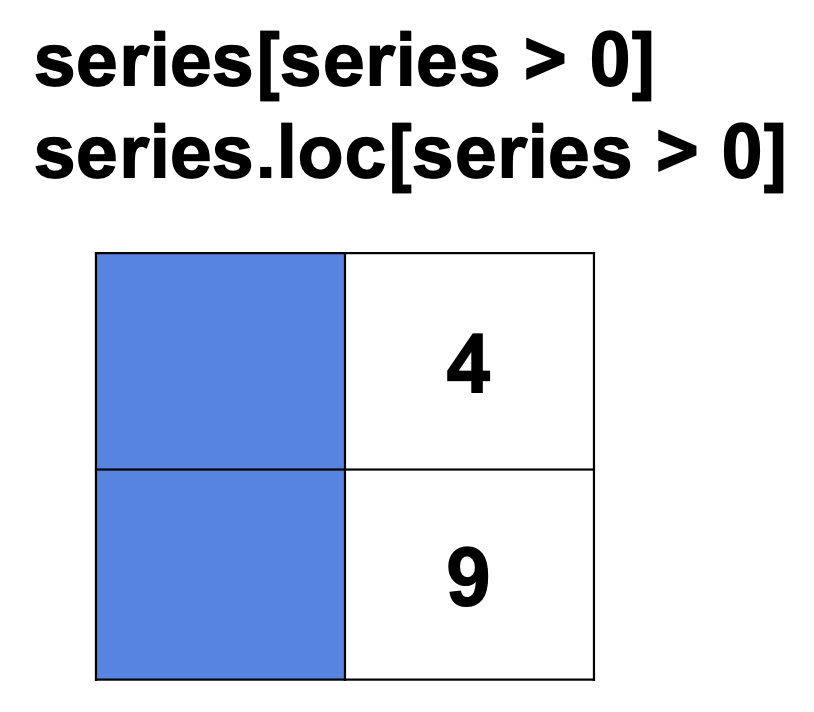1. 시리즈와 데이터프레임 속성 - 인덱서(Indexer)
인덱서(Indexer)는 판다스(Pandas)에서 시리즈(Series)나 데이터프레임(DataFrame) 안에 있는 특정 데이터를 선택하거나 조작하는 역할을 한다. 판다스에서는 인덱서를 사용하여 데이터를 더 편리하게 선택하고 조작할 수 있다.
인덱스를 사용해서 원하는 데이터에 접근하는 방법을 인덱싱(indexing)이라고 한다.
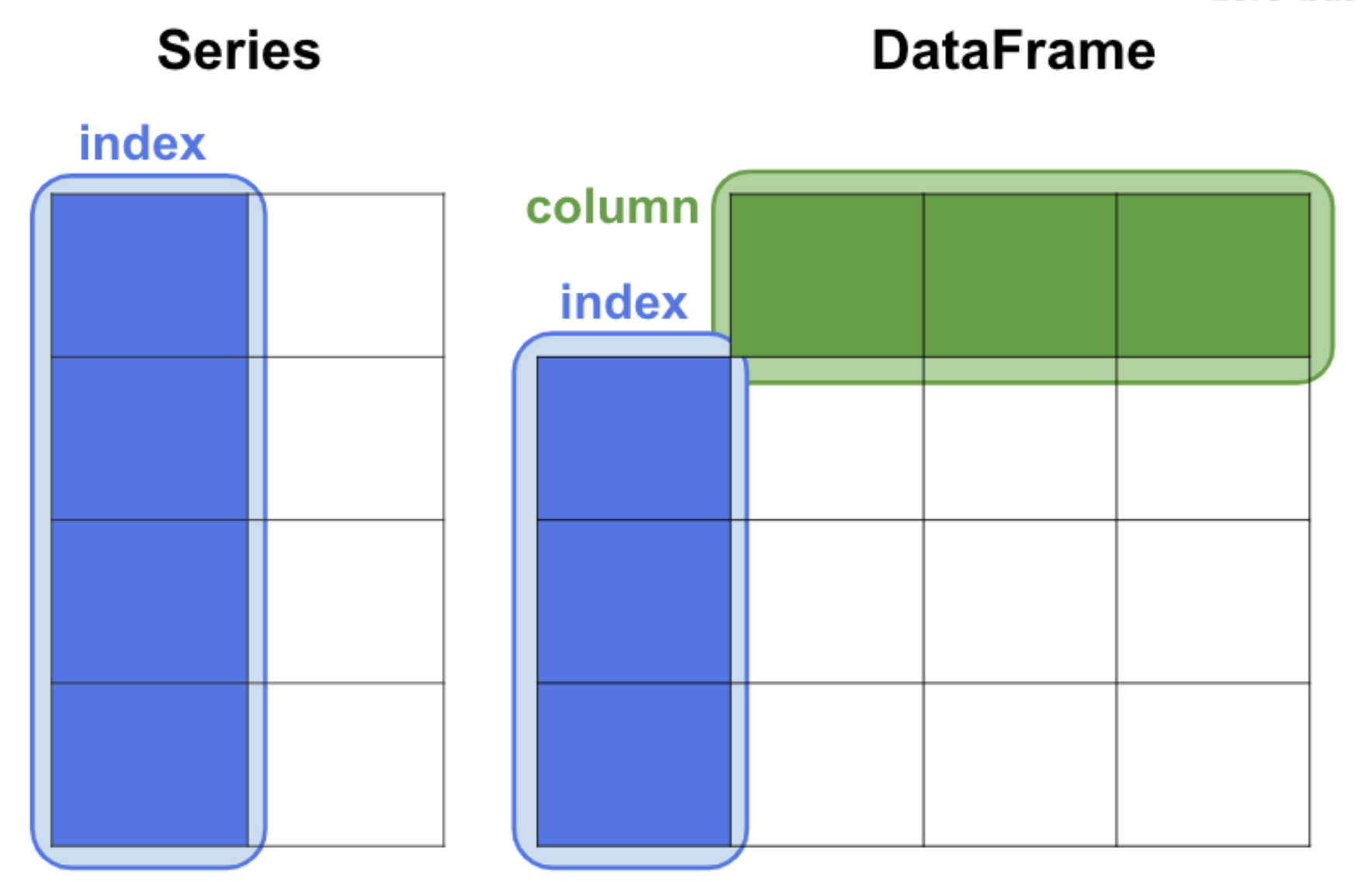
판다스(Pandas)에서는 여러가지 인덱서를 제공하고 있다.
