Q44. 데이터를 로드하고 상위 5개 컬럼 출력하기
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl)
Ans = df.head(5)
Ans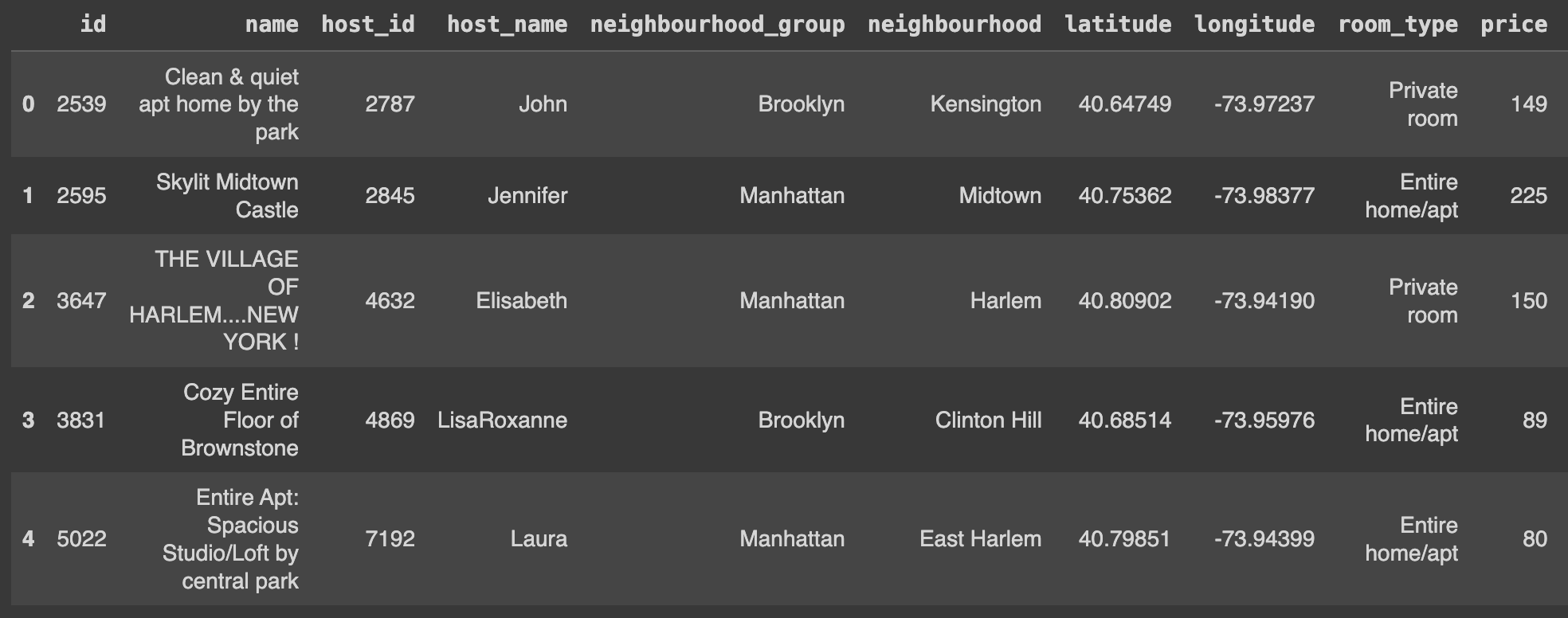
Q45. 데이터의 각 host_name의 빈도수를 구하고 host_name으로 정렬하여 상위 5개 출력하기
size()함수는 데이터프레임의 전체 요소 개수를 세며, NULL 값이 있어도 모두 포함하여 센다.count()함수는 각 열의 비어 있지 않은 값의 개수만을 세고, NULL 값은 제외한다.
해당 문제는 두 가지 방법으로 풀 수 있다.
첫번째 방법:
# 'host_name'을 기준으로 데이터프레임을 그룹화한 후, 각 그룹의 크기를 계산하여 반환
Ans = df.groupby('host_name').size()
Ans.head()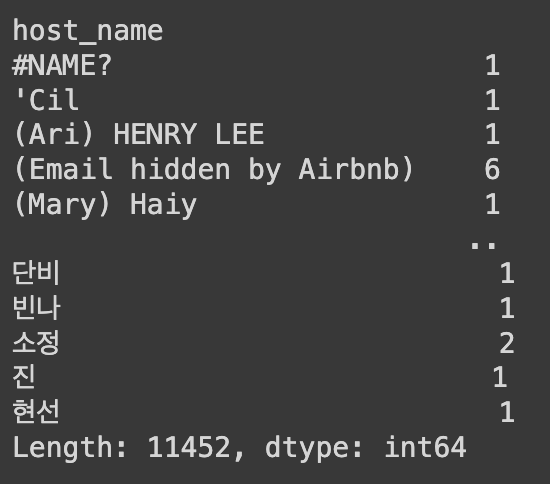
groupby()함수를 사용하여 그룹화한 후에는 그룹의 인덱스가 생성된다. 이 인덱스를 정렬하기 위해서는sort_index()함수를 사용할 수 있다. 이 함수를 적용하면 그룹의 인덱스를 기준으로 정렬된 결과를 얻을 수 있다.
