현 컴퓨터 구조는 폰 노이만이 제안한 구조를 따르고 있다.
이게 무슨 소리냐 하면,
컴퓨터가 할 수 있는 일들에 대한 명령은 메모리에 저장을 해 두고
CPU가 클럭마다 메모리에 접근하여 명령어를 가져오고, 해독하고, 실행하는 구조라는 소리다.
클럭이란?
간단히 말해 CPU가 작업을 수행하는 순간을 말한다.
흔히 "CPU가3.0 GHz다" 라고 한다면,
1초에 약3,000,000,000개의 클럭 수를 지원할 수 있는 CPU란 소리다.
이 폰 노이만 구조의 핵심은
CPUMemoryI/O Devices
이다.
여기에 추가하자면
System bus
정도가 있겠다.
Bus란?
컴퓨터 내부의 컴포넌트들끼리 혹은 컴퓨터끼리 데이터를 주고 받으며 통신하기 위한 시스템이다.
예를 들어, 프린트 명령을 내릴 때에도 프린터로 통하는 External bus를 통해 데이터가 전달된다.
여기서 말하는 System bus는 Internal Bus로, 컴퓨터 내부의 컴포넌트들 (CPU, RAM, I/O Devices) 사이에서 데이터 교환을 담당한다.
이 3개의 주요 컴포넌트들이 시스템 버스를 통해 데이터를 주고 받는 것을 그림으로 표시하면 다음과 같다.
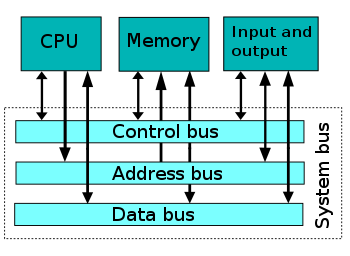
CPU가 메모리로부터 명령과 데이터를 찾아 실행한다.
이 때 명령과 메모리의 주소값, 데이터는 시스템 버스를 통해 운반된다.
간략하게는 이렇게 쉽게 표현 할 수 있지만, 여기에도 세부과정이 있다.
아아, 이것이 바로 Instruction Cycle이라는 것이다.
Instruction Cycle = Fetch Cycle + Execute Cycle
Fetch Cycle : CPU가 실행할 명령을 메모리에서 읽어오는 부분
Execute Cycle : 읽어 온 명령을 해독해서 연산을 수행하는 부분
그림으로 나타내면 아래와 같다.
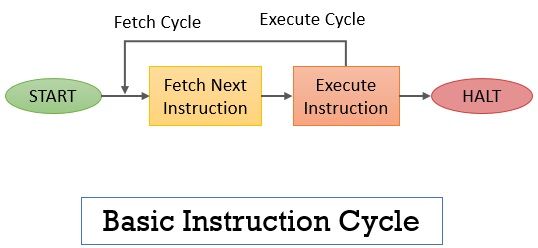
읽고->실행->읽고->실행->명령이 더 없을 때까지 반복한다
아주 간단해 보인다.
하지만 여기서 Interrupt가 출동한다면 어떨까?
Interrupt란?
명령을 실행 중 일 때 다른 명령이 끼어드는 것을 말한다.
이 경우 명령 실행 후에 Interrupt check를 한다.
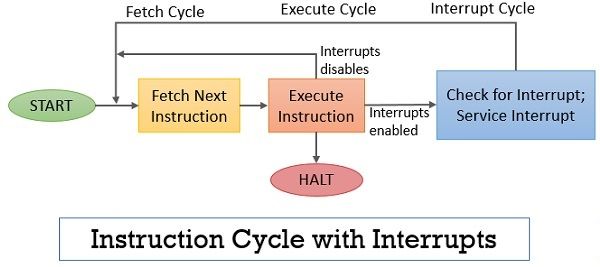
Interrupt가 있다면?
1. 우선 현재 실행되고 있는 명령의 주소를 킵하고
2. Interrupt를 먼저 처리해 준 후에
3. 실행하고 있던 명령으로 돌아간다.
없다면?
위의 기본 사이클과 같다.
혹시 Indirect Cycle이라고 들어는 봤니?