[](Bracket Indexing)
라벨(인덱스 이름)이나 정수 인덱스를 이용하여 데이터에 접근 또는 슬라이싱 가능
series['label']
series[0].loc[](Label-based Indexing)
라벨(인덱스 이름)을 사용하여 데이터에 접근하거나 조작하는 인덱서 (.loc는 location의 약자)
series.loc['label'].iloc[](Integer-based Indexing)
정수 인덱스를 사용하여 데이터에 접근하거나 조작하는 인덱서 (.iloc은 integer location의 약자)
series.iloc[0].at[](Fast Label-based Indexing)
.loc[]과 유사한 라벨 기반 인덱싱을 제공하지만, 스칼라 값을 가져오는데 최적화
series.at['label'].iat(Fast Integer-based Indexing)
.loc[]과 유사한 정수 기반 인덱싱을 제공하지만, 스칼라 값을 가져오는데 최적화
series.iat[0]2. 스칼라(Scalar) 값이란?
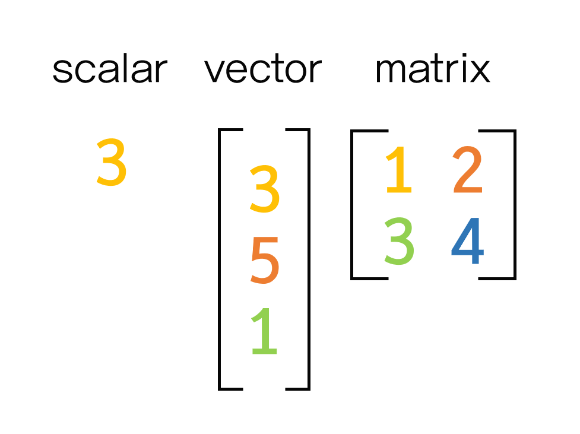
Scalar: 단일값 (0차원 데이터)
- int (정수): 10, -5, 100
- float (실수): 3.14, -0.25, 1.0
- str (문자): 'Hello', "Python"
- boolean (논리): True, False
Vector: 벡터 (1차원 배열)
Matrix: 행렬 (2차원 배열)
3. Indexing vs Fast Indexing

Pandas에서 데이터를 선택하고 접근하는 방법은 .loc[], .iloc[], .at[], .iat[] 인덱서를 사용할 수 있다. 이 네 가지 종류의 인덱서는 데이터프레임의 특정 위치에 접근하는 데 사용된다. 그러나 데이터 크기와 차원에 따라 이러한 인덱서의 성능 차이가 발생할 수 있다.
-
작은 크기의 데이터나 1차원 데이터(시리즈)
- 작은 크기의 데이터나 1차원 데이터(시리즈)의 경우, .loc[] 및 .at[]의 성능 차이를 크게 느끼지 못할 수 있다. 이는 데이터 양이 적고 차원이 단순하기 때문이다.
-
큰 데이터나 다차원 데이터
- 그러나 데이터가 크거나 다차원인 경우,
.at[]이.loc[]보다 상대적으로 더 빠른 성능을 보일 수 있다. 이는 다음과 같은 이유 때문이다. - Overhead 감소:
.at[]은 내부적으로 더 적은 오버헤드를 가지고 있다. 따라서 대량의 데이터를 처리할 때 더 효율적이다.
- Overhead 감소:
- 인덱싱 오버헤드 감소:
.loc[]은 인덱싱 연산의 추가 오버헤드가 있을 수 있다. 이는 다차원 데이터에서 특히 더 큰 영향을 미친다..at[]은 이러한 추가 오버헤드가 없어 더 효율적이다.
