Q20. 데이터 로드하기
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl)
type(df)df.head()
# head(): DataFrame에서 처음 5개의 행 가져오기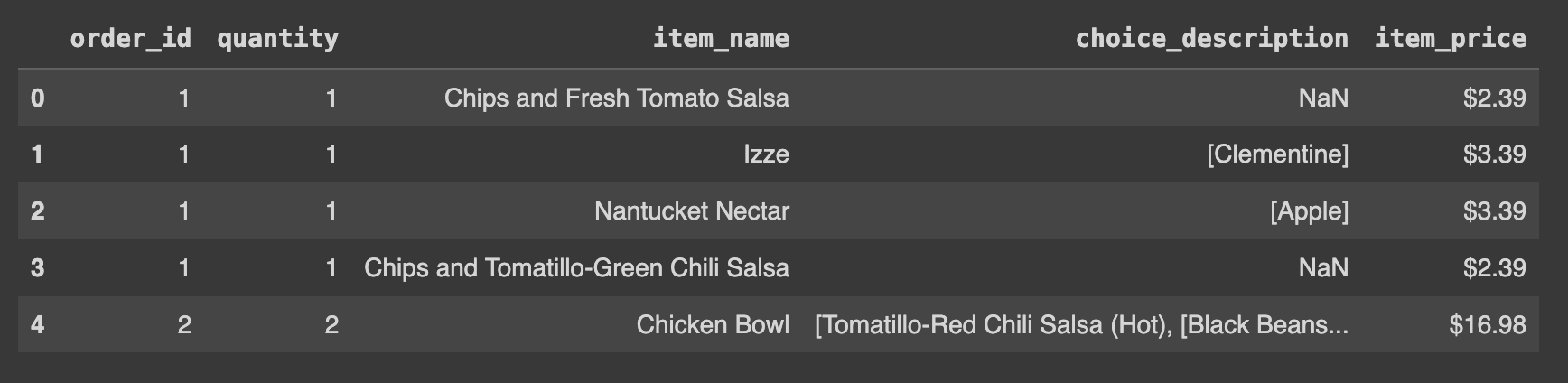
Q21. 특정 column 값이 3인 데이터를 추출하여 첫 5행 출력하기
df[df['quantity']==3].head()DataFrame(df)에서 특정 값이 df['column_이름']==3을 만족하는 행들을 선택하여 처음 5개의 행을 가져오겠다는 의미이다.
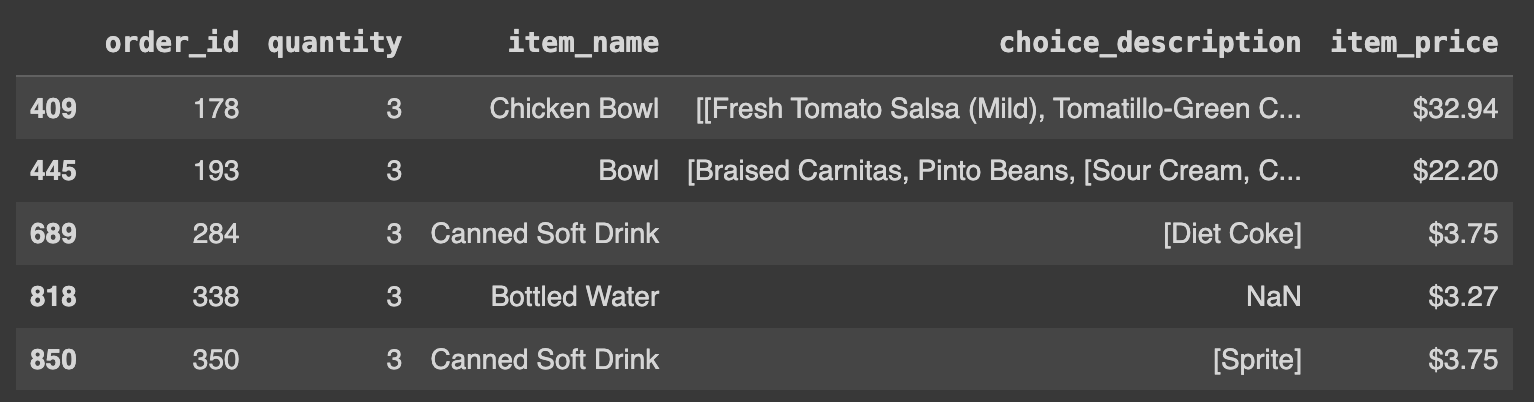
Python에서는
같다는=가 아닌 같다 기호 (==)를 쓴다.
Q22. 특정 column 값이 3인 데이터를 추출하여 index를 0부터 정렬하고 첫 5행 출력하기
df.loc[df['quantity']==3].head().reset_index(drop=True)
# reset_index(): 기존의 인덱스가 새로운 column으로 선언
# reset_index(drop=True): 선택한 행들의 인덱스를 재설정하고, 기존의 인덱스 삭제reset_index() 함수를 사용하지 않았을 때:
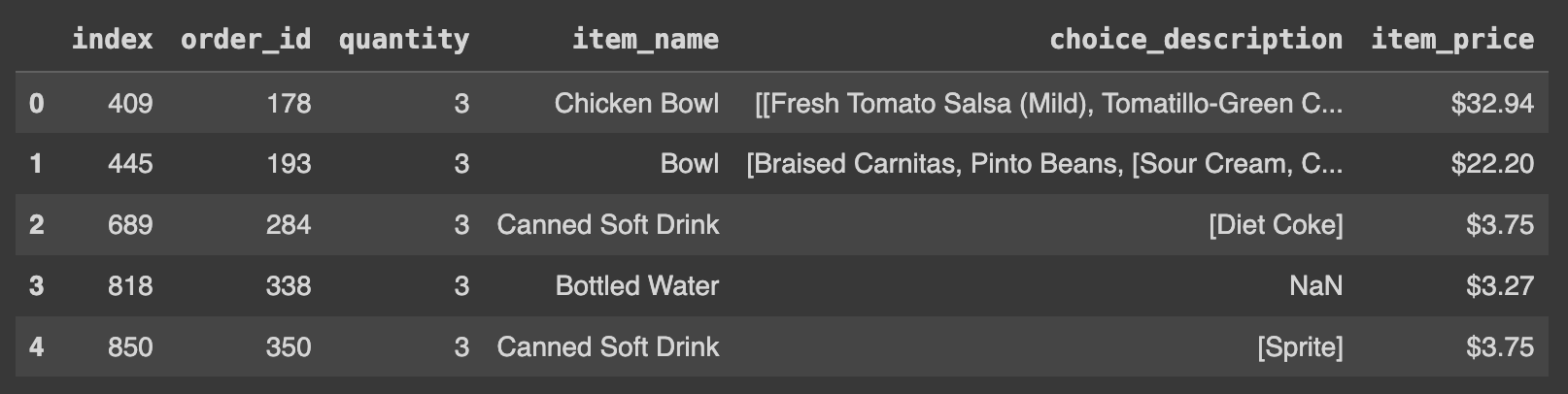
reset_index() 함수를 사용했을 때:
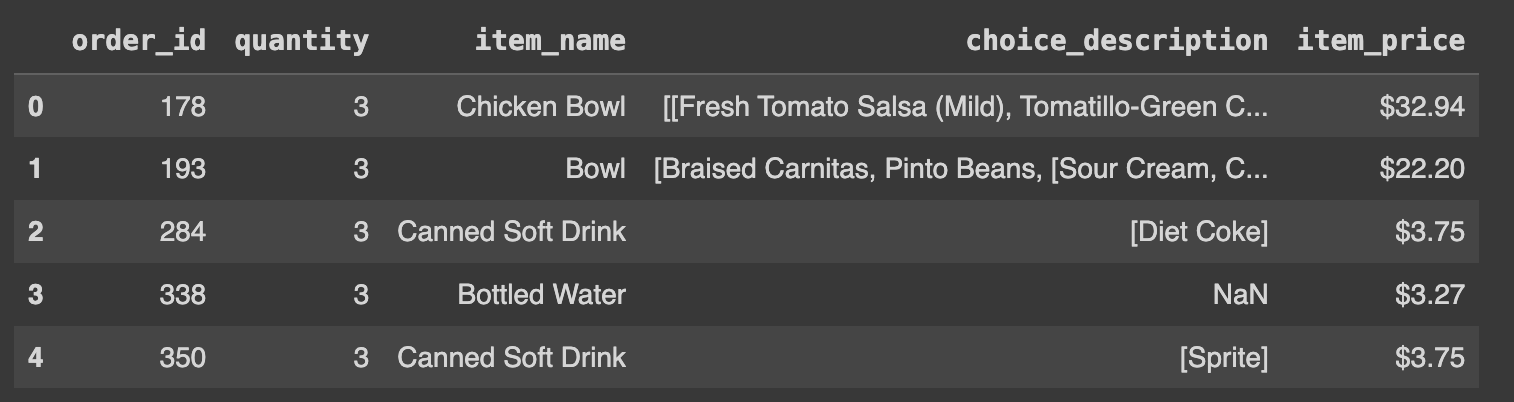
