RLHF: RL을 이용하여 human feedback으로부터 LM을 optimize하는 방식
사람이 feedback 해서 performance 를 측정하는 것이 BLEU 나 ROUGE 보다 나을 수 있음
1) LM 을 pretrain! (사람이 직접 생성하거나 정제된 데이터셋을 이용해 fine-tuning 까지 한 모델 사용할 수도 있음)
2) 이 LM 을 통해 reward 모델을 학습
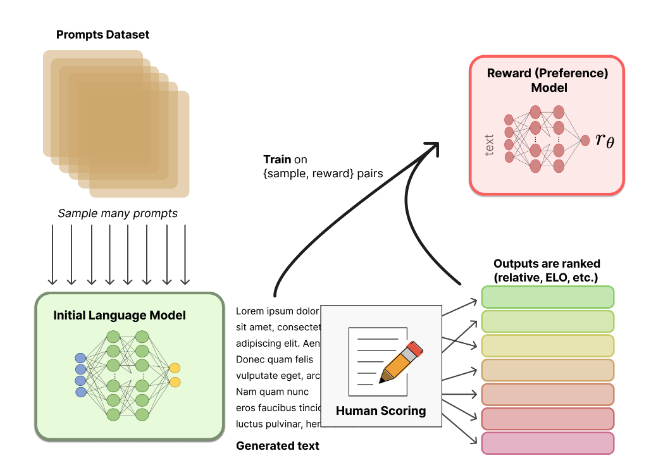
- 같은 query 에 대해 이 LM 을 이용해 k개의 output 을 generate 하고 그 중 human preference 에 따라 rank를 매김 (한 문장이 다른 문장보다 얼마나 좋은지 점수를 부여하는 건 주관적이고 어려울 수 있기 때문에 직접 점수를 매기지 않고 여러 모델에서 나온 text 간 비교를 한다. ex) 같은 prompt로 두 모델에서 나온 결과를 비교)
- LM의 모델 크기를 reward 모델도 어느정도 따라가야 함(중하위권 학생- 적은 parameter, 가르치고 평가하는 선생 - 뛰어나지 않아도 되는 작은 reward 모델)
- 이 데이터를 이용해 reward 모델을 학습, <query, generated_output>이 입력으로 주어졌을때, 모델이 생성한 generated_output에 대해 human scoring을 mimic할 수 있는 reward 결과를 부여
- PPO, LoRA 등으로 RL 기반 LM fine-tuning(최적화)
3) 이 reward model 을 기반으로 LM 을 fine-tuning 학습

CS undergraduate student, interested in ML, NLP, CV, RL, multi-modal AI