# host_name'을 기준으로 데이터프레임을 그룹화한 후, 각 그룹의 크기를 계산하여 반환, 그 결과를 인덱스를 기준으로 정렬
df.groupby('host_name').size().sort_index()
value_counts()함수는 해당 열의 고유한 값들의 빈도를 세어준다. 이 함수를 사용하면 고유한 값의 개수를 내림차순으로 정렬하여 반환한다. 또한, NULL 값은 세지 않는다.
두번째 방법:
# 'host_name' 열에서 각 고유한 값의 빈도를 세고, 그 결과를 인덱스를 기준으로 정렬하여 반환
Ans = df.host_name.value_counts().sort_index()
Ans.head()Q46. 데이터의 각 host_name의 빈도수를 구하고 빈도수로 정렬하여 상위 5개 출력하기
# 'host_name' 열에서 각 고유한 값의 빈도를 세고, 그 결과를 데이터프레임으로 변환한 후에 칼럼 이름을 'counts'로 변경하고, 'counts'를 기준으로 내림차순 정렬
# df.host_name.value_counts().to_frame().head()
Ans = df.groupby('host_name').size().\
to_frame().rename(columns={0:'counts'}).\
sort_values('counts', ascending=False)
Ans.head(5)
# to_frame(): Series 객체를 데이터프레임으로 변환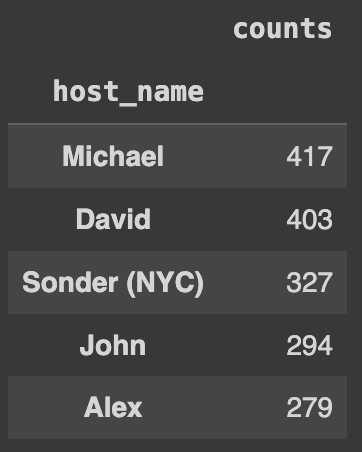
위의 코드와 같이 줄의 끝에 역슬래시(\)를 사용하여 코드를 다음 줄로 나눌 수 있다.
to_frame() 예시:
df.groupby('host_name').size().to_frame()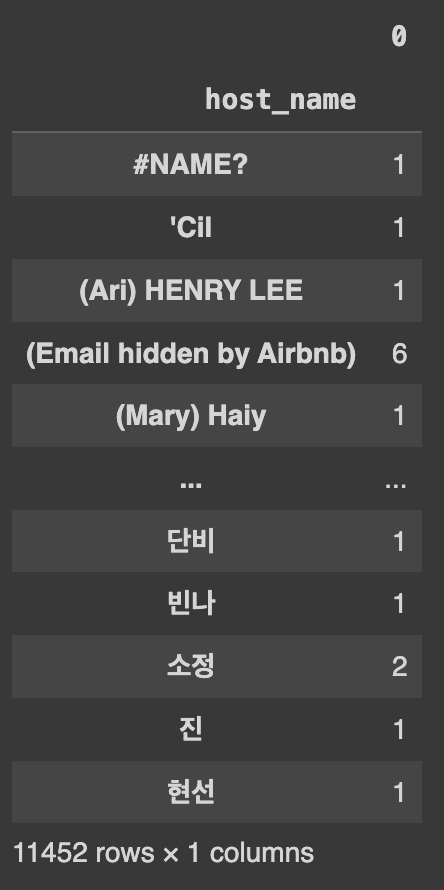
size() 함수와 같은 결과값을 얻을 수 있는 코드는 다음과 같다.
df.host_name.value_counts().to_frame().head()Q47. neighbourhood_group의 값에 따른 neighbourhood 컬럼 값의 갯수 구하기
# 'neighbourhood_group' 및 'neighbourhood' 열을 기준으로 데이터를 그룹화하고, 각 그룹의 크기(행의 개수)를 계산
Ans = df.groupby(['neighbourhood_group','neighbourhood'], as_index=False).size()
Ans.head()
# 
# 'neighbourhood_group' 및 'neighbourhood' 열을 기준으로 데이터를 그룹화하고, 각 그룹의 크기(행의 개수) 계산
Ans = df.groupby(['neighbourhood_group','neighbourhood']).size()
Ans.head()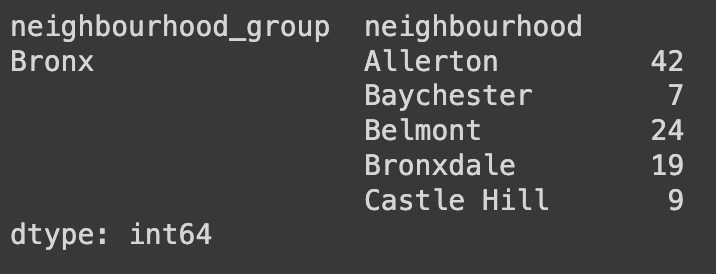
위의 결과값은 DataFrame이 아니다.
type(Ans)
# 결과값:
# pandas.core.series.Series
groupby()함수로 그룹화된 결과는 기본적으로 MultiIndex를 가진 Series로 반환된다. 이것은 하나의 열에 대한 Series이므로 보기가 불편할 수 있.
as_index=False옵션을 사용하면 그룹화된 열이 인덱스로 사용되지 않고 데이터프레임의 일반적인 열로 유지된다. 이렇게 하면 데이터프레임의 구조가 보다 직관적이며, 데이터를 이해하고 조작하기가 더 쉬워진다.