drop=True 옵션은 reset_index() 함수를 사용할 때, 기존의 인덱스를 새로운 열로 추가하지 않고 제거하도록 지시하는 것이다. 따라서 이 옵션을 사용하면 기존의 인덱스가 새로운 열로 추가되지 않고 제거된다. 이렇게 하면 불필요한 인덱스 열을 유지하지 않아도 되므로 데이터프레임이 깔끔해지게 된다.
Q23. 두 개의 특정 컬럼으로 구성된 새로운 DataFrame 정의하기
df[['quantity','item_price']]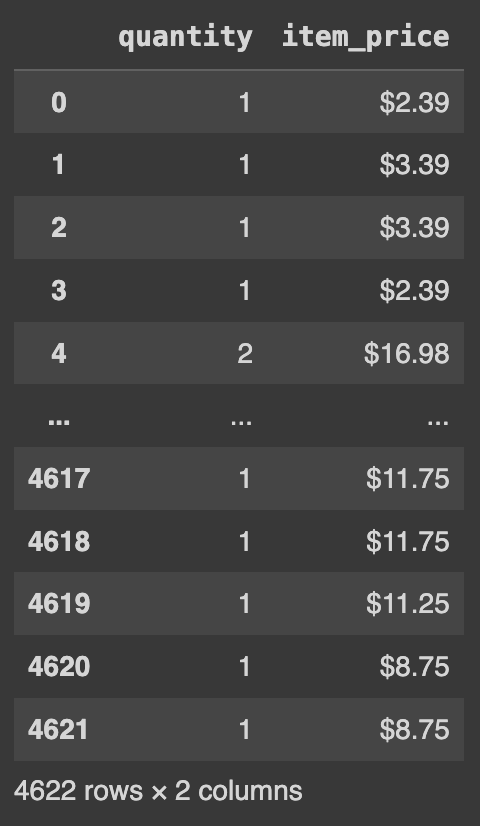
2개의 컬럼을 불러올때는 대괄호 [ ]로 안쪽에 묶어서 컬럼을 정리하고 대괄호 [ ]를 한번 더 묶으면 해당 컬럼만 출력하라는 의미이다.
새로운 DataFrame으로 정의하기 위해서는 위에서 쓰던 df가 아닌 다른 DataFrame(e.g., df2)을 써야한다.
df2 = df[['quantity','item_price']]
df2.head()여기서 d2는 quantity와 item_price라는 두개의 컬럼만 구성된 새로운 DataFrame이 만들어진다.
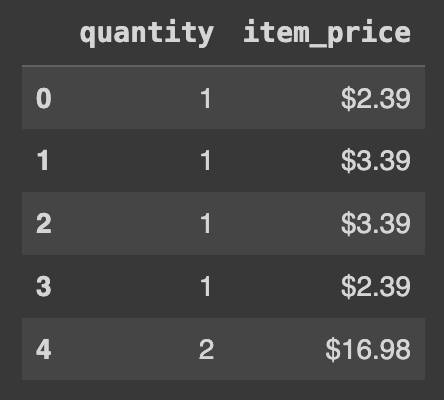
Q24. 특정 컬럼의 달러($)표시 문자 제거하고 float 타입으로 저장하여 새로운 컬럼(파생변수)에 저장하기
# 'item_price' 열의 각 값에서 달러 표시(첫 번째 문자)를 제거한 새로운 문자열 반환
df['item_price'].str[1:]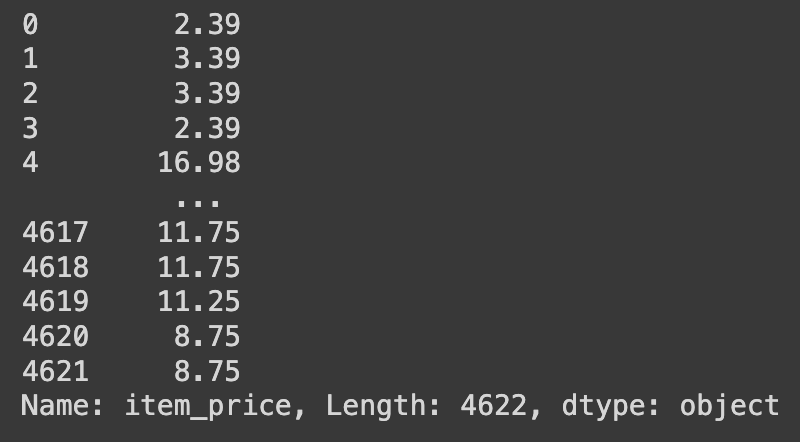
예를 들어, 'item_price' 열의 값이 "$10.99"라면, 위 코드를 적용하면 "10.99"가 반환된다.
