Q1. Data Read하기
데이터를 읽기 위해서는 먼저 해당 데이터를 불러와야한다. 보통 데이터를 읽어오기 위해 pandas 라이브러리를 사용한다.
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl)
type(df)구글 Colab에서 코드 셀을 실행시키려면 셀 왼쪽의
실행버튼을 클릭하거나, 단축키인Shift+Enter를 누르면 된다.
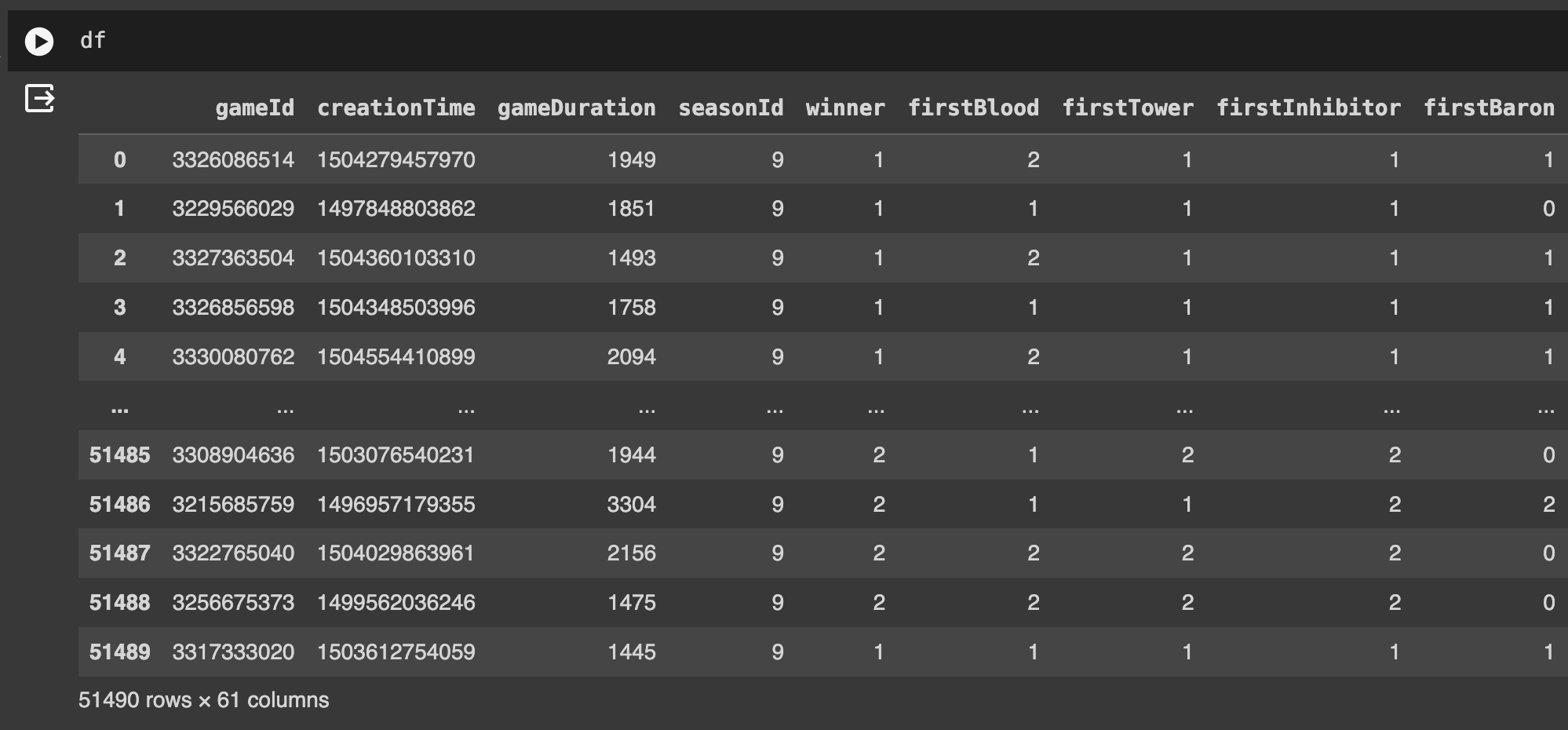
Q2. 상위 5개의 행 출력하기
df.head()
# head() 함수: dataframe의 상위 5개 행 출력
- Python에서 주의할 점은 모든 숫자는 0부터 시작한다는 것이다.
