
🔎 문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
예제
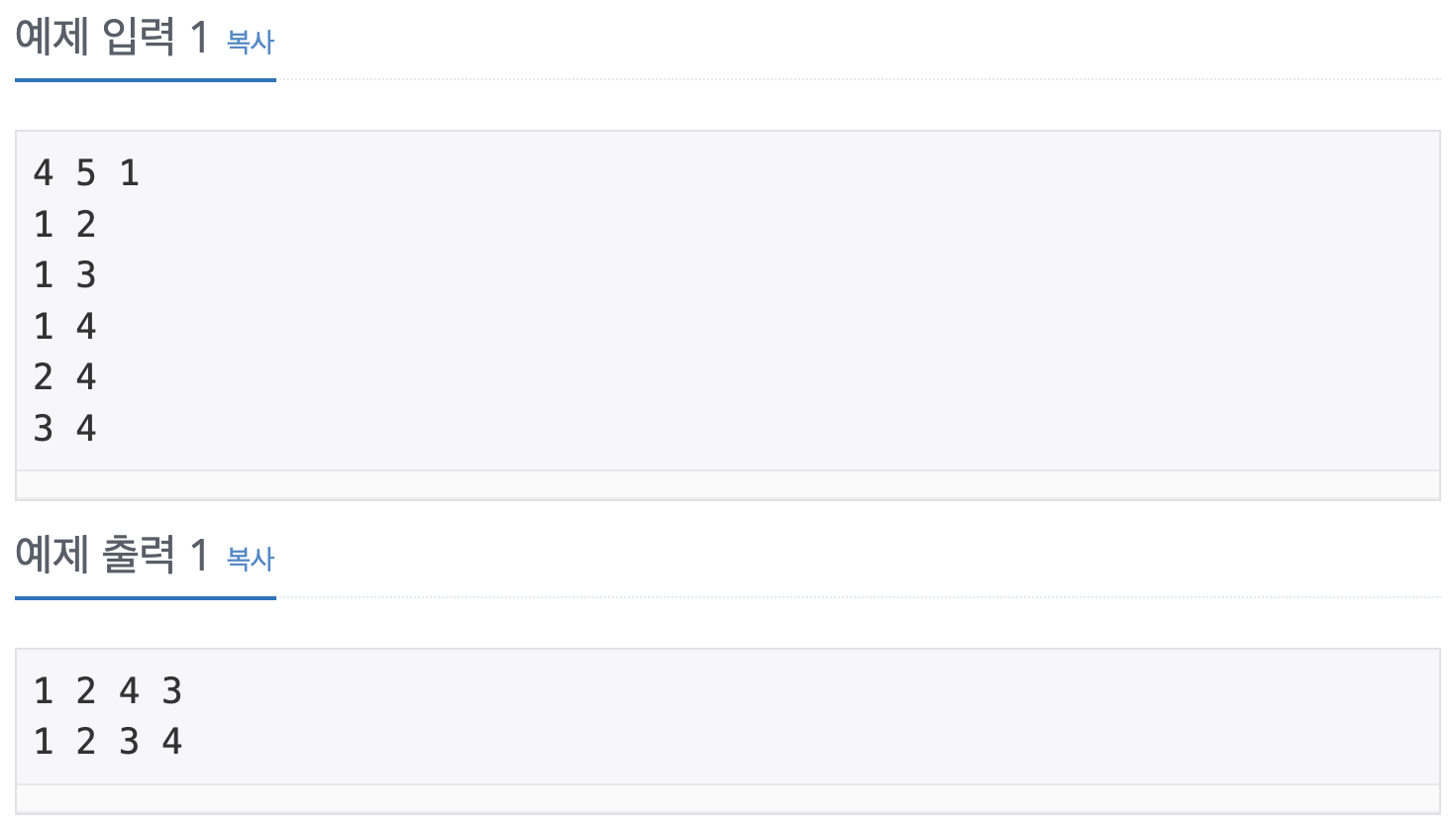

풀이1. 노드간 연결정보를 True/False로 설정해서 구현하는 방법
from collections import deque
n, m, v = map(int, input().split()) # 정점 개수, 간선 개수, 시작점 번호
graph = [[False]*(n+1) for _ in range(n+1)] # 각 정점의 연결정보를 표현할 2차원 리스트 생성(False로 초기화)
for _ in range(m):
a, b = map(int, input().split())
graph[a][b] = graph[b][a] = True # 정점 a와 b가 연결되어있다는 의미
visited_d = [False] * (n+1) # dfs의 방문기록
visited_b = [False] * (n+1) # bfs의 방문기록
def dfs(v):
visited_d[v] = True # 현재 노드 방문처리
print(v, end = " ") # 탐색 완료한 v노드 출력
for i in range(1, n+1):
if not visited_d[i] and graph[v][i]: # i번째 노드가 아직 방문하지 않은 v노드의 인접노드라면
dfs(i)
def bfs(v):
queue = deque([v]) # 큐 생성과 동시에 시작점 넣기
visited_b[v] = True # 방문처리
while queue :
v = queue.popleft() # 큐의 첫번째 원소 꺼내서 v에 지정
print(v, end = " ") # 탐색 완료한 v노드 출력
for i in range(1, n+1):
if not visited_b[i] and graph[v][i]: # i번째 노드가 아직 방문하지 않은 v노드의 인접노드라면
queue.append(i) # 큐에 해당 i번째 노드 추가하고
visited_b[i] = True # 방문처리
# 결과출력
dfs(v)
print()
bfs(v)4 5 1
1 2
1 3
1 4
2 4
3 4
1 2 4 3
1 2 3 4
풀이2. 정점 정보를 입력받고 해당 정점만 찾아가는 방법
인접한 노드 중에서 방문하지 않은 노드가 여러 개 있으면 번호가 낮은 순서부터 처리해야하기 때문에, 이 방법의 경우 dfs, bfs함수 호출 전에 그래프를 "오름차순 정렬"해야 한다.
