1. K-means 클러스터링
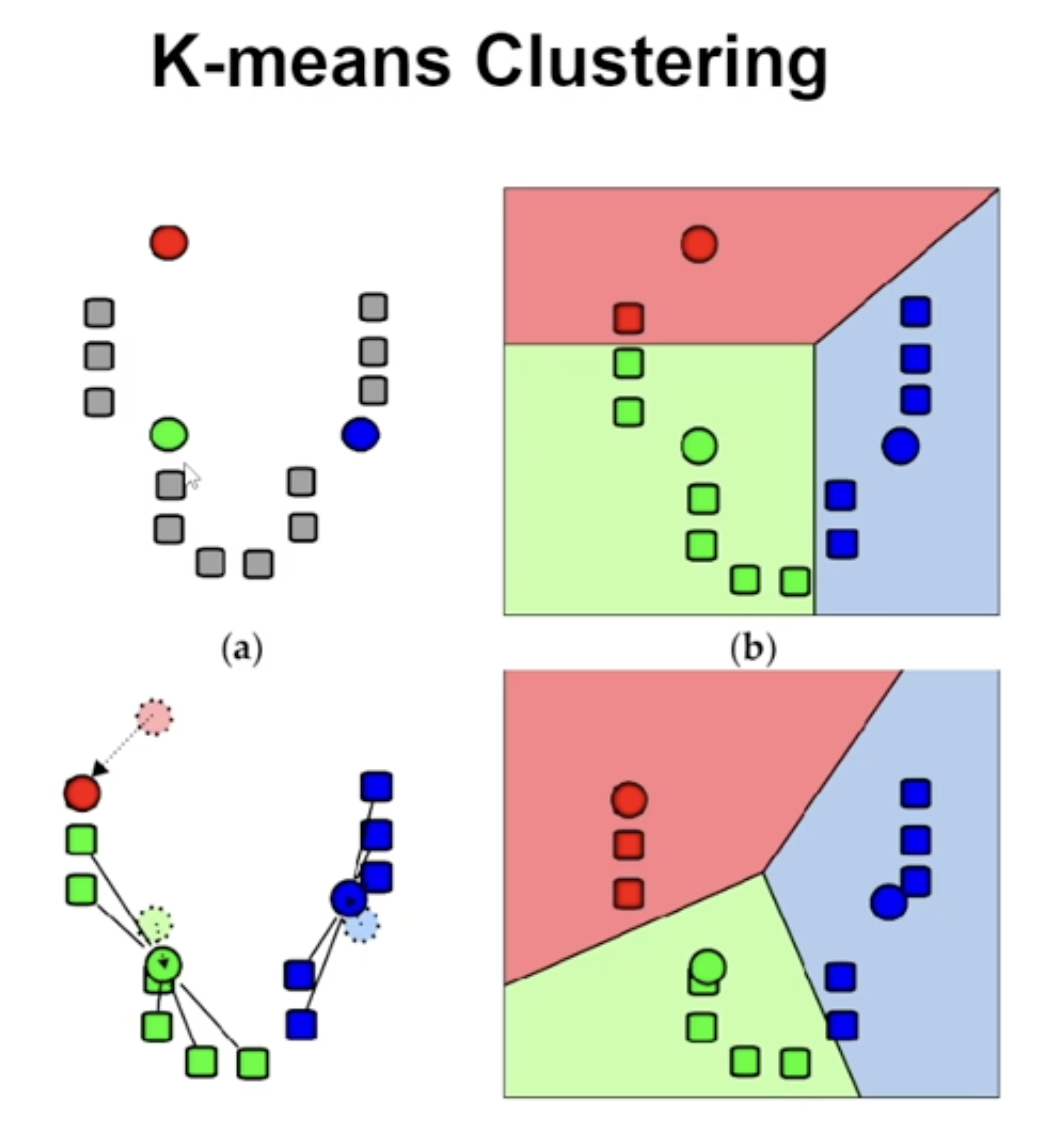
K-means 클러스터링은 비지도 학습 알고리즘 중 하나로, 주어진 데이터 집합 내에서 유사한 데이터 포인트들을 동일한 그룹으로 묶는 것이 목표이다.
비지도 학습은 데이터를 그룹화할 때 기존의 라벨 정보를 사용하지 않는다. 예를 들어, 빨간 점은 A 그룹, 초록 점은 B 그룹, 파란 점은 C 그룹이라는 라벨이 있는 상태에서 학습하는 것이 아니라, 데이터 포인트들이 빨간 점, 초록 점, 파란 점 근처에서 유사성을 기반으로 자연스럽게 그룹화되도록 하는 방식이다. 이렇게 라벨이 없는 상태에서 데이터의 패턴을 찾아 그룹을 할당하는 것이 비지도 학습의 핵심이다.
K-means 클러스터링 알고리즘은 다음과 같은 단계를 거쳐 데이터를 클러스터링한다.
1) 초기화:
- 사용자가 지정한 클러스터 개수
K만큼 임의의 중심점을 선택한다. 이 중심점들은 클러스터의 초기 중심점(centroid)으로 작용한다.
2) 할당 단계:
- 각 데이터 포인트를 가장 가까운 중심점에 할당하여 클러스터를 형성한다. 가장 가까운 중심점은 유클리드 거리나 다른 거리 측정 방법을 사용하여 계산된다.
3) 업데이트 단계:
- 각 클러스터에 속한 데이터 포인트들의 평균을 계산하여 새로운 중심점을 업데이트한다.
4) 반복:
- 할당 단계와 업데이트 단계를 중심점이 수렴할 때까지 반복한다. 중심점이 수렴한다는 것은 중심점의 위치가 더 이상 크게 변하지 않음을 의미한다.
이 과정을 통해 K-means 클러스터링 알고리즘은 주어진 데이터 집합을 K개의 클러스터로 나누게 된다.
# CLTV 기반 클러스터링
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 스케일링
scaler = StandardScaler()
df_cluster_scaled = scaler.fit_transform(df_cluster)
# 학습
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(df_cluster_scaled)
df_cluster['Cluster'] = kmeans.labels_ # 각 행별 결과값들 레이블
거북선통통통통