
이번에는 이전 글에서 설명한 Multi-Kernal 1D CNN을 가지고 의도 분류(Intent Classification)를 해 보려고 한다.
의도 분류는 챗봇에서 주로 사용되는데, 예를들어 "주말에 문 여는 대치동 맛집 추천해줘"라는 문장의 의도는 "맛집 추천"이 될 것이고, 이 문장 안에서 챗봇이 다른 구문을 해석하여 대답하게 될 것이다.
이번 글에서는 문장의 의도를 파악하는 의도 분류의 모델을 1D CNN으로 만들어보자.
Packages
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import preprocessing
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Embedding, Dropout, Conv1D, GlobalMaxPooling1D, Dense, Input, Flatten, Concatenate
from sklearn.metrics import classification_report
import urllib.request
urllib.request.urlretrieve("https://github.com/ajinkyaT/CNN_Intent_Classification/raw/master/data/train_text.npy", filename="train_text.npy")
urllib.request.urlretrieve("https://github.com/ajinkyaT/CNN_Intent_Classification/raw/master/data/test_text.npy", filename="test_text.npy")
urllib.request.urlretrieve("https://github.com/ajinkyaT/CNN_Intent_Classification/raw/master/data/train_label.npy", filename="train_label.npy")
urllib.request.urlretrieve("https://github.com/ajinkyaT/CNN_Intent_Classification/raw/master/data/test_label.npy", filename="test_label.npy")패기지를 다운받아준 후 전처리 작업을 해보자.
Data Preprocessing
먼저 다운받은 패키지의 폴더트리를 확인하기 위해 아래 명령어를 실행한다.
!ls
위처럼 npy파일이 있는 것을 확인할 수 있다.
npy파일을 원활하게 로드하기 위해서 pickle파일을 허용해줘야 한다.
old = np.load
np.load = lambda *a,**k: old(*a, allow_pickle=True, **k)우선 train_text.npy를 열어보면,

이런 형식으로 저장되어있다. 리스트 형식으로 바꿔주기 위해서 코드에 .tolist()함수를 붙여주자.
intent_train = np.load(open('train_text.npy', 'rb')).tolist()
label_train = np.load(open('train_label.npy', 'rb')).tolist()
intent_test = np.load(open('test_text.npy', 'rb')).tolist()
label_test = np.load(open('test_label.npy', 'rb')).tolist()
출력해보면 리스트로 바뀌어있다.
이제 길이를 확인해보자.
print('훈련용 문장의 수 :', len(intent_train))
print('훈련용 레이블의 수 :', len(label_train))
print('테스트용 문장의 수 :', len(intent_test))
print('테스트용 레이블의 수 :', len(label_test))
11784개의 훈련 샘플, 600개의 테스트 샘플이 있다.
샘플 몇개만 확인해보자.
1~5번째 샘플을 확인한 결과다.

2001~2002번째 샘플을 확인한 결과다.

하나하나 다 확인할 수 없으니, 표로 확인해보도록 하자.
temp = pd.Series(label_train)
temp.value_counts().plot(kind = 'bar',color='orange')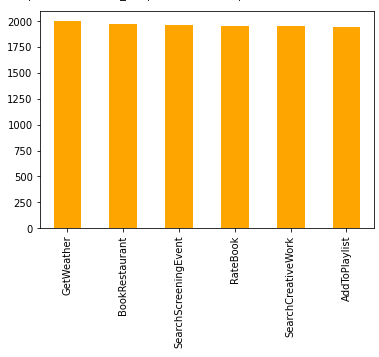
모든 문장은 총 6가지의 의도로 분류가능하다.
Encoding
이제 이 6개의 카테고리들을 고유한 정수로 인코딩하자.
이런 경우에는 sklearn의 preprocessing.LabelEncoder()를 사용할 수 있다.
idx_encode = preprocessing.LabelEncoder()
idx_encode.fit(label_train)정수를 부여했으니 정수로 변환시켜주자. label_train과 label_test둘다 변환시켜준다.
label_train = idx_encode.transform(label_train)
label_test = idx_encode.transform(label_test)
label_idx = dict(zip(list(idx_encode.classes_), idx_encode.transform(list(idx_encode.classes_))))
print(label_idx)
label_idx에서 각 카테고리가 몇번 정수를 부여받았는지 확인할 수 있다.
label_train의 앞 5개를 확인해보자. 아마 0으로 5개가 나왔을 것이다.
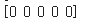
label_test도 같을 것이다. 따로 확인하지는 않겠다.