from collections import deque
def dfs(v):
visited_d[v] = True # 방문처리
print(v, end = ' ') # 탐색 완료한 노드 번호 출력
for i in graph[v]: # 인접 노드들에 대해서
if not visited_d[i]: # 해당 i번째 노드가 방문하지 않은 노드라면
dfs(i) # 재귀호출(더 깊게 들어가서 탐색)
def bfs(v):
queue = deque([v]) # 큐 생성과 동시에 시작노드 추가
visited_b[v] = True # 방문처리
while queue: # 큐가 빌 때 까지 반복
v = queue.popleft() # v에 큐의 첫번째 요소 지정
print(v, end = ' ') # 탐색 완료한 노드 번호 출력
for i in graph[v]: # 인접 노드들에 대해서
if not visited_b[i]: # 해당 i번째 노드가 방문하지 않은 노드라면
queue.append(i) # 큐에 해당 i번째 노드 추가하고
visited_b[i] = True # 방문처리
n, m, v = map(int, input().split())
graph = [[] for _ in range(n+1)]
for _ in range(m):
a, b = map(int, input().split())
# 각 노드마다 연결된 노드를 정점 정보에 추가
graph[a].append(b)
graph[b].append(a)
for i in graph:
graph.sort() # 그래프 오름차순 정렬
visited_d = [False] * (n+1) # dfs의 방문 기록
visited_b = [False] * (n+1) # bfs의 방문 기록
dfs(v)
print()
bfs(v)4 5 1
1 2
1 3
1 4
2 4
3 4
1 2 4 3
1 2 3 4
✅ 정리
Q. 정점의 연결정보를 나타내는 2차원 리스트에서 왜 한 칸을 비우는걸까?
A. 정점의 번호는 1번부터 n번까지 인데, 인덱스는 0부터 시작하기 때문에 앞에 비어있는 한 칸(index[0])을 추가해서 리스트의 인덱스를 0부터 n까지 설정해줘야 한다.
Q. 풀이에서 사용한 방식의 작동 원리를 한 줄로 설명한다면?
A. 입력받은 노드의 개수(인덱스 0을 고려해서 n+1)만큼 2차원 리스트를 False(또는 0)으로 초기화한 후, 해당 노드가 인접한 노드라면 방문기록을True로 바꿔주는 원리로 구현했다.
Q. DFS와 BFS의 구현방식에 대한 차이는?
A. DFS(깊이 우선 탐색)는 재귀함수를 사용하여 함수 안에서 재귀적으로 답을 찾아가는 방식으로 구현한다면, BFS(너비 우선 탐색)는 큐(데크)에 인접노드를 저장해두고 반복문을 돌면서 답을 찾아가는 방식으로 구현한다.
Q. 결과 출력할 때
print(dfs(v), bfs(v))가 아니라
dfs(v)
print()
bfs(v)로 하는 이유는?
A. dfs(v)와 bfs(v) 각각이 탐색 완료한 노드를 출력할 때 print(v, end = ' ')로 공백을 기준으로 노드를 나열하고 있다. 때문에 전자와 같이 코드를 작성할 경우 정답은 공백을 기준으로 뒤에 이어서 출력된다. print()를 넣어줌으로써 줄바꿈으로 각 정답을 구분해주는 역할을 한다.
🔗 references
