- 분류: Language Model
- 저자: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
- 소속: Google
- paper: Efficient Estimation of Word Representations in Vector Space
- 키워드: word2vec, word embedding, CBOW
자연어 처리(NLP) 분랴에서 word-embedding 기법의 혁신적 발전을 이룬 연구
1. 연구 배경
기존 자연어 처리 모델
- 단어를 개별 원자 단위로 취급했기 때문에 단어 간 유사성은 고려되지 않음
- 대표적으로 N-gram 모델
- 한계점
- 문맥을 고려하지 않음 -> 희소성 문제 해결 곤란
- 신경망 기반 언어 모델(NNLM, RNNLM)은 단어 벡터 학습 가능, 계산 비용 매우 높음
- 대규모 데이터셋을 처리하는 효율적인 방법 필요
(+) 기존 모델의 희소성(sparsity) 문제
단어를 개별 원자 단위로 취급, 학습 데이터에 존재하지 않는 단어가 문맥을 제대로 처리하지 못함
계산량은 줄이고 단어 간 관계를 효과적으로 학습하는 word-embedding 모델 제안
2. 핵심 아이디어 및 방법론
핵심 목표: 고품질의 단어 벡터를 매우 큰 데이터셋에서 효율적으로 학습하는 방법 찾기
1) 모델 제안
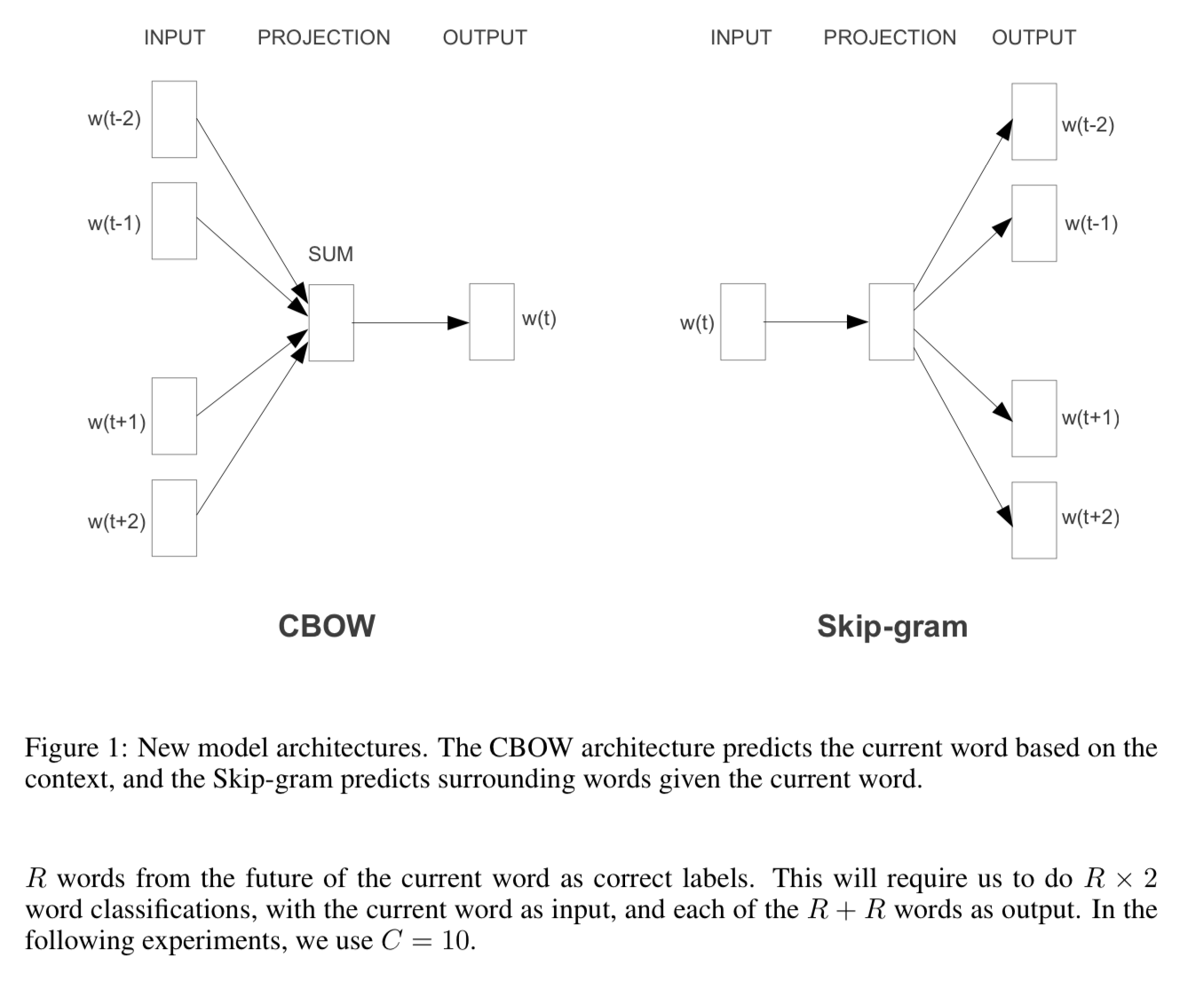
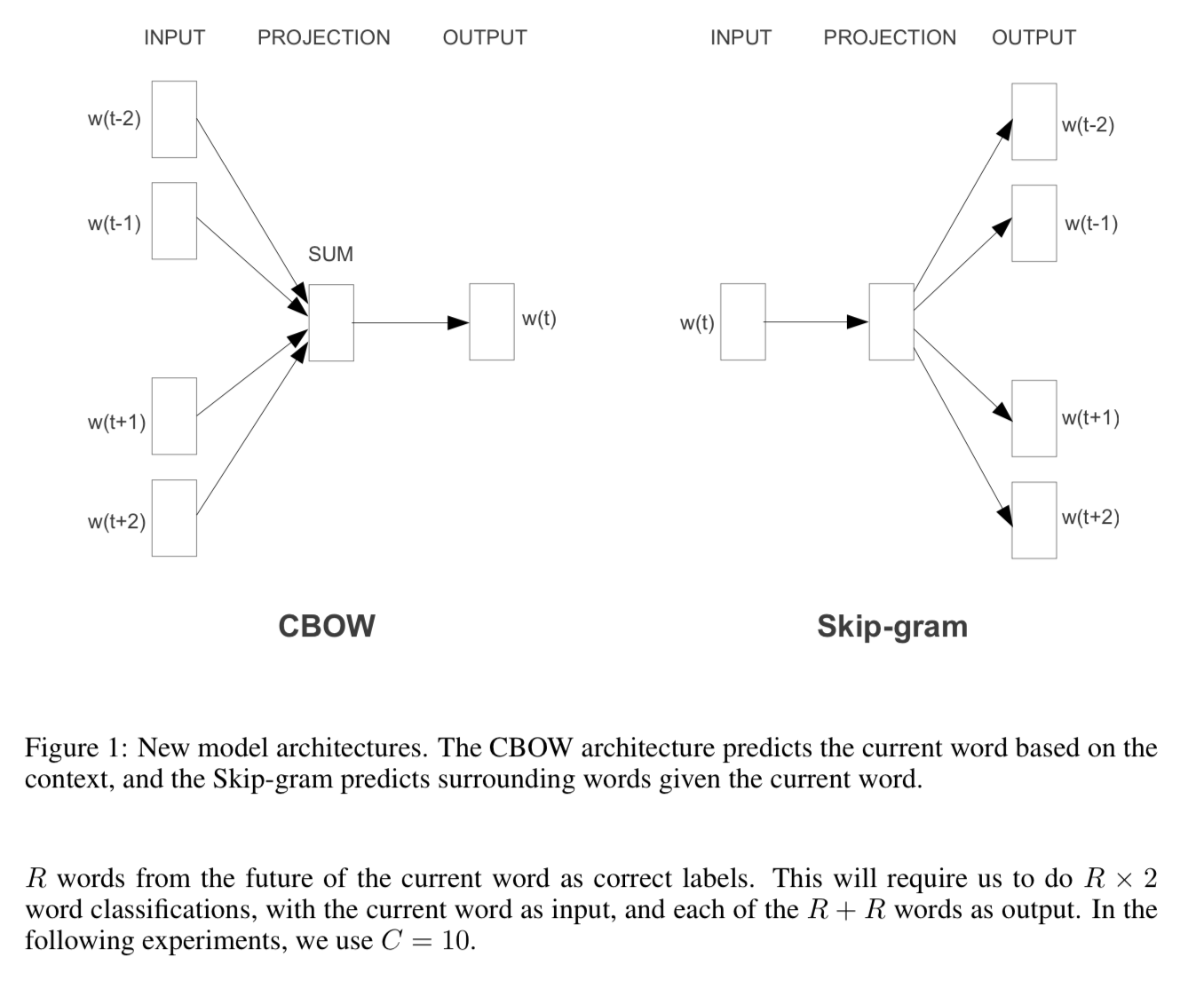
제안 모델 #1: CBOW(Continuous Bag-of-Words)
-
문맥(앞뒤 단어들)로부터 현재 단어 예측
-
단어 순서 정보 무시, 평균 벡터 활용
(예) I love NLP와 love NLP I는 같은 입력으로 처리[단어 순서 정보를 무시하는 이유]
1) 학습 속도와 계산 효율성 증가: 고려 시, 네트워크 구조가 복잡해지고 계산량 증가
2) 단어 순서보다 단어 의미의 연관성이 중요할 수 있음: 문맥을 구성하는 단어의 존재 자체가 더 중요
3) N-gram 모델에서 순서가 강하게 적용되던 문제 해결
순서가 고정되어 있어 새로운 조합을 잘 학습하지 못함. CBOW에서는 순서 제거로 일반적인 표현 학습 가능 -
매우 빠른 속도
제안 모델 #2: Continuous Skip-gram
- 현재 단어를 기반으로 주변 단어 예측
- 넓은 범위의 단어 관계 학습 가능
- CBOW 보다 속도는 느리지만, 의미적 관계를 잘 반영
2) 모델 최적화
- 계산량 감소: 기존 NNLM보다 단순한 구조로 연산량 대폭 감소