- 따라서 인덱스(Index)는 데이터의 고유한 숫자를 나타낸다.
Dataframe에서는 열(Column)을 인덱스로 사용하여 각 행을 고유하게 식별한다. Python에서는 기본적으로 인덱스를 설정하지 않으면 0부터 시작하는 숫자로 인덱싱된다.
Q3. 데이터의 행과 열의 갯수 파악하기
print(df.shape)
# shape: DataFrame의 행과 열의 수를 tuple 형태로 반환결과는 (행의 수, 열의 수) 형식으로 출력된다.
예를 들어, (51490, 61)은 51490개의 행(row)과 61개의 열(column)로 이루어진 dataframe을 의미한다.
이렇게 기본적인 정보를 탐색하고 파악하는 과정을 '탐색적 데이터 분석(Exploratory Data Analysis, EDA)'라고 한다.
데이터의 기본적인 특성을 파악하고 이해하기 위해 수행되는 이러한 과정을 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)이라고 한다. EDA는 데이터의 구조, 패턴, 관계, 이상치 등을 발견하고 데이터에 대한 통찰력을 얻는 데 도움이 된다. 이를 통해 데이터를 더 잘 이해하고 분석할 수 있다.
Tip:
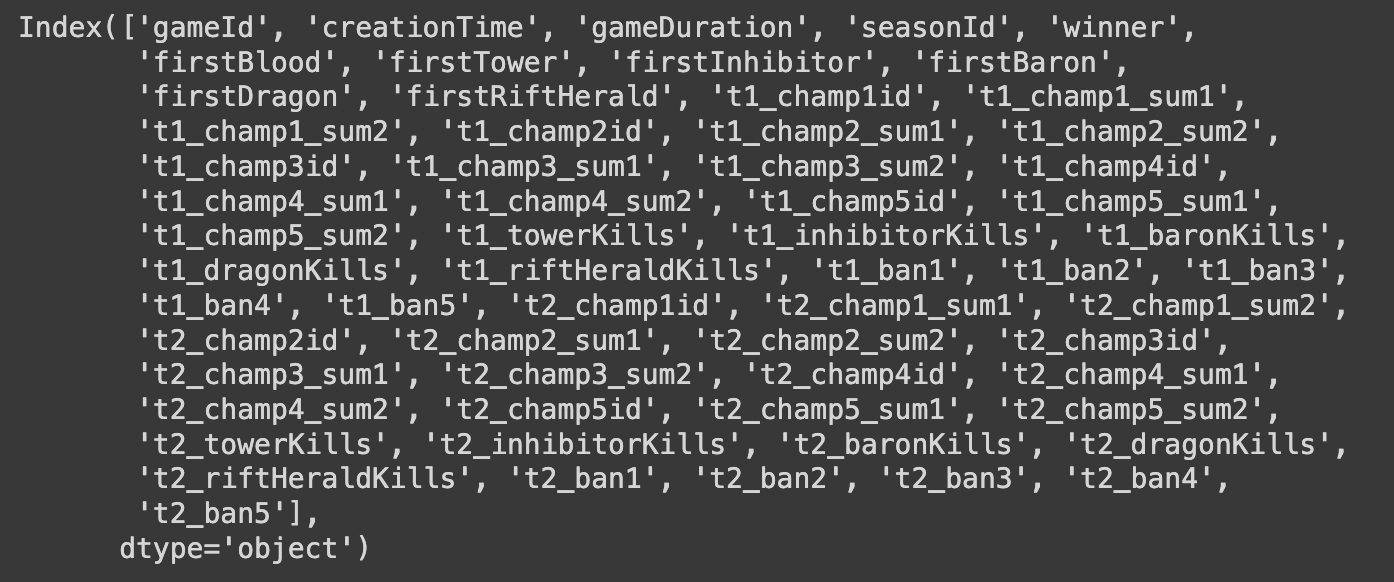
Q4. 전체 열(column) 출력하기
df.columns
# columns: DataFrame에 있는 모든 열(column)의 이름을 출력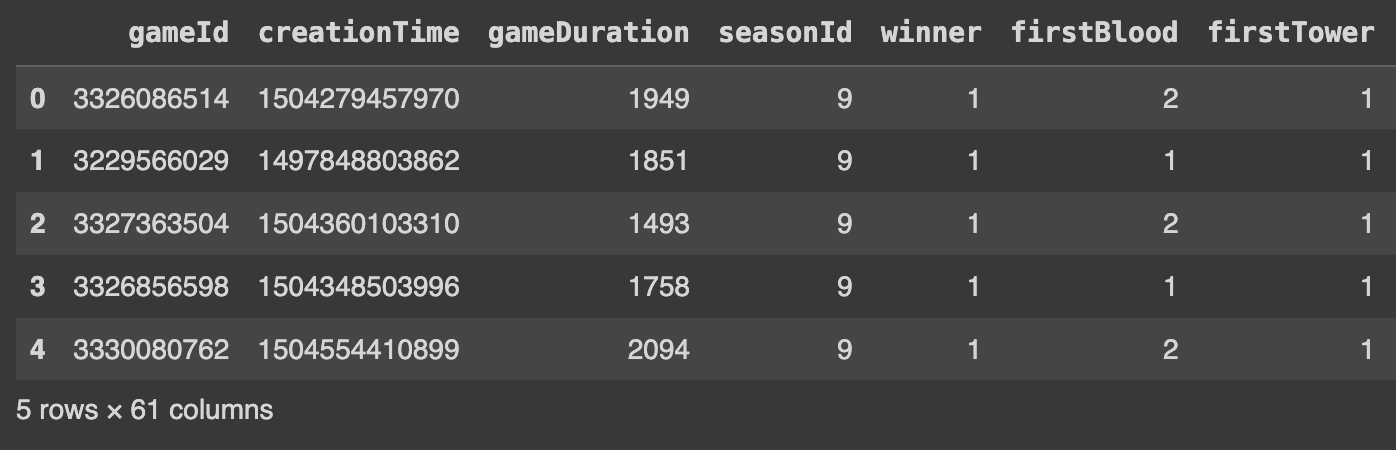
위와 같이 출력된 테이블을 DataFrame이라고 하는데 