# 'item_price' 열의 각 값에서 0번째 인덱스부터 시작하여 모든 문자 반환
df['item_price'].str[0:]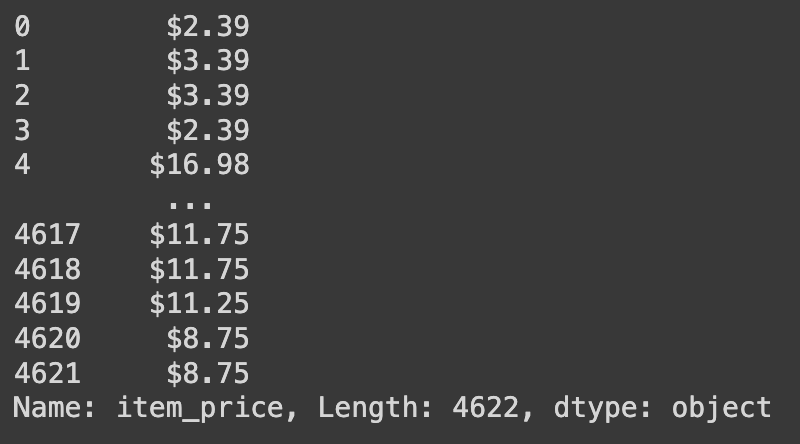
예를 들어, 'item_price' 열의 값이 "$10.99"라면, 위 코드를 적용하더라도 "$10.99"가 그대로 반환된다.
# 'item_price' 열의 각 값에서 0번째 인덱스부터 1번째 인덱스 전까지(즉, 첫 번째 문자) 반환
df['item_price'].str[0:1]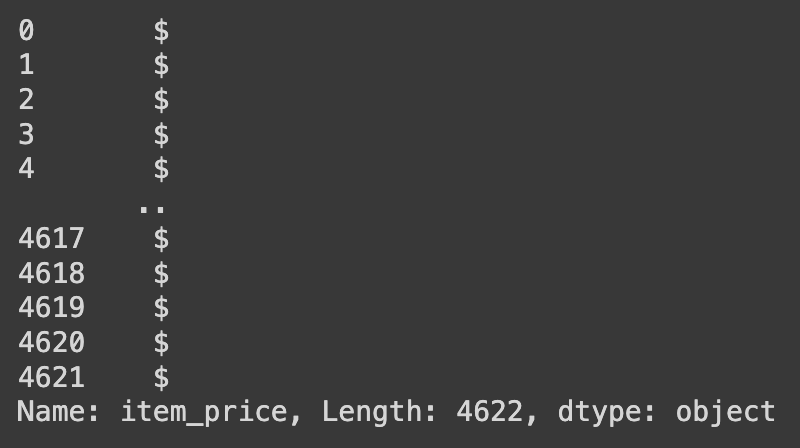
# 'item_price' 열의 각 값에서 0번째 인덱스부터 2번째 인덱스 전까지(즉, 첫 번째 문자부터 두 번째 문자까지) 반환
df['item_price'].str[0:2]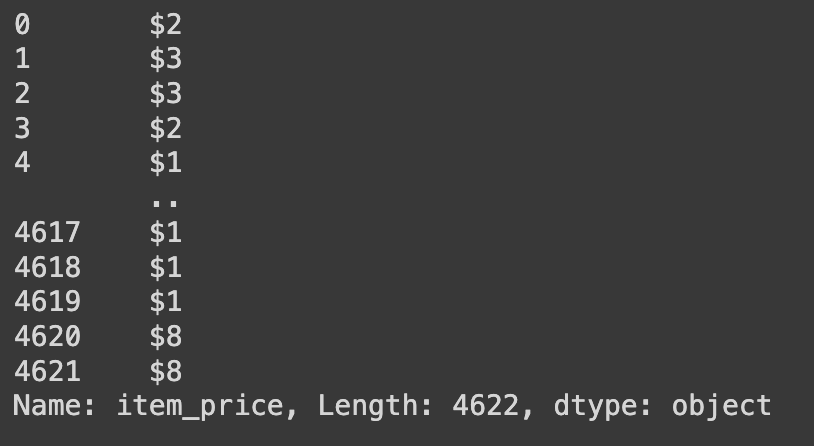
# 'item_price' 열에서 달러 표시를 제거한 후에 남은 문자열을 실수형(float)으로 변환하여 'new_price'라는 새로운 컬럼에 할당, 'new_price' 컬럼의 처음 5개의 값을 'Ans' 변수에 할당
df['new_price'] = df['item_price'].str[1:].astype('float')
Ans = df['new_price'].head()
Ans
# astype('float'): 실수형(float)으로 변환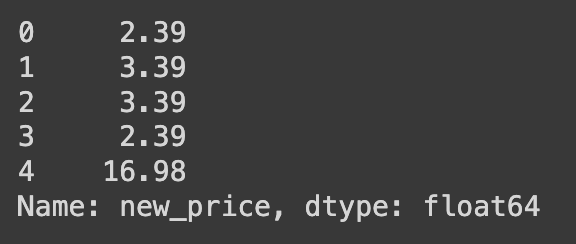
Q25. 특정 컬럼이 5이하의 값을 가지는 데이터프레임을 추출하고, 전체 갯수 구하기
# 'new_price' 열에서 값이 5 이하인 행들의 개수를 세어서 결과값 반환
len(df[df['new_price'] <=5])
# len(): 생성된 새로운 DataFrame의 길이(행의 개수) 계산
# 결과값:
# 1652Q26. item_name명이 Chicken Salad Bowl 인 데이터 프레임을 추출하고 index 값 초기화 하기
# 'item_name' 열 값이 'Chicken Salad Bowl'인 행들을 추출한 후에, 인덱스 값을 초기화
df.loc[df.item_name =='Chicken Salad Bowl'].reset_index(drop=True)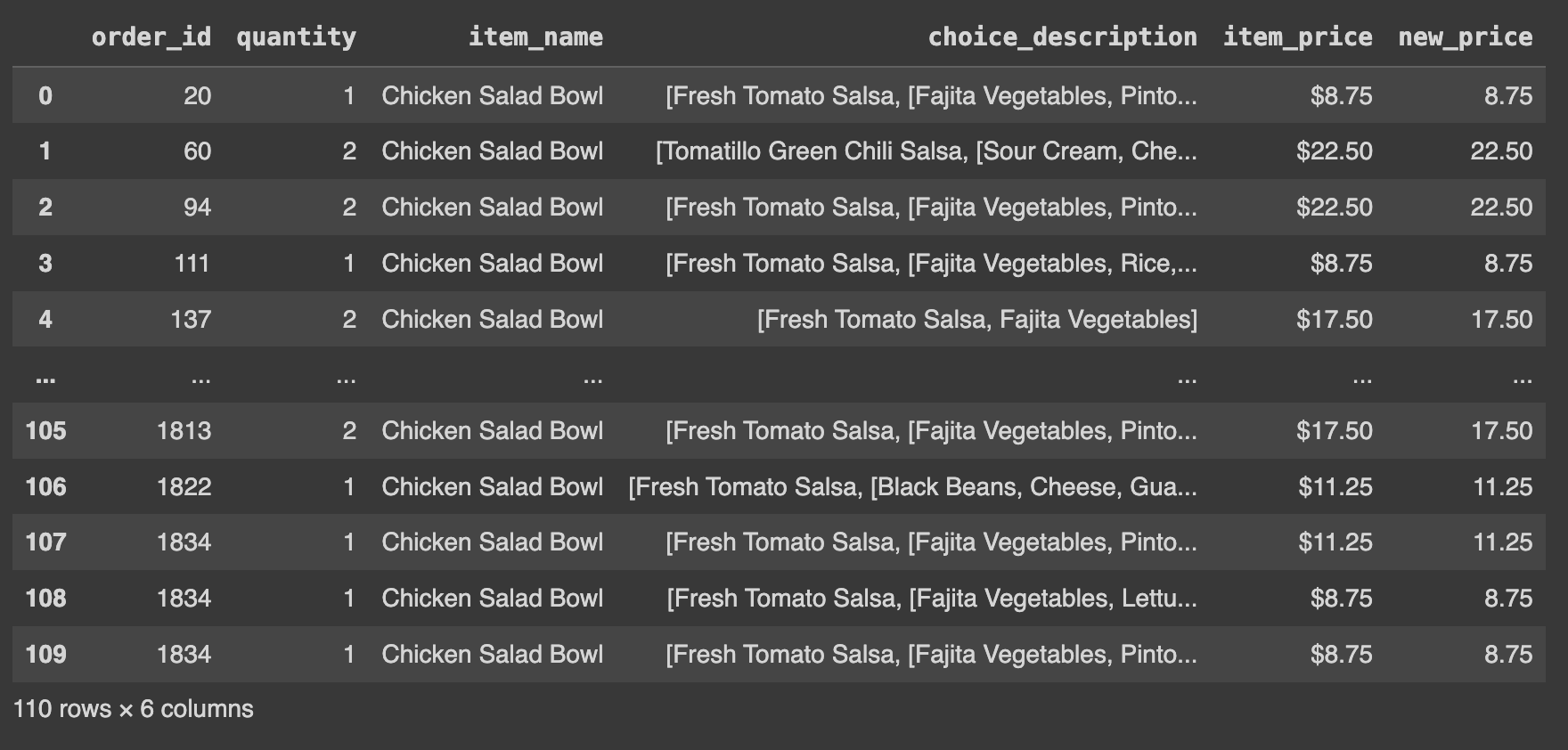
