1. 데이터 시각화
import matplotlib.pyplot as plt import koreanize_matplotlib
koreanize_matplotlib는 한글 폰트를 사용하여 Matplotlib 그래프의 한글 텍스트를 보기 좋게 만들어주는 라이브러리이다. 이를 통해 한글을 포함한 그래프를 손쉽게 작성할 수 있다.
만약 matplotlib가 설치되어 있지 않다면, 아래와 같이 설치할 수 있다.
%pip install matplotlib %pip install koreanize-matplotlib
그 후에는 코드를 실행하여 모듈을 가져올 수 있다.
plt.rc('font', family='폰트이름')은 Matplotlib에서 사용되는 폰트를 설정하는 방법 중 하나이다. 이 코드를 사용하면 그래프에서 한글 폰트를 지정할 수 있다.
koreanize_matplotlib 라이브러리를 사용하면 plt.rc()를 사용하지 않고도 Matplotlib의 한글 폰트를 설정할 수 있다. 일반적으로 한글 폰트를 설정하는데 사용되는 plt.rc() 대신에 koreanize_matplotlib 라이브러리의 기능을 활용하여 한글 폰트를 적용할 수 있다.
1) 가로 막대 그래프로 시각화하기
plt.figure(figsize=(10,10))
plt.barh(width = lang_frequency.values, y=lang_frequency.index)
plt.title('언어별 사용자 수', fontsize=15, fontweight='bold')
plt.xlabel('사용자 수', fontweight='bold')
plt.ylabel('개발언어', fontweight='bold')
plt.xticks(np.arange(0, lang_frequency.values.max()+2000, 2000), rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()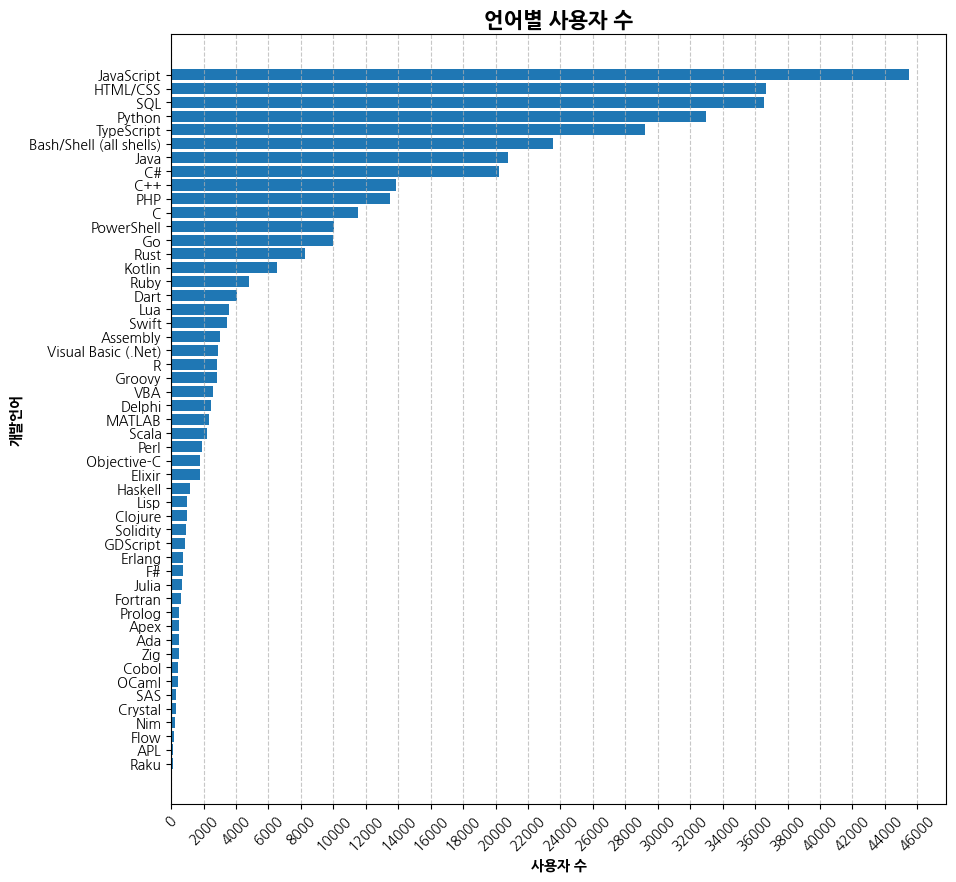
-
figure()함수: 새로운 그림(figure) 생성한다.figsize매개변수: (가로 크기, 세로 크기)로 그래프의 크기 지정한다.
-
barh()함수: 가로 막대 그래프 그리기width매개변수: 막대의 너비 지정한다.y매개변수: 각 막대의 위치 지정한다.
-
title()함수: 그래프의 제목 설정fontsize매개변수: 제목의 폰트 크기fontweight매개변수: 레이블의 폰트 두께를 지정한다. 가능한 값으로는 'normal'(기본값), 'bold', 'light', 'heavy', 'regular' 등이 있다.
-
xlabel()함수: x축 레이블 설정한다. -
ylabel()함수: y축 레이블 설정한다. -
xticks()함수: x축의 눈금 설정한다.rotation=45매개변수: 레이블을 45도로 회전한다.
-
grid()함수: 그래프에 격자 라인 추가한다.axis매개변수: 그리드 라인을 추가할 축(x축 또는 y축 방향) 지정한다.linestyle매개변수: 그래프의 선 스타일을 지정한다. 예를 들어, '-'(실선), '--'(대쉬), ':'(점선), '-.'(대쉬-점선) 등이 있다.alpha매개변수: 그래프 요소의 투명도 조절한다.
-
plt.show(): 그래프를 화면에 출력한다.
참고:
axis매개변수는 0부터 1까지의 값을 가지며, 0에 가까울수록 투명하고 1에 가까울수록 불투명하다.plt.show()함수를 호출하지 않으면 그래프가 표시되지 않는다.
2) 가장 큰 값을 가진 행 반환하기
# 가장 큰 값을 가진 상위 10개의 행
df.nlargest(10)nlargest() 함수는 데이터프레임에서 가장 큰 값을 가진 행을 반환하는 메서드이다.
예를 들어, df.nlargest(n, 'column')은 'column' 열에서 가장 큰 값을 가진 상위 n개의 행을 반환한다. 이때 'column'은 데이터프레임에서 값을 비교하고 기준으로 삼을 열의 이름이다.
만약 'column'을 지정하지 않으면 기본적으로 인덱스를 기준으로 가장 큰 값을 찾는다.
3)
top10_lang = lang_frequency.nlargest(10).sort_values(ascending=True)
total_id = lang_df['Id'].nunique()
top10_lang_percentage = (top10_lang / total_id) * 100
plt.figure(figsize=(10, 10))
lang_bars = plt.barh(width=top10_lang.values, y = top10_lang.index)
for bar, percentage in zip(lang_bars, top10_lang_percentage):
plt.text(x=bar.get_width() - top10_lang.values.max()*0.1, y=bar.get_y() + bar.get_height()/2, s=f'{percentage: .2f}%',
color='white', fontweight='bold', fontsize=15, va='center', ha='center')
plt.title('개발자들이 가장 많이 사용하는 개발언어 10위 (전체 응답자 비율 %)', fontsize=15, fontweight='bold')
plt.xlabel('사용자 수', fontweight='bold')
plt.ylabel('개발 언어', fontweight='bold')
plt.xticks(np.arange(0, top10_lang.values.max()+5000,5000))
plt.yticks(rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()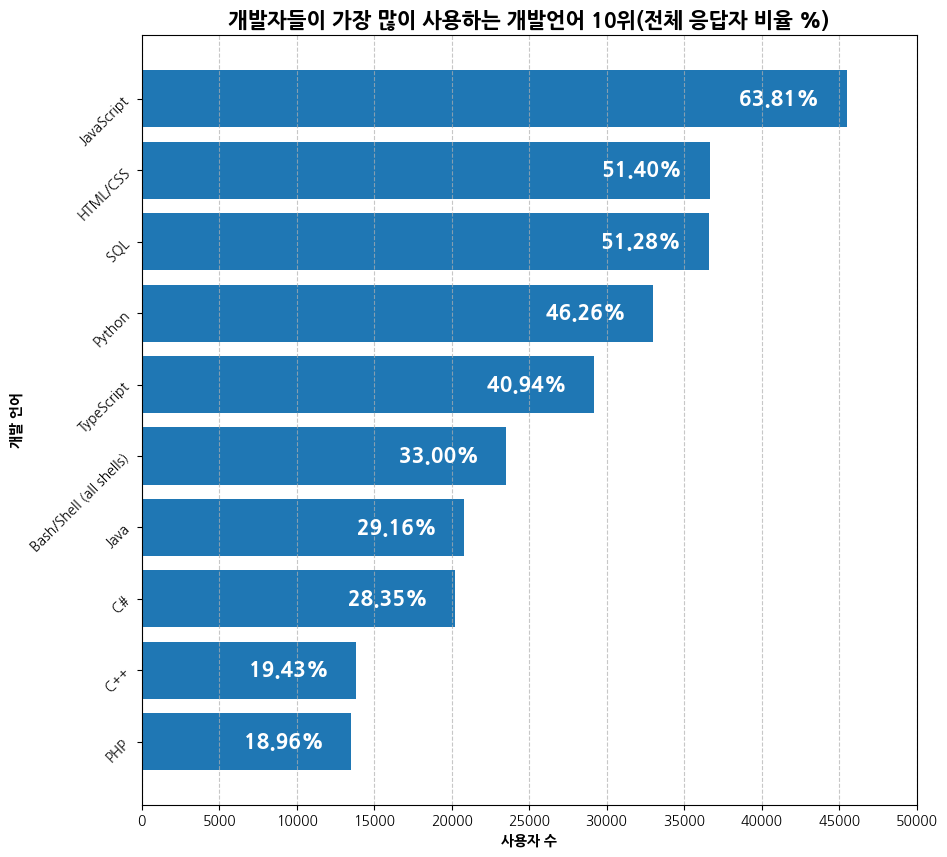
-
nlargest(n):nlargest()함수: DataFrame 또는 Series에서 가장 큰 값을 가진 요소를 반환한다.n: 반환할 상위 요소의 개수를 지정한다.
-
sort_values(ascending=True):sort_values()함수: DataFrame 또는 Series를 주어진 열의 값을 기준으로 정렬한다.ascending: 정렬 순서를 결정한다. True이면 오름차순, False이면 내림차순으로 정렬된다.
-
plt.figure(figsize=(10, 10)): 새로운 그림(figure)을 생성한다.figsize매개변수: 그림의 크기를 지정한다.(가로, 세로)형식의 튜플로 크기를 지정할 수 있다.
-
plt.barh(): 수평 막대 그래프를 그린다.width매개변수: 막대의 너비를 지정한다.y매개변수: 막대의 y축 위치를 지정한다.