- Huffman 트리기반 softmax 활용: 빈도 기반 계층적 softmax 적용 -> 학습 속도 향상
- 대규모 병렬 학습: Google의 DistBelief 분산 학습 프레임워크 활용, 수천 개의 CPU 코어에서 병렬 처리
3. 실험 및 핵심 작업
1) 단어 유사성 평가
단어 벡터가 의미적 및 문법적 관계를 얼마나 잘 포착하는지 평가
예) ‘king-man + woman = queen’
예) ‘Paris-France + Italy = Rome’
2) 대규모 데이터셋 학습
- Google News 데이터셋(60억 단어)
- 100만 개 이상의 단어 벡터 생성
- 벡터 차원 & 데이터 크기에 따른 성능 비교
3) 다양한 모델 성능 비교
- 기존 NNLM, RNNLM과의 성능 비교
- microsoft senetence comletion challenge 벤치마크 실험
4. 결과 및 분석
1) 성능 비교
- 제안된 CBOW & Skip-gram 모델은 기존 신경망 모델보다 뛰어난 성능을 보임
- 훨씬 적은 계산 비용으로도 높은 품질의 단어 벡터 생성
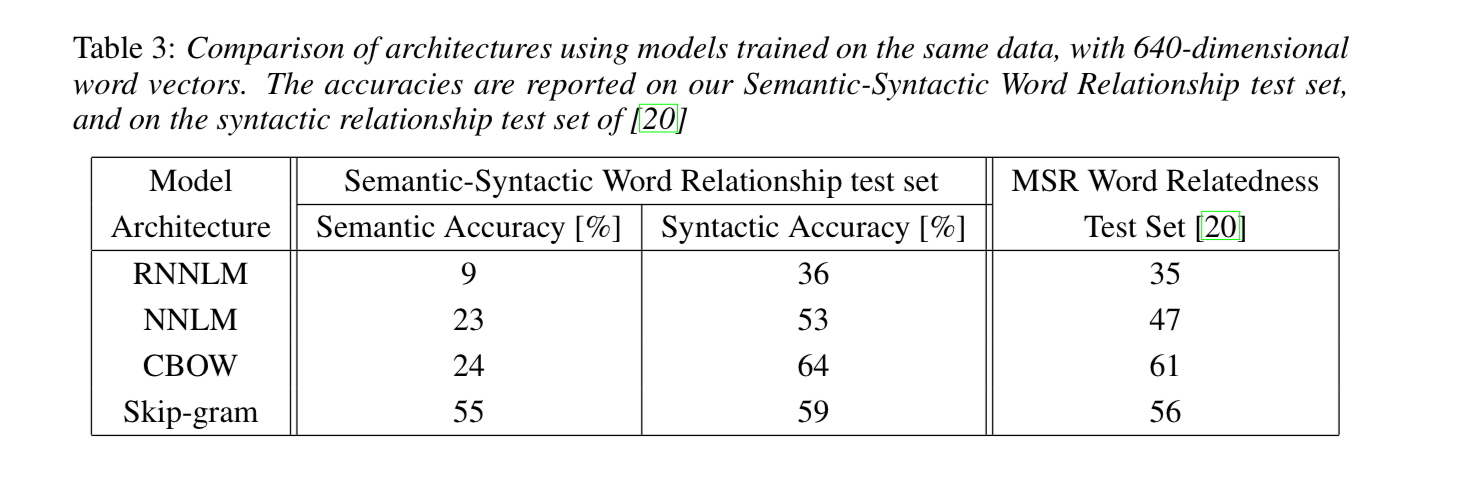
- Skip-gram: 의미적 관계 학습에서 가장 높은 성능
- CBOW: 빠른 속도와 우수한 문법적 관계 학습 성능