DataFrame은 데이터를 표 형식으로 다루는 데 사용되는 Python의 자료구조를 가리킨다. DataFrame은 판다스(Pandas) 라이브러리에서 제공되며, 표 형식의 데이터를 다루는 데 유용하며, 열과 행으로 구성되어 있다. DataFrame은 엑셀 Spreadsheet와 유사한 형태를 가지고 있어 데이터를 보다 구조화하고 처리하기 쉽게 만들어 준다.
위와 같이 출력된 데이터들을 list라고 하며 리스트(list)는 대괄호 [ ] 안에 요소들을 나열하여 정의되는 데이터 구조이다.
Q5. 6번째 열(column) 출력하기
리스트에서 특정 항목을 선택하려면 해당 항목의 인덱스를 대괄호 [ ] 안에 넣어주면 된다.
df.columns[5]6번째 열(column)을 출력하려면 5번 인덱스를 사용해야 한다. Python에서는 인덱스가 0부터 시작하기 때문에 5번 인덱스가 실제로는 6번째 열을 나타낸다.
Q6. 6번째 열(column)의 데이터 타입 확인하기
데이터 타입(dtype)은 주로정수형(integers),실수형(floats),문자열(strings)등으로 이루어져 있다.
df.iloc[:,5].dtype
# [:,5]: 모든 행과 6번째 열을 선택하는 인덱싱 방법
# dtype: 선택된 열의 데이터 유형을 반환
# 결과값:
dtype('int64') # 정수형 데이터 타입iloc는 정수 기반의 인덱스를 사용하여 데이터에 접근하는 방법이다. 데이터프레임의 행과 열을 정수 인덱스를 사용하여 선택할 수 있다.
결과값이 int64인 경우 해당 열이 정수형 데이터를 포함하고 있음을 나타낸다.
