여러 gpu 를 이용해 OOM 을 해결하고 싶으면 DataParallel(DP) 를 이용하면 된다. (속도는 비슷)
Multi-GPU 개념: 모델을 복사해서 각 gpu 에 할당 -> batch size 를 gpu 수만큼 나눔(scatter) -> 각 gpu 에서 입력 받아 출력(forward) -> 출력을 다시 하나의 gpu로 모음(gather) -> back propagation 은 다시 각 gpu 별로 실행 -> 이 gradient 들을 다시 하나의 gpu 에 모아서 업데이트
기존 DataParallel 방식:
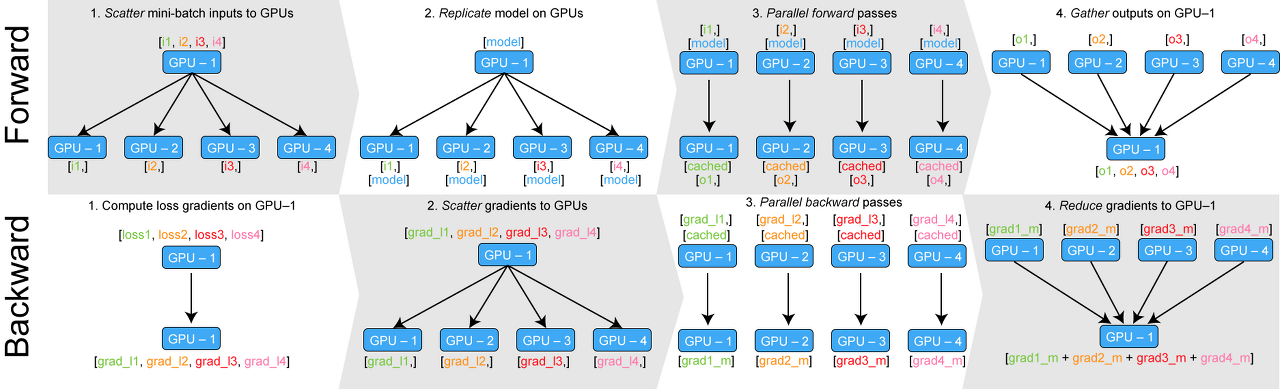
이 방식은 한 gpu 에서 loss function을 계산했기 때문에 극심한 GPU memory 불균형이 일어난다.
또한 Pytorch 에서 multithreading 기반 DataParallel 을 제공하는데, 파이썬은 GIL(Global Interpreter Lock) 기반으로, 여러 스레드 중 하나씩만 파이썬 코드에 접근할 수 있다. 따라서 멀티쓰레드가 싱글 스레드 급으로 작동해 영 좋지 않다.
새로운 방식(https://github.com/zhanghang1989/PyTorch-Encoding):
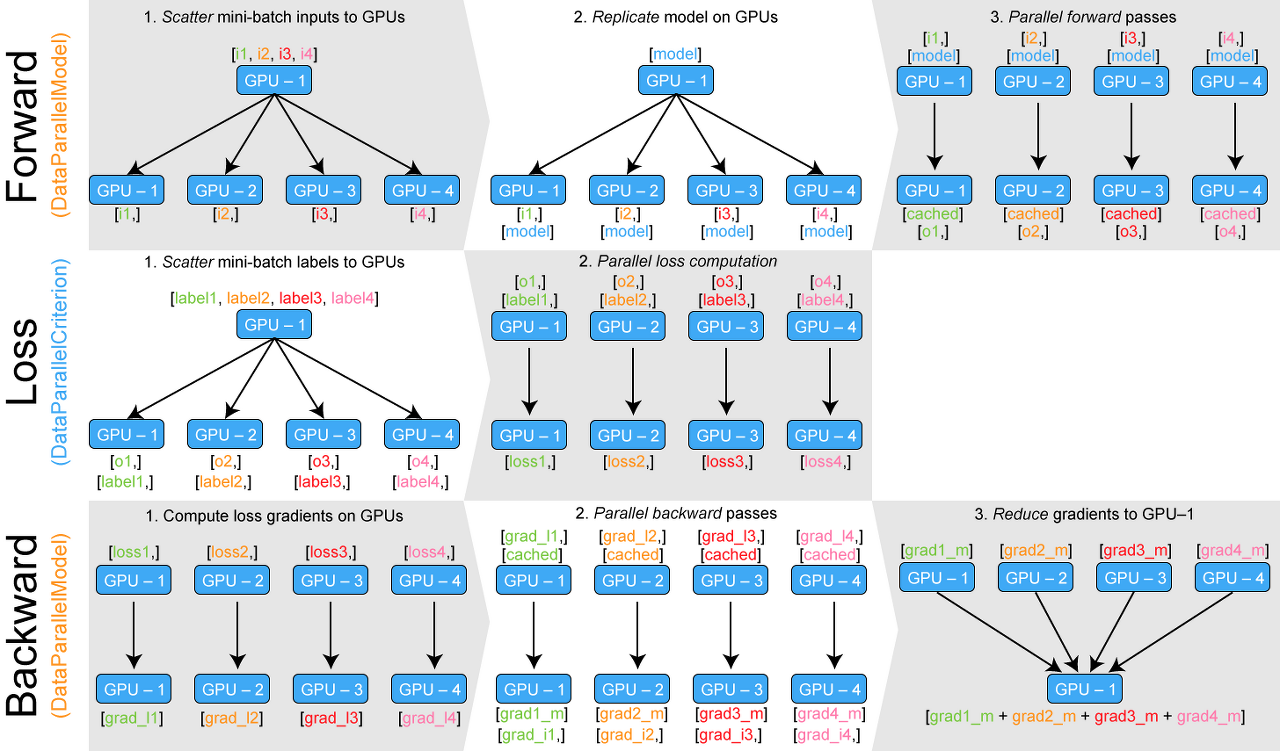
Custom 한 DP로 불균형 해결(각 gpu 에서 바로 loss 계산 후 backward)
But 두 방식 다 gpu 성능을 최대로 끌어올리지는 못함, 학습 속도 느림 => 해결 방법 : Distributed Data Parallel(DDP)
DDP는 다중 프로세스 병렬 처리(멀티 프로세싱)를 사용하기 때문에 모델 복제본 간의 GIL connection 이슈가 없음
아까 말했듯이 GIL(global interpreter lock) connection : 파이썬에서 여러 쓰레드가 동시에 실행되는 것을 막는 것
DDP 는 하나의 GPU 에 하나의 프로세스 할당하는 것! 한 GPU 가 한 프로세스라 누가 더 많이 차지하는 비율도 없음. 단 각 프로세스끼리 계산한 결과를 합칠 때 백엔드 라이브러리가 필요함
단일 GPU 학습 코드에 비해 몇 가지 추가/수정 필요