Q48. neighbourhood_group의 값에 따른 neighbourhood컬럼 값 중 neighbourhood_group그룹의 최댓값들 출력하기
최대값을 구하는데에는
max()함수를 사용한다.
# 'neighbourhood_group'과 'neighbourhood' 열을 기준으로 그룹화하고, 각 그룹의 크기를 계산. 그런 다음 'neighbourhood_group'을 기준으로 다시 그룹화하고, 각 그룹에서 최대값 계산
Ans = df.groupby(['neighbourhood_group','neighbourhood'], as_index=False).size()\
.groupby(['neighbourhood_group'], as_index=False).max()
Ans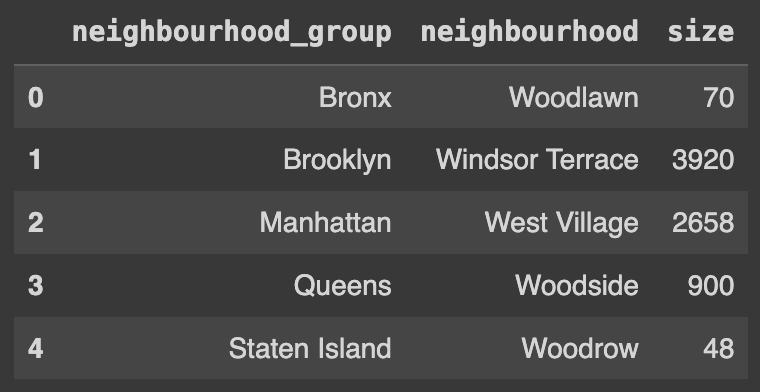
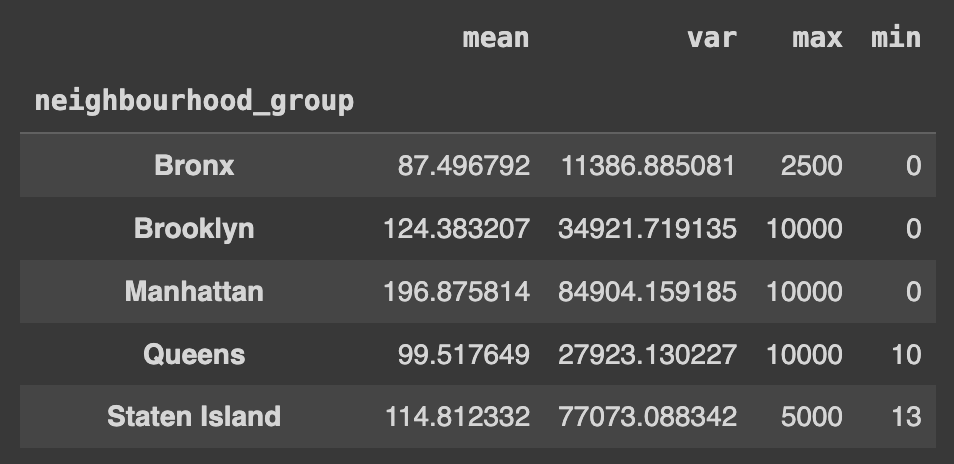
Q49. neighbourhood_group 값에 따른 price값의 평균, 분산, 최대, 최소 값 구하기
# neighbourhood_group 열을 기준으로 그룹화한 뒤, price 열에 대해 평균(mean), 분산(var), 최댓값(max), 최솟값(min) 계산
Ans = df.groupby('neighbourhood_group')['price'].agg(['mean','var','max','min'])
Ans
# agg(): aggregate function(사칙 연산)
# var: 분산
agg()함수는 여러 개의 집계 함수를 한 번에 적용할 수 있다. 각 집계 함수는 사전(dictionary) 형태로 전달되며, 열마다 적용된다. 이렇게 함으로써 데이터프레임에서 여러 통계량을 한 번에 계산할 수 있다.
여러 개의 사칙 연산을 한 번에 쓰려면 사칙 연산 함수를 리스트나 배열로 묶어서 전달해야 한다. 이렇게 하면 한 번에 여러 가지 연산을 적용할 수 있습니다.
