- 분류: Object Detection
- 저자: Ross Girshick, ,Jeff Donahue, Trevor Darrell, Jitendra Malik
- 소속: UC Berkeley
- paper: Rich feature hierarchies for accurate object detection and semantic segmentation
- 키워드: R-CNN, bounding-box regression, semantic segmentation, fine-tuning
1. 연구 배경
기존의 객체 검출(Object Detection)
주로 HOG(Histogram of Oriented Gradients) & SIFT(Scale-Invariant Feature Transform) 사용
→ 저수준 특징(low-level features) 활용으로 모델 구성
2010-2012, 정체된 성능 향상: PASCAL VOC 데이터셋
가장 좋은 성능을 보인 것은 여러 모델을 조합한 복잡한 앙상블 시스템
2012, AlexNet
ImageNet에서의 획기적인 성능 향상 → 딥러닝 기반 접근법이 주목 받기 시작
→ 하지만, 이미지 분류/객체 검출은 다른 분야, CNN이 객체 검출에도 좋은 성능을 보일지 의문
⇒ 지역 제안(Region Proposals) + CNN = R-CNN 제안
2. 핵심 아이디어 및 방법론
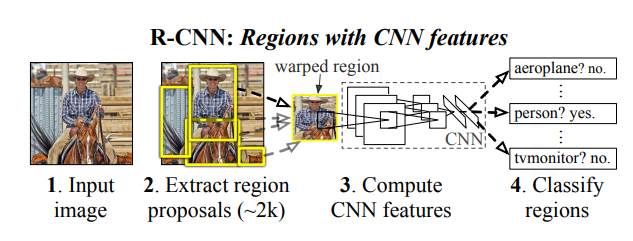
1) 핵심 아이디어
객체 검출을 위한 Region Proposals(지역 제안) + CNN 결합
전체 이미지를 처리하지 않고 선택적 탐색(selective search)로 존재 가능성이 높은 약 2000개의 지역(Region Proposals) 생성 후, CNN에 입력하여 특징 추출
→ 기존의 슬라이딩 윈도우 방식(OverFeat)보다 더 효율적 & 정확한 방법으로 활용
Selective Search(선택적 탐색)
객체 검출에서 바운딩 박스 후보 영역을 생성하는 기법
-
selective search가 필요한 이유: 기존 슬라이딩 윈도우의 문제점
- 모든 위치와 크기의 윈도우를 이동시키며 객체를 탐색하는 방식
- 그러나, 윈도우 크기, 비율, 위치를 조정해야 하는 경우의 수가 많아 연산량이 기하급수적으로 증가
- 특히, 딥러닝 기반 CNN을 모든 윈도우에 적용하면 연산량이 너무 커서 비효율적
→ Selective Search는 이러한 문제를 해결하기 위해 제안된 기법, 슬라이딩 윈도우 대신 ‘의미있는 후보 영역(region proposals)’만 선택하여 연산량을 줄이는 방법
-
Selective search 알고리즘 원리
저수준(low-level) 이미지 분할 기법을 기반으로 객체 후보 영역을 생성하는 방식
-
주요 과정
(1) 초기 이미지 분할(inital segmentation)
- 먼저, superpixel 분할 기법을 적용하여 작은 유사한 영역들도 이미지 분할
- superpixel은 색상, 질감, 경계를 기반으로 비슷한 픽셀들을 묶어 작은 영역으로 나눔
- 예: SLIC(Simple Linear Iterative Clustering) 알고리즘 사용 가능
(2) 유사한 영역 병합(region merging)
- 초기 superpixels을 점진적으로 병합하여 더 큰 후보 영역(region proposals) 생성
- 병합 기준
- 색상(color) 유사성
- 텍스처(Texture) 유사성
- 크기(size) 유사성
- 윤곽선(edge) 유사성
- 비슷한 영역끼리 합쳐 나가면서 점진적으로 객체 후보 영역 형성
(3) 다양한 크기 및 비율의 후보 영역 생성
- 모든 병합 과정에서 생성된 당야한 크기와 비율의 바운딩 박스를 저장
- 이렇게 하면 다양한 객체 크기와 위치를 커버할 수 있음
(4) 최종 region proposals 출력
- 최종적으로 대략 1000 ~ 2000개의 객체 후보 영역만 선택하여 CNN으로 전달
- 기존의 슬라이딩 윈도우 방식에 비해 연산량을 크게 절감 & 객체 탐지 성능 유지
-
-
Selective search의 장점과 단점
- 장점
-
연산량 감소
- 모든 위치에 대해 CNN을 실행하는 것이 아니라 객체가 있을 가능성이 높은 영역만 선택
- 슬라이딩 윈도우보다 훨씬 적은 영역만 평가하므로 계산 비용 절감
-
객체 크기 및 비율 고려 가능
- 초기 superpixel 분할 및 영역 병합을 통해 다양한 크기와 비율의 바운딩 박스 생성
- 다양한 객체 크기를 포착할 수 있어 검출 성능 향상
-
객체의 윤곽과 일치하는 후보 영역 생성 가능
selective search는 색상, 텍스처, 크기 등을 고려하여 유사한 픽셀을 병합하므로 ,객체의 윤곽을 더 잘 따르는 후보 영역을 생성할 가능성이 높음
-
- 단점
-
여전히 연산량 많음
- selective search는 슬라이딩 윈도우보다 훨씬 빠르지만, selective search 자체도 연산량이 많아 속도가 느림
- 특히, 딥러닝 기반 객체 검출이 발전함에 따라 selective search 없이 CNN 자체에서 region proposals을 생성하는 방법이 필요하게 됨
-
end-to-end 학습 불가능
selective search는 딥러닝 모델이 아닌 전통저인 컴퓨터 비전 기법, CNN과 함께 학습이 불가능, 딥러닝 기반 최적화가 어려움
-
객체 탐지 정확도의 한계
selective search는 객체가 아닌 부분을 포함하는 바운딩 박스도 생성할 가능성이 높음. 작은 객체를 정확하게 찾기 어려울 수 있음
-
- 장점
CNN’s pre-training & domain-specific Fine-tuning
- 대규모 데이터셋(ILSVR2012)로 CNN을 학습한다.
