를 초기화 하여 다음 Instruction Cycle이 시작되게끔 하는 것이다.
AND
AR의 유효 주소의 비트와 AC의 비트에 대해 AND 연산을 하고, 결과를 AC에 저장한다.
해당 주소의 값을 먼저 DR에 전달 후, AC와 DR 값으로 and 연산을 하고 결과를 AC에 저장한다.
ADD
AR의 유효 주소의 값과 AC의 값을 더해 결과를 AC에 저장한다.
E는 플립플롯이며 최상위 캐리아웃을 E에 저장한다.
LDA (Load Address)
AR의 유효 주소의 값을 AC에 불러온다.
데이터를 먼저 DR로 불러온 후 AC에 저장한다.
STA (Store Address)
AC의 값을 AR의 유효 주소에 저장한다.
BUN (Branch Unconditionally)
AR의 값을 PC에 저장해 다음에 실행 될 명령을 지정한다.
때문에 무조건 분기 내지는 점프라고도 부른다.
BSA (Branch and Save return Address)
BUN이 편도 점프라면, BSA의 왕복 점프라고 할 수 있다.
점프 후에 원래 흐름으로 돌아오기 때문에 보통 서브루틴(subroutine) or 프로시저 (procedure)라고 하는 프로그램의 일부분으로 분기하는 데 사용된다.
흐름을 살펴보면 이러하다.
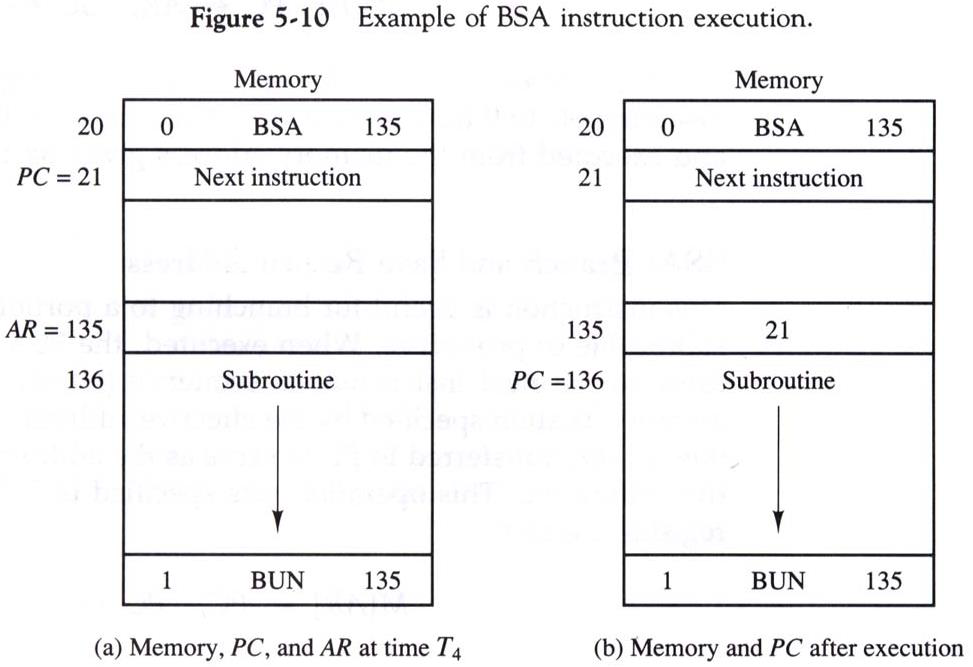
- 주소 20에서 BSA 명령을 만났다. 0은 Addressing mode, 135는 Operand이다.
AR에135를 저장한다.- 의 값
21을 AR이 가리키는 곳에 저장한다. 이 경우에는M[135]가 된다.- AR을 1 증가시켜
136을 만들고,PC에 저장한다.- PC의 값인 136에 대해 다음 Instruction Cycle이 돌며 적절한 작업을 수행한다.
