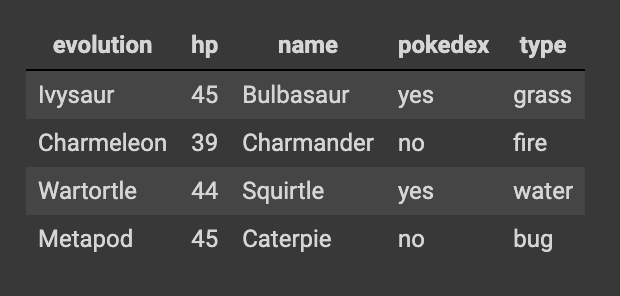
Q103. 상위 데이터 셋의 정보를 활용하여 데이터 프레임을 생성하기
import pandas as pd
df = pd.DataFrame({"name": ['Bulbasaur', 'Charmander','Squirtle','Caterpie'],
"evolution": ['Ivysaur','Charmeleon','Wartortle','Metapod'],
"type": ['grass', 'fire', 'water', 'bug'],
"hp": [45, 39, 44, 45],
"pokedex": ['yes', 'no','yes','no']})
df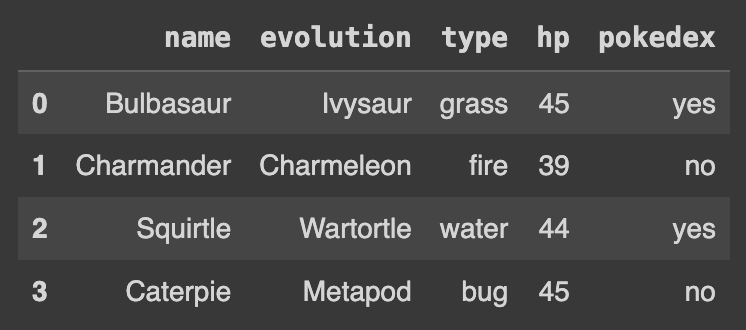
Q104. 컬럼의 순서를 name, type, hp, evolution, pokedex로 변경하기
df = df[['name', 'type', 'hp', 'evolution','pokedex']]
df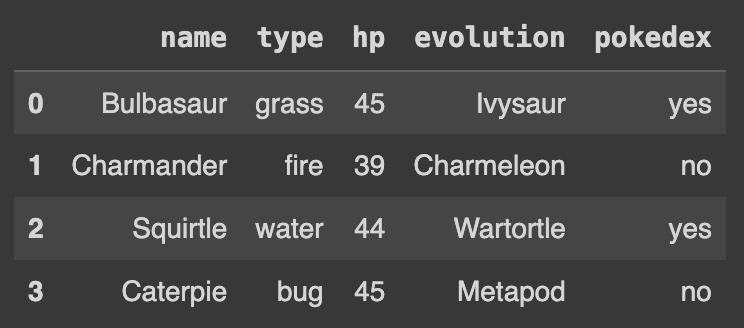
Q105. 새로운 컬럼을 생성하고 임의의 값을 할당하기
df['place'] = ['sea','mountain','lake','forest']
df
새로운 컬럼을 생성할 때는 기존에 있는 변수명을 사용하면 안 된다. 이렇게 하면 기존의 데이터가 변경될 수 있으며, 코드를 이해하기 어려워질 수 있다. 새로운 컬럼을 생성할 때는 다른 이름을 사용하여 충돌을 피해야 한다.
Q106. 각 컬럼에 대한 타입 확인하기
df.info()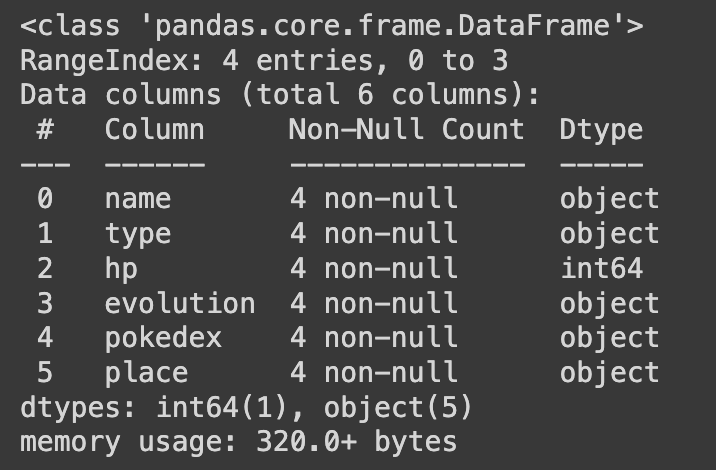
# df.dtypes를 쓰면 타입만 확인 가능
df.dtypes
# 결과값:
# name object
# type object
# hp int64
# evolution object
# pokedex object
# place object
# dtype: object
df.dtypes은 DataFrame의 각 열에 대한 데이터 유형(dtype)을 확인하는 명령이다. 이를 통해 각 열이 어떤 유형의 데이터를 포함하고 있는지 파악할 수 있다.