Q7. 데이터셋의 인덱스 구성 확인하기
인덱스(Index)는 DataFrame에서 가장 앞단에 위치하며 각 행을 식별하는 숫자이다. 일반적으로 0부터 시작하여 하나씩 증가하는 방식으로 인덱스가 부여된다. 데이터프레임을 생성할 때 특별한 처리를 하지 않으면 기본적으로 이러한 인덱스가 부여됩니다.
df.index
# 결과값:
# RangeIndex(start=0, stop=51490, step=1)
# RangeIndex: 인덱스의 범위
# start 매개변수: 시작 인덱스
# stop 매개변수: 끝 인덱스RangeIndex(start=0, stop=51490, step=1)은 인덱스의 범위를 나타낸다. 여기서 시작 인덱스는 0이고, 끝 인덱스는 51490이 아닌 51489까지이며, 1씩 증가한다.
- 따라서 총 51490개의 행이 있고, 인덱스는 0부터 51489까지 순차적으로 증가한다.
Q8. 6번째 열(column)의 3번째 값은 무엇?
df.iloc[2,5][2,5]는 3번째 행의 6번째 열 값이라고 해석하면된다.
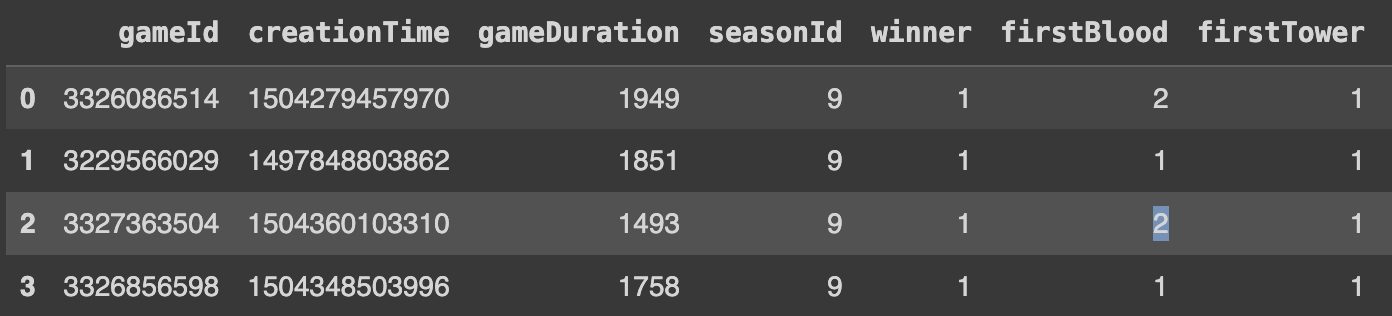
Q9. 데이터 로드하기 - column이 한글
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl, encoding = 'euc-kr')
type(df)encoding은 이 데이터를 저장할 때 어떠한 형식으로 저장을 했는지에 따라서 이거를 읽을 때도 동일한 형식으로 encording을 설정해주고 읽어야한다.
