이전에 랜포를 소개하는 글에서 모델 학습 방법을 소개하면서 예측하는 방법도 같이 언급했었다.
여기서는 조금 다른 예측 방법을 소개한다.
캣부스트로 학습을 시켜준 코드를 먼저 확인해보자.
from catboost import CatBoostClassifier
cbc = CatBoostClassifier(verbose = 200)
cbc.fit(train2, train['OutcomeType'])여기서는 OutcomeType 셀에 대해서 학습을 시켜준 것 같다.
이 셀의 내용을 확인해보자.

위와 같이 몇개의 클래스로 분류된다.
그렇다면 위 몇개의 클래스가 각각 몇 퍼센트의 확률로 예측되는지 궁금할 것이다.
이때 사용하는 코드이다.
result = cbc.predict_proba(test2)
result결과를 확인해보자.
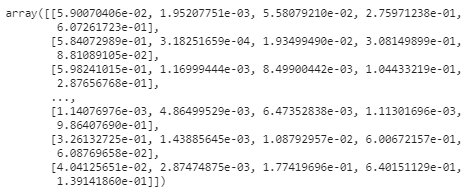
각 행에 대해서 각각의 클래스가 될 확률이 몇 퍼센트인지 수치가 나온다.
어떤 클래스가 몇 번째인지 알고 싶다면, sub을 출력해서 확인하는 방법도 있다.
우선 sub을 확인해보자.

이것은 sub의 column내용이다. 알파벳 순으로 정렬되어 있는 걸 확인할 수 있는데,
위의 .predict_proba도 마찬가지로 알파벳 순으로 출력되게 된다!
이제 우리가 하고싶은 일은 아마 저 숫자들을 sub안으로 옮기는 일 일 것이다.
sub.iloc[:,1:] = result
sub예측한 값들을 .iloc을 이용하여 sub파일의 해당 셀에 넣어주면 된다!
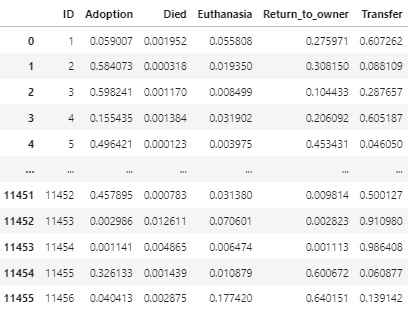
실행한 결과이다.

뜬금없지만 세계여행이 꿈입니다.