-
plt.text(): 그래프에 텍스트를 추가한다.x, y매개변수: 텍스트가 표시될 위치를 지정한다.s매개변수: 텍스트 내용을 지정한다. (s의 약자는string)color매개변수: 텍스트의 색상을 지정한다.va매개변수: 텍스트의 수직 방향 정렬을 지정한다. 'center', 'top', 'bottom' 중 하나를 선택할 수 있다.ha매개변수: 텍스트의 수평 방향 정렬을 지정한다. 'center', 'right', 'left' 중 하나를 선택할 수 있다.
매개변수
va와ha
va는 vertical alignment의 약자ha는 horizontal alignment의 약자
-
plt.xticks(): x축의 눈금을 설정한다.np.arange()함수 사용하여 눈금의 간격을 지정한다.
-
plt.yticks(): y축의 눈금을 설정한다.rotation매개변수: 눈금 레이블의 텍스트를 회전시킨다. 이는 눈금 레이블이 긴 경우에 유용하다.
-
plt.grid(): 그리드 라인을 추가한다.axis매개변수: 그리드 라인을 추가할 축을 지정한다.linestyle매개변수: 그리드 라인의 스타일을 지정한다.alpha매개변수: 그리드 라인의 투명도를 지정한다.
4)
plt.figure(figsize=(10, 5))
prflang_bars = plt.barh(width=top10_prflang.values, y=top10_prflang.index, color='salmon')
plt.title('개발자들이 가장 많이 사용하고 싶어하는 개발언어 10위 (전체 응답자 비율 %)', fontsize=15, fontweight='bold')
plt.xlabel('사용자 수', fontweight='bold')
plt.ylabel('개발언어', fontweight='bold')
plt.xticks(np.arange(0, top10_prflang.values.max()+5000, 5000))
for bar, pencentage in zip(prflang_bars, top10_prflang_percentage):
plt.text(bar.get_width()-(top10_prflang.values.max() * 0.1), bar.get_y()+bar.get_height()/2, f'{percentage: .2f}%',
color='white', fontsize=15, fontweight='bold', ha='center', va='center')
plt.grid(axis='x', linestyle='--', alpha =0.7)
plt.show()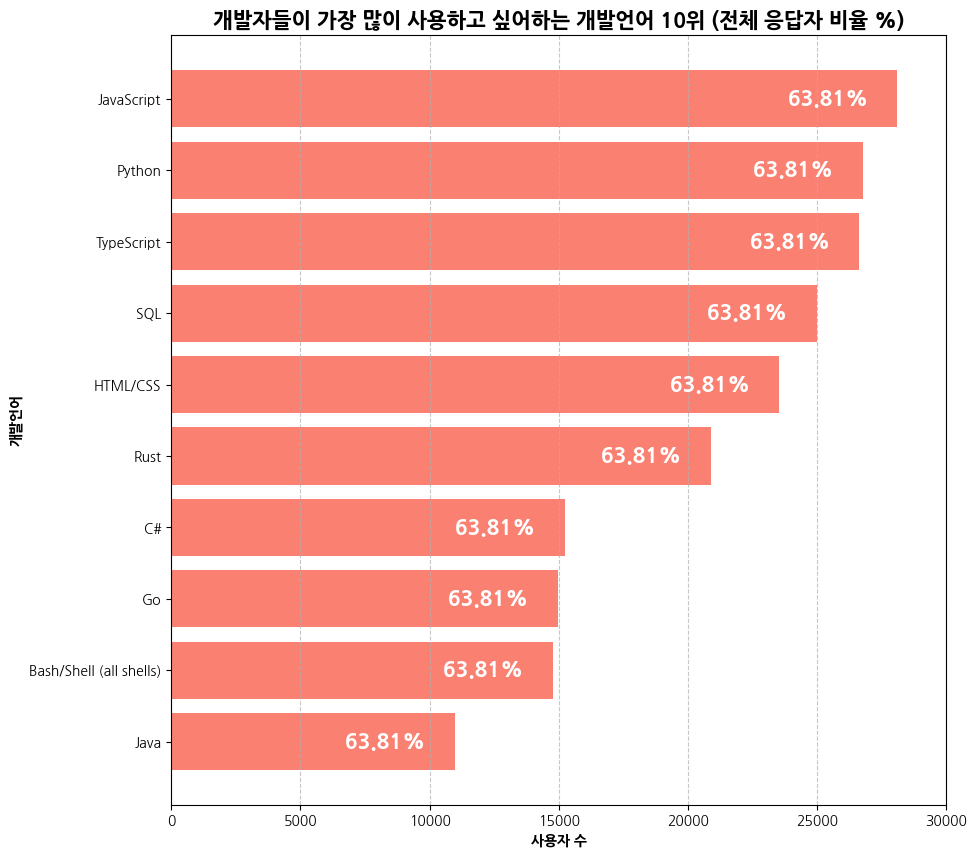
zip()함수는 여러 개의 iterable(순회 가능한 객체)를 받아서 각 iterable에서 한 번씩 요소를 가져와서 튜플로 묶어주는 역할을 한다. 즉, 여러 개의 리스트나 배열 등을 동시에 순회하며 해당 위치의 요소들을 묶어준다.
예를 들어,
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
for x, y in zip(list1, list2):
print(x, y)
# 결과값:
# 1 a
# 2 b
# 3 c위 코드는 두 개의 리스트를 동시에 순회하면서 각 리스트에서 같은 위치에 있는 요소들을 가져와서 출력합니다.
zip() 함수는 가장 짧은 iterable이 모두 소진되면 멈추므로, 길이가 다른 경우에는 가장 짧은 길이에 맞추어 순회됩니다.
f'{percentage: .2f}%': 표시될 텍스트 형식을 지정한다. 소수점 둘째 자리까지 표시하고 '%' 기호를 추가한다.
5)
plt.figure(figsize=(20, 10))
# 그래프 1 - 현재 사용하는 언어
plt.subplot(1, 2, 1)
lang_bars = plt.barh(width=top10_lang.values, y = top10_lang.index)
for bar, percentage in zip(lang_bars, top10_lang_percentage):
plt.text(x=bar.get_width() - top10_lang.values.max()*0.1, y=bar.get_y() + bar.get_height()/2, s=f'{percentage: .2f}%',
color='white', fontweight='bold', fontsize=15, va='center', ha='center')
plt.title('개발자들이 가장 많이 사용하는 개발언어 10위(전체 응답자 비율 %)', fontsize=15, fontweight='bold')
plt.xlabel('사용자 수', fontweight='bold')
plt.ylabel('개발 언어', fontweight='bold')
plt.xticks(np.arange(0, top10_lang.values.max()+5000,5000))
plt.yticks(rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 그래프 2 - 사용을 희망하는 언어
plt.subplot(1, 2, 2)
prflang_bars = plt.barh(width=top10_prflang.values, y=top10_prflang.index, color='salmon')
plt.title('개발자들이 가장 많이 사용하고 싶어하는 개발언어 10위 (전체 응답자 비율 %)', fontsize=15, fontweight='bold')
plt.xlabel('사용자 수', fontweight='bold')
plt.ylabel('개발언어', fontweight='bold')
plt.xticks(np.arange(0, top10_prflang.values.max()+5000, 5000))
for bar, pencentage in zip(prflang_bars, top10_prflang_percentage):
plt.text(bar.get_width()-(top10_prflang.values.max() * 0.1), bar.get_y()+bar.get_height()/2, f'{percentage: .2f}%',
color='white', fontsize=15, fontweight='bold', ha='center', va='center')
plt.grid(axis='x', linestyle='--', alpha =0.7)
plt.tight_layout()
plt.show()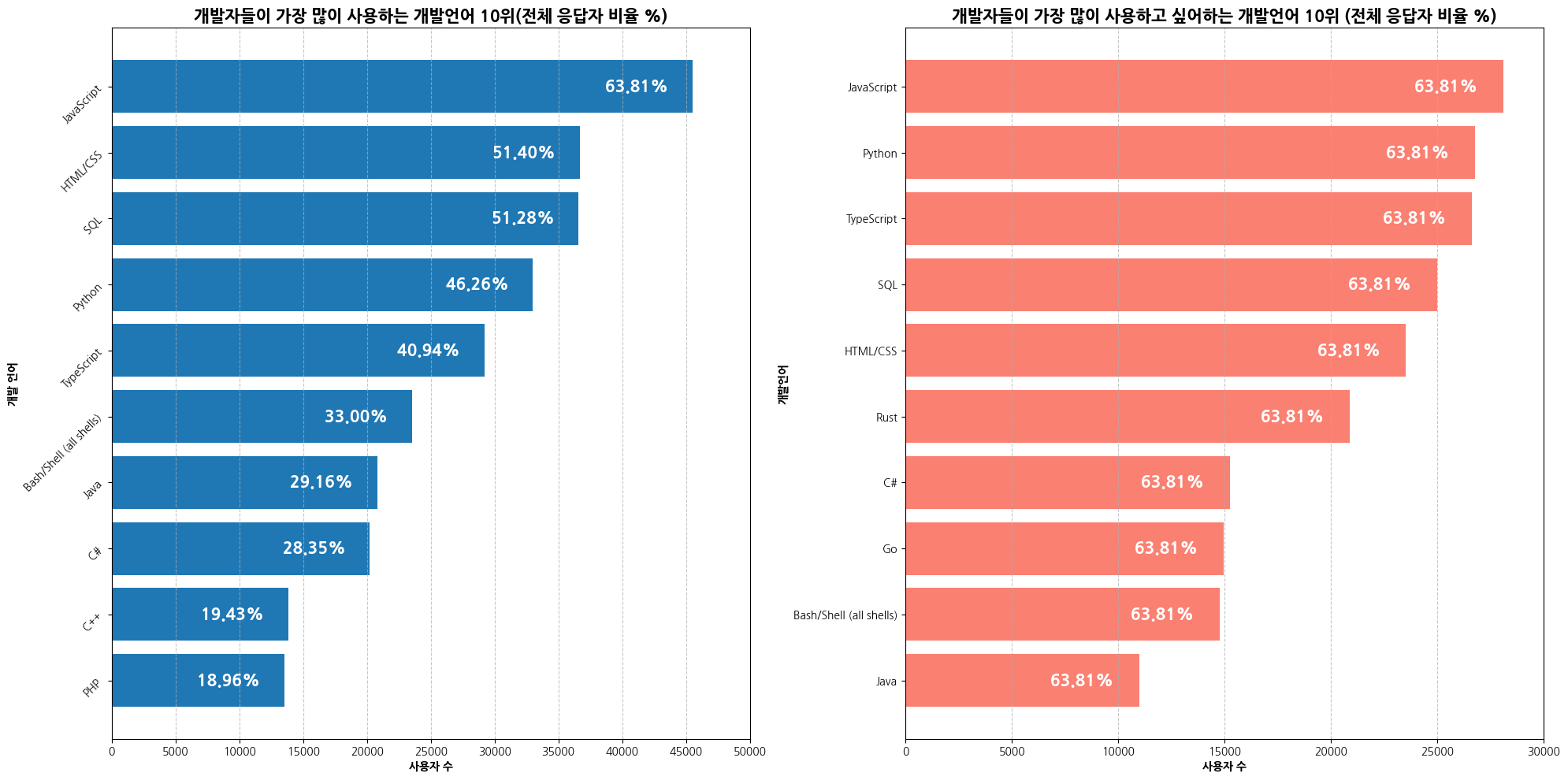
plt.subplot()함수는 하나의 그림(figure) 안에 여러 개의 서브플롯(subplot)을 생성한다. 이 함수를 사용하여 행(row)과 열(column)의 수를 지정하여 여러 개의 서브플롯을 배열할 수 있다.plt.subplot(nrows, ncols, index) # nrows: 전체 그림 영역을 행(row)으로 나눌 개수 # ncols: 전체 그림 영역을 열(column)으로 나눌 개수 /* index: 생성할 서브플롯의 인덱스를 지정. 이 값은 1부터 시작하여 왼쪽에서 오른쪽 방향으로, 위에서 아래 방향으로 채워진다. */
예를 들어, plt.subplot(1, 2, 1)은 1행 2열의 서브플롯 중 첫 번째(왼쪽) 서브플롯을 선택한다.