이제 명령 실행 중에 간섭 발생 시 CPU가 어떻게 처리하는 지도 알았다.
하지만 여기서 다중 피연산자가 두둥 등장한다면?
위의 사이클 대로라면 명령을 받아서 이제 연산을 수행해야 하는데
대강 = 3 + 같은 상황인 것이다.
이 경우, 피연산자를 메모리로부터 추가적으로 읽어올 필요가 있다.
이럴 때 사용하는 것이 Indirect Addressing이다.
Interrupt/Indirect Cycle까지 포함한 Instruction Cycle은 이러하다.
1. Instruction Fetch (IF)
2. 해당 명령이 Indirect Addressing 인지 아닌지 검사
3. 사용중이라면 Indirect Cycle이 실행된다
4. 아니라면 Basic Instruction Cycle 실행
5. 그 와중에 Interrupt 발생하면 그것부터 처리
그림으로 나타내면 아래와 같다.
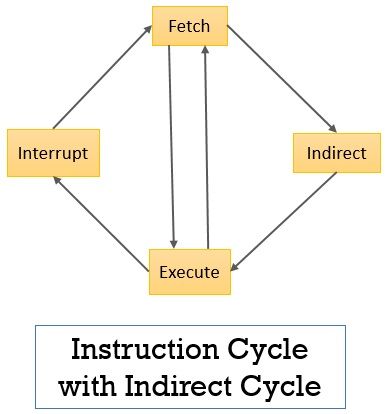
Fetch 후에 Indirect Check가 있고,
Execute 후에 Interrupt Check가 있다.
Indirect Cycle은 Basic Instruction Cycle과 어떻게 다른가?
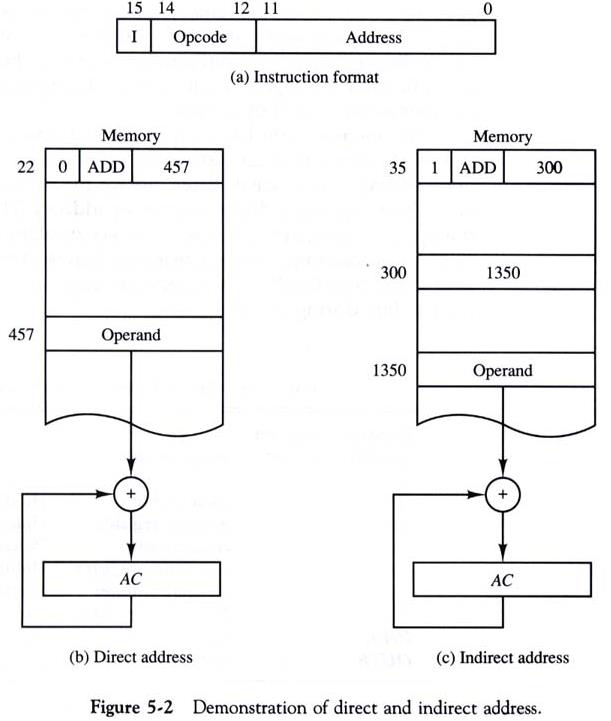
왼쪽이 Direct, 오른쪽이 Indirect이다.
(b)와 (c)에 있는 메모리 구조에서 가장 위를 보면 각각의 Instruction format이 있다.
0 ADD 457 / 1 ADD 300 이라고 되어 있는데,
맨 앞의 0과 1은 Addressing mode를 뜻하며
0이 Direct, 1이 Indirect를 표시한다.
그 뒤의 ADD 457이 바로 Instruction이고,
세부적으로는 ADD가 Opcode, 457이 Operand인데 이건 아직 몰라도 된다.
아무튼, 457의 값을 더해라 라는 것인데 여기서 Operand는 기본적으로 메모리의 Address로 주어진다는 것을 알아야 한다.
그러니까 AC += 457이 아니라, AC += M[457]이라는 것이다.
왼쪽의 경우 메모리 457번지에 있는 값을 그대로 가져오면 되는데,
오른쪽은 Indirect mode이기 때문에 457번지에 있는 값인 1350를 다시 주소로 받아들여서 1350번지에 있는 값을 가지고 와야 한다.
