Q93. 상위 10개의 행을 출력하기
Ans = df.head(10)
Ans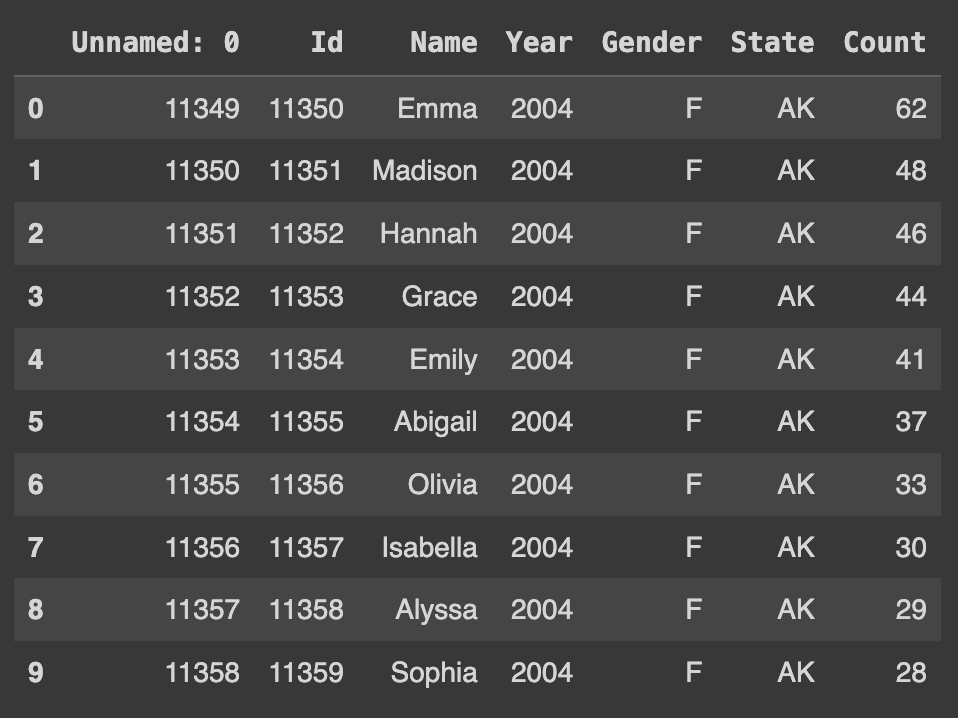
Q94. 'Unnamed: 0' and 'Id' 제거하기
# deletes 'Unnamed: 0'
del df['Unnamed: 0']
# deletes 'Id'
del df['Id']
df.head()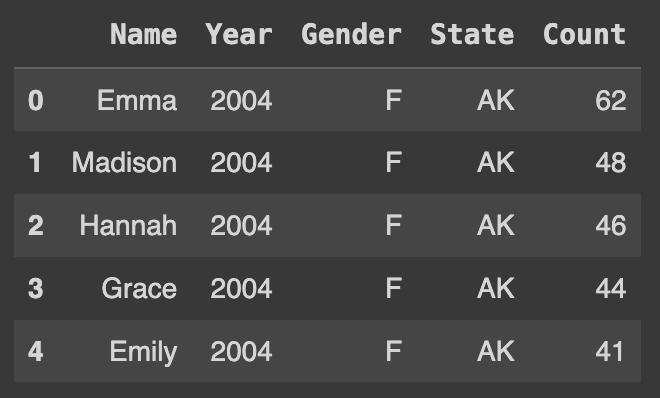
del키워드를 사용하여 DataFrame에서 열을 삭제할 수 있다.
