1. 데이터 불러오기
1) Pandas 라이브러리를 사용하여 CSV 파일을 불러와 데이터프레임으로 저장
# 라이브러리 임포트
import pandas as pd
import numpy as np
file_path = '파일_이름.csv'
raw_data = pd.read_csv(file_path)
raw_data2) 데이터프레임에 대한 간단한 요약 정보
raw_data.info()데이터프레임의 구조와 각 열의 데이터 타입, 그리고 결측치 여부 등을 확인할 때 사용한다.
info 함수가 반환하는 정보의 예시:
- 데이터프레임의 행(row) 수
- 각 열(column)의 이름과 데이터 타입
- 각 열의 비어있지 않은(non-null) 값의 개수
- 메모리 사용량 등
3) 주어진 파일에서 특정 열(column)들만을 선택하여 데이터프레임으로 불러오기
filtered_data = pd.read_csv(file_path, usecols = columns)
filtered_data.head()
# usecols 매개변수: 원하는 열만 선택하여 불러오기2. EDA
2.1 데이터 전처리
1) filtered_raw라는 데이터프레임을 복사하여 새로운 데이터프레임인 df를 생성하고, 출력하기
df = filtered_raw.copy()
df.head()
# copy() 함수 : 데이터프레임 복사2) 데이터프레임에서 특정 인덱스의 행을 삭제하고, 인덱스를 재설정하기
df = df.drop(index = 0).reset_index(drop=True)
df.head()
# index = 0: 인덱스가 0인 행 삭제
# reset_index(drop=True): 인덱스 재설정3) 결측치를 포함한 행을 삭제한 후의 데이터프레임의 정보를 다시 요약하여 출력하기
df.dropna().info()
# dropna() 함수: 결측치를 포함한 행 삭제4) Pandas의 옵션을 설정하여 float 값을 출력할 때 소수점 이하 자리수 설정하기
pd.set_option('display.float_format', '{:,.2f}'.format)
# pd.set_option: Pandas의 옵션을 설정하는 함수
# 'display.float_format': 출력되는 float 값의 형식을 지정하는 옵션
# '{:,.2f}'.format: 포맷 문자열을 사용하여 float 값을 특정 형식으로 포맷
# '{:,.2f}'는 소수점 이하 2자리까지 표시하고, 숫자를 천 단위로 쉼표로 구분하여 표시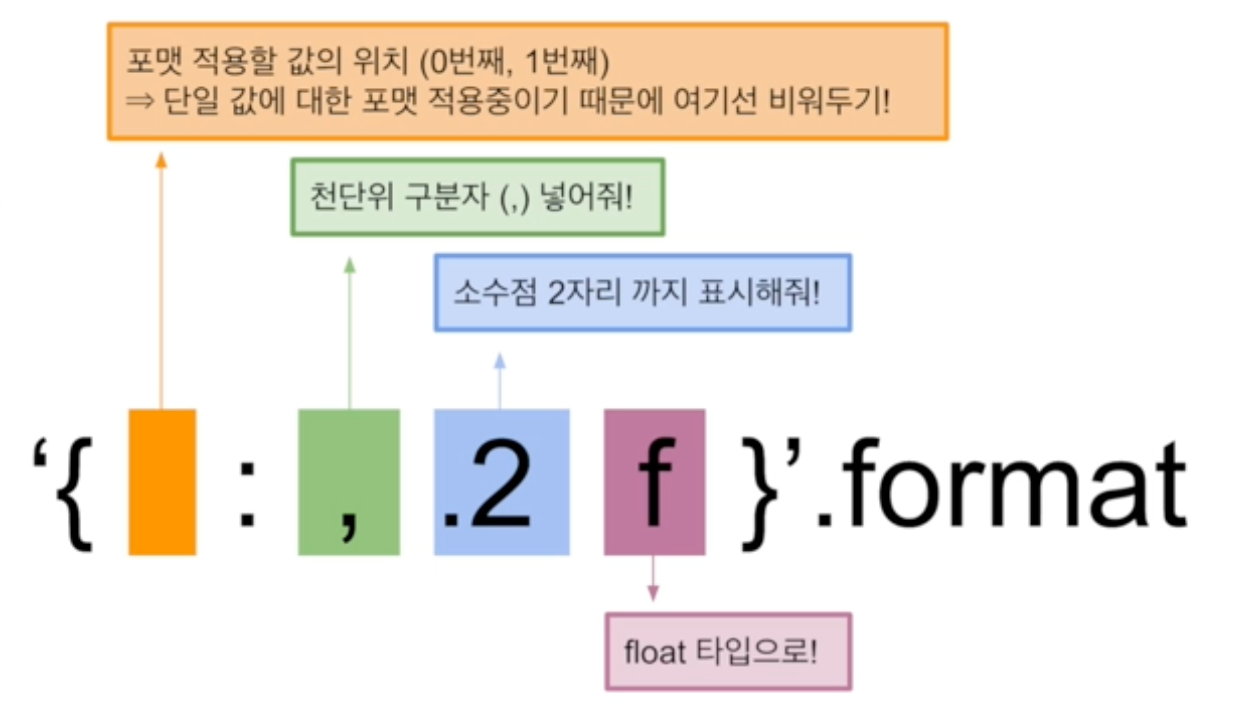
5) 데이터프레임의 요약 통계량(또는 이상치, Outlier) 출력하기
# 수치형 변수의 요약 통계량 출력
df.describe()
# 범주형 변수의 요약 통계량 출력
df.describe(include = object)
# 전치(transpose)된 범주형 변수의 요약 통계량 출력
df.describe(include = object).T-
