기존 zero shot 에서는 task 만 주어지고 결과 값을 얻을 수 있었고 few-shot 에서는 prompt에 예시를 몇개 주면 결과 값을 얻을 수 있었다.
이러한 가중치 조정 없이 prompt를 이용하는 in-context learning 이 대두되면서 여러 step 을 거쳐야 풀 수 있는 문제들을 해결하는 chain-of-thought 방식이 나온다.
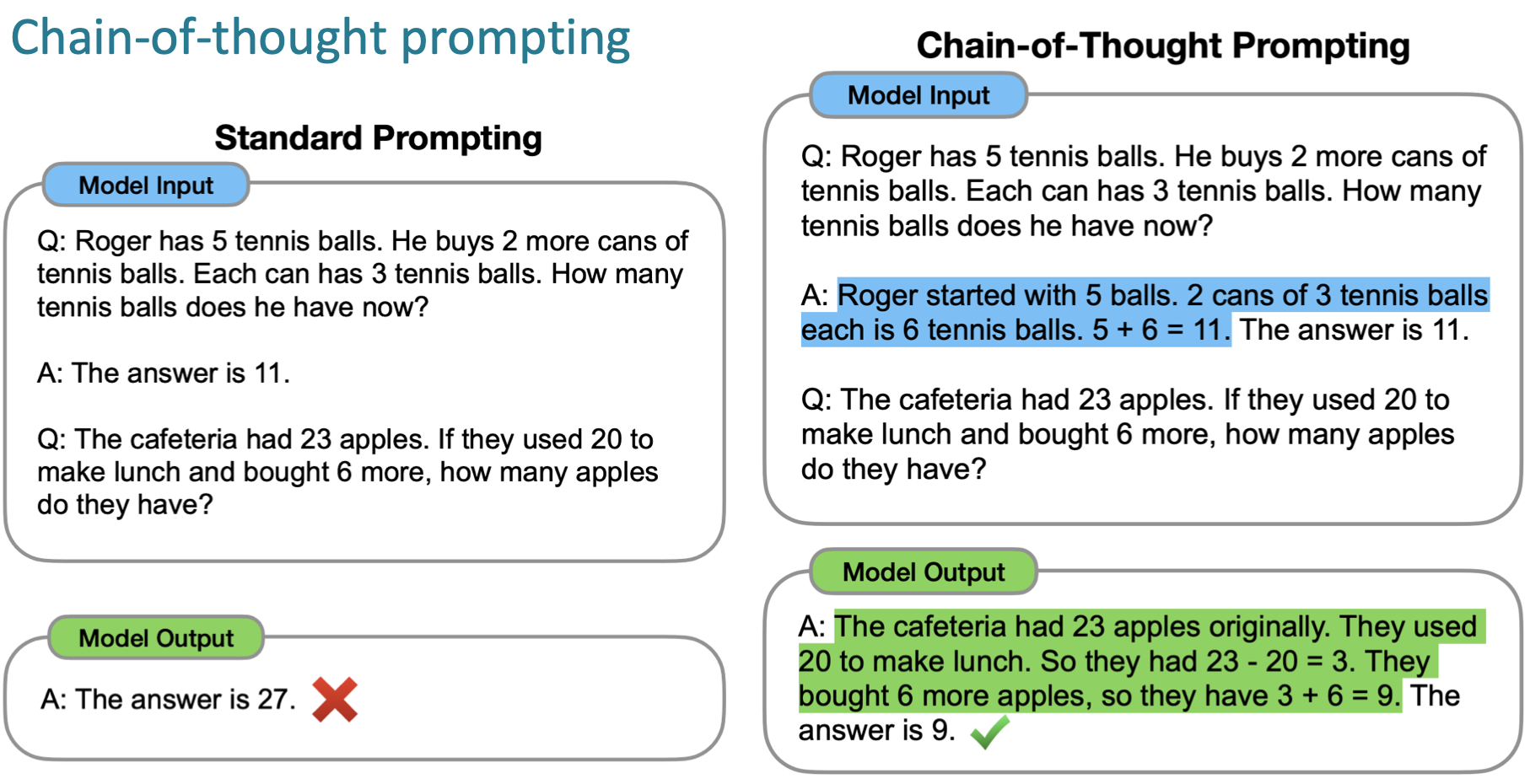
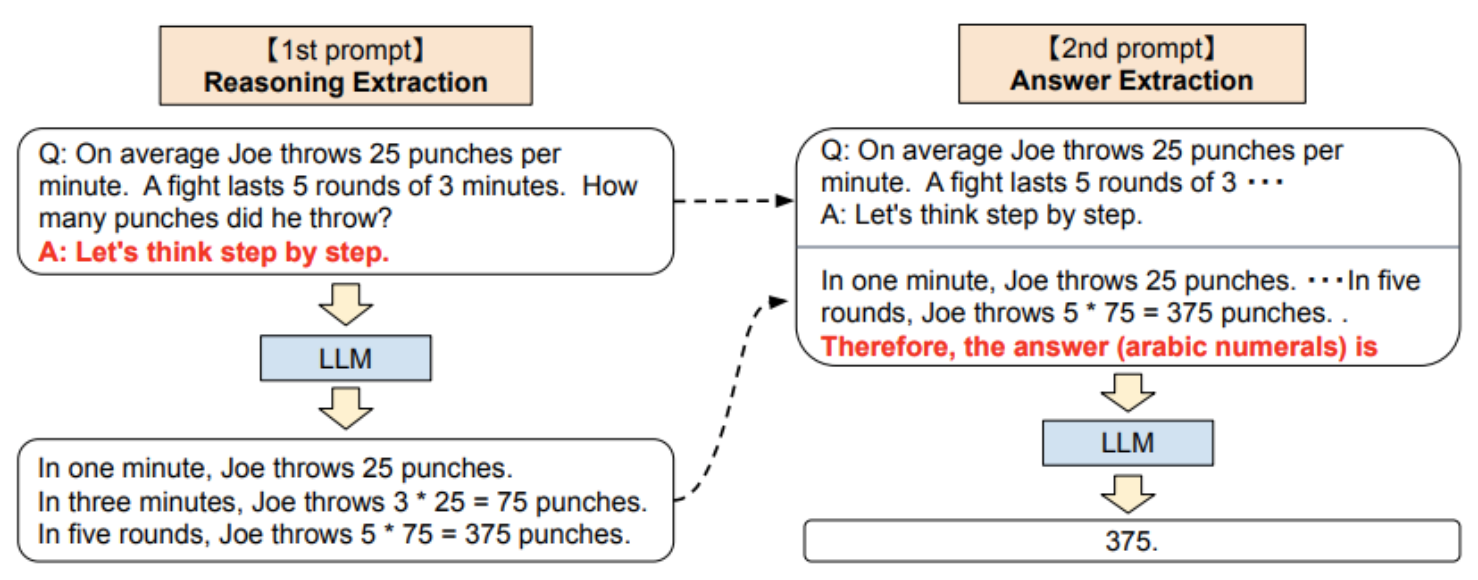
여기서 한발 더 나아간 방식이 zero-shot chain-of-thought로, llm 에서 inference 결과를 가져와 step by step 으로 제시한다.