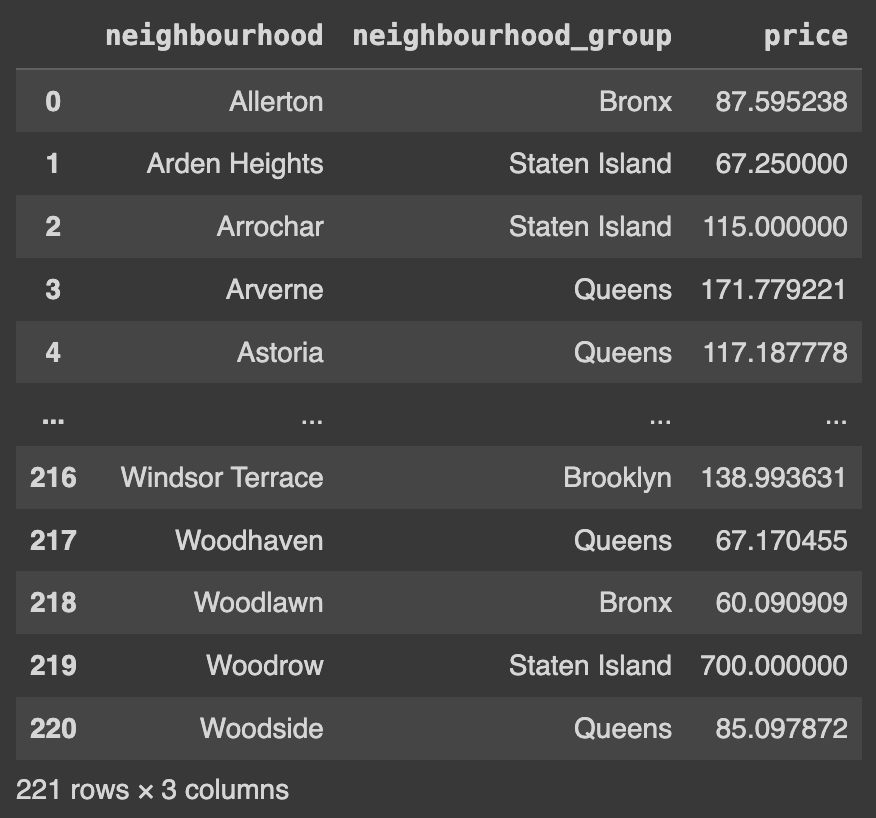
Q50. neighbourhood 값과 neighbourhood_group 값에 따른 price의 평균 구하기
# neighbourhood와 neighbourhood_group을 기준으로 그룹화하고, 각 그룹 내의 price 열의 평균 계산
Ans = df.groupby(['neighbourhood','neighbourhood_group']).price.mean()
Ans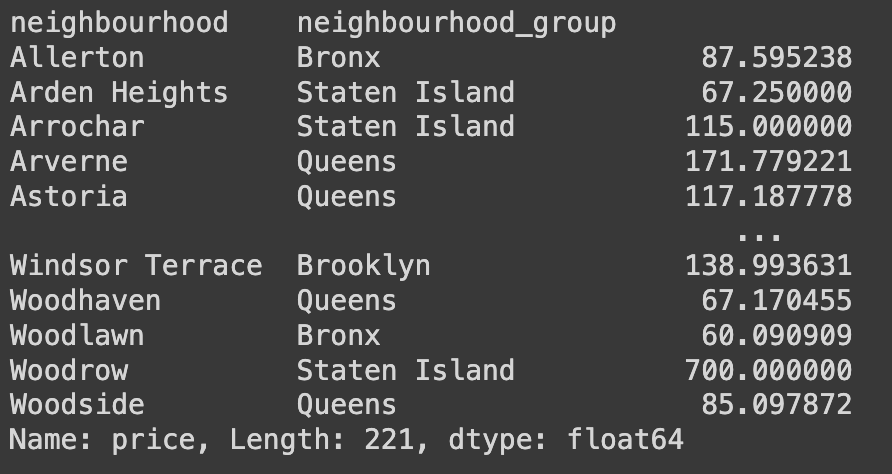
아래와 같이 코드를 써도 위와 결과치는 똑같다.
# .price 대신 ['price']
df.groupby(['neighbourhood','neighbourhood_group'])['price'].mean()Ans = df.groupby(['neighbourhood','neighbourhood_group'],as_index=False).price.mean()
Ansas_index=False를 사용하여 DataFrame 형태로 출력할 수 있다. 이렇게 하면 그룹화된 열이 인덱스로 설정되지 않고 새로운 열로 유지된다. 결과적으로 Series 형식이 아닌 DataFrame 형식으로 데이터를 더 쉽게 다룰 수 있다.
Q51. neighbourhood 값과 neighbourhood_group 값에 따른 price 의 평균을 계층적 indexing 없이 구하기
계층적인 인덱싱 없이 데이터를 더 직관적으로 표현하고 싶다는 것은 데이터를 단순하게 구조화하여 보기 쉽게 만들고 싶다는 것이다. 계층적 인덱싱은 데이터를 여러 수준으로 그룹화하여 복잡한 구조를 가질 수 있기 때문에 이를 제거하고 데이터를 더 간결하게 표현하는 것을 의미한다. 이를 통해 데이터를 더 직관적으로 이해하고 분석할 수 있다.