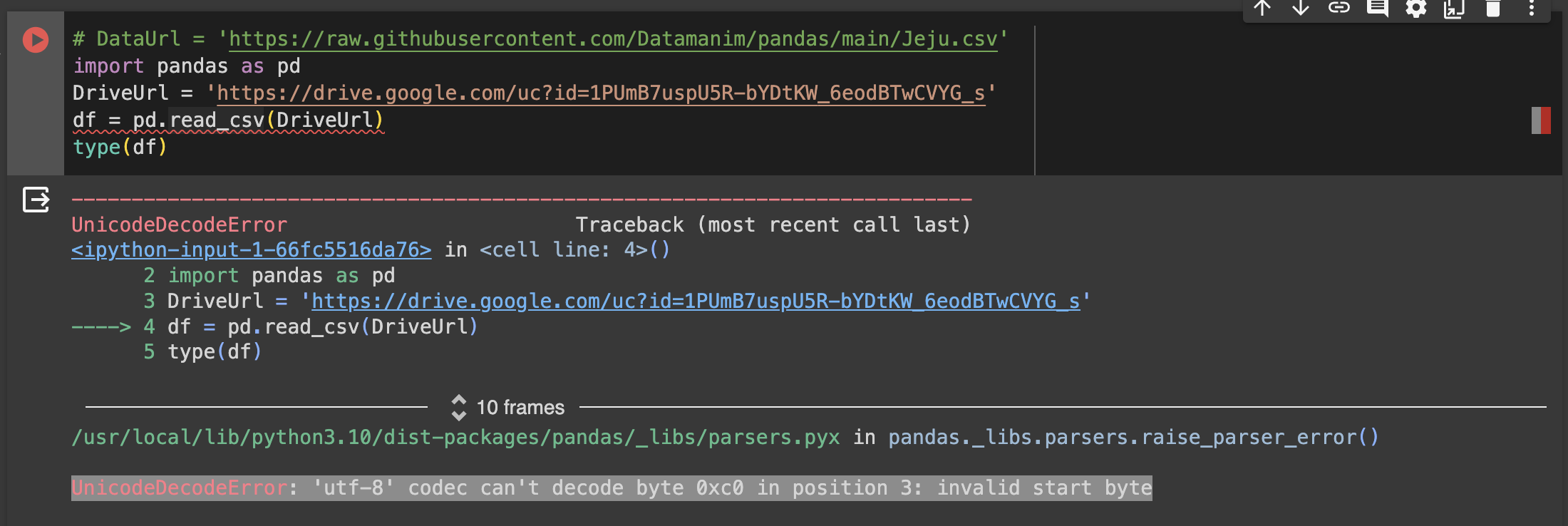
위의 이미지처럼 encoding = 'euc-kr' 옵션을 설정 안하면 데이터를 정확하게 변환시킬 수 없다는 에러가 뜬다.
Q10. 데이터 마지막 3개행 출력하기
df.tail(3)df.tail() 또는 df.head()처럼 (괄호)안에 아무 숫자도 쓰지 않으면 기본값으로 5개행까지 출력된다.
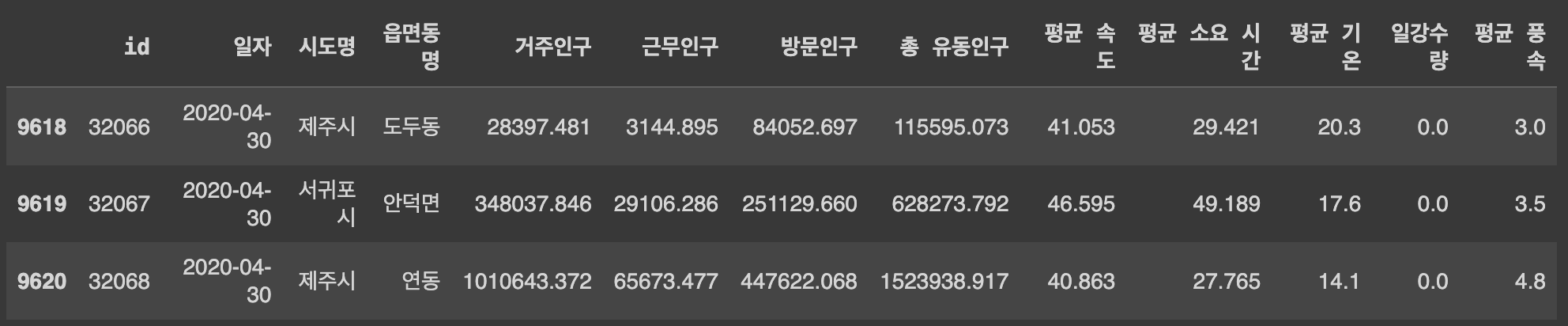
Q11. 수치형 변수를 가진 열(column) 출력하기
수치형 변수는 numerical 변수라고도 하며, 숫자로 이루어진 데이터이다.
select_dtypes 명령어는 내가 어떠한 데이터타입을 선택하겠다라는 의미이다.
# 선택한 datatype의 열(column) 출력
df.select_dtypes(exclue=object).columns
# exclude 매개변수: 제외
# object: Python Dataframe에서 문자형 형태의 데이터
Q12. 범주형 변수를 가진 열(column) 출력하기
범주형 변수는 categorical value라고도 하며 문자열로 이루어진 형식의 데이터이다.
df.select_dtypes(include=object).columns
# include 매개변수: 포함
참고:
float은 소수점이 있는 데이터int는 소수점이 없는 데이터
Q13. 각 열(column)의 결측치 숫자 파악하기
결측치는 데이터에 값이 없다. Null, NA, NAN이라고도 한다.