Q107. hp가 40이상인 데이터 출력하기
df[df['hp'] >= 40]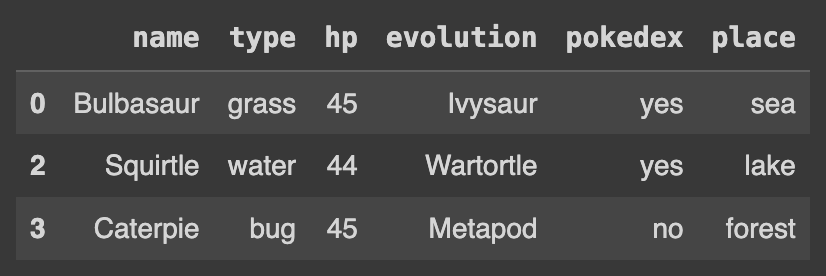
Q107. 전체 데이터 셋 중에서 name과 type만 출력하기
df[['name', 'type']]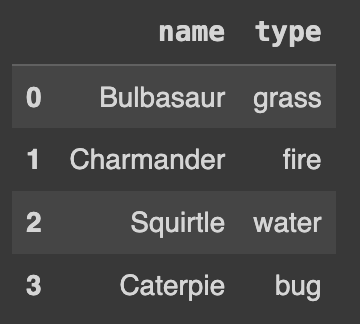
Q108. 데이터 세트에 인덱스를 one, two, three, four로 변경하기. (새로운 객체에 할당 할 것)
df2 = df.copy()
df2.index = ['one', 'two', 'three', 'four']
df2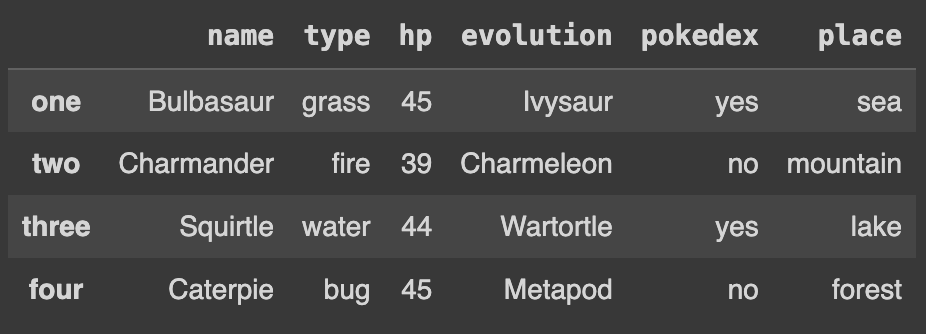
copy()함수는 데이터프레임을 복사하는 데 사용된다. 이 함수를 사용하여 새로운 데이터프레임을 만들고 원본 데이터프레임과는 별개로 데이터를 조작할 수 있다. 이렇게 함으로써 원본 데이터를 손상시키지 않고 안전하게 작업할 수 있다.
예를 들어, df2 = df를 사용하면 새로운 변수 df2가 생성되지만, 내용은 df와 동일한 데이터를 참조한다. 따라서 df2에서의 변경 사항이 df에도 영향을 미쳐 문제점이 발생한다.
df.index는 데이터프레임 df의 인덱스를 나타낸다.
Q109. name을 인덱스로 설정하기
df2.set_index('name', inplace=True)
df2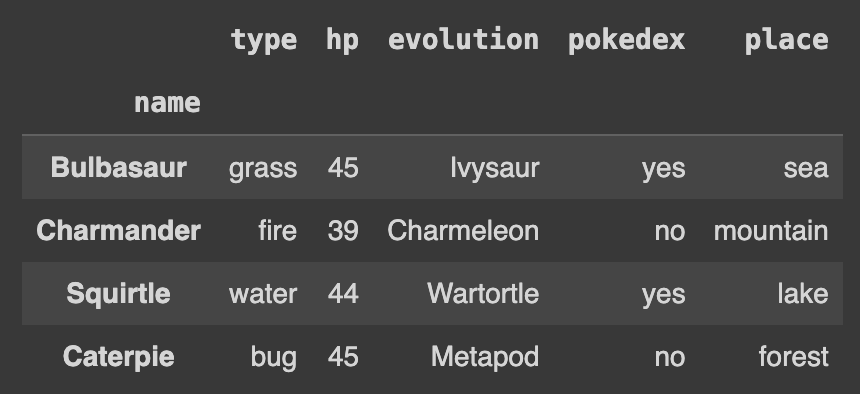
set_index('column')은 데이터프레임의 인덱스를 지정된 열(column)의 값으로 변경한다. 따라서 해당 컬럼에 있는 값들이 데이터프레임의 새로운 인덱스가 된다.
inplace=True옵션을 사용하면 함수가 호출된 데이터프레임 자체를 변경하고,inplace=False로 설정하면 변경된 데이터프레임의 복사본을 반환한다. 이 옵션은 데이터프레임을 직접 수정하고자 할 때 유용하게 사용될 수 있다.
inplace=True를 사용하지 않으면 함수가 적용된 데이터프레임이 원본 데이터프레임에 바로 적용되지 않는다. 따라서 원본 데이터프레임을 직접 수정하고자 할 때는inplace=True를 사용해야 한다.