이번에는 토큰화를 해보자.
Tokenization
intent_train에 대해 토큰화를 해주기 전에 모습을 보자.
['add another song to the cita rom ntica playlist', 'add clem burke in my playlist pre party r b jams', 'add live from aragon ballroom to trapeo', 'add unite and win to my night out', 'add track to my digster future hits']
토큰화를 해주자.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(intent_train)
sequences = tokenizer.texts_to_sequences(intent_train)
sequences[:5]마지막으로 상위 5개 샘플을 출력해보면 아래와 같은 결과가 나온다.

토큰화가 된 모습이다. 단어가 고유한 숫자로 바뀌었다.
몇개의 단어가 존재하는지 확인해보자.
word_index = tokenizer.word_index
vocab_size = len(word_index) + 1
print('단어 집합(Vocabulary)의 크기 :',vocab_size)
11784개의 샘플 안에 9870개의 단어 집합이 존재한다.
이번엔 나중에 패딩작업을 위해 문장의 최대 길이와 평균 길이를 확인해보자.
print('문장의 최대 길이 :',max(len(l) for l in sequences))
print('문장의 평균 길이 :',sum(map(len, sequences))/len(sequences))
plt.hist([len(s) for s in sequences], bins=50, color='orange')
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()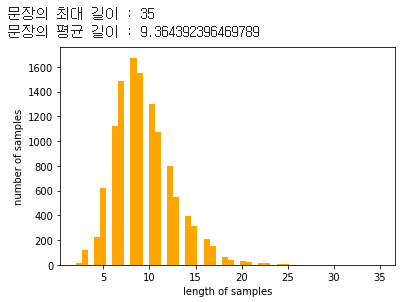
평균길이는 9.3이고 최대 길이는 35이다.
35정도면 그렇게 긴 길이는 아니니 모든 훈련 데이터를 35길이로 패딩해보자. 레이블의 경우에는 다중 클라스 분류를 수행하기 위해서 원-핫 인코딩을 넣어준다.
Padding
max_len = 35
intent_train = pad_sequences(sequences, maxlen = max_len)
label_train = to_categorical(np.asarray(label_train))
print('전체 데이터의 크기(shape):', intent_train.shape)
print('레이블 데이터의 크기(shape):', label_train.shape)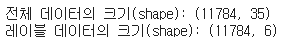
패딩해주고 난 후, 전체 데이터의 크기가 35로 일정해졌다.
확인을 위해 첫번째 intent_train과 label_train을 뽑아 확인해보자.
print(intent_train[0])
print(label_train[0])
빈 공간에 0이 채워진 모습이다.
아까 우리는 앞에 몇개의 샘플을 출력해서 레이블이 1부터 6까지 순서대로 나열되어있는 모습을 확인할 수 있었다. 이렇게 되면 훈련 데이터에서 데이터들을 분리했을 때 데이터가 골고루 들어가지 않을 수 있으므로 섞어줘야 한다.
Shuffle Data
우선 뒤죽박죽 정수를 가진 intent_train크기의 시퀀스를 만들어준다.
indices = np.arange(intent_train.shape[0])
np.random.shuffle(indices)
print(indices)
이 정수의 순서를 인덱스의 순서로 하도록 훈련 데이터를 섞어준다.
intent_train = intent_train[indices]
label_train = label_train[indices]섞어준 다음에 label_train의 데이터 앞에 20개를 뽑아보았다.

잘 섞인 모습이다.
검증 데이터는 훈련 데이터의 10%만을 사용한다.
검증 데이터는 몇 개여야 하는지 확인해보자.
n_of_val = int(0.1 * intent_train.shape[0])
print(n_of_val)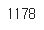
1178의 검증데이터를 사용하게 될 것이다. 훈련 데이터에서 1178개의 데이터를 분리해주자.
X_train = intent_train[:-n_of_val]
y_train = label_train[:-n_of_val]
X_val = intent_train[-n_of_val:]
y_val = label_train[-n_of_val:]
X_test = intent_test
y_test = label_testprint('훈련 데이터의 크기(shape):', X_train.shape)
print('검증 데이터의 크기(shape):', X_val.shape)
print('훈련 데이터 레이블의 개수(shape):', y_train.shape)
print('검증 데이터 레이블의 개수(shape):', y_val.shape)
print('테스트 데이터의 개수 :', len(X_test))
print('테스트 데이터 레이블의 개수 :', len(y_test))
각각의 개수와 크기는 이렇게 된다.