그러면 선택한 서브플롯에 그래프를 그리거나 설정을 적용할 수 있다. 이후에 다른 서브플롯을 선택하여 그래프를 추가로 그릴 수 있다.
plt.tight_layout()함수는 그래프의 요소들이 겹치지 않도록 자동으로 레이아웃을 조정해주는 함수이다. 주로 여러 개의 서브플롯(subplot)을 한 번에 그릴 때 사용하며, 서브플롯 간의 간격을 조정하여 그래프의 가독성을 향상시킨다.
- 이 함수를 호출하면 플롯 요소들이 서로 겹치거나 너무 붙어있지 않도록 축의 위치나 그래픽 요소들의 크기를 조정하여 자동으로 최적의 레이아웃을 만들어 준다. 이는 그래프를 더 보기 쉽게 만들어주고, 레이아웃 조정에 따른 수작업을 줄여준다.
- 일반적으로
plt.show()전에 호출하여 사용한다. 따로 매개변수를 받지 않으며, 호출할 때마다 현재 그림의 레이아웃이 재조정된다.
6)
plt.figure(figsize=(10, 5))
plt.barh(width=lang_frequency.values,
y=np.arange(len(lang_frequency)),
tick_label=lang_frequency.index,
alpha=0.6)
for index, lang in enumerate(lang_frequency.index):
prflang_count = prflang_frequency.loc[lang]
plt.barh(y=index, width=prflang_count, color='salmon', alpha=0.6)
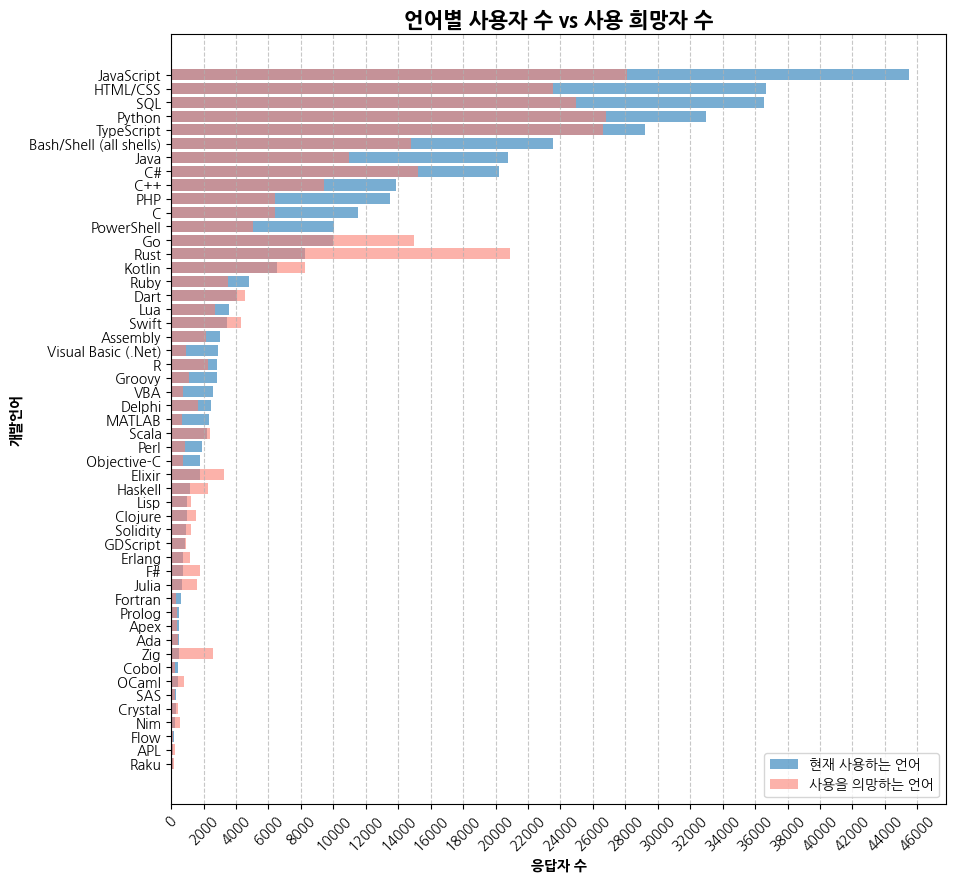
plt.title('언어별 사용자 수 vs 사용 희망자 수', fontsize=15, fontweight='bold')
plt.ylabel('개발언어', fontweight='bold')
plt.xlabel('응답자 수', fontweight='bold')
plt.xticks(np.arange(0, max(lang_frequency.values.max(), prflang_frequency.values.max())+2000, 2000), rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.legend(['현재 사용하는 언어', '사용을 의망하는 언어'], loc='lower right')
plt.show()plt.barh():tick_label매개변수: 막대 그래프의 각 막대에 대한 레이블을 지정한다.
enumerate()함수는 주어진 시퀀스(리스트, 튜플, 문자열 등)의 각 요소에 대해 인덱스와 값을 순회하면서 반복하는 파이썬 내장 함수이다.
- 이 함수는 보통 for 반복문과 함께 사용되며, 반복하려는 시퀀스의 각 요소에 대해 인덱스와 값을 함께 가져올 수 있다.
languages = ['Python', 'Java', 'C++', 'JavaScript']
for index, lang in enumerate(languages):
print(f"Index: {index}, Language: {lang}")
# 결과값:
# Index: 0, Language: Python
# Index: 1, Language: Java
# Index: 2, Language: C++
# Index: 3, Language: JavaScript
loc[]은 Pandas DataFrame에서 특정 행(row)이나 열(column)을 선택하기 위해 사용되는 인덱싱(indexing) 메서드이다.loc[]을 사용하여 행을 선택할 때는 행의 라벨(label)을 기준으로 선택하며, 열을 선택할 때는 열의 라벨을 기준으로 선택한다.
# 특정 행 선택
df.loc['행_라벨']
# 특정 열 선택
df.loc[:, '열_라벨']
# 특정 행과 열 동시에 선택
df.loc['행_라벨', '열_라벨']loc[]을 사용하여 선택된 데이터는 Series나 DataFrame 형식으로 반환된다. 따라서 선택된 데이터를 변수에 할당하여 나중에 사용할 수 있다.
예를 들어,
A B C
0 1 4 7
1 2 5 8
2 3 6 9여기서 loc[]을 사용하여 특정 행이나 열을 선택할 수 있다.
import pandas as pd
# 예시 DataFrame 생성
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
# 특정 행 선택
row = df.loc[0]
# 결과: row는 Series 객체로, {'A': 1, 'B': 4, 'C': 7}을 나타냄
# 특정 열 선택
col = df.loc[:, 'B']
# 결과: col은 Series 객체로, {0: 4, 1: 5, 2: 6}을 나타냄
# 특정 행과 열 동시 선택
value = df.loc[1, 'B']
# 결과: value는 5
plt.legend()함수는 그래프에 범례(legend)를 추가하는 함수이다. 범례는 그래프에 표시된 데이터의 의미를 설명해 주는 역할을 한다.
plt.legend() 함수는 특별한 매개변수를 받지 않고 호출할 수 있다. 이 함수를 호출하면 그래프에 설정된 레이블을 바탕으로 자동으로 범례가 생성되며, 그래프의 기본 위치에 표시된다.
범례를 특정 위치에 표시하고 싶다면 loc 매개변수를 사용하여 원하는 위치를 지정할 수 있다. 다양한 위치 옵션들이 있으며, 'upper left', 'upper right', 'lower left', 'lower right' 등이 있다. 또한 'best' 옵션을 사용하여 최적의 위치를 자동으로 선택할 수도 있다.
예를 들어, plt.legend(loc='upper left')와 같이 사용하면 범례가 그래프의 왼쪽 상단에 표시된다.
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
plt.subplots() 함수는 Matplotlib에서 여러 개의 서브플롯(subplot)을 포함하는 그림(figure)을 생성하는 함수이다. 이 함수를 사용하면 행(row)과 열(column)의 개수를 지정하여 원하는 서브플롯 레이아웃을 만들 수 있다.
fig, axes = plt.subplots(nrows, ncols, figsize=(width, height))
# nrows: 생성할 서브플롯의 행(row) 수를 나타낸다.
# ncols: 생성할 서브플롯의 열(column) 수를 나타낸다.
# figsize: 생성할 그림(figure)의 크기를 지정한다. (가로 길이, 세로 길이) 형식의 튜플로 입력된다.이 함수를 호출하면 fig 변수에는 생성된 그림 객체가, axes 변수에는 생성된 서브플롯의 축(axes) 객체들이 배열 형태로 저장된다. 이후에 각 축 객체를 사용하여 서브플롯에 그래프를 그릴 수 있다.
참고:
ax # 결과값: # array([<Axes: >, <Axes: >], dtype=object)
ax 변수는 plt.subplots() 함수에서 생성된 서브플롯(subplot)을 담고 있는 배열(array)이다. 각 서브플롯은 Axes 객체로 나타내며, 이 배열에 저장되어 있다.
따라서 ax를 출력하면 배열에 포함된 각 서브플롯의 정보가 출력된다. 이 경우에는 두 개의 서브플롯이 생성되었으며, 각각의 서브플롯을 Axes 객체로 나타내고 있다.