- 작업의 마지막에 간접모드로
BUN명령을 내린다.- 간접 명령이기 때문에 135가 아닌 M[135]의 값인
21이PC에 저장된다.- PC의 값인 21에 대해 다음 Instruction Cycle이 돌며 적절한 작업을 수행한다.
ISZ (Increment if Zero)
대개 프로그래머에 의해 해당 유효주소에 음수가 저장되며, 이게 1씩 증가하다 보면 언젠가는 0을 만난다. 그러면 PC의 값이 1 증가하여 다음 Instruction을 패스하게 된다.
레지스터 참조 명령어
IR에 있는 12비트로 12가지 명령어를 나타낸다.
그림에 나타난 바와 같이 레지스터 참조 명령어는 시간 T3에 수행되고, 이후 순차 카운터의 타이밍 신호는 다시 T0으로 돌아간다.
아래는 레지스터 참조 명령어의 micro-ops이다.

입출력 명령어
입출력에 관련된 명령어들의 micro-ops이다.
입출력과 인터럽트에 대해서는 따로 글을 하나 작성 할 예정이다.

이렇게 Instruction Code의 한 부분을 담당하는 Opcode에는 특징이 하나 있다.
Opcode들은 CPU의 종류마다 다르다.
Intel CPU에서 동작하던 프로그램을 들고 ARM CPU에서 실행시키면 문제가 생기는 이유다.
몇몇 언어의 경우 그런 문제 없이 잘 동작하는데,
이는 컴파일러와 인터프리터의 차이 때문이다.
도대체 왜 이런 것일까?
CISC vs RISC
컴퓨터의 프로세서는 설계에 따라 CISC와 RISC로 나뉘는데,
이 두 종류의 프로세서는 지원하는 OPCODE가 다르다
그렇기 때문에 위에서 말한 Intel Processor용 프로그램을 들고 ARM Processor의 환경 위에서 실행시키면 문제가 발생하는 것이다.
Complex Instruction Set Computer (CISC)는 문자 그대로
복잡한 명령어들을 가지고 있는 프로세서 구조이다.
반면,
Reduced Instruction Set Computer (RISC)는
보다 적은 양의 기본적인 명령어들을 가지고 있는 프로세서 구조이다.
이 두 가지 구조의 차이를 간단히 설명하기 위해
MULT 라고 하는 Complex opcode를 예로 들어보자.
이는 두 수를 곱하는 명령이며, MULT 2:3, 5:2와 같은 형태로 표현될 수 있다.
In CISC,
MULT 2:3, 5:2
이 한 줄로 끝난다. 지원되는 opcode이기에 뭘 더 할 것도 없다.
여기서 Operands들은 주소를 가리킨다.
In RISC,
LOAD A, 2:3
LOAD B, 5:2
PROD A, B
STORE 2:3, A
MULT를 지원하지 않기 때문에 이렇게 4줄로 나뉘어진다.
무엇이 더 나은가는 애매하다.
각기 장단점이 있기 때문이다.

위의 식이 프로그램의 실행 속도를 결정하는 공식인데,
CISC는 3번째의 Insturctoins 즉, 명령어의 수를 줄여 시간을 줄인다.
RISC는 2번째의 cycles 즉, 명령의 실행 사이클의 길이를 줄여 시간을 줄인다.
둘 다 나름의 이론이 있고, 성능 향상의 근거가 있다만,
적어도 Pipelining에 한해서는 RISC의 손을 들어주고 싶기도 하다.
Instruction pipelining
파이프라인이란 여러 명령들이 연속으로 들어올 때,
연속적이고 효율적인 실행을 위해, 명령들을 조금씩 겹쳐서 실행하는 것을 말한다.
아래는 Pipeline을 설명하기 위한 전통적인 세탁기 이론이다.