조건을 만족하는 데이터를 가져올 때 df[df['new_price']] 또는 df.loc[df.item_name]라고 사용해도 된다.
iloc는 순서 또는 위치 기반의 인덱싱(indexing) 하는 기법이다. (예시: `df.iloc[0]는 첫 번째 행 선택)loc는 값 기준으로 인덱싱(indexing) 하는 기법이다. (예시:df.loc[0]은 인덱스가 0인 행 선택)
여기서 잠깐 타임!
아래 두 코드 다 동일한 방법이다.
df['new_price'] # `대괄호 [ ]`로 묶어서 '따옴표' 안에 값을 넣어주는 방법 df.item_name # `점(.)`을 기준으로 컬럼 값을 바로 적는 방법한가지 주의사항으로 컬럼 값이 공백이 있을 경우 (예: new price), 위의 기능으로 불러올 수 없다.
- 공백이 있을 경우,
df['new price']를 사용 해야한다.- 공백이 없는 경우,
df['new_price'],df.item_name처럼 둘 다 사용 가능하다.
Q27. new_price 값이 9 이하이고 item_name 값이 Chicken Salad Bowl인 데이터프레임 추출하기
Ans = df.loc[(df.item_name =='Chicken Salad Bowl') & (df.new_price <= 9)]
Ans.head()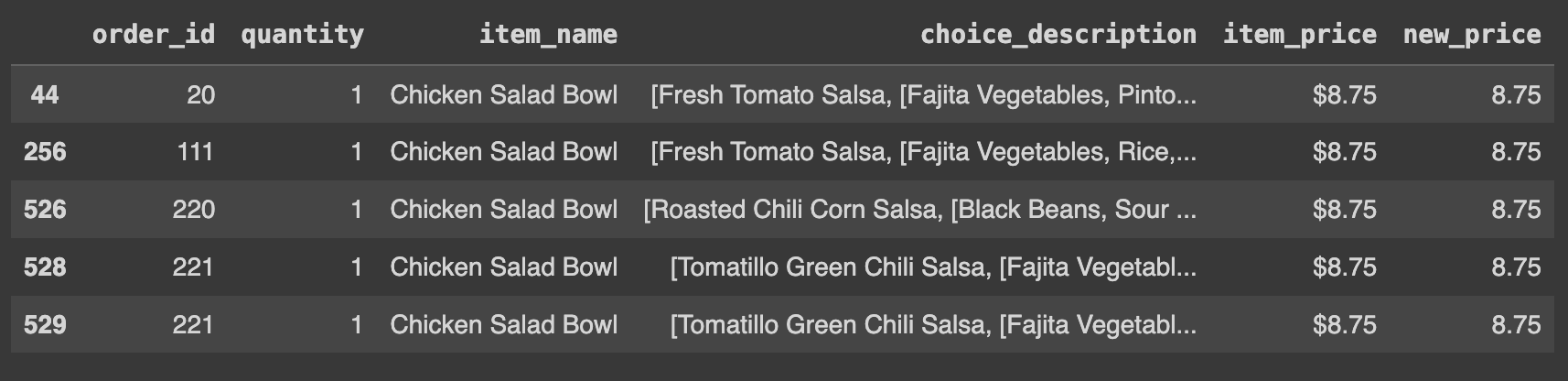
두 가지 이상의 조건을 만족하려고 하면 각 조건을 괄호 ( )로 묶어줘야한다. 두 조건을 동시에 만족해야하면 조건 연산자 &(and)를 사용해야한다.
Python에서는 논리 연산자 'and'를
&로 표시한다
Q28. df의 new_price 컬럼 값에 따라 오름차순으로 정리하고 index 초기화 하기
Ans = df.sort_values('new_price').reset_index(drop=True)
Ans.head()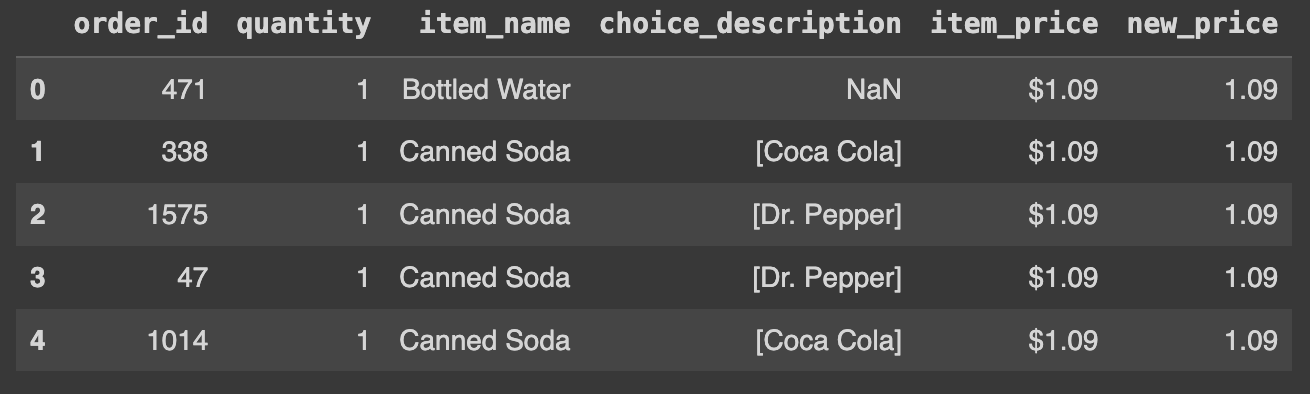
sort_values() 메서드를 사용하여 데이터프레임을 정렬할 수 있다. 이 메서드는 정렬 기준이 되는 열의 값을 인자로 받는다.