원본 데이터를 삭제하는 것은 데이터 손실의 위험이 있기 때문에 권장되지 않는다. 데이터를 변경하거나 정제할 때는 원본 데이터를 유지하고, 변경된 데이터를 새로운 변수에 할당하여 작업하는 것이 좋다. 이렇게 하면 필요한 경우에 원본 데이터로 되돌릴 수 있다
따라서 필요한 데이터를 삭제하는 대신, 필요한 데이터만을 선택하여 아래와 같이 새로운 데이터프레임을 만드는 것이 좋다. 이렇게 하면 원본 데이터는 보존되면서 필요한 데이터만을 가지고 작업할 수 있다.
df2 = df[['Name', 'Year', 'Gender', 'State', 'Count']]Q95. 데이터셋에 남성 이름이 더 많나요, 아니면 여성 이름이 더 많나요?
df['Gender'].value_counts()
# 결과값:
# F 558846
# M 457549
# Name: Gender, dtype: int64
value_counts()메서드는 시리즈의 고유한 값의 빈도수를 반환한다. 이 메서드를 호출하면 각 고유한 값이 시리즈에 몇 번씩 나타나는지를 알 수 있다. 이는 주로 범주형 데이터에 대해 유용하게 사용된다.
예를 들어, 성별이나 학력 수준과 같은 범주형 변수의 빈도수를 확인할 때 자주 사용된다.
Q96. 데이터셋을 이름별로 그룹화여 'Count'를 Sum하고, names라는 변수에 할당하기. (상위 5개의 행만 출력)
names = pd.DataFrame(df.groupby('Name')['Count'].sum())
names.sort_values(by=['Count'], ascending=0).head(5)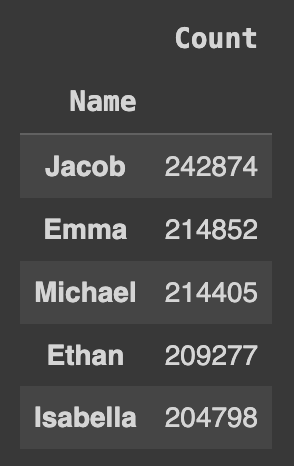
sort_values(by=['열_이름'], ascending=False)은 특정 열을 기준으로 데이터프레임을 내림차순으로 정렬한다. 여기서ascending=False는 내림차순으로 정렬하겠다는 의미이다.
ascending=0 또는 ascending=False는 모두 같은 내림차순 정렬을 나타낸다.
Q97. 서로 다른 이름은 총 몇개인가요?
df['Name'].nunique()
nunique()함수는 고유한 값의 개수를 반환하는 메서드이다. 이를 통해 데이터의 다양성을 빠르게 확인할 수 있다.
Q98. 가장 많이 등장한 이름은?
# 'Count' 열에서 가장 큰 값을 갖는 행을 필터링
names[names.Count == names.Count.max()]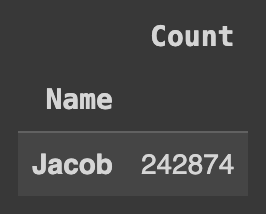
Q99. 가장 적게 등장한 이름은 몇개인가요?
# 'Count' 열에서 최소 값을 가진 이름의 수 반환
len(names[names.Count == names.Count.min()])
# 결과: 2578
len()함수는 DataFrame에서 조건을 충족하는 행의 개수를 반환한다.
Q100. 중앙값(median)의 개수를 가지고 있는 이름은?
names[names.Count == names.Count.median()]
median()는 중앙값을 구하는 명령어이다.
Q101. 이름 개수(Count)의 표준편차 구하기
names.Count.std()
# 결과: 11006.06946789057
std()는 표준편차를 구하는 명령어이다.
Q102. names의 평균, 최소, 최대, 표준편차, 4분위수를 계산하기
names.describe()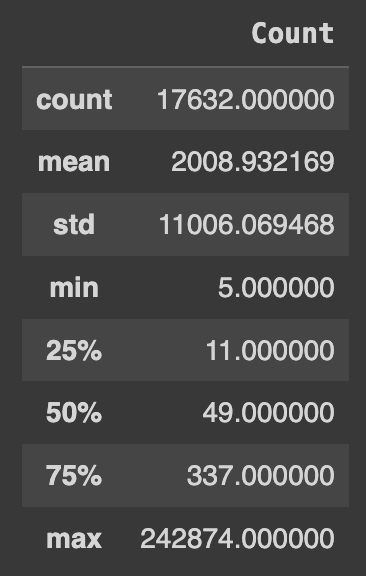
describe()함수는 DataFrame의 각 열에 대한 요약 통계를 제공한다. 이는 평균, 표준편차, 최솟값, 25%, 50%, 75% 백분위수 및 최댓값을 포함한다.