- 학습된 모델에 객체 검출용 데이터셋(PASCAL VOC)로 fine-tuning을 한다.
-> 기존 방식(DPM 등)은 작은 데이터셋에서 학습하기 어려웠지만, 사전 학습 + 미세조정으로 적은 데이터로도 CNN 성능 극대화 가능
2) R-CNN(Regions iwth CNN features)
-
입력 이미지에서 지역 제안(region proposals) 생성
selective search 알고리즘으로 약 2000개의 후보 영역 탐색
-
제안된 영역을 CNN으로 특징 추출
- 크기가 다른 지역을 CNN이 처리할 수 있도록 고정 크기(227 * 227)로 변환
- CNN의 마지막 feature vector(4096 차원) 추출
→ 특징 추출기의 가능성, 전이 학습(Transfer learning)의 기반이 됨
-
SVM으로 feature vector 분류
객체별 선형 SVM 학습, 해당 영역이 특정 객체인지 판단
-
비최대 억제(Non-Maximum Suppression, NMS) 적용
중복된 검출 결과 제거, 최종적으로 객체 위치 결정
3. 실험 및 핵심 작업
1) PASCAL VOC에서 기존 방법과 비교
- 기존 방법들과 동일한 지역 제안 방법(selective search) 사용으로 비교 실험
- R-CNN: 기존 최고 성능 모델보다 30%p 이상 성능 향상
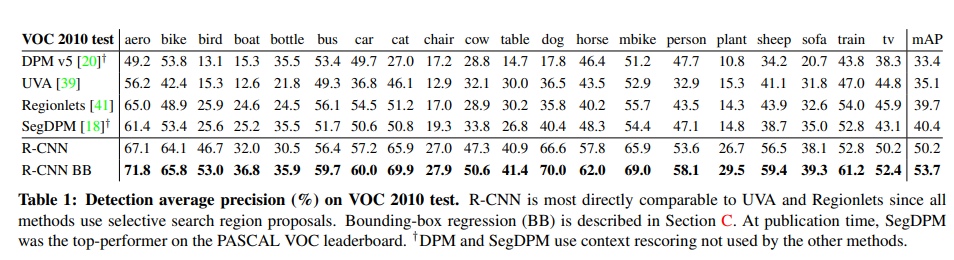
- selectived search 기반 방법론과 비교하여 큰 성능 향상을 보임
2) ILSVRC 2013
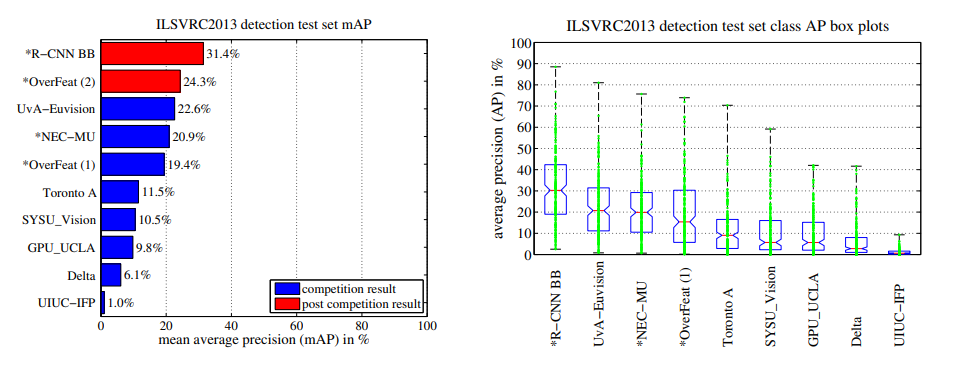
- OverFeat(mAP 24.3%)과 비교하여 31.4%로 7%p 향상
3) CNN의 학습 전략 검증
사전 훈련(ILSVRC) + fine-tuning(PASCAL VOC)의 효과 입증하기
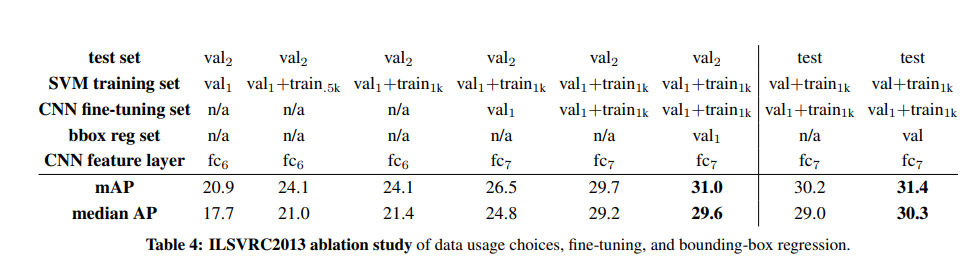
→ 적은 데이터에서도 CNN의 성능을 극대화하는 데에 효과적
5. 결론 및 향후 연구 방향
1) 결론
- CNN을 지역 제안과 결합한 R-CNN이 기존 객체 검출보다 뛰어남을 입증함 → Faster R-CNN을 넘어 Region Proposal Network(RPN) 개발에 영향
- PASCAL VOC 2012에서 기존 최고 성능 대비 30%p 향상(mAP 53.7%)
- ILSVR 2013에서도 OverFeat보다 7%p 높은 성능(mAP 31.4%)
- pre-training + fine-tuning: 적은 데이터로 강력한 학습 가능 → 딥러닝 기반 태스크(의료 영상 분석, 위성 영상 분석, …)에서 광범위하게 사용되는 핵심 학습 기법이 됨
2) 향후 연구 방향
실시간 속도 개선 필요
R-CNN은 높은 성능을 보이지만 속도가 느림
더 향상된 지역 제안 연구
selective search는 고정된 제안 방식, CNN과 통합된 방식으로 개선이 가능함
→ 이후, Faster R-CNN, YOLO, SSD 등의 기반이 됨
더 정밀한 위치 예측 방법 추가