기본적으로 sort_values() 메서드를 사용할 때는 오름차순으로 정렬이 이루어진다. 따라서 추가적인 옵션을 지정하지 않으면 오름차순으로 정렬된다.
예를 들어, 'col_name' 열을 기준으로 데이터프레임을 오름차순으로 정렬하는 경우:
df.sort_values(by='col_name')내림차순으로 정렬하려면 ascending=False 옵션을 추가한다.
df.sort_values(by='col_name', ascending=False)하지만 기본적으로 오름차순으로 정렬되므로, 옵션을 할당할 필요가 없다.
Q29. df의 item_name 컬럼 값 중 Chips 포함하는 경우의 데이터 출력하기
# 'item_name' 열의 값 중에서 특정 문자열('Chips')을 포함하는 행들을 추출
Ans = df.loc[df.item_name.str.contains('Chips')]
Ans.head()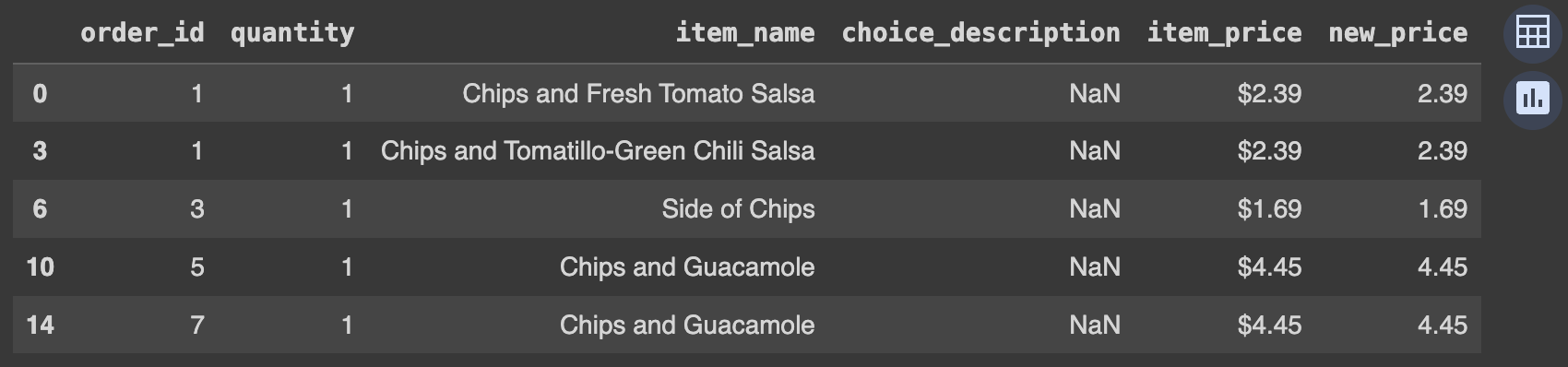
위 26번과 27번 문제들은 item_name 중 chicken salad bowl의 full name을 추출하였지만 해당 문제는 'item_name' 열의 값 중에서 'Chips'라는 문자열을 포함하는 행들을 추출하기 때문에 str.cotntains() 명령어를 사용해야 한다.
Q30. df의 짝수 번째 컬럼만을 포함하는 데이터프레임 출력하기
Ans = df.iloc[:,::2]
Ans.head(5)
# [:, ::2]: 모든 행(`:`)을 선택하고, 짝수 번째 열(`::2`)을 선택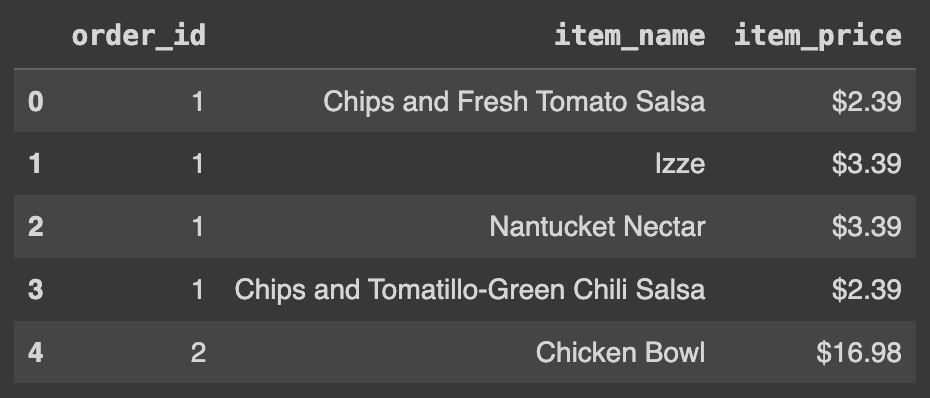
::2옵션은 짝수 번째 열만 선택한다.