학습 코드를 함수화하고 해당 함수를 멀티프로세싱 모듈로 실행하는 방식으로 분산 학습을 진행 가능
world_size = 전체 gpu 개수
rank = gpu 번호
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
def train(rank, world_size, batch_size, epochs=100):
global_rank = rank # multi-nodes인 경우, 수정 필요
dist.init_process_group(
backend="nccl",
init_method="tcp://127.0.0.1:33445",
rank=global_rank,
world_size=world_size,
)
torch.cuda.set_device(rank)
model = T5ForConditionalGeneration.from_pretrained("t5-large").to(rank)
model = DDP(model, device_ids=[rank])
dataset = DummyDataset()
sampler = DistributedSampler(dataset, shuffle=True, drop_last=True)
dataloader = DataLoader(dataset, batch_size=batch_size, sampler=sampler)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for epoch in range(epochs):
sampler.set_epoch(epoch)
for data in tqdm(dataloader):
data = {k: data[k].to(rank) for k in data}
optimizer.zero_grad()
output = model(**data)
output.loss.backward()
optimizer.step()여기서 DDP 는 모든 gpu 에 모델 state 를 저장하지만, 각각 다른 gpu 에서 저장하고 사용할 때만 불러온다면 통신은 많아져도 다룰 수 있는 모델의 크기는 더 커질 수 있다. 이 방법이 FSDP(Fully Sharded DataParallel)!
