Q55. 데이터를 로드하고 데이터 행과 열의 갯수 출력하기
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl)
df.shape
# 결과값:
(10127, 23) # 10,127개의 행과 23개의 열로 구성된 데이터
df.shape은 DataFrame의 행과 열의 개수를 tuple 형태로 반환하는 속성(attribute)이다. 반환되는 튜플은(행의 개수, 열의 개수)형태로 구성된다.
Q56. Income_Category의 카테고리를 map 함수를 이용하여 다음과 같이 변경하여 newIncome 컬럼에 매핑하기
dic = {
'Unknown' : 'N',
'Less than $40K' : 'a',
'$40K - $60K' : 'b',
'$60K - $80K' : 'c',
'$80K - $120K' : 'd',
'$120K +' : 'e'
} # dic: dictionary(사전)의 줄임말
df['newIncome'] = df.Income_Category.map(lambda x: dic[x])
Ans = df[['newIncome', 'Income_Category']]
Ans.head()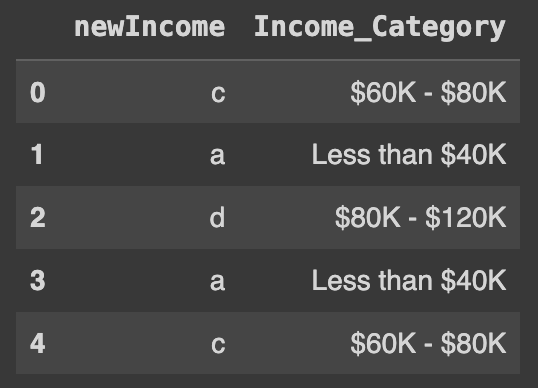
map()함수는 Series나 DataFrame의 각 요소에 대해 주어진 함수를 적용하여 새로운 값을 반환한다. 이 함수는 일반적으로 요소별 변환을 쉽게 수행할 때 사용된다. 예를 들어, 모든 요소에 대해 제곱을 계산하거나 특정 문자열을 검색하여 해당하는 요소를 찾는 등의 작업을 수행할 수 있다.
lambda함수는 일반적으로 간단한 함수를 정의할 때 사용된다. 특히map()함수와 같이 사용되어 각 요소에 대해 특정한 연산을 적용하거나 조건을 검사할 때 유용하다.lambda함수를 사용하면 간단한 함수를 한 줄로 작성할 수 있어서 코드를 간결하게 만들 수 있다. lambda 키워드 다음에는 인자가 오고, 콜론(:) 뒤에는 해당 인자를 이용한 표현식이 온다. 여기서x는 매개변수(parameter)로 함수의 입력 변수를 나타내며, 'income_category' 값들을 하나씩 받아와서 함수 내에서 사용된다.
Q57. Income_Category의 카테고리를 apply 함수를 이용하여 다음과 같이 변경하여 newIncome 컬럼에 매핑하기
def changeCategory(x): # def: defition의 약자
if x =='Unknown':
return 'N'
elif x =='Less than $40K': # elif: else lf의 줄임말
return 'a'
elif x =='$40K - $60K':
return 'b'
elif x =='$60K - $80K':
return 'c'
elif x =='$80K - $120K':
return 'd'
elif x =='$120K +' :
return 'e'
df['newIncome'] = df.Income_Category.apply(changeCategory)
Ans = df[['newIncome', 'Income_Category']]
Ans.head() # map() 함수를 쓴 56번과 동일한 결과값 출력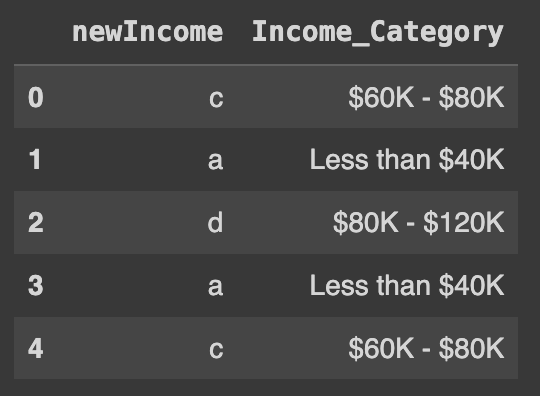
def문법은 사용자가 직접 함수를 정의할 때 사용된다. 함수 이름 뒤에는 함수가 받을 인자를 나타내는 괄호가 오고, 이 괄호 안에는 함수가 사용할 변수들을 정의한다. 이후 콜론(:)을 찍고 함수의 내용을 작성하면 된다. 함수 내부에서 받은 인자를 이용하여 원하는 연산을 수행할 수 있다.