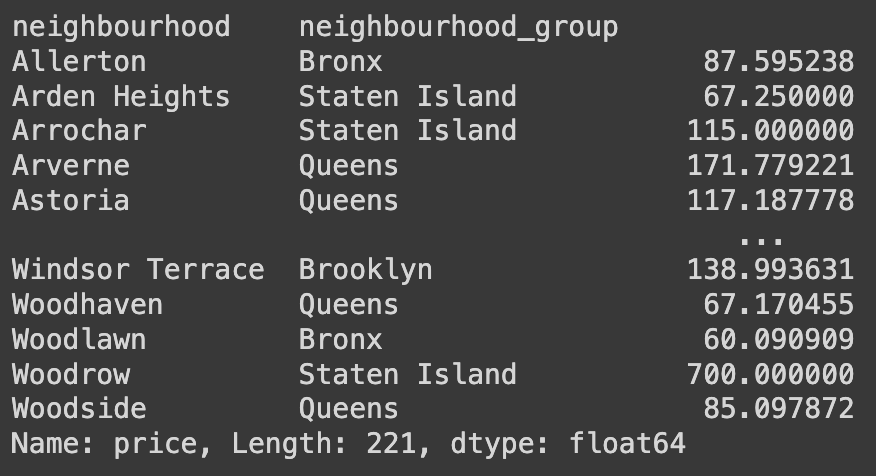
Ans = df.groupby(['neighbourhood','neighbourhood_group']).price.mean().unstack()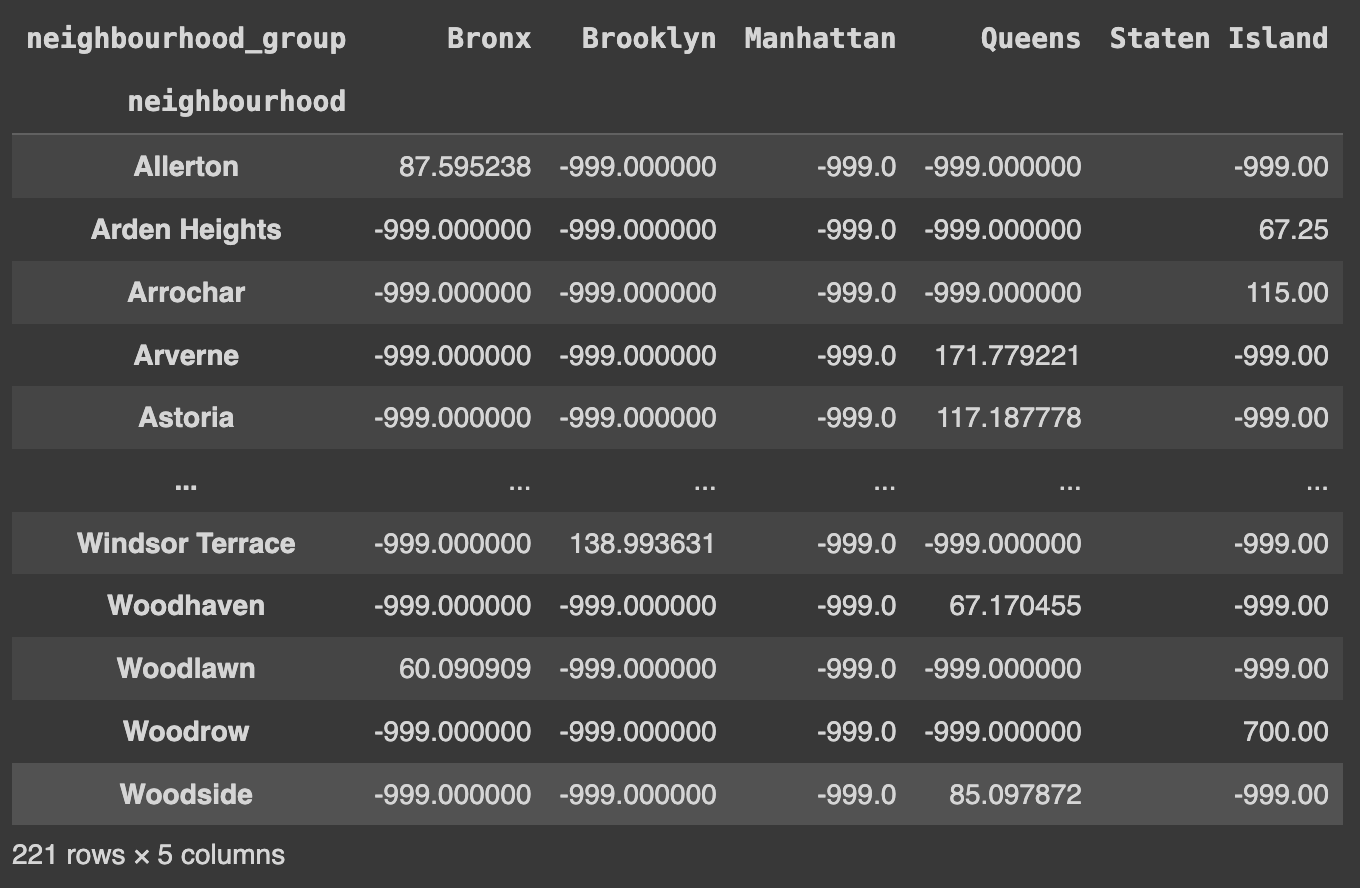
unstack()명령어는 계층적 인덱스를 가진 Series나 DataFrame을 다룰 때 사용된다. 특히, 계층적으로 구성된 인덱스를 열로 변환하여 새로운 DataFrame을 생성한다. 이를 통해 계층적 구조를 가진 데이터를 보다 편리하게 다룰 수 있다.