Q31. df의 new_price 컬럼 값에 따라 내림차순으로 정리하고 index를 초기화하기
Ans = df.sort_values('new_price', ascending=False).reset_index(drop=True)
Ans.head()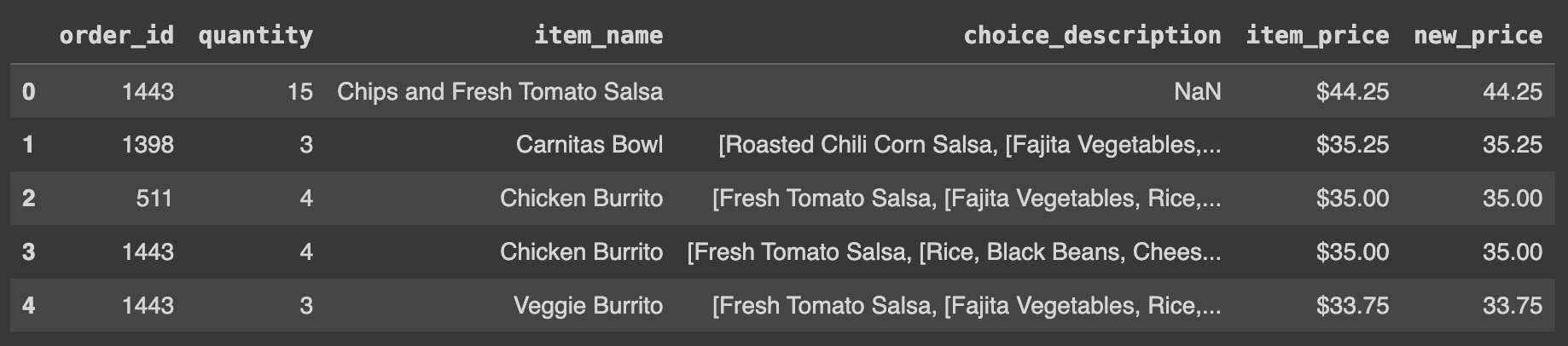
reset_index(drop=True) 명령어 불포함:
Ans = df.sort_values('new_price', ascending=False)
Ans.head()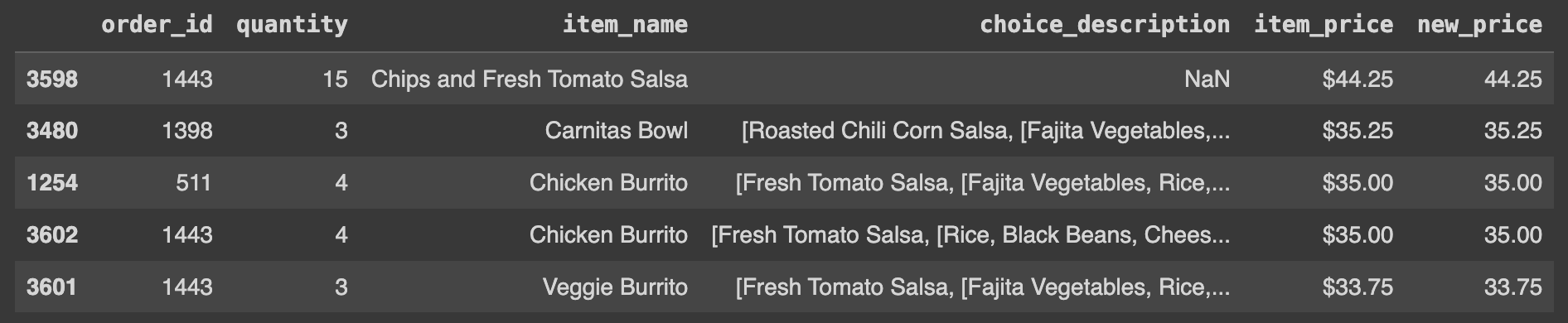
reset_index(drop=True) 명령어를 사용하지 않으면 위의 이미지와 같이 정렬된 데이터프레임의 인덱스가 이전의 순서를 유지하게 된다. 이로 인해 인덱스가 뒤죽박죽이 되어 데이터를 읽기가 불편해진다.
올바른 방법은 reset_index(drop=True) 명령어를 사용하여 인덱스를 재설정하여 데이터프레임의 인덱스가 0부터 시작하게 하는 것이다. 이렇게 하면 데이터를 더 쉽게 읽고 이해할 수 있다.
Q32. df의 item_name 컬럼 값이 Steak Salad 또는 Bowl인 데이터 인덱싱하기
Ans = df.loc[(df.item_name =='Steak Salad') | (df.item_name =='Bowl')]
Ans.head()
아래와 같이 loc를 쓰지 않아도 모두 동일한 결과를 반환한다.
Ans = df[(df.item_name =='Steak Salad') | (df.item_name =='Bowl')]
Ans.head()
데이터 인덱싱하기 = 데이터 찾기
데이터프레임에서 특정 조건을 만족하는 행을 선택할 때,or 조건을 나타내는|를 사용한다.
Q33. df의 item_name 컬럼 값이 Steak Salad 또는 Bowl 인 데이터를 데이터 프레임화 한 후, item_name를 기준으로 중복행이 있으면 제거하되 첫번째 케이스만 남기기
문제에서 첫번째 케이스만 남기기라는 의미는 테이블에서 'item_name' 열 중 첫번째 데이터와 세번째 데이터가 같을 시 첫번째 데이터는 남기고, 세번째 데이터는 제거하는 것이다.
Ans = df.loc[(df.item_name == 'Steak Salad') | (df.item_name == 'Bowl')]
Ans = Ans.drop_duplicates('item_name')
Ans.head()
# drop_duplicates(): 특정 열의 값이 중복되는 경우에는 첫 번째 케이스만 남기기
아래와 같이 loc를 쓰지 않아도 모두 동일한 결과를 반환한다.
Ans = df[(df.item_name == 'Steak Salad') | (df.item_name == 'Bowl')]
Ans = Ans.drop_duplicates('item_name')
Ans.head()
Q35. df의 데이터 중 new_price값이 new_price값의 평균값 이상을 가지는 데이터들을 인덱싱하기
Python에서 데이터의 평균을 계산할 때는
mean()메서드를 사용한다.
df.new_price.mean()
# 결과값:
# 7.464335785374297Ans = df[df.new_price >= df.new_price.mean()]
Ans.head()
Q36. df의 데이터 중 item_name의 값이 Izze 데이터를 Fizzy Lizzy로 수정하기
# 'item_name' 열 값이 'Izze'인 행을 선택하여 해당 행의 'item_name' 열에 접근하여 'item_name' 값을 'Fizzy Lizzy'로 수정
df.loc[df.item_name == 'Izze', 'item_name'] = 'Fizzy Lizzy'
Ans = df
Ans.head()
iloc는 인덱스의 순서를 기반으로 행과 열을 선택하는 데 사용되며,loc는 행 및 열의 라벨을 기반으로 데이터를 선택하는 데 사용된다.
따라서 데이터프레임에서 단일 조건을 만족하는 특정 행을 선택할 때는 iloc나 loc를 모두 사용할 수 있다. 하지만 행과 열에 대해 독립적으로 sorting 및 filtering을 할 때는 loc를 사용하는 것이 좋다.
loc를 사용할 때는 행과 열을 선택하여 데이터를 가져올 수 있다. 이때 행과 열은 각각 인덱스 이름이나 라벨을 사용하여 지정한다.
loc[행,열]
# [행, 열]: 각각 해당 행과 열의 인덱스 이름이나 라벨을 의미loc를 사용하지 않고 데이터프레임에서 특정 조건을 만족하는 특정 열을 선택하려면 다음과 같이 사용할 수 있다.
df[df.item_name == 'Izze']['item_name']
loc를 사용하여 데이터프레임에서 특정 조건을 만족하는 특정 열을 선택할 때는 다음과 같이 사용한다.