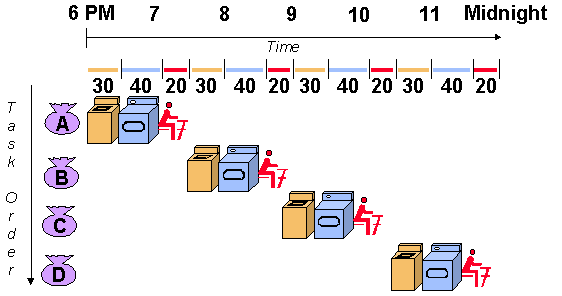
CPU가 하나이기 때문에, 1명이 세탁을 한다고 하고,
세탁을 하는 데에 30분, 건조하는 데에 40분, 개는 데에 20분이 걸린다고 가정하자.
총 4덩이의 세탁물이 있다고 하고, 이를 1덩이씩 끝낸다고 하면
(30 + 40 + 20) * 4 = 360분이 걸린다.
그런데 그림을 잘 보면,
건조를 시작하게 되면 세탁기는 놀게 되고,
옷을 개기 시작하면 건조기가 놀게 된다.
이에 착안하여 아래와 같이 프로세스를 바꾸면,
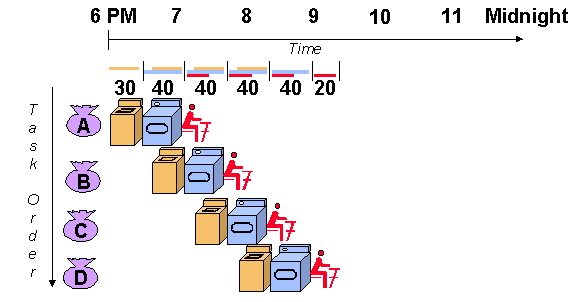
총 소요시간이 30 + 40 * 4 + 20 = 210분으로 줄게 된다.
즉, 한 파트의 작업이 끝나고 다음 파트로 넘어갈 때, 이전 파트에 새로운 작업물을 할당해주는 것이 Pipelining이다.
이게 CPU와 무슨 연관이 있는가 하면,
CPU 또한 하나의 작업을 세세하게 나눌 수 있기 때문이다.
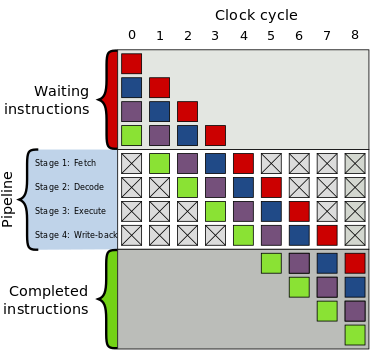
명령어의 인출 / 해독 / 실행 / 결과 기록 / ...
하나의 작업을 이렇게 여러 Stage로 나누어서
CPU의 각 부분 (PC, MAR, MBR, IR etc.)에 할당하면
여러 파트들이 쉼 없이 돌아가며 시간당 작업처리 효율이 상승하게 된다.
사진에는 4개의 Stage만 있지만 실제로는 더 많은 Stage가 존재 할 수 있다.
예를 들어, Texas Instruments의 C55x 제품군의 경우에는
FetchDecode
Address: computes data and branch addresses
Access 1: reads dataAccess 2: finishes data read
Read stage: puts operands onto internal busses
Read stage: puts operands onto internal busses
이렇게 7개의 Stage를 가진다.
References
- Instruction Format and Sequencing : https://binaryterms.com/instruction-format-and-sequencing.html
- Instruction set architecture : https://en.wikipedia.org/wiki/Instruction_set_architecture#cite_ref-7
- Instruction Format In Computer Architecture : https://www.learncomputerscienceonline.com/instruction-format/
- Computer Organization and Architecture : https://upscfever.com/upsc-fever/en/gatecse/en-gatecse-chp157.html
- RISC vs CISC : https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/risccisc/
- Instruction pipelining : https://en.wikipedia.org/wiki/Instruction_pipelining
- Pipelining : https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/pipelining/index.html