def다음에 오는 이름은 내가 만든 함수의 이름이다. 그리고(x):에서 괄호 안에는 함수가 받을 인자를 나타내며, 이 부분에서x는 함수가 받을 인자의 이름을 나타낸다. 함수가 받을 인자의 개수에 따라 괄호 안에 변수를 여러 개 쓸 수도 있다. 이렇게 정의된 함수는 나중에 호출하여 사용할 수 있다.
apply함수는 데이터프레임이나 시리즈의 각 행 또는 열에 사용자가 정의한 함수를 적용할 때 주로 사용된다. 이 함수를 사용하면 복잡한 연산을 간단하게 적용할 수 있다. 특히 사용자가 직접 작성한 함수를 데이터프레임의 각 행이나 열에 적용할 때 유용하다.
Q58. Customer_Age의 값을 이용하여 나이 구간을 AgeState 컬럼으로 정의하라. (0-9: 0 , 10-19: 10 , 20-29: 20) … 각 구간의 빈도수 출력하기
df['AgeState'] = df.Customer_Age.map(lambda x: x//10 *10)
Ans = df['AgeState'].value_counts().sort_index()
Ans
# 결과값:
# 20 195
# 30 1841
# 40 4561
# 50 2998
# 60 530
# 70 2
# Name: AgeState, dtype: int64apply() 문법을 써도 위와 동일한 결과를 가져온다.
df['AgeState'] = df.Customer_Age.apply(lambda x: x//10 *10)
Ans = df['AgeState'].value_counts().sort_index()
Ans
# 결과값:
# 20 195
# 30 1841
# 40 4561
# 50 2998
# 60 530
# 70 2
# Name: AgeState, dtype: int64
//는나누기 연산자이며, 결과값은 나눗셈의 몫만을 반환한다. 이 연산자를 사용하면 소수점 이하의 값은 버려지고 정수 부분만 남게 된다.# 예시 5 // 2 # 출력 결과: 2
Q59. Education_Level의 값중 Graduate 단어가 포함되는 값은 1 그렇지 않은 경우에는 0으로 변경하여 newEduLevel 컬럼을 정의하고 빈도수 출력하기
df['newEduLevel'] = df.Education_Level.map(lambda x : 1 if 'Graduate' in x else 0)
Ans = df['newEduLevel'].value_counts()
Ans
# 출력값:
# 0 6483
# 1 3644
# Name: newEduLevel, dtype: int64apply() 문법을 써도 위와 동일한 결과를 가져온다.
df['newEduLevel'] = df.Education_Level.apply(lambda x : 1 if 'Graduate' in x else 0)
Ans = df['newEduLevel'].value_counts()
Ans
# 출력값:
# 0 6483
# 1 3644
# Name: newEduLevel, dtype: int64np.where() 함수를 사용한 아래의 방법으로도 동일한 결과를 가져온다.
# Education_Level 열에서 'Graduate'를 포함하는지 여부에 따라 새로운 열인 newEduLevel을 만들고, 'Graduate'를 포함하면 1로, 그렇지 않으면 0으로 값을 할당
import numpy as np
df['newEduLevel'] = np.where( df.Education_Level.str.contains('Graduate'), 1, 0)
Ans = df['newEduLevel'].value_counts()
Ans
# 출력값:
# 0 6483
# 1 3644
# Name: newEduLevel, dtype: int64
np.where함수는 조건을 검사하고 조건을 충족할 때와 충족하지 않을 때 서로 다른 값을 반환한다. 조건을 충족하면 첫 번째 매개변수에 지정된 값을 반환하고, 그렇지 않으면 두 번째 매개변수에 지정된 값을 반환합니다. 이를 사용하여 데이터프레임의 열에 대한 조건부 값을 간단하게 생성할 수 있다.