7)
fig, axes = plt.subplots(1, 2, figsize=(20, 10))
# 왼쪽 그래프
axes[0].barh(width=data_top10_lang.values, y=data_top10_lang.index)
axes[0].set_title('데이터 관련 직군 - 가장 인기 있는 개발언어 10위 (현재 사용)', fontsize=15, fontweight='bold')
axes[0].set_xlabel('응답자 수', fontweight='bold')
axes[0].set_ylabel('개발언어', fontweight='bold')
axes[0].grid(axis='x', linestyle='--', alpha=0.7)
# 오른쪽 그래프
axes[1].barh(width=data_top10_prflang.values, y=data_top10_prflang.index, color = 'salmon')
axes[1].set_title('데이터 관련 직군 - 가장 인기 있는 개발언어 10위 (사용 희망)', fontsize=15, fontweight='bold')
axes[1].set_xlabel('응답자 수', fontweight='bold')
axes[1].set_ylabel('개발언어', fontweight='bold')
axes[1].grid(axis='x', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()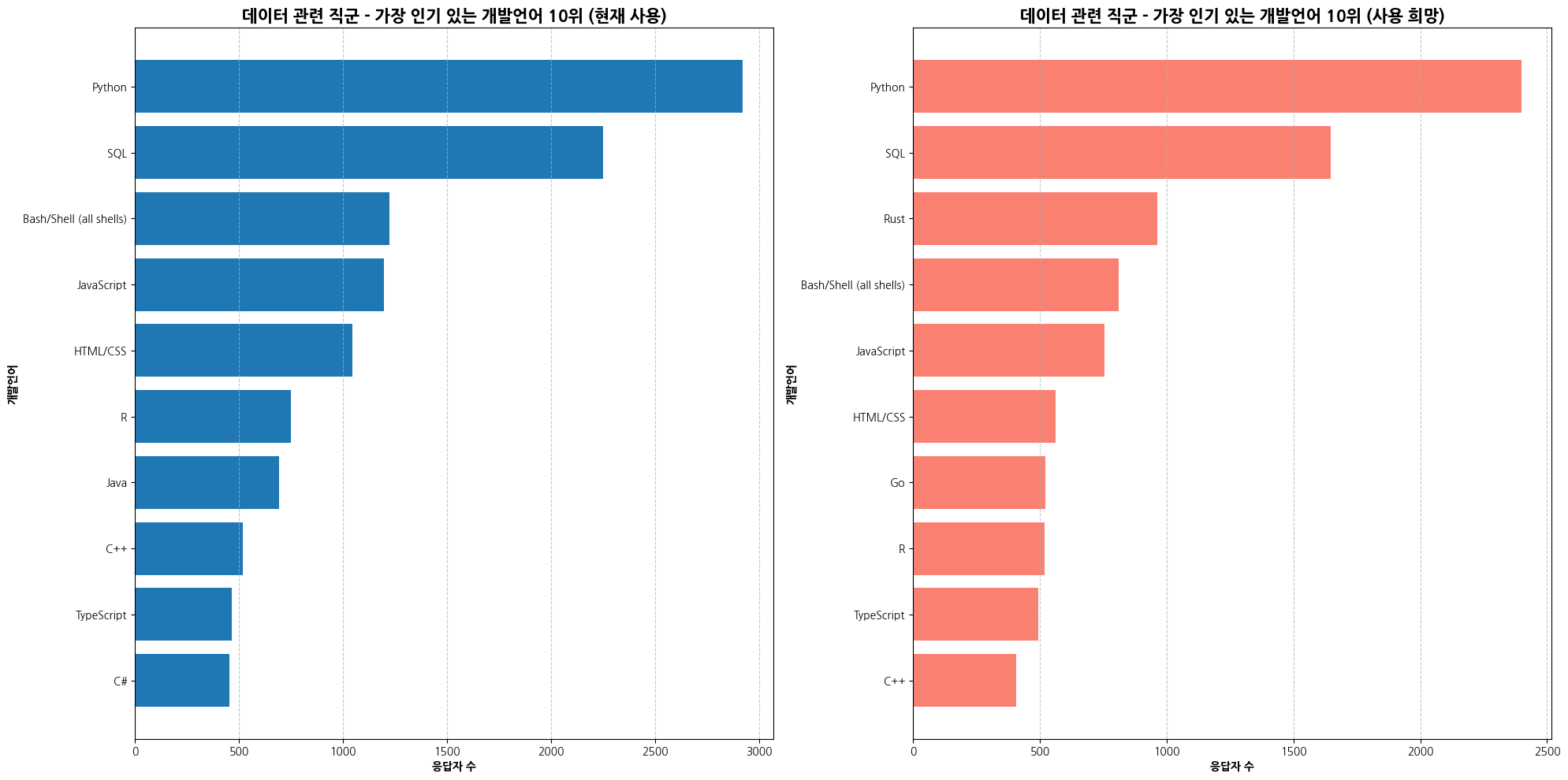
Matplotlib의 객체 지향 인터페이스를 사용하면 그림(Figure) 객체와 축(Axes) 객체를 명시적으로 다룰 수 있다. 따라서 그림과 축을 직접적으로 다루기 위해 set_title(), set_xlabel(), set_ylabel()과 같은 메서드를 사용한다.
각 메서드는 특정한 축(Axes) 객체에 대해 호출되며, 해당 축에 대한 제목, x축 레이블, y축 레이블을 설정한다. 이러한 메서드를 사용하면 여러 개의 축이 있는 그림을 생성하거나 각 축에 대해 개별적으로 레이블을 설정할 수 있다.
반면에 title(), xlabel(), ylabel()과 같은 함수는 현재 활성화된 축(Axes)에 대해 각각 제목, x축 레이블, y축 레이블을 설정한다. 이 함수들은 현재 활성화된 축을 기본으로 사용하기 때문에, 여러 개의 축을 가진 그림을 다룰 때는 명확하지 않을 수 있다.
그러므로 객체 지향적인 스타일을 따르기 위해 set_title(), set_xlabel(), set_ylabel()을 사용한다.
set_title()메소드: 그래프의 제목을 설정한다.set_xlabel()메소드: x축의 레이블을 설정한다.set_ylabel()메소드: y축의 레이블을 설정한다.
예를 들어, 두 개의 서브플롯을 가진 그래프를 생성하고 각 서브플롯에 제목과 축 레이블을 설정하는 경우, 다음과 같이 코드를 작성할 수 있다.
import matplotlib.pyplot as plt
# 두 개의 서브플롯을 가진 그래프 생성
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 첫 번째 서브플롯 설정
axes[0].plot([1, 2, 3], [4, 5, 6])
axes[0].set_title('첫 번째 서브플롯의 제목')
axes[0].set_xlabel('X축 레이블')
axes[0].set_ylabel('Y축 레이블')
# 두 번째 서브플롯 설정
axes[1].scatter([1, 2, 3], [4, 5, 6])
axes[1].set_title('두 번째 서브플롯의 제목')
axes[1].set_xlabel('X축 레이블')
axes[1].set_ylabel('Y축 레이블')
plt.tight_layout()
plt.show()이 코드에서는 set_title(), set_xlabel(), set_ylabel() 메서드를 사용하여 각 서브플롯의 제목과 축 레이블을 설정한다. 이 메서드들은 각각 Axes 객체에 대해 호출되어 해당 객체에 대한 설정을 변경한다.
8)
plt.figure(figsize=(10, 5))
x_indices = np.arange(len(data_top10_lang.index))
bar_width = 0.25
for index, dev_type in enumerate(DATA_DEVS):
# 해당 직군 = dev_type 데이터를 필터링 한다 (lang_df)
filtered_data_lang_df = data_lang_df[data_lang_df['DevType'] == dev_type]
# 필터링된 데이터의 언어 사용빈도 계산 (lang_frequency)
data_lang_frequency = filtered_data_lang_df['LanguageHaveWorkedWith'].value_counts()
# 상위 10개 언어에 대한 빈도만 선택
data_lang_frequency_top10 = data_lang_frequency[data_lang_frequency.index.isin(data_top10_lang.index)]
values = [data_lang_frequency_top10[lang] for lang in data_top10_lang.index]