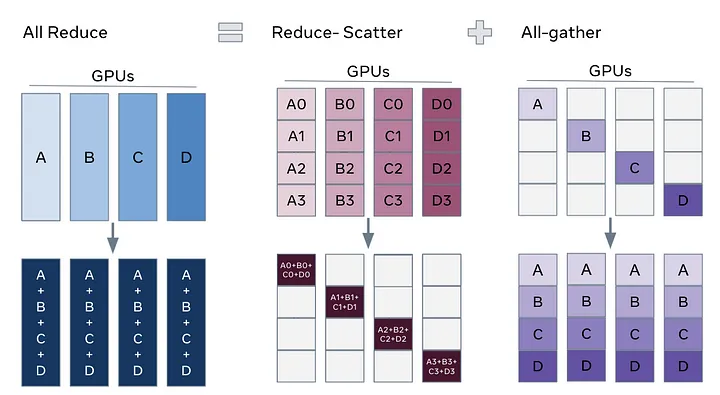
위 방법이 DDP 방식
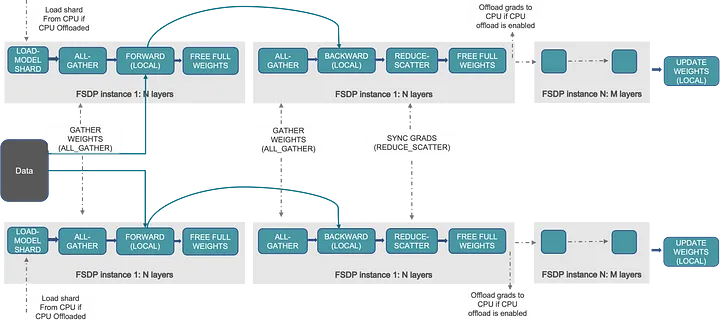
위 방법이 FSDP 방식
FSDP 코드는 다음과 같은데, DDP 에서 큰 차이가 없다.
import functools
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from transformers.models.t5.modeling_t5 import T5Block
def train(rank, world_size, batch_size, epochs=100):
global_rank = rank
dist.init_process_group(
backend="nccl",
init_method="tcp://127.0.0.1:33445",
rank=global_rank,
world_size=world_size,
)
torch.cuda.set_device(rank)
model = T5ForConditionalGeneration.from_pretrained("t5-large")
wrap_policy = functools.partial(transformer_auto_wrap_policy, transformer_layer_cls={T5Block})
model = FSDP(model, auto_wrap_policy=wrap_policy, device_id=rank)
dataset = DummyDataset()
sampler = DistributedSampler(dataset, shuffle=True, drop_last=True)
dataloader = DataLoader(dataset, batch_size=batch_size, sampler=sampler)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for epoch in range(epochs):
sampler.set_epoch(epoch)
for data in tqdm(dataloader):
data = {k: data[k].to(rank) for k in data}
optimizer.zero_grad()
output = model(**data)
output.loss.backward()
optimizer.step()FSDP 는 통신이 많아 무조건 DDP 보다 빠르다 혹은 좋다 할 수 없다. 서버(node) 가 많다면 서버간 통신 속도까지 고려하여 오히려 안 좋을 수 있다. 대신 FSDP 는 모델 크기를 더 큰 걸 사용할 수 있게 된다.
응용 방법들 : DeepSpeed
DDP 참고 자료:
https://mvje.tistory.com/141
https://pytorch.org/tutorials/intermediate/dist_tuto.html