Embedding
여기서는 스탠포드 대학교에서 제공하는 GloVe 임베딩을 사용한다.
필요한 패키지를 다운받아주자.
!wget http://nlp.stanford.edu/data/glove.6B.zip
!unzip glove*.zip임베딩 벡터를 로드한다.
embedding_dict = dict()
f = open(os.path.join('glove.6B.100d.txt'), encoding='utf-8')
for line in f:
word_vector = line.split()
word = word_vector[0]
word_vector_arr = np.asarray(word_vector[1:], dtype='float32') # 100개의 값을 가지는 array로 변환
embedding_dict[word] = word_vector_arr
f.close()
print('%s개의 Embedding vector가 있습니다.' % len(embedding_dict))
임의로 훈련된 임베딩에서 'playlist'의 벡터값과 벡터의 차원을 출력해보자.
print(embedding_dict['playlist'])
print(len(embedding_dict['playlist']))
'playlist'의 벡터의 차원은 100차원이다.
이번 예시에서 사용될 임베딩 테이블을 구축해보자.
우리가 처음에 embedding_dim을 100으로 설정했기 때문에 임베딩 테이블의 열도 100이어야 한다. vocab_size를 행의 크기로, 열의 크기는 100인 테이블을 만들어준다.
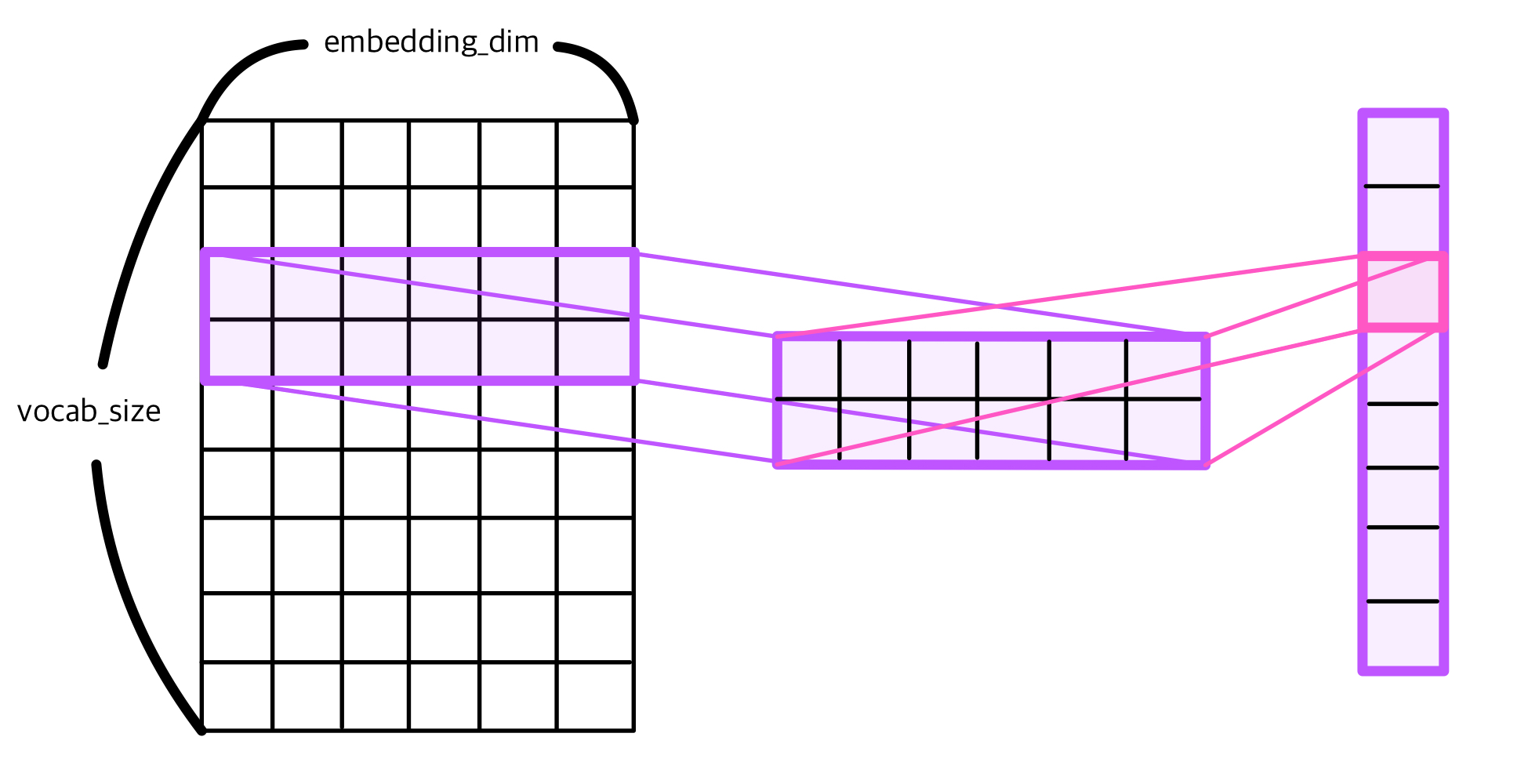
embedding_dim = 100
embedding_matrix = np.zeros((vocab_size, embedding_dim))크기를 확인해보자.