여기서 주소가 아닌 최종적인 데이터 값이 있는 메모리를 Effective Address (EA)라고 한다.
세부적으로 보면 MAR에 값을 넘겨주는 주체가 다른데,
Basic Cycle에서 일어나는 동작들을 살피면 아래와 같다.
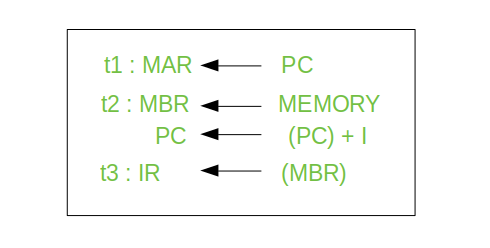
맨 윗 줄을 보면 PC에서 MAR로 값이 넘어가는 것을 볼 수 있다.
그리고 이것이 Indirect Cycle이다.
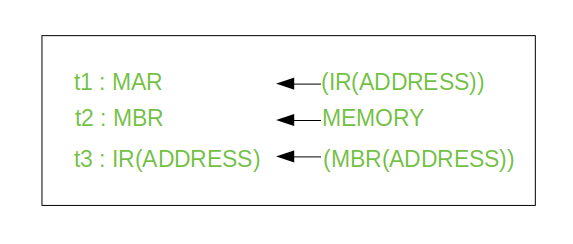
PC에서 다음 명령을 가져오는 것이 아니라 IR에서 가리키는 주소값(위의 예시에서는 1350)이 들어오게 된다.
MAR? MBR? PC? IR? 뭔 소리임?
CPU 내에 존재하는 Register들의 이름이다.
CPU의 명령 실행순에 따라 나열해보자면
Program Counter (PC) : 다음에 실행될 명령이 있는 주소를 가리킨다. 해당 명령을 읽어와 MBR에 저장한 이후에 n만큼 증가한다.
명령어마다 길이가 다르기 때문에 무조건 +1이 아닌 해당 명령어의 길이만큼 증가한다.
Memory Address Register (MAR) : PC가 가리키고 있던 주소에 가서 데이터를 읽어오기 전에 해당 주소를 임시적으로 저장한다.
Memory Buffer Register (MBR) : MAR이 가리키고 있던 주소의 데이터(명령)를 저장한다.
Instruction Register (IR) : 가장 최근에 인출된 명령어를 저장한다.
Accumulator (ACC) : 연산 결과가 임시적으로 저장한다.
이것들을 위의 설명과 연관시켜 생각해보면,
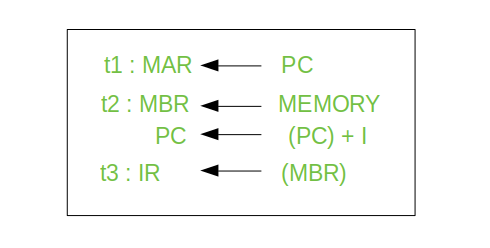
위 그림은 Instruction Fetch (IF)의 과정을 나타내고 있음을 알 수 있다.
t1:
PC가 가리키고 있던 주소를MAR로 옮긴다
t2:MAR이 가리키는 주소에 가서 데이터(명령)을 가져와MBR에 저장한다.
t2-1:PC를I만큼 증가시킨다. (1이 아니다)
t3:MBR의 데이터를 인출을 위해IR에 이관한다.
Micro-operation
위의 그림들에서 볼 수 있는
MAR <- PC
MBR <- Memory
등의 명령을 micro-operation이라고 한다.