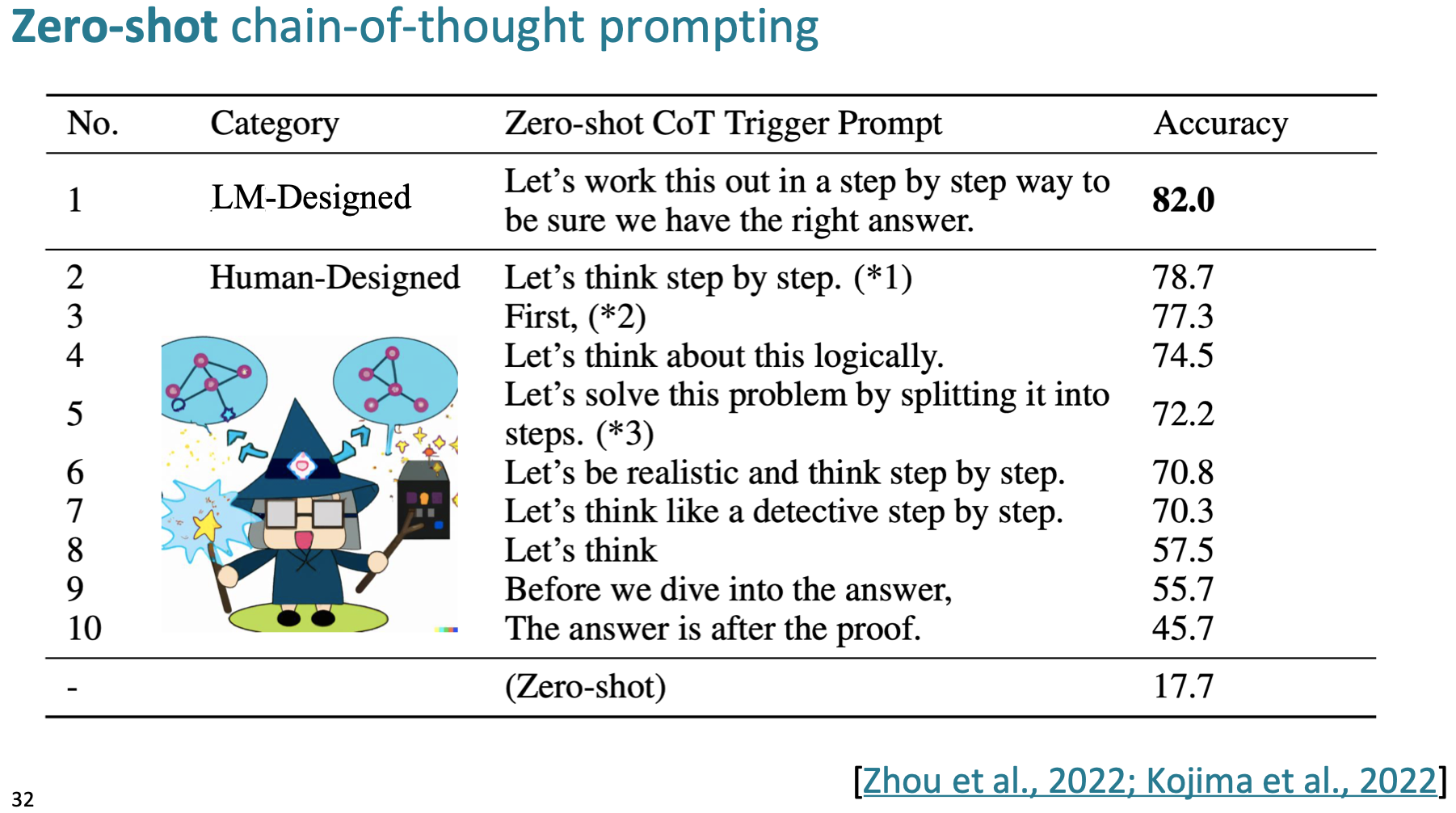
이 cot 를 유도하는 prompt 는 디게 다양하다.
Instruction Tuning 의 메인 키워드는 align 이다.
실제 사람은 이런 답변을 할 것이다.

하지만 gpt3 는 이런 답변을 하겠지.

이렇게 프롬프트의 의도와 다른 답을 하는 것을 막기 위해 instruction 과 output 데이터셋을 따로 학습시키는 것을 instruction finetuning 이라고 한다.
다양한 task 가 instruction 형태로 들어있다.