# neighbourhood_group이 행 인덱스로, neighbourhood가 열 인덱스로 사용
Ans = df.groupby(['neighbourhood_group', 'neighbourhood']).price.mean().unstack()
Ans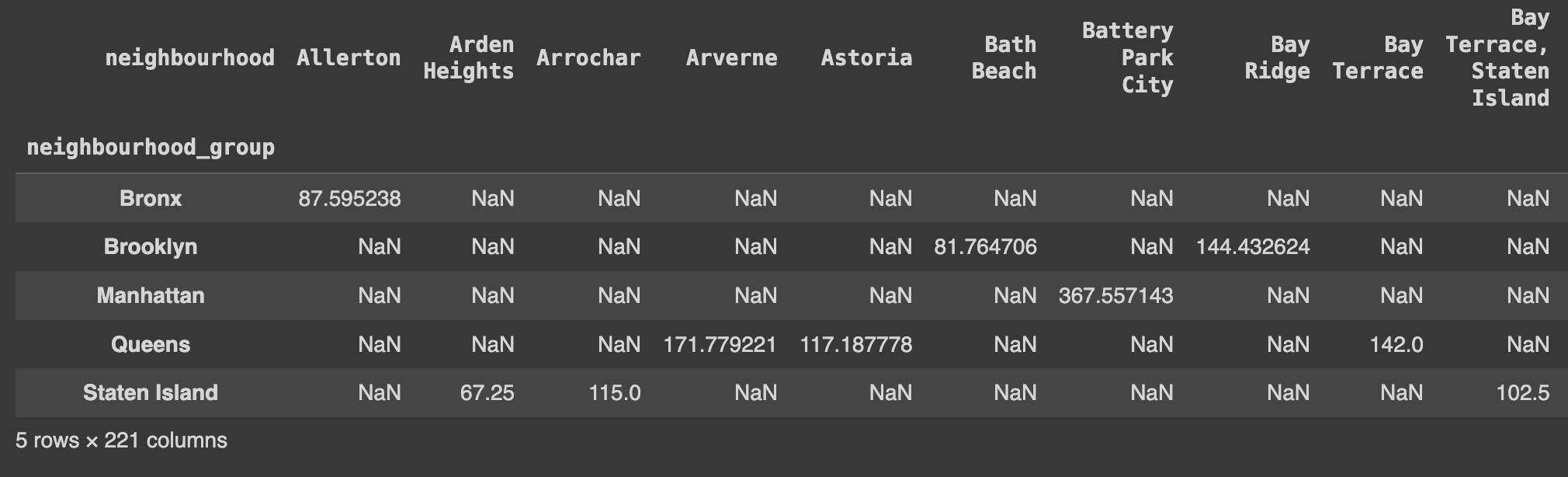
Q52. neighbourhood 값과 neighbourhood_group 값에 따른 price의 평균을 계층적 indexing 없이 구하고 nan 값은 -999 값으로 채우기
Ans = df.groupby(['neighbourhood','neighbourhood_group']).price.mean().unstack().fillna(-999)
Ans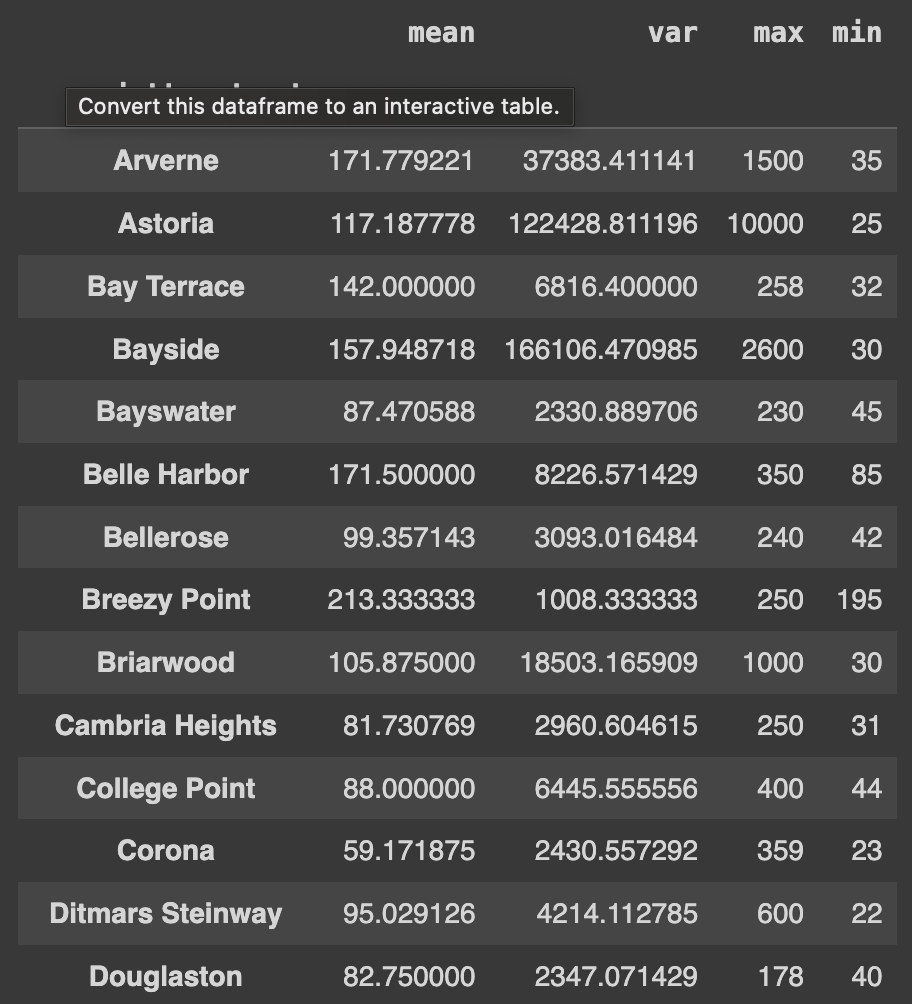
fillna()는 DataFrame 또는 Series에서 결측값(빈 값 또는 NULL)을 다른 값으로 채우는 데 사용된다.
Q53. 데이터 중 neighbourhood_group 값이 Queens값을 가지는 데이터들 중 neighbourhood 그룹별로 price값의 평균, 분산, 최대, 최소값 구하기