수치형 변수의 요약 통계량 출력:
df.describe()는 데이터프레임의 수치형 변수에 대한 요약 통계량을 출력한다. 이는 각 열의 개수(count), 평균(mean), 표준편차(std), 최솟값(min), 25%, 50%, 75% 분위수(quantile), 최댓값(max) 등을 보여준다. -
범주형 변수의 요약 통계량 출력:
df.describe(include='object')는 데이터프레임의 범주형 변수에 대한 요약 통계량을 출력한다. 이는 각 열의 개수(count), 고유값의 개수(unique), 최빈값(top), 최빈값의 빈도수(freq) 등을 보여준다. -
전치된 범주형 변수의 요약 통계량 출력:
.T는 데이터프레임을 전치(transpose)하는 역할을 한다. 따라서df.describe(include='object').T는 범주형 변수에 대한 요약 통계량을 출력한 후, 결과를 전치하여 행과 열을 바꾼 형태로 출력한다. 이렇게 하면 보기 편한 형식으로 데이터프레임을 확인할 수 있다.
참고:
여기서 한가지 알아야할 점은 변수를 대문자로 정의하는 것은 해당 변수가 상수(Constant)로 취급되며, 해당 정보가 변경되지 않는다는 것을 나타낸다. 이런 관습은 코드를 읽는 사람들에게 변수가 상수임을 명확하게 전달해주고, 변수의 값이 변경되지 않아야 함을 강조한다.
- 대문자로 정의된 변수는 프로그래밍 언어의 상수와는 달리 사실 불변(immutable)하지 않는다. 파이썬에서는 변수에 새로운 값을 할당하여 변경할 수 있다. 하지만 이러한 관습은 해당 변수의 값을 변경하지 않는 것을 장려하고, 코드의 가독성을 향상시키는 데 도움이 된다.
- 예를 들어, 'PRO_DEV = 'I am a professional developer''와 같이 대문자로 변수를 정의하면 해당 변수가 프로그램 내에서 개발자를 나타내는 정보를 변경하지 않고 유지할 것이라는 것을 코드를 읽는 사람에게 알려준다. 이는 변수에 새로운 값을 할당하여 변경하지 않는 것이 좋은 관행이며, 변수의 역할과 의도를 명확히 전달할 수 있다.
6) 데이터프레임에서 열(column)의 값이 주어진 목록에 포함된 행들 선택하기
df = df[df['열_이름'].isin(목록)]
df['열_이름'].value_counts()
df.info()
# isin() 메서드는 주어진 값들을 포함하는 행 선택
# value_counts(): 각 값의 빈도수 계산7) 열의 값들의 빈도수를 계산하고, 이를 전체 값의 비율로 정규화하여 출력하기
display(df['Age'].value_counts(normalize = True))
# value_counts(normalize=True): 각 값의 발생 빈도를 전체 값의 비율로 표현
# display() 함수: 출력 결과를 보여주는 함수참고:
display() 함수는 일반적으로 Jupyter Notebook이나 IPython과 같은 환경에서 사용된다. 이를 통해 결과를 보다 보기 좋게 출력할 수 있다.