# 해당 직군의 막대를 그림
plt.bar(height=values, x=x_indices + index * bar_width, width=bar_width, label=dev_type)
plt.xticks(x_indices + bar_width, data_top10_lang.index, rotation=45)
plt.yticks(np.arange(0, data_lang_frequency.values.max() + 400, 100))
plt.title('데이터 관련 직군별 언어 사용 현황 (TOP 10 언어)', fontsize=15, fontweight='bold')
plt.xlabel('개발언어', fontweight='bold')
plt.ylabel('응답자 수', fontweight='bold')
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()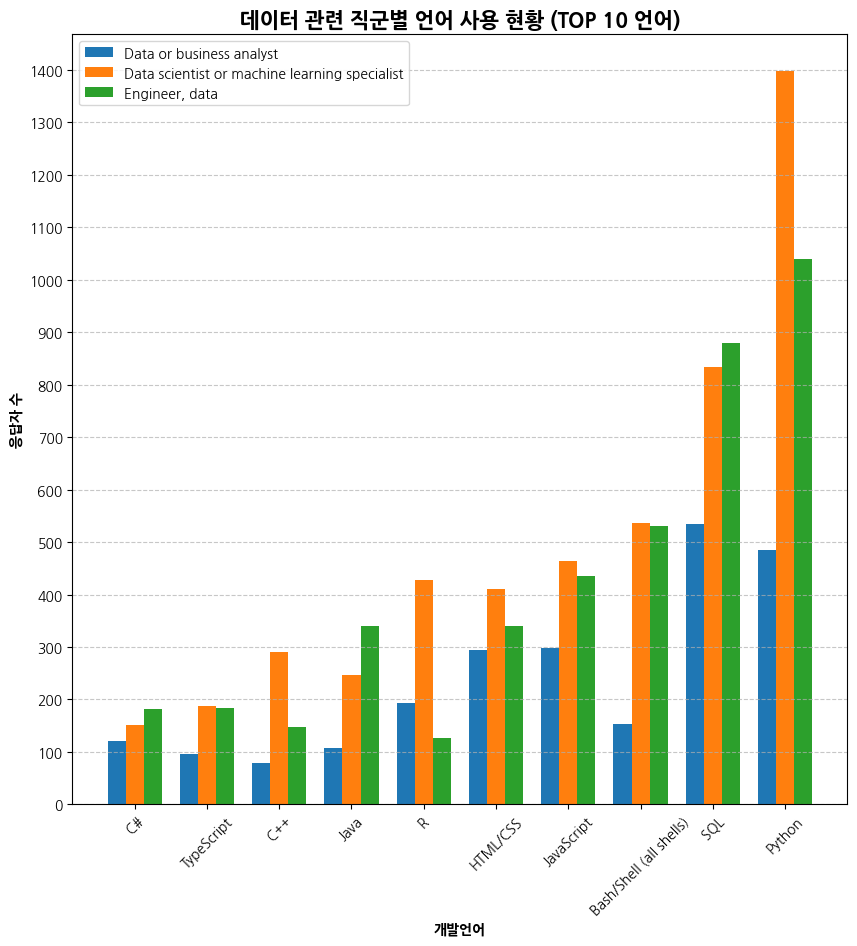
9)
y_positions = []
current_language = None
for index, row in top3_devtypes_by_lang_sorted.iterrows():
if current_language != row['LanguageHaveWorkedWith']:
current_language = row['LanguageHaveWorkedWith']
y_positions.append((current_language, index+2))
y_labels, y_ticks = zip(*y_positions)
plt.figure(figsize=(15,30))
plt.barh(y=top3_devtypes_by_lang_sorted.index, width=top3_devtypes_by_lang_sorted['Count'])
plt.yticks(y_ticks, y_labels)
plt.show()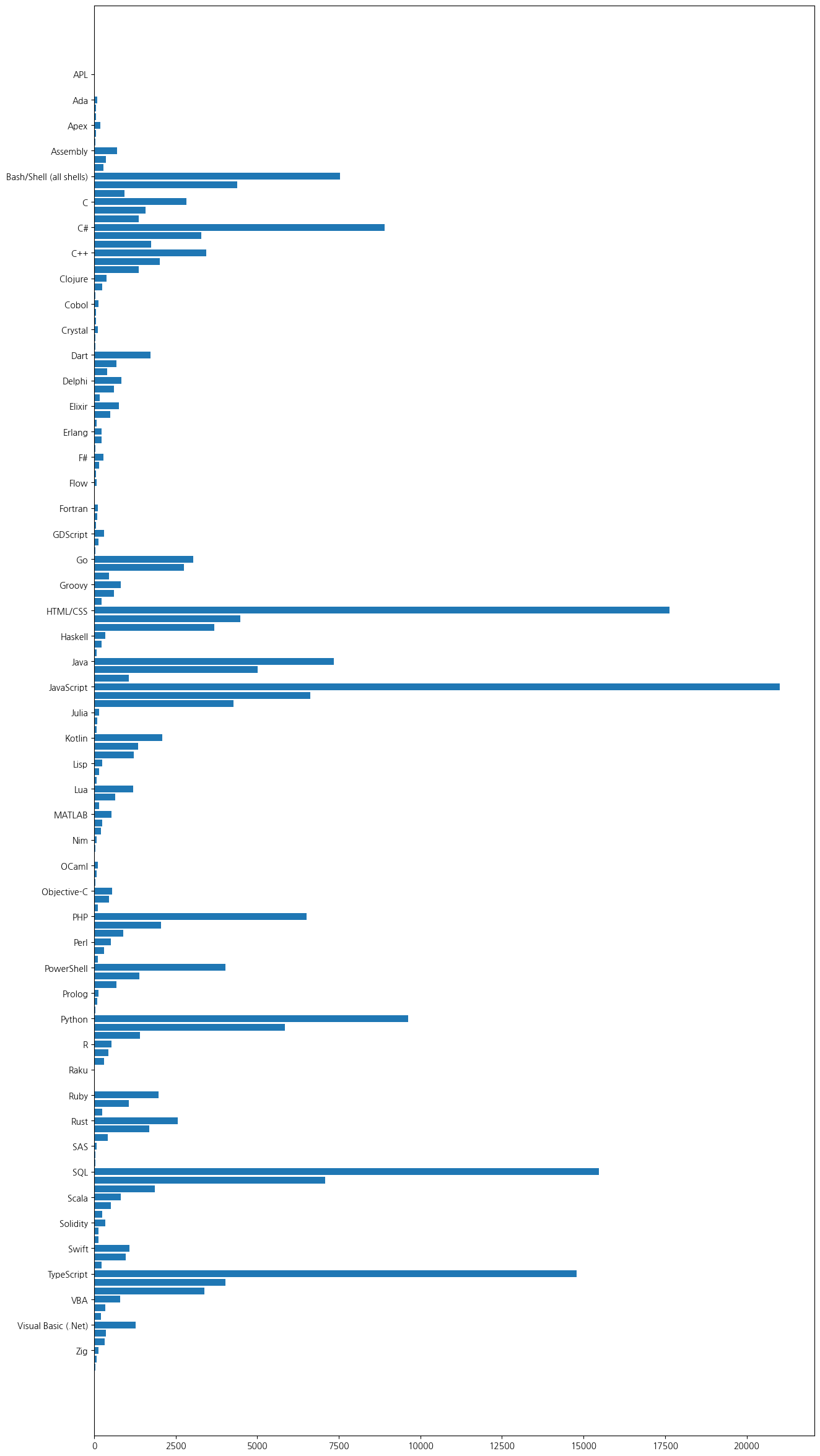
iterrows()는 Pandas DataFrame에서 각 행을 순회하는 메서드이다. 이 메서드를 호출하면 DataFrame의 각 행에 대해 인덱스와 해당 행을 반환하는 iterator가 생성된다.
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']}
df = pd.DataFrame(data)이제 iterrows()를 사용하여 DataFrame의 각 행을 반복할 수 있다.
for index, row in df.iterrows():
print(index, row['Name'], row['Age'], row['City'])
# 출력:
# 0 Alice 25 New York
# 1 Bob 30 Los Angeles
# 2 Charlie 35 Chicagoiterrows()를 사용하여 DataFrame의 각 행에 대해 반복할 수 있으며, 각 반복에서 인덱스와 해당 행을 가져와서 원하는 작업을 수행할 수 있다. 단, 대용량 데이터프레임의 경우에는 iterrows()를 사용하는 것보다 다른 방법을 고려해야 한다.
*은 파이썬에서 언패킹(Unpacking) 연산자로 사용됩니다. 리스트, 튜플 등의 iterable 객체를 언패킹하여 각 요소를 개별적인 인자로 전달합니다.
예를 들어, 다음과 같은 리스트가 있다고 가정해봅시다.
my_list = [1, 2, 3]
print(*my_list) # 출력: 1 2 3이 경우 *my_list는 리스트 my_list의 각 요소를 개별적인 인자로 전달합니다. 즉, print(1, 2, 3)과 동일한 효과를 갖습니다.
zip(*y_positions)에서도 이와 비슷한 원리가 적용됩니다. *y_positions은 y_positions 리스트를 언패킹하여 각 튜플의 같은 위치에 있는 요소들을 묶어주는 역할을 합니다. 따라서 zip(*y_positions)은 각 튜플의 같은 위치에 있는 요소들을 묶어서 새로운 튜플을 생성합니다.
10)
plt.figure(figsize=(15,30))
top3_dev_bars = plt.barh(y=top3_devtypes_by_lang_sorted.index, width=top3_devtypes_by_lang_sorted['Count'])
plt.yticks(y_ticks, y_labels)
for bar, (devtype, percentage) in zip(top3_dev_bars, top3_devtypes_by_lang_with_total[['DevType', 'Percentage']].values):
plt.text(x=bar.get_width(), y=bar.get_y()+bar.get_height()/2, s=f'{devtype} ({percentage:.2f}%)', va='center', ha='left', fontsize=10)
plt.show()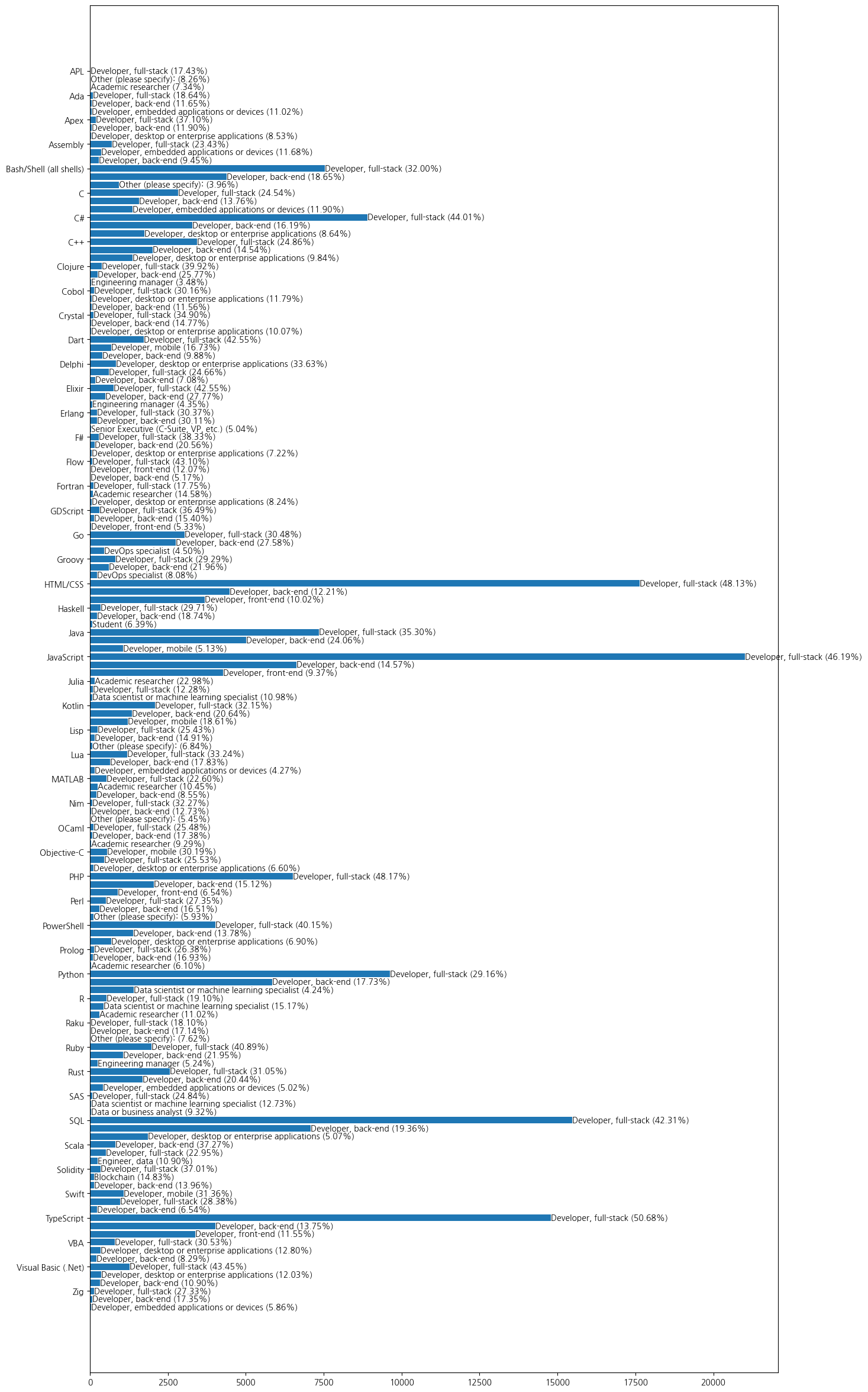
참고:
plt.cm.viridis
plt.cm.viridis는 Matplotlib의 컬러맵(colormap) 중 하나이다. 컬러맵은 데이터를 시각화할 때 사용되는 색상 체계를 정의하는데 사용된다. Viridis 컬러맵은 낮은 값에서 높은 값까지 색상이 점진적으로 변화하며, 잘 구별되는 색상을 사용하여 데이터의 변화를 시각적으로 표현한다. 이 컬러맵은 색상의 밝기와 채도를 조정하여 데이터의 특징을 더욱 명확하게 보여준다.