- NNLM & RNNLM보다 적은 연산량 & 높은 성능
2) 학습 데이터 크기 및 차원의 영향
- 학습 데이터 크기와 벡터 차원이 증가할수록 성능 향상
- 일정 수준 이상에선느 성능 향상 둔화
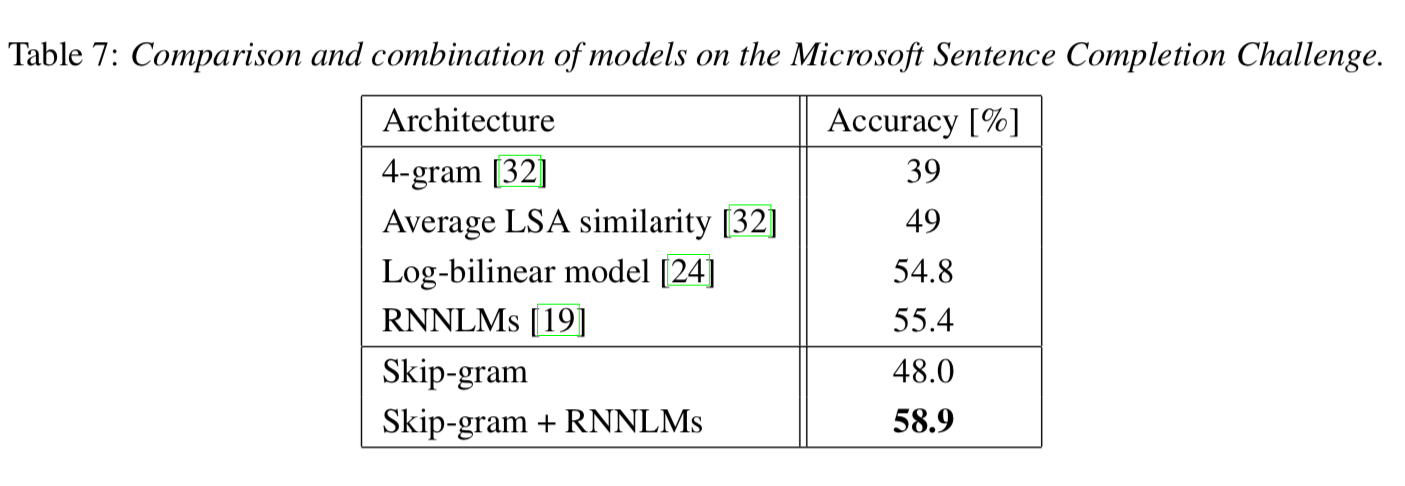
3) Microsoft Sentence Completion Challenge
기존 RNNLM(55.4%)보다 높은 58.9% 정확도 기록
4) 성능 측정 방법
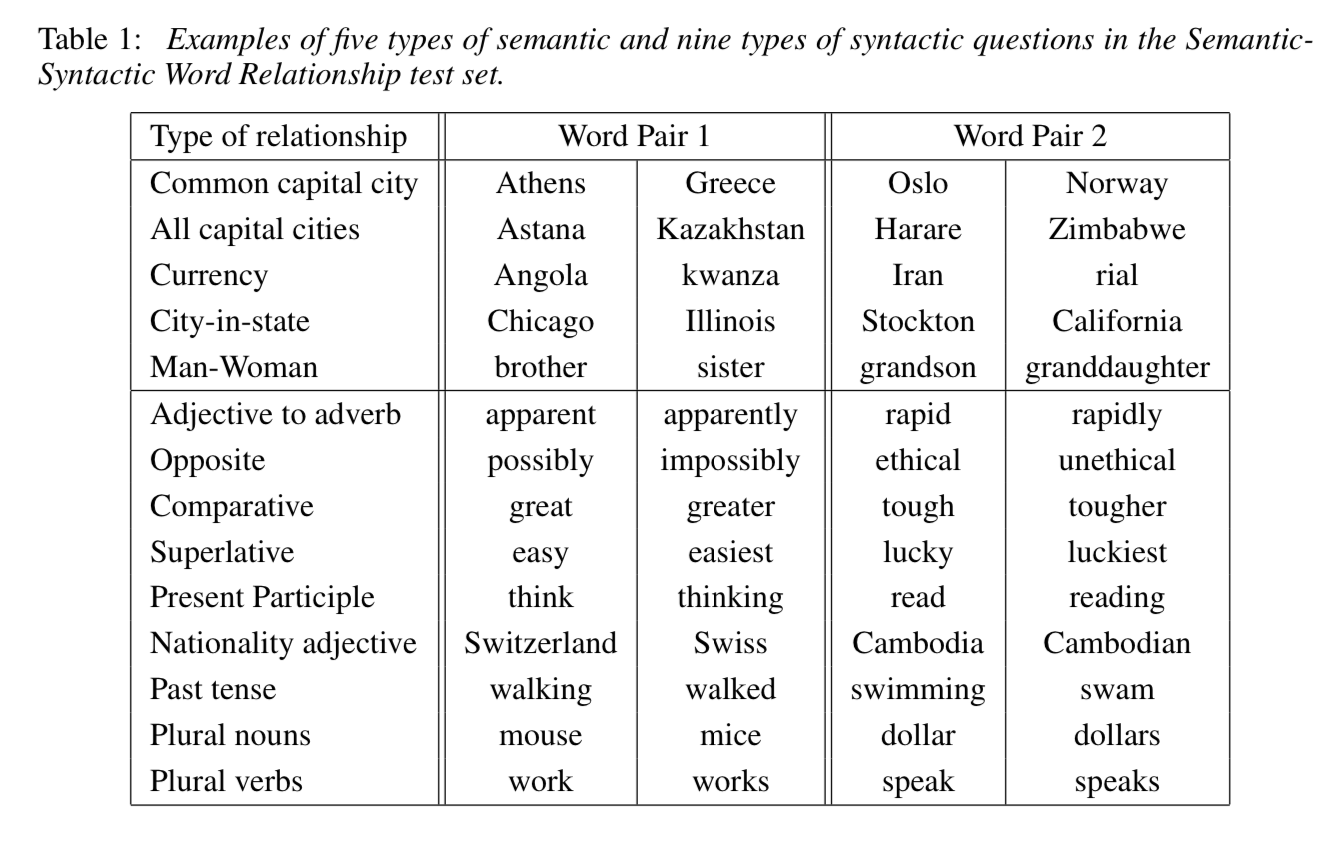
단어 관계 테스트(Word Anology Task)
핵심 개념
- 단어 벡터가 의미적(semantic) 및 문법적(syntactic) 관계를 잘 표현하는지
- 벡터 연산으로 단어 간 관계 추론 능력 측정
평가 방법
특정한 단어 관계를 표현하는 연산 수행, 가장 유사한 벡터를 찾아 정답 맞추기
(예)
vector(‘King’) - vector(‘Man’) + vector(‘Woman’) ≈ vector(‘Queen’)평가 데이터 구성: semantic-syntatic word relationship test set 생성
점수 계산
- 벡터 연산을 통해 예상되는 단어 벡터 계산, 가장 가까운 단어가 정답이면 정답