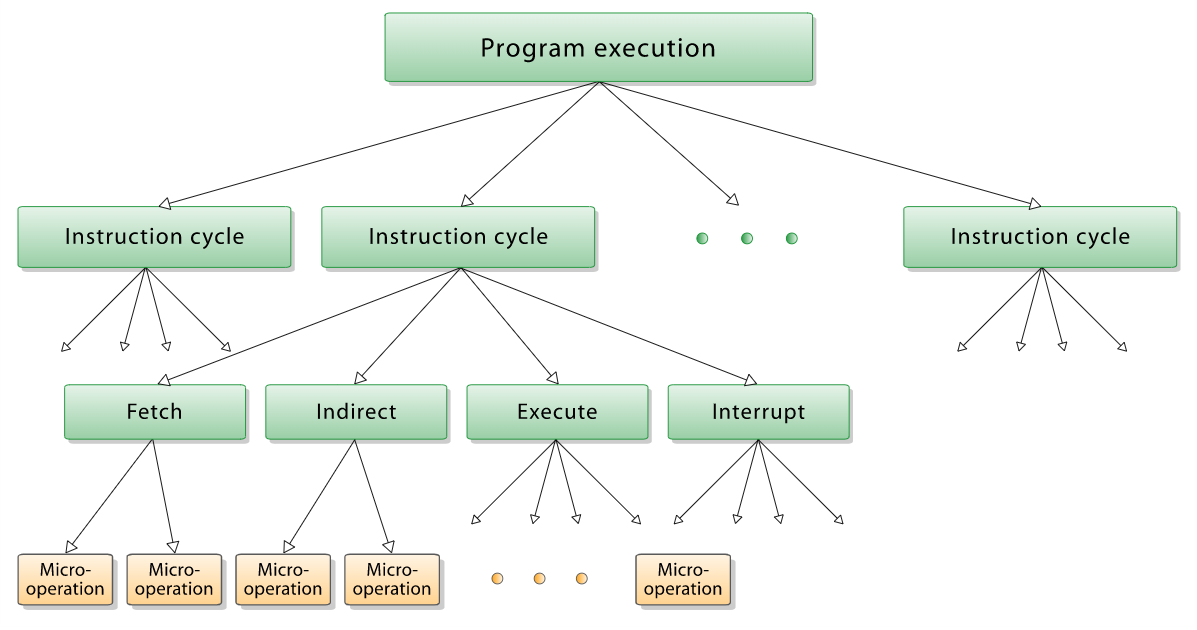
하나의 복잡한 작업은 여러 개의 명령으로 나누어지고,
이 명령들은 Instruction Cycle에 따라 Fetch, Indirect, Execute, Interrupt 라는 세부작업으로 나누어지며,
이 세부작업들은 더 작은 단위의 작업인 Micro-operation (micro-op)으로 나누어진다.
그러니까 CPU가 실제로 하는 일들은 바로 이 micro-ops인 것이다.
Micro-op이 실행 될 지는 Opcode와 Operands로 구성된 Instruction에 의해 결정된다.
Opcode와 Operand에 대해서는 여기에 나와있다.
아무튼, 이 micro-op의 특징은 이렇다.
- 하나의 클럭 펄스 내에서 실행된다.
- CPU의 Control Unit (CU)의 제어 아래에서 실행된다. 실행 순서도 CU에 의해 결정된다.
- 데이터에 대한 산술/논리/비트 연산, 데이터의 이동/삭제 등을 담당한다.
대표적인 동작은 이렇게 4가지이다.
- 시프트(shift) : 데이터의 직렬 전송을 위하여 사용되며, 논리, 순환, 산술 세 가지 종류가 있다.
- 카운트(count) : PC의 값을 다음 주소에 맞게 증가시킨다.
- 클리어(clear) : 해당 메모리를 비운다.
- 로드(load) : 메모리에서 데이터를 불러온다.
이 외에도 산술/논리 연산 등의 동작들이 있다.
Micro-ops의 예시를 간단하게 들어보자.
여기까지 읽었으면 명령어 인출(Instruction Fetch)과 같은 과정도 여러 개의 micro-ops의 조합으로 이루어져 있다는 것을 알 것이다.
그걸 표현해보면 위에서 본 문장들이 나온다.
t0:MAR <- PC
t1:MBR <- M[MAR], PC<--PC+I
t2:IR <- MBR
첫 문장의 경우, t0 == 1이라면 PC가 가리키는 곳의 값을 MAR에 갖다 집어넣으라는 의미이다.