# Queens 지역에서 각 neighbourhood의 가격에 대한 평균, 분산, 최대값, 최소값 계산
Ans = df[df.neighbourhood_group=='Queens'].groupby(['neighbourhood']).price.agg(['mean','var','max','min'])
AnsQ54. 데이터 중 neighbourhood_group 값에 따른 room_type 컬럼의 숫자를 구하고 neighbourhood_group 값을 기준으로 각 값의 비율을 구하기
# neighbourhood_group 및 room_type에 따른 각 조합의 빈도를 계산하고, 그 값을 해당 행의 합계로 나누어서 각 그룹 내의 비율 계산
Ans = df[['neighbourhood_group','room_type']].groupby(['neighbourhood_group','room_type']).size().unstack()
Ans.loc[:,:] = (Ans.values /Ans.sum(axis=1).values.reshape(-1,1))
Ans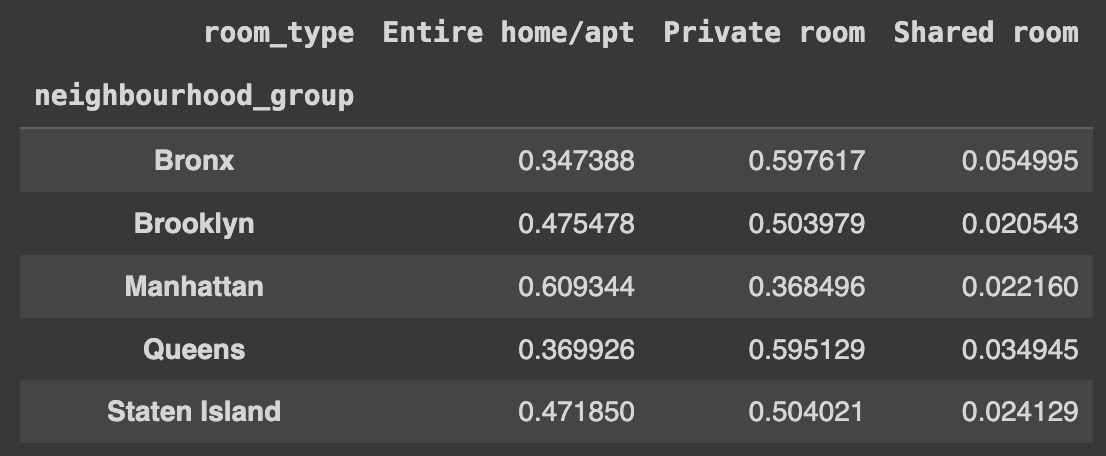
1) 'neighbourhood_group'과 'room_type'을 기준으로 데이터를 그룹화하고, 각 그룹 내의 빈도를 계산한 후 unstack()을 사용하여 데이터를 재구성한다.