Q110. 데이터 세트를 csv파일로 저장하기
df2.to_csv('sample.csv')
to_csv('파일명.csv')를 사용하면 데이터프레임을 CSV 파일로 저장할 수 있다.
csv파일의 저장 경로 확인은
import os
os.getcwd() # 저장할 csv 파일의 저장 경로 확인
os.chdir('특정경로') # 특정 경로에 작업 디렉토리 변경Q111. 아래와 같이 새로운 데이터 프레임을 생성하고, 기존 데이터 프레임과 병합하기

new_df = pd.DataFrame({"name": ['Pikachu'],
"type": ['electric'],
"hp": [35],
"evolution": ['Raichu'],
"pokedex": ['yes'],
"place": ['forest']})
new_df
Ans = pd.concat([df, new_df], axis=0).reset_index(drop=True)
Ans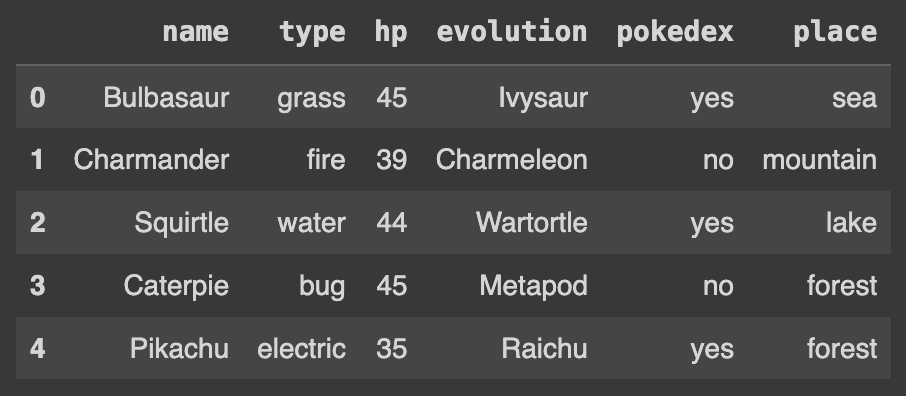
reset_index(drop=True)를 사용하면 인덱스가 재설정되고, 이전의 인덱스는 삭제된다. 이렇게 함으로써 새로운 인덱스가 생성되고 순차적으로 할당된다. 이를 통해 생성한 테이블을 합칠 때 인덱스가 꼬이는 상황을 방지할 수 있다.
Q112. Ans에서 place 1번째와 3번째 row에 NaN값을 입력하기
import numpy as np
# 데이터프레임 'Ans'의 인덱스가 0과 2인 행의 'place' 열을 NaN(결측치)으로 설정
Ans.loc[[0,2],'place'] = np.nan
Ans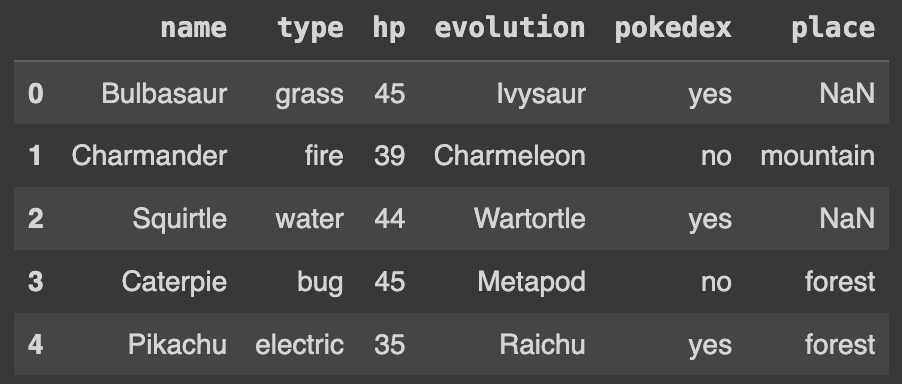
위 이미지와 같이 해당 행의 'place' 열 값이 결측치로 변경된다.
import numpy as np는 파이썬에서 NumPy 라이브러리를 불러온다.
넘파이(NumPy)는 파이썬에서 과학적 및 수학적 계산을 수행하는 데 사용되는 핵심 라이브러리 중 하나이다. 넘파이는 다차원 배열(특히 대규모 데이터를 다룰 때 유용)을 처리하는 데 특화되어 있으며, 이러한 배열을 조작하고 연산하는 다양한 함수를 제공한다. 또한 넘파이는 선형 대수, 푸리에 변환 및 난수 생성과 같은 다양한 수학적 기능도 제공한다.
Null값을 선언을 할 때는np.nan옵션을 넣어준다.np.nan은 NumPy에서 결측치를 나타내는 값이다. 이것을 사용하여 데이터프레임에서 결측치를 나타낼 수 있다.