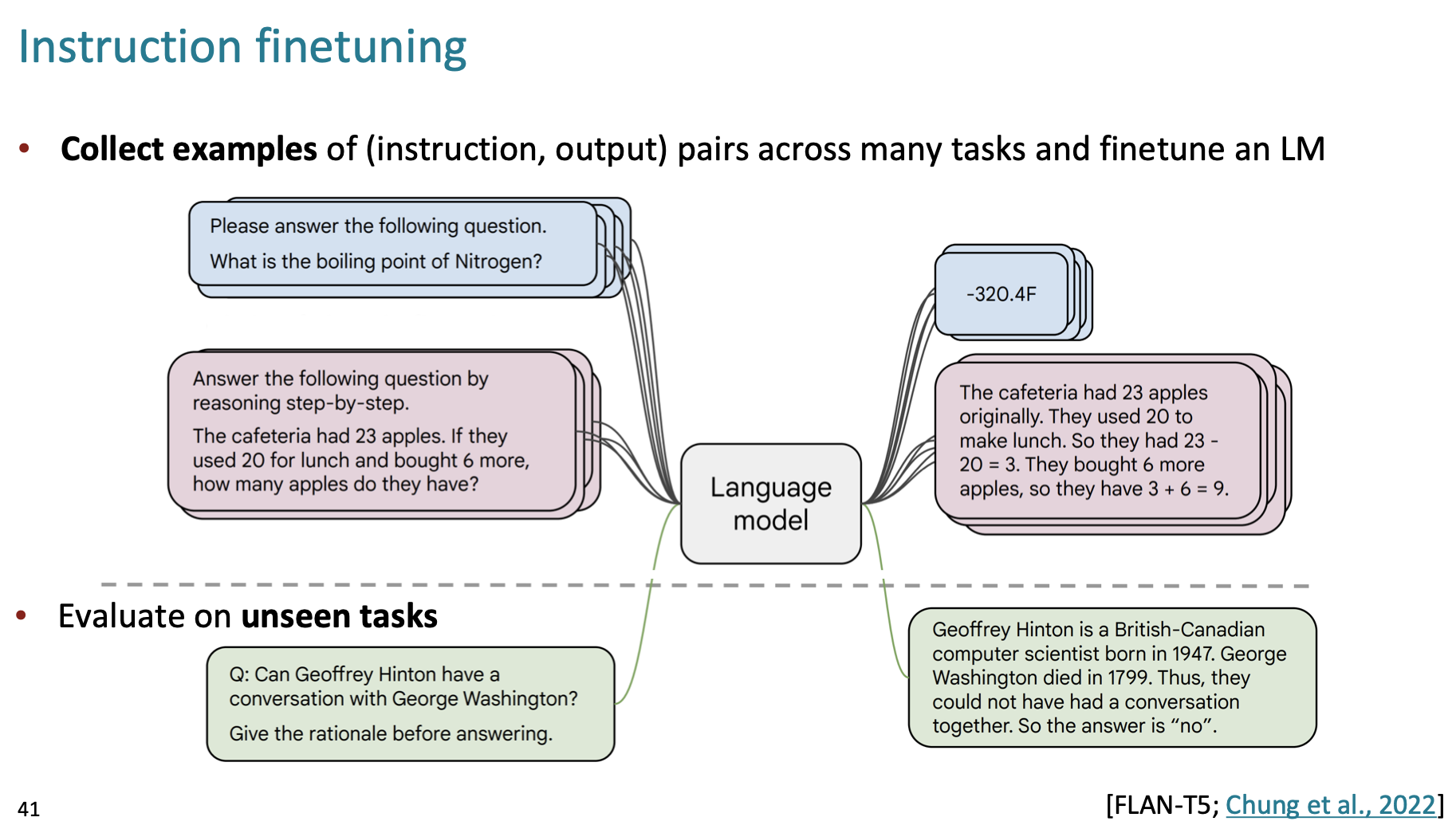
높은 성능 향상을 보일 수 있지만, task 가 많기 때문에 비용이 많이 들고, open-ended 문제에 대한 채점 기준이 모호하다. 등등 여러 단점도 있음.
이를 해결하기 위해 나오는 것이 RLHF 라고 하네요..다음 시간에~

CS undergraduate student, interested in ML, NLP, CV, RL, multi-modal AI