8) 열에 결측치가 있는지 여부 확인하기
df['열_이름'].hasnans
# hasnans: 선택된 열에 결측치가 있는지 여부를 확인하는 속성(attribute)열에 결측치가 하나라도 있다면, hasnans는 True를 반환하고, 그렇지 않으면 False를 반환한다.
9) 열에서 결측치를 제거한 후에, 각 행의 값을 세미콜론(;)을 기준으로 분할하여 리스트 형태로 반환하기
df['열_이름'].dropna().str.split(';')
# dropna(): 열에서 결측치를 제거한 시리즈를 반환
# str.split(';'): 각 행의 값을 세미콜론(;)을 기준으로 문자열로 분할하여 리스트 형태로 반환10)
flattened_list = [val for sublist in split_lists for val in sublist]
flattened_list
unique_values = set(flattened_list)
unique_values여기서 리스트 컴프리헨션은 중첩된 반복문과 유사한 역할을 한다. 리스트 컴프리헨션을 사용하면 코드를 더 간결하고 읽기 쉽게 작성할 수 있다. 다음과 같이 일반적인 for 반복문으로 표현할 수 있다.
flattened_list = []
for sublist in split_lists:
for val in sublist:
flattened_list.append(val)이 코드는 각 sublist에서 val을 추출하여 flattened_list에 추가하는 것을 반복한다.
11) flattened_list에 있는 값들의 빈도수를 계산하고, 이를 시리즈로 만들어서 출력하기
pd.Series(flattened_list).value_counts()
# pd.Series(flattened_list): flattened_list에 있는 값을 가지고 Pandas의 시리즈 생성12) 열에서 결측치 제거하기
df.dropna(subset='열_이름')
# subset 매개변수: 결측치를 제거할 열을 지정하는 역할만약 subset 매개변수를 사용하지 않으면 모든 열에서 결측치를 제거하게 된다.
13) 열에서 특정 문자열을 포함하는 행들을 선택하기
condition1 = devs_df[devs_df['열_이름'].str.contains("문자열")]
# 열에서 문자열을 포함하는 행들을 선택14) 열의 값들의 빈도수를 계산하고, 이를 전체 값의 비율로 정규화하여 출력하기
df['열_이름'].value_counts(normalize=True, dropna=False)
# dropna=False 옵션: 결측치 포함 여부15) 열에서 특정 값을 다른 값으로 대체하기
df['열_이름'] = df['열_이름'].replace({'문자열1': '0.5', '문자열2': '21'})
df['열_이름']16) 열의 값을 숫자형으로 변환한 후, 해당 열의 고유한 값들 확인하기
df['열_이름'] = pd.to_numeric(df['열_이름']).astype('float')
df['열_이름'].unique()
/% pd.to_numeric(): 숫자형으로 변환
(변환할 수 없는 값이 있을 경우, 결측치로 처리) %/
# astype(): 데이터 타입 변환
# unique(): 고유한 값 확인17) 열에 있는 값 중에서 결측치가 있는지 여부를 확인하고, 결측치의 개수와 비율 출력하기
df['열_이름'].isna().value_counts()
# isna(): 결측치 여부 확인하여 불리언 시리즈로 반환
# 18) 열에서 결측치가 있는 행들을 제거하고, 원본 데이터프레임 수정하기
df.dropna(subset='열_이름', inplace=True)
# inplace=True: 원본 데이터프레임을 직접 수정하도록 지정하는 옵션inplace=True 옵션이 사용되면 새로운 데이터프레임을 반환하지 않고, 원본 데이터프레임이 변경된다.
19) 열의 각 값들을 문자열의 일부분만 남기기
df['열_이름'].str.slice(start=0, stop=3)
# str.slice(): 문자열의 일부분만 남기는 역할
# start=0 옵션: 문자열의 시작부터를 의미
# stop=3 옵션: 문자열의 세 번째 문자 이전까지 의미20) pickle 라이브러리를 사용하여 파일에서 객체를 역직렬화하여 불러오기
pickle은 기본적인 라이브러리로 객체를 직렬화하고 역직렬화하는 기능을 제공한다.
파이썬의 리스트, 딕셔러니, 클래스 인스턴스와 같은 객체들을 파일로 저장하고, 불러와서 직접 사용할 수 있게 해주는 라이브러리이다.
import pickle
with open('example.pkl', 'rb') as file:
example = pickle.load(file)
display(example)
# with open('example.pkl', 'rb') as file: 파일을 바이너리 읽기 모드로 열기
# pickle.load(file): 파일에서 객체를 역직렬화하여 불러오기
# display(): 역직렬화된 객체인 변수를 출력참고:
일반적으로 Jupyter Notebook과 같은 환경에서는
display() 함수를 사용하여 객체를 출력한다.