df.loc[df.item_name == 'Izze', 'item_name']
Q37. df의 데이터 중 choice_description 값이 NaN 인 데이터의 갯수 구하기
df.choice_description.isnull().sum()
# isnull(): 각 행이 null 값인지 여부 확인 (null 값인 경우 True 반환, 그렇지 않은 경우 False 반환)
# sum(): True 값을 1로, False 값을 0으로 간주하여 해당 열에서의 True의 개수 합산
# 결과값:
# 1246Q38. df의 데이터 중 choice_description 값이 NaN 인 데이터를 NoData 값으로 대체하기(loc 이용)
# 데이터프레임에서 'choice_description' 열의 값이 null인 경우를 찾아서 해당 값을 'NoData'로 대체
df.loc[df.choice_description.isnull(),'choice_description'] = 'NoData'
Ans = df
Ans.head()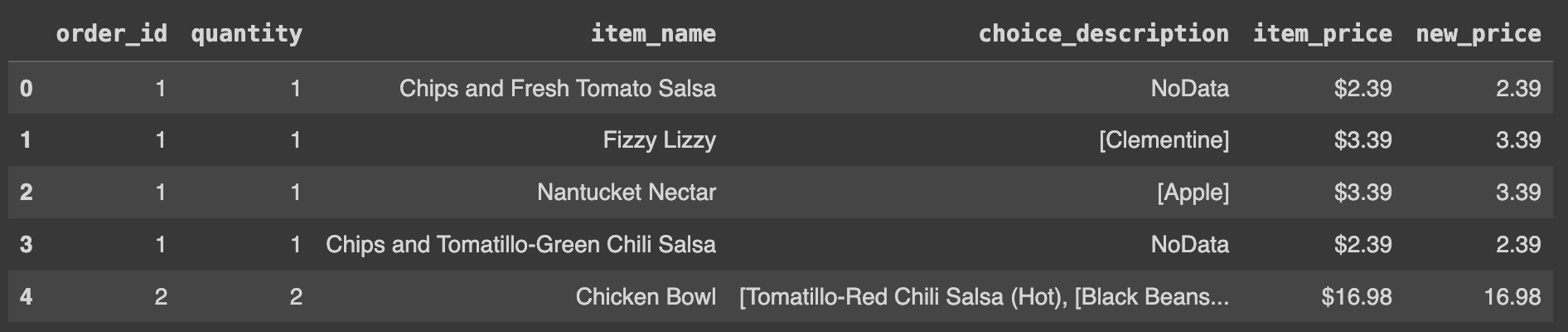
Q39. df의 데이터 중 choice_description 값에 Black이 들어가는 경우 인덱싱하기
# 데이터프레임에서 'choice_description' 열의 값 중에 'Black'이 포함된 행들 선택
Ans = df[df.choice_description.str.contains('Black')]
Ans.head()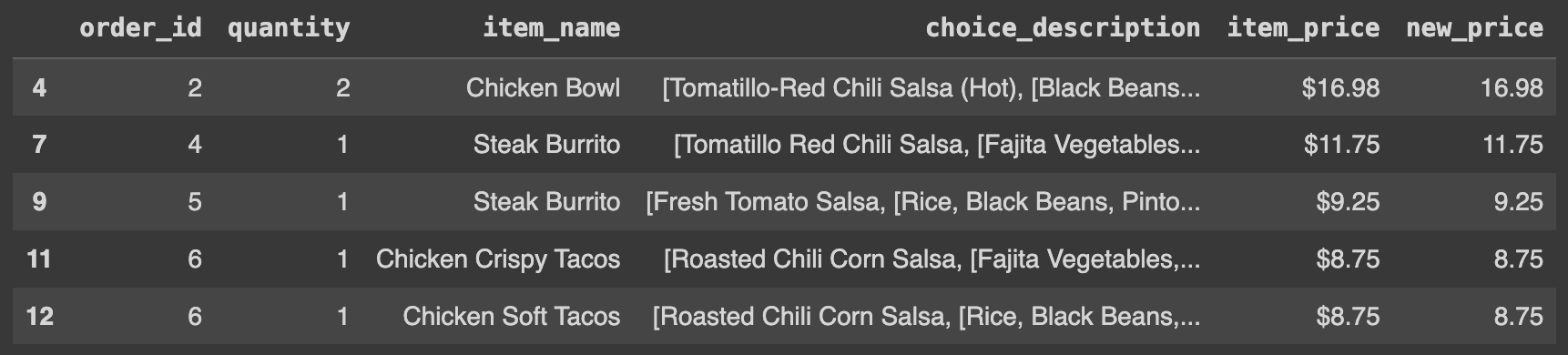
하나씩 검증해보는 방법은 아래와 같다.
# 데이터프레임에서 선택된 'choice_description' 열의 첫 번째 행을 리스트로 변환하여 출력
list(Ans['choice_description'])[0]
# 결과값:
# [Tomatillo-Red Chili Salsa (Hot), [Black Beans, Rice, Cheese, Sour Cream]]# 데이터프레임에서 선택된 'choice_description' 열의 두 번째 행을 리스트로 변환하여 출력
list(Ans['choice_description'])[1]
# 결과값:
# [Tomatillo Red Chili Salsa, [Fajita Vegetables, Black Beans, Pinto Beans, Cheese, Sour Cream, Guacamole, Lettuce]]Q40. df의 데이터 중 choice_description 값에 Vegetables 들어가지 않는 경우의 갯수 출력하기
Python에서는 Not 조건을 나타내기 위해
~기호를 사용한다.