- 인덱싱 오버헤드 감소:
- 그러나 데이터가 크거나 다차원인 경우,
따라서 큰 데이터셋이나 다차원 데이터에서는 .at[]이 데이터 접근에 더 효율적일 수 있다. 하지만 데이터의 크기와 상황에 따라 실제 성능 차이는 달라질 수 있으므로 데이터셋의 특성을 고려하여 적절한 인덱서를 선택해야 한다.
4. 불리언 (Boolean) 인덱싱
불리언 인덱싱(boolean indexing)은 참(True) 또는 거짓(False) 값을 가지는 조건을 활용하여 데이터를 선택하는 방법이다. 이 방법은 데이터의 실제 값을 기반으로 조건을 설정하고, 해당 조건을 만족하는 데이터만을 선택한다.
예를 들어서,
series > 0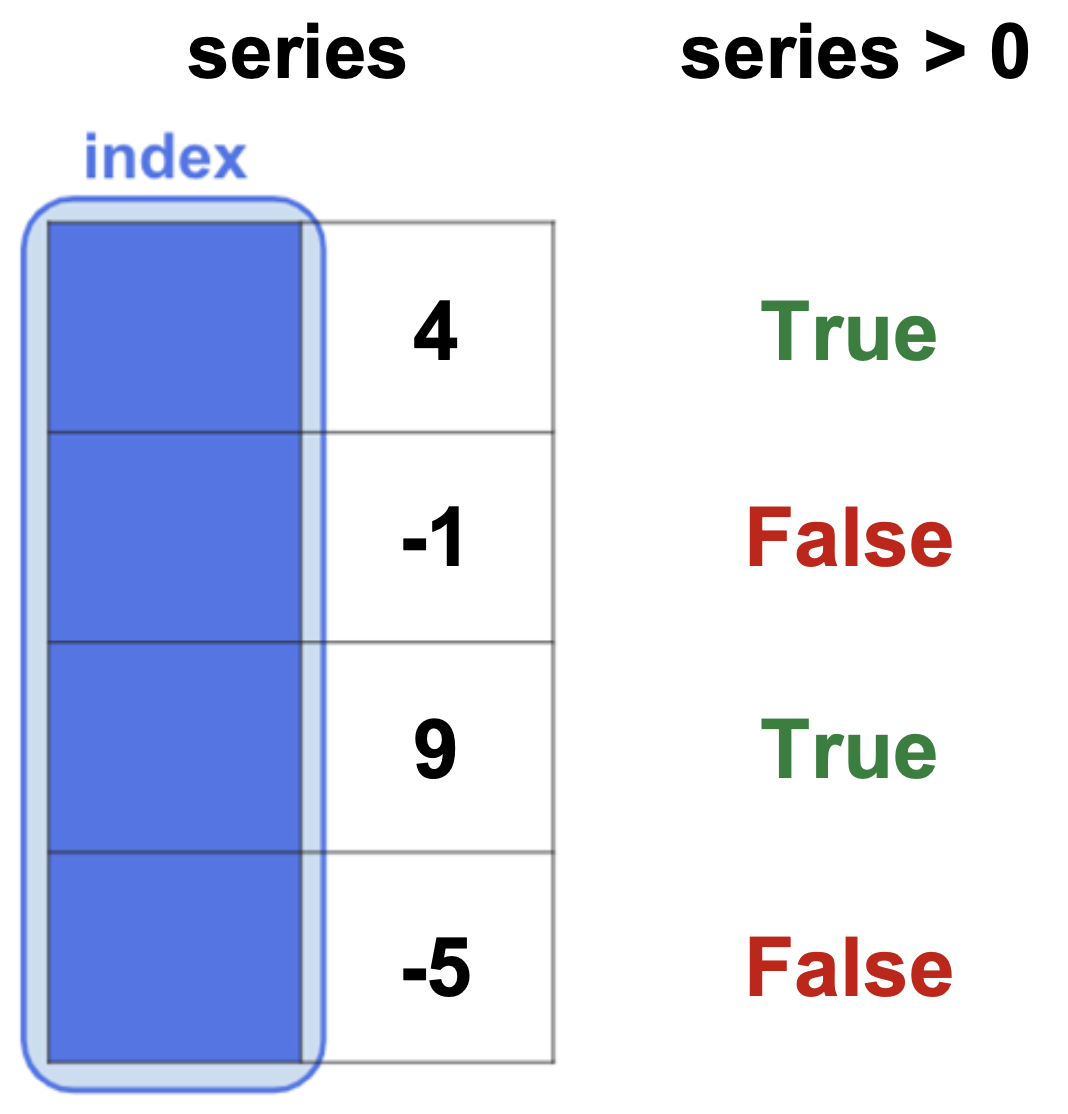
그리고 이 불리언 시리즈를 다시 원래의 시리즈에 적용하여 True에 해당하는 값들만 선택한다.
seres[series > 0]
series.loc[series > 0]