11)
unique_devtypes = top3_devtypes_by_lang['DevType'].unique()
colors = plt.cm.viridis(np.linspace(0,1,len(unique_devtypes)))
color_map = {devtype: color for devtype, color in zip(unique_devtypes, colors)}
color_mapplt.figure(figsize=(15,30))
top3_dev_bars = plt.barh(y=top3_devtypes_by_lang_sorted.index,\
width=top3_devtypes_by_lang_sorted['Count'],\
color=[colaor_map.get(devtype) for devtype in top3_devtypes_by_lang_sorted['DevType']])
plt.yticks(y_ticks, y_labels)
for bar, (devtype, percentage) in zip(top3_dev_bars, top3_devtypes_by_lang_with_total[['DevType', 'Percentage']].values):
plt.text(x=bar.get_width(), y=bar.get_y()+bar.get_height()/2, s=f'{devtype} ({percentage:.2f}%)', va='center', ha='left', fontsize=10)
plt.legend([plt.Rectangle(xy=(0,0), width=1, height=1, color= color_map[devtype]) for devtype in unique_devtypes],
unique_devtypes,
title='DevTypes',
loc='upper right')
plt.show()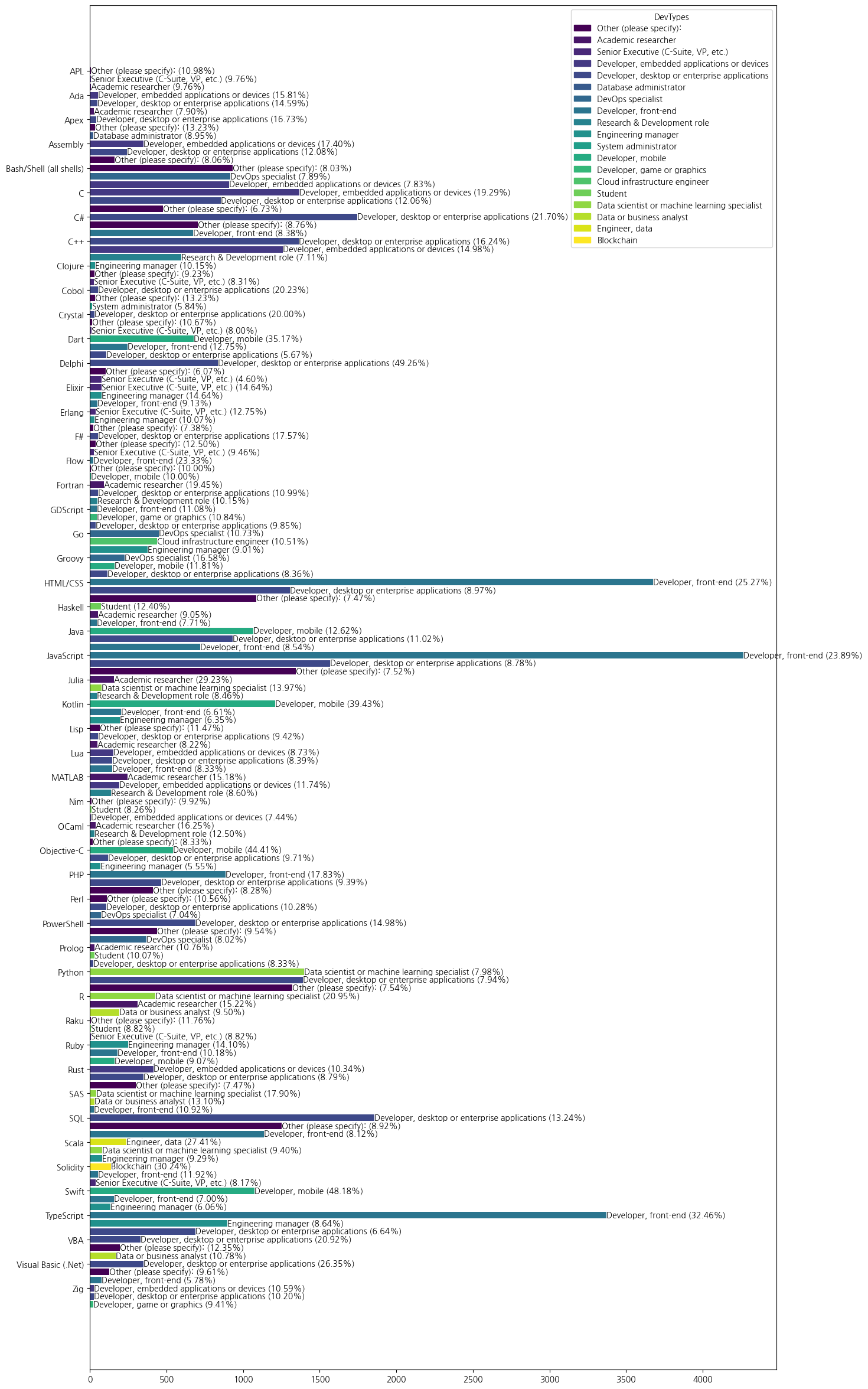
np.linspace()함수는 NumPy에서 사용되는 함수 중 하나로, 지정된 범위 내에서 등간격으로 일정 개수의 값을 생성한다.
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
# start: 시작 값
# stop: 종료 값
# num: 생성할 값의 개수 (기본값은 50)
# endpoint: True로 설정하면 종료 값도 포함된다. False로 설정하면 종료 값은 포함되지 않습니다. (기본값은 True)
# retstep: True로 설정하면 간격(step) 반환 (기본값은 False)
# dtype: 배열의 데이터 타입 지정 (기본값은 None)
# axis: 연산을 수행할 축 지정 (기본값은 0)np.linspace(0, 1, len(unique_devtypes))와 같이 사용하면 0부터 1까지의 범위에서 len(unique_devtypes) 개의 값이 생성된다. 이 값들은 시작과 끝을 포함하며, 등간격으로 배치됩니다. 따라서 이 함수는 주어진 범위 내에서 일정 개수의 등간격 값을 생성하는 데 사용됩니다.
12)
plt.figure(figsize=(10, 5))
plt.hist(comp_sr, bins=50, color='teal', edgecolor='black')
plt.ticklabel_format(style='plain', axis='x')
plt.title('개발자 연봉 분포(KRW)', fontsize=15, fontweight='bold')
plt.xlabel('연봉(만원)', fontweight='bold')
plt.ylabel('응답자 수', fontweight='bold')
plt.grid(True)
plt.show()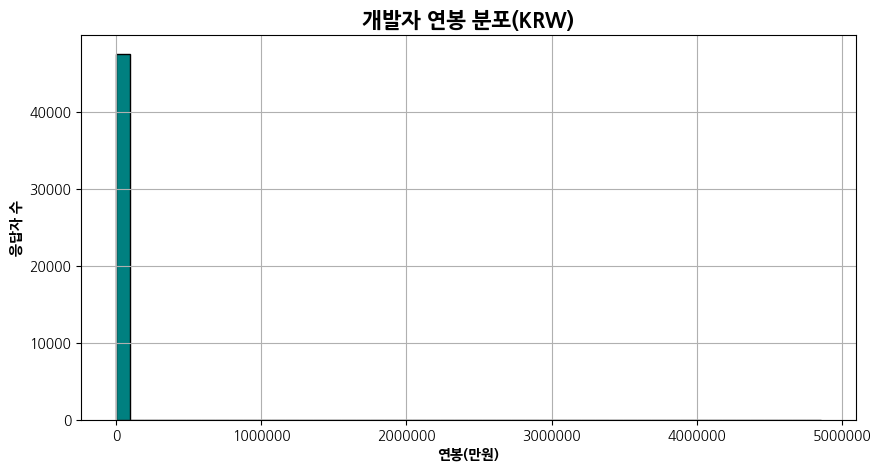
-
plt.hist()함수: 히스토그램을 그린다.bins매개변수: 히스토그램의 막대 개수를 설정한다.color매개변수: 히스토그램의 색상을 지정한다.edgecolor매개변수는 히스토그램 막대의 테두리 색상을 지정한다.
-
plt.ticklabel_format(style='plain', axis='x'): x축의 숫자 형식을 일반 형식으로 설정한다. 이렇게 하면 숫자가 지수 형식이 아닌 일반 숫자로 표시된다.
plt.ticklabel_format() 함수는 Matplotlib에서 눈금의 숫자 형식을 설정하는 함수이다. 이 함수를 사용하면 그래프의 x축 또는 y축에 표시되는 숫자의 형식을 지수 형식(exponential format)이나 일반 형식(plain format) 등으로 조절할 수 있다.
plt.ticklabel_format(style='스타일', axis='축')
# style: 눈금의 숫자 형식을 지정한다. 'sci'는 지수 형식을, 'plain'은 일반 형식을 의미한다.
# axis: 형식을 적용할 축을 지정한다. 'x'는 x축을, 'y'는 y축을 의미한다.참고:
지수 연산은 어떤 값을 특정 지수로 거듭제곱하는 연산을 말한다. 이 연산은 대체로 데이터를 빠르게 증가시키거나 줄이는 데 사용된다.
예를 들어, 2의 3승(2^3)은 다음과 같이 계산된다.
2^3 = 2x2x2 = 8
-
밑(base): 2
-
지수(exponent): 3
-
로그 연산은 지수 연산의 역과정으로, 어떤 값을 특정 밑(base)의 로그 값으로 변환하는 연산을 말한다. 로그를 사용하면 데이터의 범위를 줄이고 큰 값들을 작게 만들어준다.
예를 들어, 10을 밑으로 1000의 로그를 계산하면 다음과 같다.
log10(1000) = 3
즉, 10^3 = 1000 이므로 log10(1000) = 3이 된다.
이러한 연산을 통해 데이터의 범위를 줄이고 분석을 더 쉽게 할 수 있다. 특히 데이터의 분포가 한쪽으로 치우쳐져 있거나 값의 범위가 매우 넓을 때 유용하다.
아래는 이상치를 제거하지 않고 로그 변환을 통해 그래프 그리는 방법이다.
np.log1p()
# log1p(x) == log(x+1)np.log1p() 함수는 주어진 배열 또는 값에 대해 자연로그(로그의 밑이 자연상수 e인 로그)를 취한 후 1을 더한 값을 반환한다. 이 함수는 주로 데이터의 로그 변환에 사용되며, 데이터에 1을 더해줌으로써 0 또는 음수인 경우에도 로그를 취할 수 있도록 한다.
로드 변환은 데이터의 분포를 정규분포에 가깝게 만들거나 데이터의 범위를 줄이는 등의 목적으로 사용된다. 특히 이상치가 있는 경우 로그 변환을 적용하면 이상치의 영향을 줄일 수 있다.