Python을 사용 중에 Null 값이 있으면 실행이 안되는 코드들이 상당이 많다. Null 값이라는 데이터는 해석을 할 수 없는 데이터이기에 Null 값에 대한 처리를 해줘야한다.
Null 값을 처리하기 전에 Null 값이 있는지 먼저 확인을 해봐야한다.
df.isnull().sum()
# isnull(): NULL 값이 있는지 없는지에 대한 여부를 물어보는 명령어
# sum(): 더하기
# 결과값:
# id 0
# 일자 0
# 시도명 0
# 읍면동명 0
# 거주인구 0
# 방문인구 0isnull()은 is null로 NULL 값이 있는지 없는지에 대한 여부를 물어보는 명령어이다.
Q14. 각 열(column)의 데이터 수, 데이터타입 한번에 확인하기
df.info()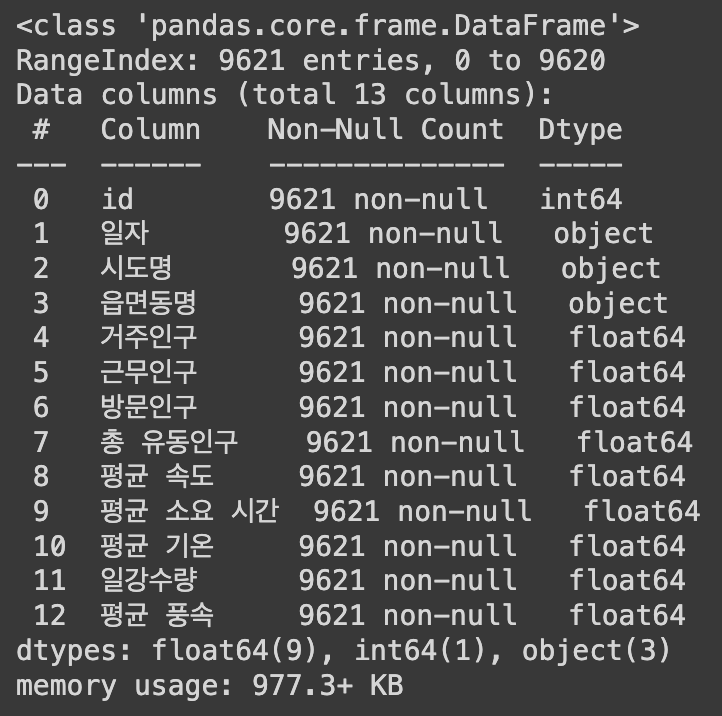
위의 결과값을 보고 알 수 있는 것은
- RangeIndex: 9621 entries는 총 9621개의 데이터를 가진 테이블이다.
- Index는 0부터 9620번까지 설정이 되어있다.
- 열(column)은 총 13개이다.
- 각 column의 이름 및 datatype을 알 수 있다.
Non-Null Count는 Null이 아닌 데이터를 나타낸다- 해당 정보의 하단에서 요약도 확인할 수 있다.
dtypes: float64(9)로 실수형 데이터가 9개, int64(1)로 정수형 데이터가 1개, object(3)로 object가 3개로 구성이 되어있다. - 해당 데이터는 977.3+ KB의 메모리를 차지하고 있다.