두 번째는 t1 == 1이라면 메모리에서 MAR이 담고 있는 주소로 찾아가 그 값을 MBR에 넣고, PC의 값을 I만큼 증가시키라는 의미이다.
t1 시점에는 2개의 마이크로 연산이 있는데 병렬적으로 처리 가능한(각 연산이 서로에게 영향을 미치지 않는) 연산 일 경우 콤마( , )로 구분해서 위처럼 같이 넣으면 된다.
여기서 t0, t1, t2가 뭔지 의문이 들 텐데 이걸 알기 위해서는 타이밍 신호에 대해 알아야 한다.
타이밍 신호란?
CPU의 Control Unit (CU) 내부에 Sequence Counter (SC) 라고 하는 특정한 이벤트가 발생한 횟수를 저장하는 회로가 있다.
이 회로의 출력은 Decoder 하나의 입력으로 들어가게 되어 있는데, 이를 통해 SC가 담고 있던 카운트가 T0~Tn(보통 T15)의 출력으로 나뉘어진다.
SC의 입력값에는 CPU Clock이 있기 때문에 클럭 1회에는 T0, 2회에는 T1 같은 식으로 해당 출력이 활성화 된다.
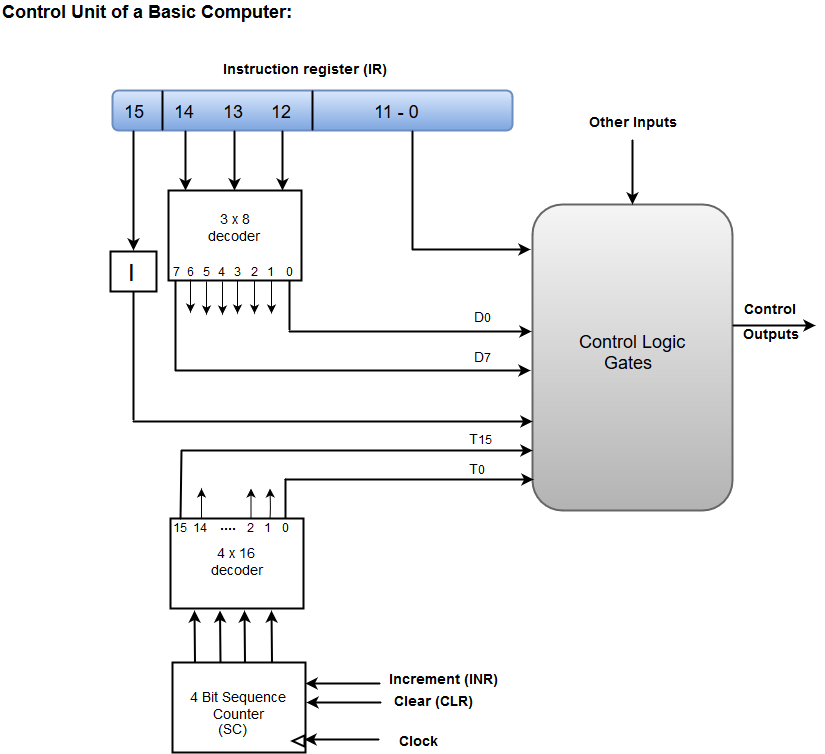
그러니까 이를 통해 위의 micro-ops의 해석에 조금 덧붙여보면
1회 째의 클럭 펄스 때 MAR <- PC 연산을
2회 째의 클럭 펄스 때 MBR <- M[MAR], PC<--PC+I
3회 째의 클럭 펄스 때 IR <- MBR를 하라는 소리이다.
그리고 나서는 내부적인 설계에 따라
D3T4: SC <- 0 와 같이 T4의 타이밍에 D3의 입력이 활성화 되어 있으면 값을 초기화한다.
References
- Instruction Cycle : https://binaryterms.com/instruction-cycle.html
- Computer Organization | Different Instruction Cycles : https://www.geeksforgeeks.org/different-instruction-cycles/
- System bus : https://en.wikipedia.org/wiki/System_bus
- Micro-operation : https://en.wikipedia.org/wiki/Micro-operation
- Basic Control Unit : http://people.uncw.edu/tagliarinig/Courses/242/BasicComputer/ControlUnit.htm