# 데이터프레임에서 'choice_description' 열의 값 중에서 'Vegitables'를 포함하지 않는 행의 개수 계산
Ans = len(df.loc[~df.choice_description.str.contains('Vegitables')])
Ans
# 결과값:
# 3900Q41. df의 데이터 중 item_name 값이 N으로 시작하는 데이터 모두 추출하기
# 데이터프레임에서 'item_name' 열의 값이 'N'으로 시작하는 행들 선택
Ans = df[df.item_name.str.startswith('N')]
Ans.head()
# str.startswith(): ~으로 시작하는지 여부 확인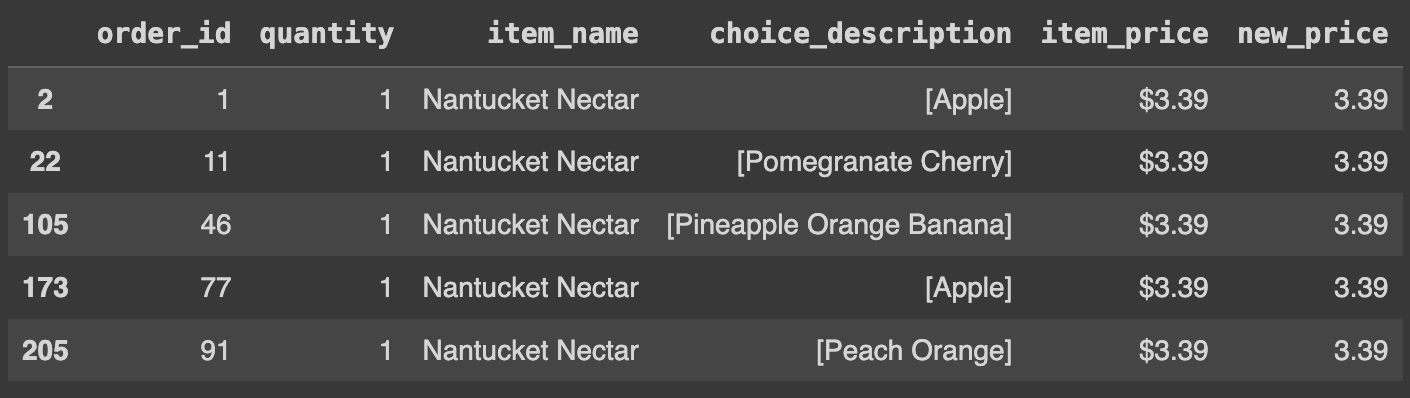
Q42. df의 데이터 중 item_name 값의 단어갯수가 15개 이상인 데이터를 인덱싱하기
# 데이터프레임의 'item_name' 열의 각 값에 대해 문자열의 길이 계산
df.item_name.str.len()
# str.len(): 각 값에 대해 문자열의 길이를 계산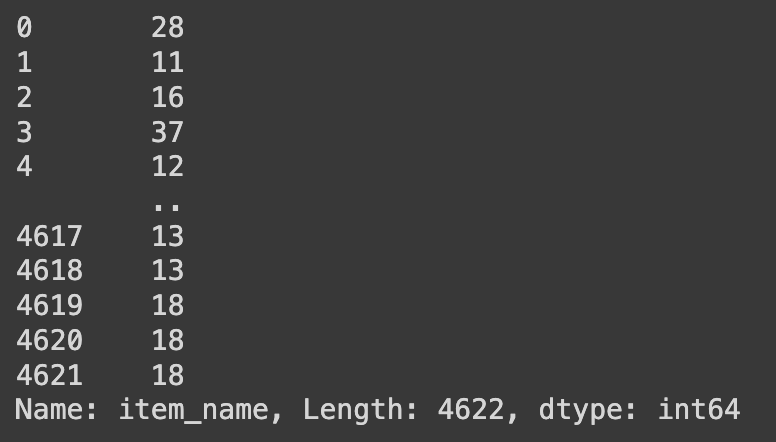
'item_name'의 첫번째 행(인덱스 0번째)은 'Chips and Fresh Tomato Salsa'로 공백 포함 28 글자이다.
위의 명령어를 사용하면 공백도 포함하여 단어 갯수를 센다.
# 데이터프레임에서 'item_name' 열의 값 중에서 문자열 길이가 15 이상인 행들 선택
Ans = df[df.item_name.str.len() >= 15]
Ans.head()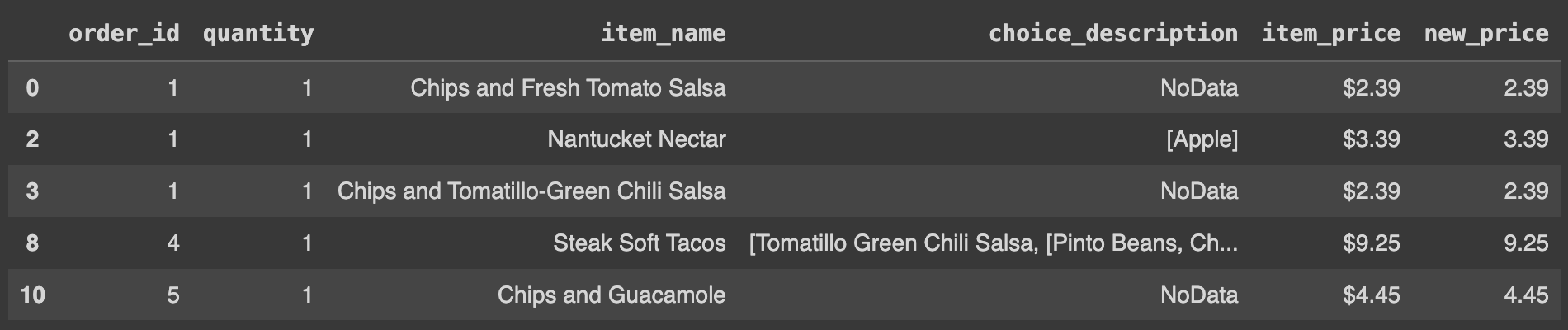
Q43. df의 데이터 중 new_price값이 lst에 해당하는 경우의 데이터 프레임을 구하고 그 갯수를 출력하기
# 데이터프레임에서 'new_price' 열의 값이 주어진 리스트(lst)에 포함된 값들을 가진 행들을 선택
lst =[1.69, 2.39, 3.39, 4.45, 9.25, 10.98, 11.75, 16.98]
Ans = df.loc[df.new_price.isin(lst)]
display(Ans.head(3))
print(len(Ans))
# isin(): 시리즈 또는 데이터프레임의 값이 주어진 리스트나 집합에 포함되는지를 검사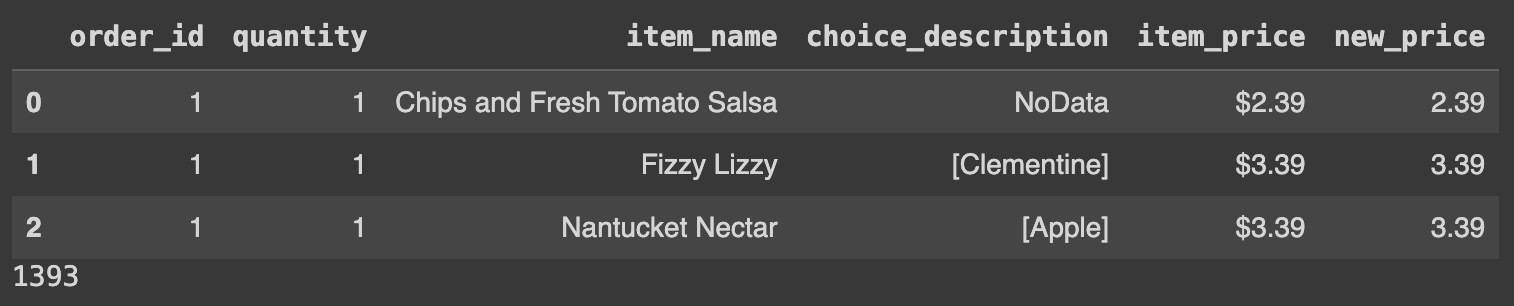
print(len(Ans)) 명령어 불포함:
# 주어진 리스트(lst)에 포함된 값을 가진 'new_price' 열의 행들 중 상위 3개의 행 출력
lst =[1.69, 2.39, 3.39, 4.45, 9.25, 10.98, 11.75, 16.98]
Ans = df.loc[df.new_price.isin(lst)]
display(Ans.head(3))위의 이미지에서는 테이블 하단에 숫자(예: 1393)를 나타났는데 아래 이미지에서는 해당 숫자를 찾을 수 없다.

display(Ans.head(3)) 명령어 불포함:
# 주어진 리스트(lst)에 포함된 값을 가진 'new_price' 열의 행들 중의 개수 출력
lst =[1.69, 2.39, 3.39, 4.45, 9.25, 10.98, 11.75, 16.98]
Ans = df.loc[df.new_price.isin(lst)]
print(len(Ans))
# 결과값:
# 1393