Q15. 각 수치형 변수의 분포(사분위, 평균, 표준편차, 최대, 최소) 확인하기
df.describe()
# describe(): 숫자형 열에 대한 기본적인 통계 정보 제공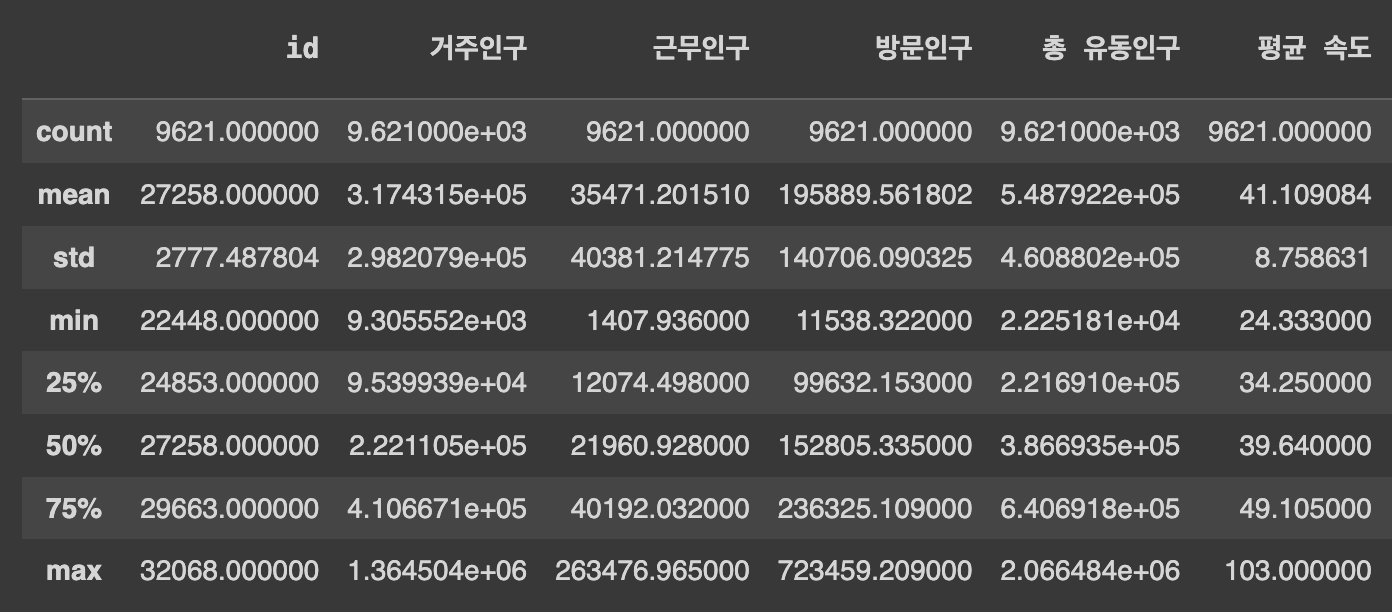
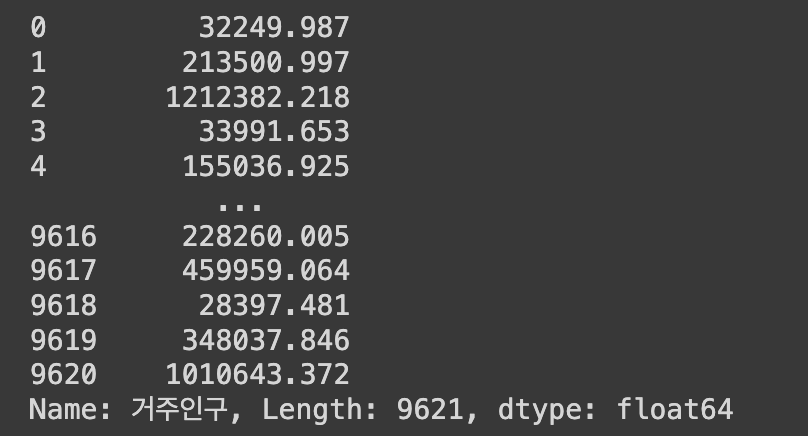
Q16. 특정 열(column)의 값 출력하기
df['거주인구']df.iloc()보다는 df.[column_이름]를 더 자주 쓴다.
Q17. 평균 속도 열(column)의 4분위 범위(IQR) 값 구하기
IQR은 보통 75%에서 25%를 뺀 값을 말한다.
df['평균 속도'].quantile(0.75) - df['평균 속도].quantile(0.25)
# 결과값:
# 14.854999999999997Q18. 특정 column의 유일값 갯수 출력하기
df['읍면동명'].nunique()
# nunique(): 특정 컬럼에 있는 고유한 값들의 개수 반환
# 결과값:
# 41Q19. 특정 column의 유일값 모두 출력하기
df['읍면동면'].unique()
# unique(): 특정 컬럼에 있는 고유한 값들의 리스트 반환
# 결과값:
# ['읍면동면1', '읍면동면2', '읍면동면3', ...]