예를 들어, 아래는 주어진 데이터에 로그 변환을 적용하여 그래프를 그리는 코드이다.
import numpy as np
import matplotlib.pyplot as plt
# 주어진 데이터 (예: 연봉 데이터)
data = [10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000]
# 데이터에 로그 변환 적용
transformed_data = np.log1p(data)
# 그래프 그리기
plt.hist(transformed_data, bins=10, color='skyblue', edgecolor='black')
plt.title('로그 변환된 데이터의 분포', fontsize=15)
plt.xlabel('로그(연봉)', fontsize=12)
plt.ylabel('빈도', fontsize=12)
plt.grid(True)
plt.show()13)
log_comp_sr = np.log1p(comp_sr)
plt.figure(figsize=(10, 5))
plt.hist(log_comp_sr, bins=50, color='teal', edgecolor='black')
plt.title('개발자 연봉 분포(KRW) - 로그 변환', fontsize=15, fontweight='bold')
plt.xlabel('연봉(만원)', fontweight='bold')
plt.ylabel('응답자 수', fontweight='bold')
plt.grid(True)
plt.show()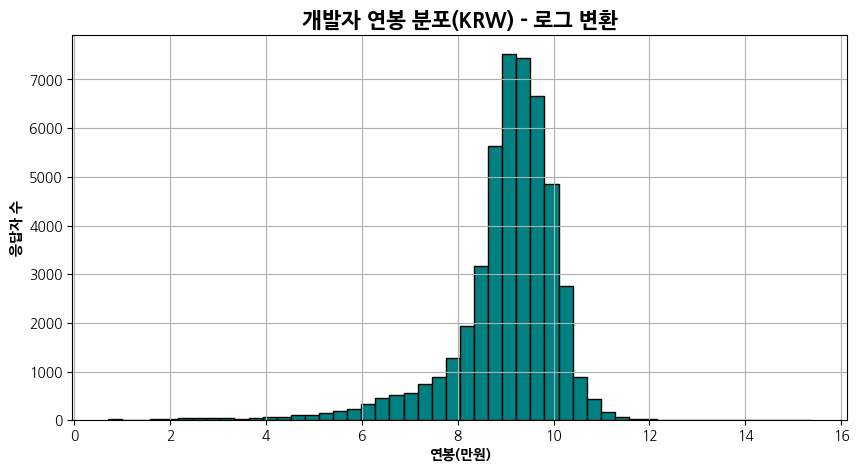
plt.grid(True)는 그래프에 격자 라인을 표시하는 역할을 한다. 격자 라인은 주로 데이터의 분포를 시각적으로 파악하는 데 도움이 된다.
예를 들어, 히스토그램의 경우 데이터의 분포를 보다 명확하게 확인할 수 있다. 격자 라인이 있으면 각 막대의 높이를 더 정확하게 읽을 수 있다.
14)
merged_df = pd.merge(lang_df, comp_df[['Id', 'TotalKrw(만원)']], on='Id', how='inner')pd.merge(): 두 데이터프레임을 병합하는 함수이다.on매개변수: 두 데이터프레임을 합칠 때 기준이 되는 열을 지정한다.how매개변수: 병합 방법을 지정한다.'left': 왼쪽 데이터프레임의 모든 행을 유지하면서 오른쪽 데이터프레임과 병합한다. 오른쪽 데이터프레임에 해당하는 값이 없는 경우에는 NaN으로 채운다.'right': 오른쪽 데이터프레임의 모든 행을 유지하면서 왼쪽 데이터프레임과 병합한다. 왼쪽 데이터프레임에 해당하는 값이 없는 경우에는 NaN으로 채운다.'inner': 교집합을 수행하여 두 데이터프레임에서 공통된 값만을 병합한다.'outer': 합집합을 수행하여 두 데이터프레임의 모든 값을 포함한다. 공통된 값이 없는 경우에는 NaN으로 채운다.
15)
plt.figure(figsize=(10, 20))
plt.barh(y=median_salary_by_lang['LanguageHaveWorkedWith'], width=median_salary_by_lang[COMP_KRW])
plt.title('개발 언어별 연봉 중간값', fontsize=15, fontweight='bold')
plt.xlabel('연봉 중간값 (KRW, 만원)', fontweight='bold')
plt.ylabel('개발 언어', fontweight='bold')
plt.xticks(np.arange(0, median_salary_by_lang[COMP_KRW].values.max()+1000, 1000), rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()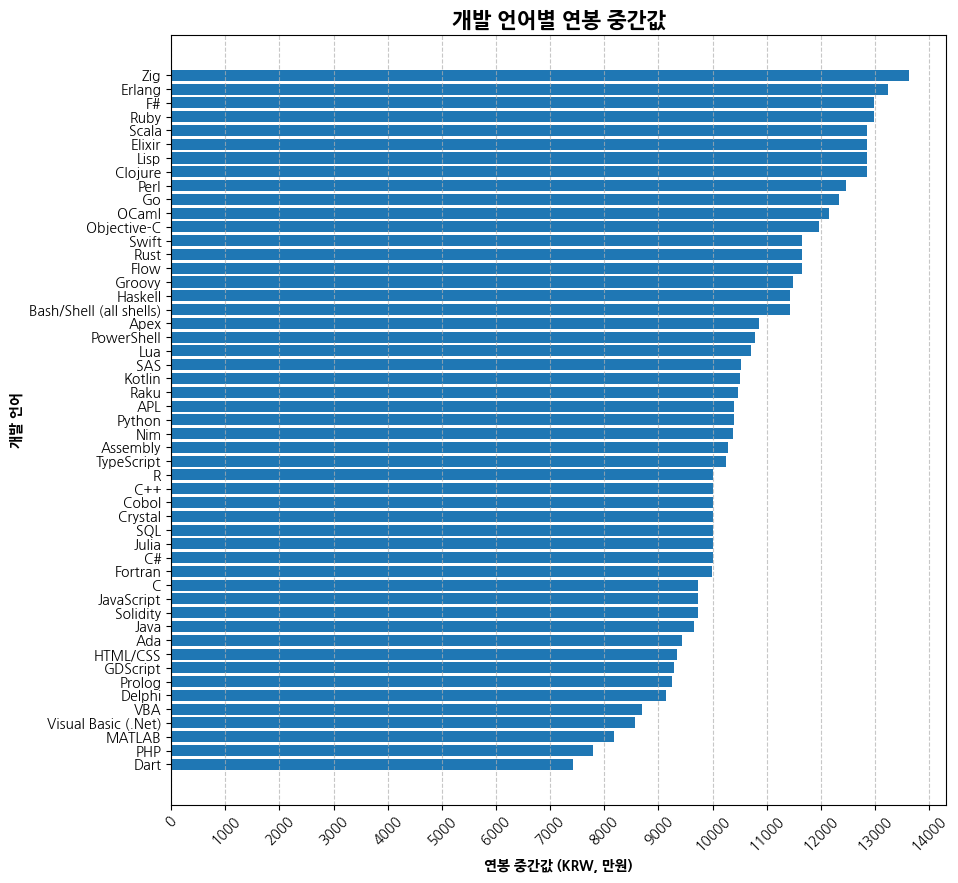
위의 코드를 그대로 함수화 작업을 하면 다음과 같이 나타낼 수 있다.
def draw_median_salary_barh(df, target, title, ylabel, figsize=(10, 10)):
plt.figure(figsize=figsize)
plt.barh(y=df[target], width=df[COMP_KRW])
plt.title(title, fontsize=15, fontweight='bold')
plt.xlabel('연봉 중간값 (KRW, 만원)', fontweight='bold')
plt.ylabel(ylabel, fontweight='bold')
plt.xticks(np.arange(0, df[COMP_KRW].values.max()+1000, 1000), rotation=45)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()
함수화된 코드를 사용하면 코드를 재사용하기 쉽고 가독성도 높일 수 있다.
16)
plt.figure(figsize=(10, 5))
plt.boxplot(test, showfliers=False)
plt.show()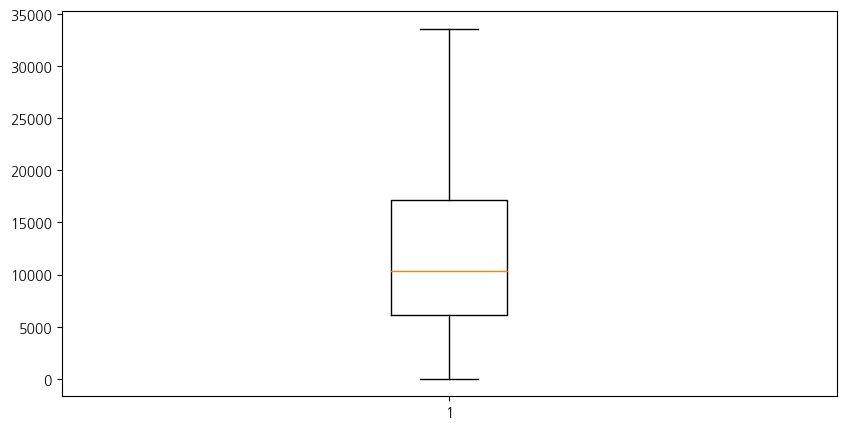
상자 그림(boxplot)은 데이터의 분포를 시각화하는 데 사용되는 효과적인 도구이다. 상자 그림은 데이터의 중앙값, 사분위수, 이상치 등을 표시하여 데이터의 대략적인 분포를 파악할 수 있도록 도와준다.
showfliers매개변수: 상자 그림(boxplot)에서 이상치(outliers)를 표시할지 여부를 지정한다.
17)
plt.figure(figsize=(10, 5))
plt.boxplot(test, vert=False, showfliers=False)
plt.show()boxplot():vert매개변수: 상자 그림(boxplot)을 수직 방향이 아니라 수평 방향으로 그릴지를 결정한다.
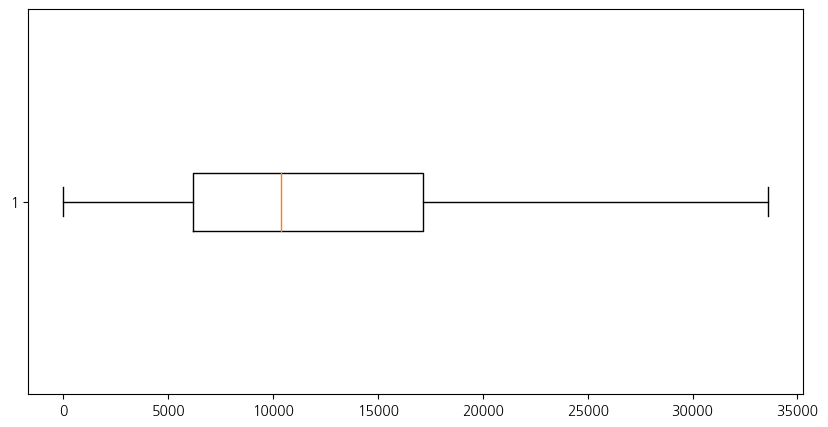
18)
plt.figure(figsize=(10, 5))
plt.boxplot(test, vert=False, showfliers=False, showmeans=True, meanline=True)
plt.show()boxplot():showmeans매개변수: 상자 그림(boxplot)에서 평균값을 보여줄지 여부를 결정한다. 기본값은 False이며, 이를 True로 설정하면 상자 그림에 평균값을 표시한다.meanline매개변수: 상자 그림에서 평균값을 나타내는 선을 표시할지 여부를 결정한다. True로 설정되어 있어야만 이 매개변수가 작동하며, 기본값은 False이다.