- 전체 질문 중 정답을 맞춘 비율로 평가
문장 완성 테스트(Microsoft Sentence Completion Challenge)
핵심 개념
- 단어 벡터가 실제 문장에서 적절한 단어를 예측할 수 있는지?
- 실제 NLP 태스크에서의 모델 성능 검증
평가 방법
- Microsoft Sentence Completion Challenge 데이터셋 사용
- 총 1040개 문장에서 하나의 단어가 비워져 있고, 5개의 선택지 제공
결과
5. 결론 및 향후 연구 방향
CBOW와 Skip-gram이 기존 NNLM, RNNLM보다 훨씬 빠르고 효율적으로 단어 벡터 학습
1) 핵심 기여
- CBOW 모델은 빠른 속도로 대규모 데이터 학습 가능
- Skip-gram 모델은 의미적 관계를 정교하게 학습
- 대규모 분산 학습으로 실제 적용 가능성 증명
2) 한계점
- 고정된 단어 표현: 문맥에 따라 달라지는 단어 의미 반영 X
- 구문 정보 부족: 단순 단어 벡터만으로는 문장 구조 반영 곤란
- 다의어 처리 한계: 단어의 여러 의미를 구별하는 메커니즘 부재
3) 향후 연구 방향
- 컨텍스트를 고려한 동적 단어 벡터 학습
- 개별 단어가 아닌 구문 및 문장 단위 학습으로 확장
- 단어 의미 변화를 반영하는 기술 개발