df[['neighbourhood_group','room_type']].groupby(['neighbourhood_group','room_type']).size().unstack()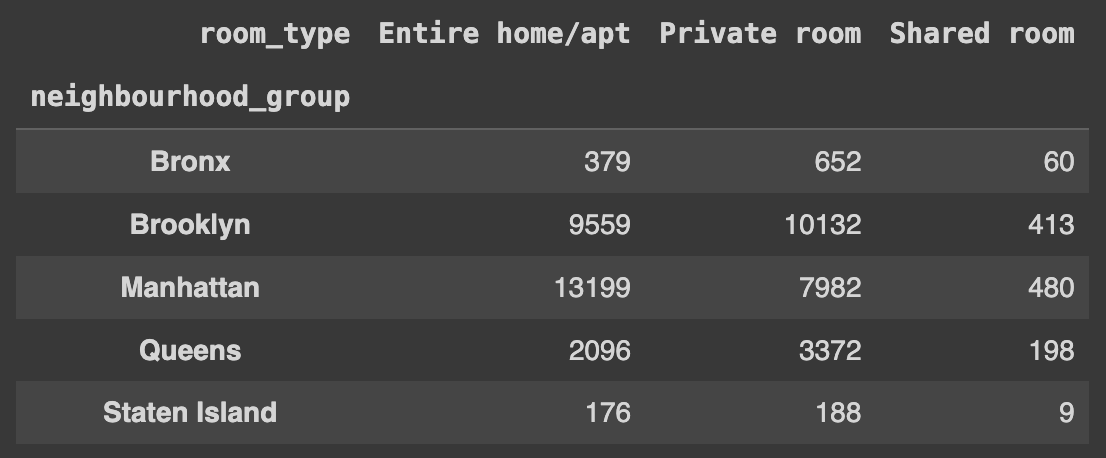
2) Ans.values는 데이터프레임의 값들을 2차원 배열로 반환한다. 이 배열은 각 셀에 해당하는 값들을 포함하고 있다. 이를 통해 데이터프레임의 값을 매트릭스 형태로 확인할 수 있다
Ans.values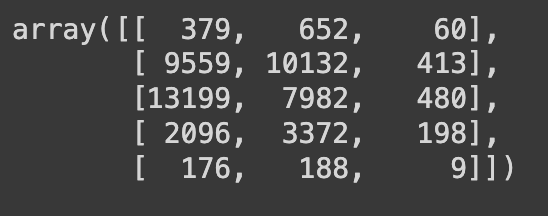
3) Ans.sum(axis=1)은 각 행의 값을 더한 결과를 반환한다. 여기서 axis=1은 각 행을 따라 합계를 계산하라는 의미이다.
Ans.sum(axis=1)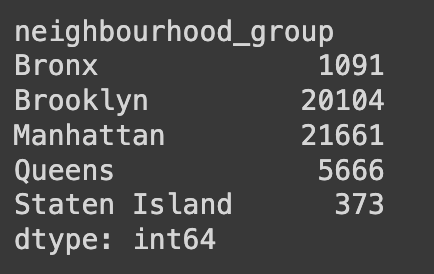
참고:
sum(axis=0)은 각 열의 합을 구하는 연산이다.A B C 0 1 2 3 1 4 5 6 2 7 8 9 # 결과값: # A 12 # B 15 # C 18 # dtype: int64
4) 각 행의 합계 값을 열 벡터로 재구성한다.
Ans.sum(axis=1).values.reshape(-1,1)
# 결과값:
# array([[ 1091],
# [20104],
# [21661],
# [ 5666],
# [ 373]])reshape() 함수는 데이터의 형태(행과 열에 대한 차원의 개수)를 변경할 때 사용된다.
-1은 해당 차원에 대해 남은 차원의 크기를 자동으로 계산하라는 의미이며,1은 열 벡터 모양(하나의 열로 배열을 구성)으로 만들라는 것이다.
따라서 reshape(-1, 1)은 1차원 배열을 열 벡터로 변환하는 데 사용된다.
1차원은 아래와 같다.
# array([[ 1091],
# [20104],
# [21661],
# [ 5666],
# [ 373]])5) Ans의 값들을 각 행의 총합으로 나누어서 각 요소가 해당 행의 합으로 나누어진 행렬을 만든다. 이를 통해 각 행의 값이 해당 행의 총합에 대한 비율로 표현된다.
Ans.values / Ans.sum(axis=1).values.reshape(-1,1)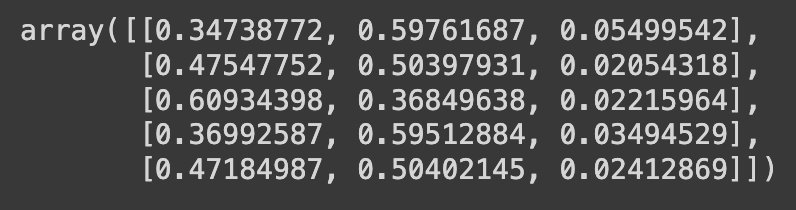
예시:
0.34738772 = 379 (Ans.values에서 구한 첫번째 값) / 1091 (Ans.sum(axis=1).values.reshape(-1,1) 구한 첫번째 값)