Q60. Credit_Limit 컬럼값이 4500 이상인 경우 1 그외의 경우에는 모두 0으로 하는 newLimit 정의하기. newLimit 각 값들의 빈도수 출력하기
# Credit_Limit 열의 값이 4500 이상이면 1로, 그렇지 않으면 0으로 값을 설정하여 새로운 열인 newLimit을 생성
df['newLimit'] = df.Credit_Limit.map(lambda x : 1 if x>=4500 else 0)
Ans = df['newLimit'].value_counts()
Ans
# 결과값:
# 1 5096
# 0 5031
# Name: newLimit, dtype:int64apply() 문법을 써도 위와 동일한 결과를 가져온다.
df['newLimit'] = df.Credit_Limit.apply(lambda x : 1 if x>=4500 else 0)
Ans = df['newLimit'].value_counts()
Ans
# 결과값:
# 1 5096
# 0 5031
# Name: newLimit, dtype:int64Q61. Marital_Status 컬럼값이 Married 이고 Card_Category 컬럼의 값이 Platinum인 경우 1 그외의 경우에는 모두 0으로 하는 newState컬럼을 정의하기. newState의 각 값들의 빈도수 출력하기
def check(x):
if x.Marital_Status == 'Married' and x.Card_Category == 'Platinum':
return 1
else:
return 0
df['newState'] = df.apply(check.axis=1)
Ans = df['newState'].value_counts()
Ans
# 결과값:
# 0 10120
# 1 7
# Name: newState, dtype: int64위 코드에서는 apply() 함수에 axis=1 인수를 사용하여 각 행에 대해 check 함수를 적용하고 있다. 이 때 check 함수의 인자로는 각 행이 전달되므로 해당 행의 데이터에 접근하여 조건을 확인할 수 있다.
apply()함수에axis=1인수를 사용하면 행 단위로 함수를 적용할 수 있다. 이 경우에는 각 행을 Series로 전달하고 함수를 적용한다. 따라서 해당 함수에 접근할 때 x라는 변수를 사용하여 각 행의 값에 접근할 수 있다.
참고:
axis=0은 함수가 각 열(column)에 대해 적용됨을 의미한다.axis=1은 함수가 각 행(row)에 대해 적용됨을 의미한다.
따라서df.apply(check, axis=1)은 DataFrame의 각 행에 대해 check 함수를 적용하고,df.apply(check, axis=0)은 DataFrame의 각 열에 대해 check 함수를 적용한다.
Q62. Gender 컬럼값 M인 경우 male F인 경우 female로 값을 변경하여 Gender 컬럼에 새롭게 정의하기. 각 value의 빈도 출력하기
def changeGender(x):
if x == 'M':
return 'male'
else:
return 'female'
df['Gender'] = df.Gender.apply(changeGender)
Ans = df['Gender'].value_counts()
Ans
# 결과값:
# female 5358
# male 4769
# Name: Gender, dtype: int64map() 함수는 시리즈나 데이터프레임의 각 요소에 대해 함수를 적용하여 새로운 값을 반환하는 데 사용된다. 반면에 apply() 함수는 시리즈나 데이터프레임의 행(axis=1) 또는 열(axis=0)에 함수를 적용하여 새로운 결과를 생성하는 데에 활용된다. 따라서 각 요소에 동일한 함수를 적용하려면 map()을 사용하고, 행 또는 열에 대해 복잡한 연산을 적용하려면 apply()를 사용하는 것이 좋다.