21) 딕셔너리에서 키에 해당하는 값의 키들을 리스트로 추출하기
df = list(example['results'].keys())
df
# 딕셔너리에서 'results' 키에 해당하는 값의 모든 키들을 반환22) 딕셔너리를 사용하여 열(Currency)의 값 매핑하기
import pandas as pd
# 예시 데이터프레임 생성
data = {'Currency': ['USD', 'EUR', 'GBP', 'JPY', 'CAD'],
'ExchangeRate': [1.25, 1.42, 1.66, 0.012, 0.98]}
df = pd.DataFrame(data)
# 환율 정보 딕셔너리
example_results = {'USD': 1.25, 'EUR': 1.42, 'GBP': 1.66, 'JPY': 0.012, 'CAD': 0.98}
# 소수점 다섯 번째 자리까지 출력 형식 지정
pd.options.display.float_format = '{:.5f}'.format
# 각 통화에 대한 대한민국 원(KRW)으로의 환율 계산하여 새로운 열 추가
df['ExchangeRateToKRW'] = df['Currency'].map(example_results)
# 결과 출력
print(df)참고:
map() 함수는 파이썬에서 사용되는 내장 함수 중 하나이다. 이 함수는 주어진 시퀀스(리스트, 튜플 등)의 각 요소에 대해 특정 함수를 적용한 결과를 반환한다.
- 간단히 말하면,
map()함수는 여러 개의 데이터를 한 번에 처리할 때 사용된다. 예를 들어, 리스트의 각 요소에 대해 제곱을 계산하거나, 문자열의 각 요소에 대해 대문자로 변환하는 등의 작업을 할 때 유용하다.
- function: 각 요소에 적용할 함수를 지정한다.
- iterable: 함수를 적용할 데이터를 포함하는 이터러블 객체(리스트, 튜플 등)를 지정한다.
예시:
numbers = [1, 2, 3, 4, 5] squared_numbers = map(lambda x: x ** 2, numbers) print(list(squared_numbers)) # [1, 4, 9, 16, 25]
23) 열의 값이 리스트(fakeId)에 포함되지 않는 행들로 구성된 새로운 데이터프레임을 생성하기
df_comp = df_comp[~devs_df_comp['Id'].isin(fakeId)]여기서 ~는 논리 부정 연산자로, 해당 조건을 만족하지 않는 행들을 선택하는 역할을 한다. 즉, 'fakeId' 리스트에 속하지 않는 'Id' 값을 가진 행들을 선택한다.
24) 열에 리스트 형태로 저장된 데이터를 펼쳐서 여려 행으로 분해하기
df.explode('Occupation')explode() 함수는 리스트 또는 시리즈 내에 포함된 리스트를 펼쳐서 각 원소를 개별 행으로 만들어주는 Pandas의 함수이다. 즉, 리스트를 펼쳐서 여러 행으로 분해하는 역할을 한다.
25) 열을 기준으로 데이터프레임을 그룹화하고, 각 그룹 내에서 원하는 열의 개수를 세기
type = df.groupby(['DevType', 'Occupation'])['Id'].count().reset_index(name='Count')
# groupby(): 그룹화
# count(): 각 그룹 내에서 열의 개수 세기
# reset_index(name='Count'): 새로운 열 이름으로 저장26) 데이터프레임(type)을 지정된 열(Count)을 기준으로 내림차순으로 정렬하기
type.sort_values(by='Count', ascending = False)
# sort_values() 메서드: 데이터프레임의 행을 지정된 열(들)을 기준으로 정렬
# by 옵션: 정렬 기준이 되는 열(들)을 지정
# ascending=False 옵션: 내림차순으로 정렬27) 열의 값 중에 특정 문자열을 포함하는 행들을 필터링하기
type[type['DevType'].str.contains('data', case=False)]
# str.contains('문자열'): 문자열 포함 여부 확인
# case=False 옵션: 대소문자를 구분하지 않고 검색하도록 설정3. 데이터 저장하기
df.to_csv('new_data.csv', index=False)
# to_csv(): 데이터프레임을 CSV 파일로 저장
# index=False 옵션: 인덱스를 CSV 파일에 저장하지 않도록 설정4. 데이터 불러오기
new_df = pd.read_csv('new_data.csv')
# pd.read_csv(): 파일에서 데이터를 읽어와서 새로운 데이터프레임을 생성