19)
unique_langs = merged_df['LanguageHaveWorkedWith'].dropna().unique()
unique_langs
plt.figure(figsize=(10, 15))
plt.boxplot([merged_df[merged_df['LanguageHaveWorkedWith']==lang][COMP_KRW] for lang in unique_lang],
vert=False,
showfliers=False,
showmeans=True,
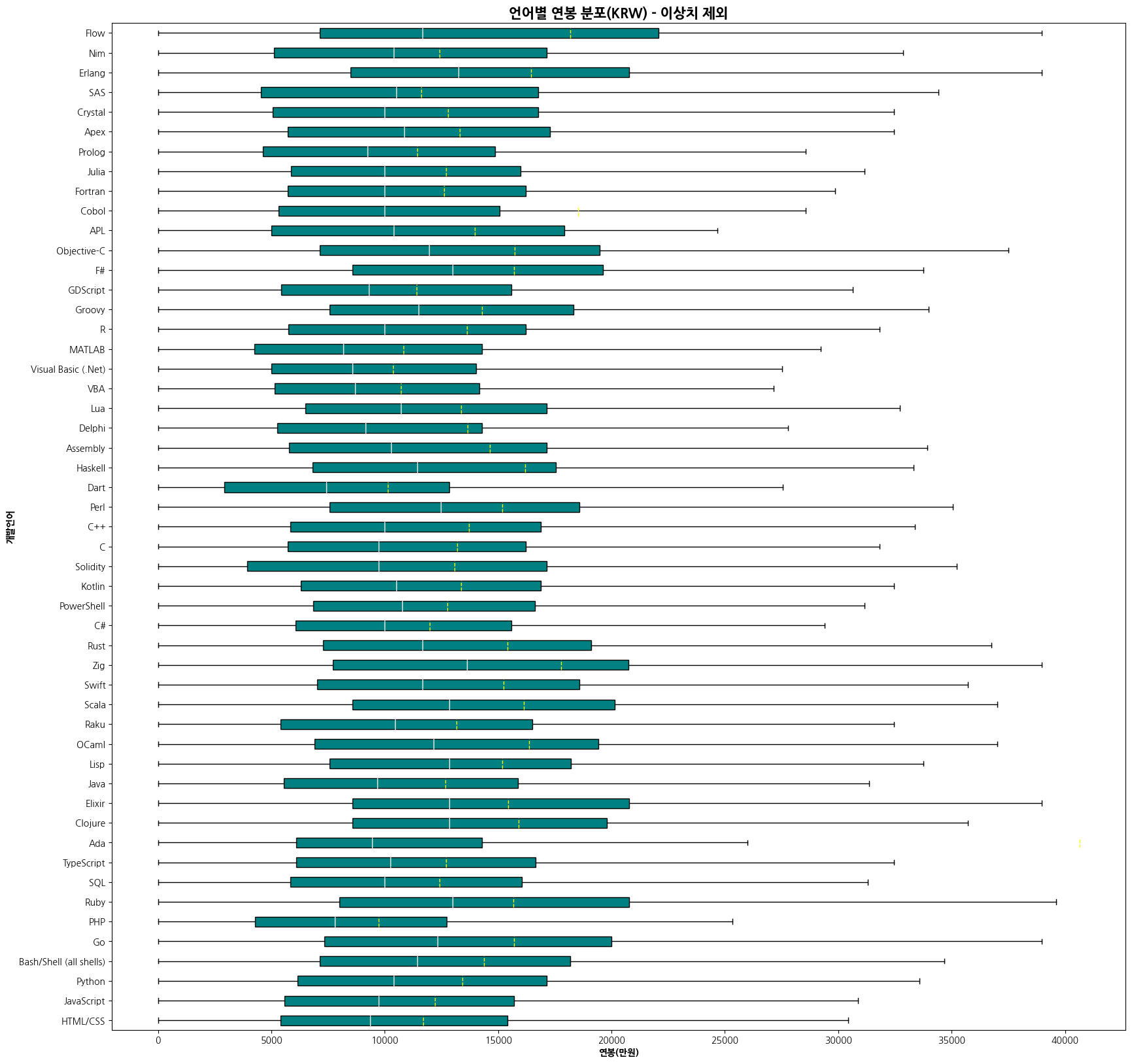
meanline=True,
labels=unique_langs)
plt.show()
20)
plt.figure(figsize=(10, 15))
box = plt.boxplot([merged_df[merged_df['LanguageHaveWorkedWith']==lang][COMP_KRW] for lang in unique_lang],
vert=False,
showfliers=False,
showmeans=True,
meanline=True,
labels=unique_langs,
patch_artist=True,
boxprops={'facecolor':'teal'})
plt.setp(box['medians'], color='white')
plt.setp(box['means'], color='yellow', linewidth=1)
plt.title('언어별 연봉 분표(KRW)', fontsize=15, fontweight='bold')
plt.xlabel('연봉(만원)', fontweight='bold')
plt.ylabel('개발 언어', fontweight='bold')
plt.ticklabel_format(style='plain', axis='x')
plt.show()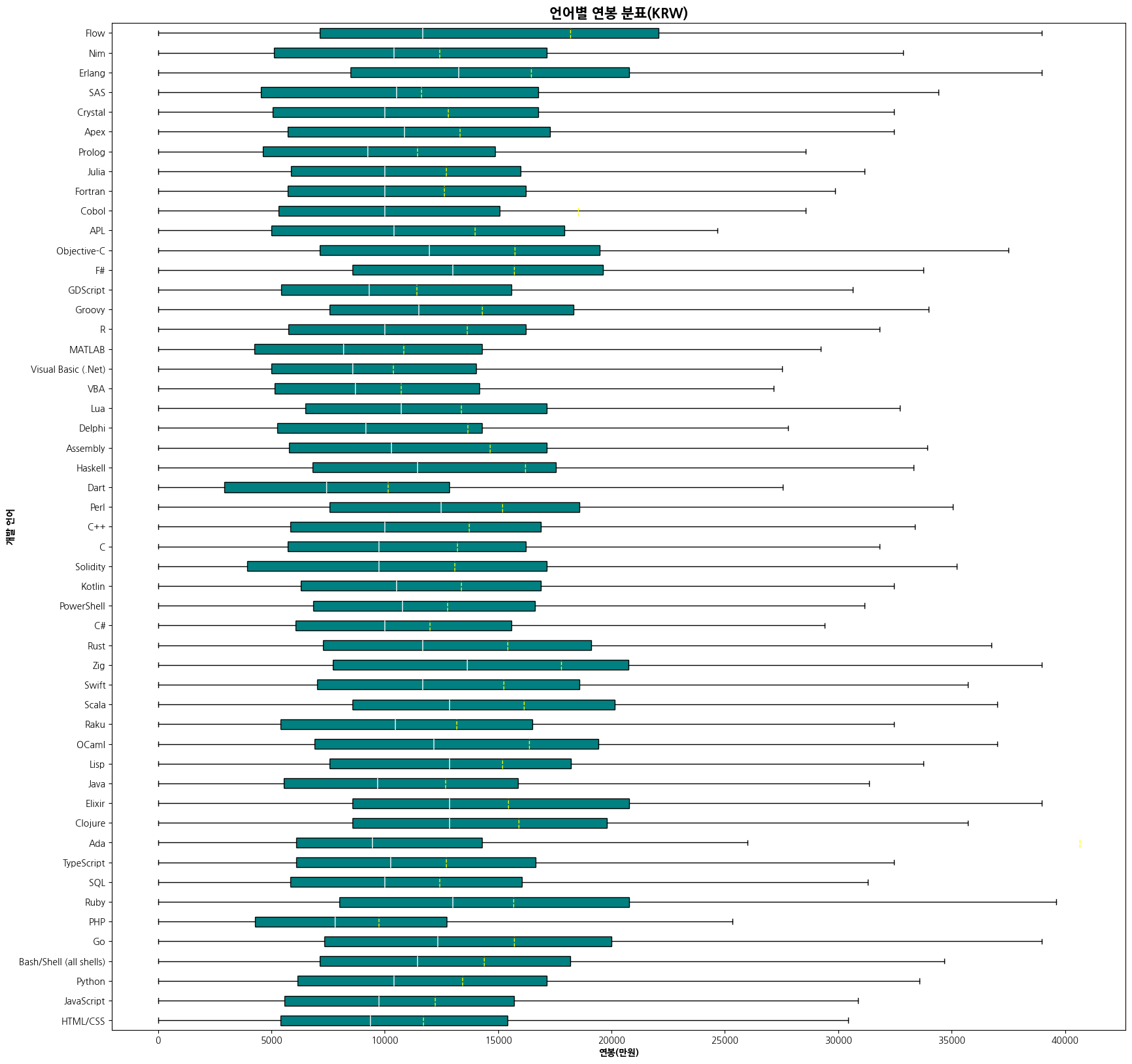
patch_artist매개변수: 상자 그림(Boxplot)에서 상자의 내부를 채우는 데 사용되는 패치 아티스트를 활성화하는 데 사용된다. 상자의 내부를 채우는 데 패치 아티스트를 사용하면 상자의 색상을 변경하거나 다양한 패턴을 적용할 수 있다. 이 매개변수를 True로 설정하면 상자의 내부를 채우고자 할 때 사용된다.
patch_artist=Trueboxprops매개변수: 상자의 속성을 설정하는 데 사용된다. 상자 그림에서 상자의 속성을 변경하려는 경우에 유용하다. 예를 들어,'facecolor'속성을 사용하여 상자의 내부 색상을 지정할 수 있다.
boxprops={'facecolor':'teal'}plt.setp()함수: 객체의 속성을 설정하는 데 사용된다.
# 중앙값 선의 색상을 흰색으로 설정
plt.setp(box['medians'], color='white')
# 평균값 선의 색상을 노란색으로 설정하고 두께를 1로 지정
plt.setp(box['means'], color='yellow', linewidth=1)평균값은 상자 그림에서 기본적으로 표시되지 않지만, 'showmeans=True' 옵션을 사용하여 표시할 수 있다.
위의 코드를 함수화 작업하기
def draw_salary_boxplot(df, target, title, ylabel, showfliers=False, figsize=(10, 20):
label_values = df[target].dropna().unique()
plt.figure(figsize=figsize)
box = plt.boxplot([df[df[target]==value][COMP_KRW] for value in label_values],
vert=False,
showfliers=showfliers,
showmeans=True,
meanline=True,
labels=label_values,
patch_artist=True,
boxprops={'facecolor':'teal'})
plt.setp(box['medians'], color='white')
plt.setp(box['means'], color='yellow', linewidth=1)
plt.title(title, fontsize=15, fontweight='bold')
plt.xlabel('연봉(만원)', fontweight='bold')
plt.ylabel(ylabel, fontweight='bold')
plt.ticklabel_format(style='plain', axis='x')
plt.show()draw_salary_boxplot(df=merged_df, target='LanguageHaveWorkedWith', title='언어별 연봉 분포(KRW) - 이상치 제외', ylabel='개발언어')