bounding-box regression을 넘어 보다 정확한 객체 위치 조정 방법 개발 피리요
→ bounding-box regression은 객체 검출에서 필수적 기법이 됨
Bounding-Box Regression
객체 검출(Object Detection)에서 예측된 바운딩 박스의 위치를 더 정확하게 조정하기 위한 방법
-
필요한 이유
기존 객체 검출 모델은 객체가 존재하는 영역을 CNN을 통해 분류하는 방식 사용. 그러나,
-
초기 바운딩 박스가 정확하지 않음
selective search/region proposal network에서 생성된 바운딩 박스는 대략적 객체 위치만 제공 → 경계가 맞지 않거나 너무 크거나 작을 가능성 높음
-
객체의 크기와 위치가 다양함
- 다양한 객체의 크기의 비율에 따라 바운딩 박스가 부정확하게 설정될 수 있음
- 특히, 작은 객체나 경계가 불분명한 객체는 더 정확한 위치 조정 필요
→ bounding box regression을 통해 바운딩 박스의 위치를 조정하면 객체의 검출 정확도 향상
-
-
원리
단순히 바운딩 박스를 다시 예측하는 것이 아니라, 기존 바운딩 박스를 작은 범위 내에서 조정하는 방식
-
수학적 표현
- : 바운딩 박스의 중심 좌표
- : 바운딩 박스 너비와 높이
모델은 기존 박스에서 보정값(offset)을 학습하여 적용
보정 후의 새로운 바운딩 박스
- 는 학습을 통해 최적화되는 보정값
- → 바운딩 박스 중심의 위치 조정
- → 바운딩 박스 크기를 조정(log-space에서 변환하여 안정적으로 조정)
-
바운딩 박스 보정
- 각 region proposal에 대해 CNN을 적용하여 특징 벡터 생성
- 각 객체 클래스별 회귀 모델 학습
- 학습된 보정값을 기존 바운딩 박스에 적용
-
-
bounding box regression의 학습 과정
일반적으로 회귀(regression) 문제, L2 손실(mean squared Error, MSE) 사용하여 학습
-
학습 데이터 구성
- 입력: CNN을 통해 추출된 pool5 특징 벡터
- 출력: ground-truth 박스와 예측 박스 간의 차이(보정값)
-
손실 함수
예측된 박스가 실제 정답 박스에 가깝도록 조정하는 것. 손실 함수로 L2 손실(MSE) 사용
- : 예측된 보정값
- : 실제 보정값(ground truth 기준)
*이 손실 함수가 최소화되도록 회귀 모델을 학습하여, 정확한 바운딩 박스를 예측할 수 있도록 함
-
-
bounding box regression의 성능 향상 효과
- 객체 검출 정확도(mAP)
- localization 오류 감소
- 작은 객체 검출 성능 향상
-
한계
- 바운딩 박스를 보정하는 방식이지만, 여전 객체의 형태까지 정확히 표현
- 객체의 위치를 조정하는 것만 가능, 픽셀 단위의 마스크(instance segmentation)까지 제공하지 못함
- 작은 객체 또는 겹쳐 있는 객체의 경우, bounding box regression만으로는 한계가 있음