np.shape(embedding_matrix)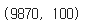
아까 위에서 구했던 단어집합의 크기와 임베딩 벡터차원이 잘 나왔다.
우리가 가지고 있는 데이터의 단어들과 맵핑되는 사전 훈련된 워드 임베딩 벡터의 값을 방금 만든 임베딩 테이블에 저장하자.
for word, i in word_index.items():
embedding_vector = embedding_dict.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vectorBuild Model
Packages
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Embedding, Dropout, Conv1D, GlobalMaxPooling1D, Dense, Input, Flatten, Concatenate이전 글에서 설명했던 Multi-Kernel 1D CNN구조를 사용하자.
파라미터 값은 아래와 같이 조금 바꿔야 한다.
filter_sizes = [2,3,5]
num_filters = 512
drop = 0.5모델을 구축하자.
이전과 다르게 임베딩 층 이후에는 dropout을 해주지 않았다.
model_input = Input(shape = (max_len,))
z = Embedding(vocab_size, embedding_dim, weights=[embedding_matrix],
input_length=max_len, trainable=False)(model_input)
conv_blocks = []
for sz in filter_sizes:
conv = Conv1D(filters = num_filters,
kernel_size = sz,
padding = "valid",
activation = "relu",
strides = 1)(z)
conv = GlobalMaxPooling1D()(conv)
conv = Flatten()(conv)
conv_blocks.append(conv)
z = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
z = Dropout(drop)(z)
model_output = Dense(len(label_idx), activation='softmax')(z)
model = Model(model_input, model_output)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])마지막엔 다중 분류 문제이기 때문에 소프트맥스 함수를 사용해주었다.
모델이 완성되었다.
model.summary()를 통해서 자세히 확인해보자.
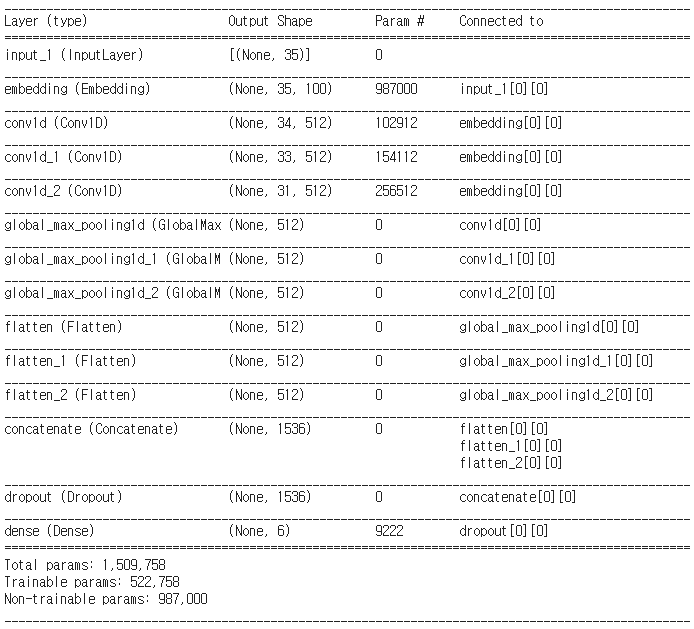
앞에서 분리해놨던 검증 데이터로 성능을 점검하면서 훈련해보자.
history = model.fit(X_train, y_train,
batch_size=64,
epochs=10,
validation_data = (X_val, y_val))
약 99%, 98%의 정확도가 나왔다.
그래프를 그려서 확인해보자.
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['acc'])
plt.plot(epochs, history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='lower right')
plt.show()
epochs = range(1, len(history.history['loss']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='upper right')
plt.show()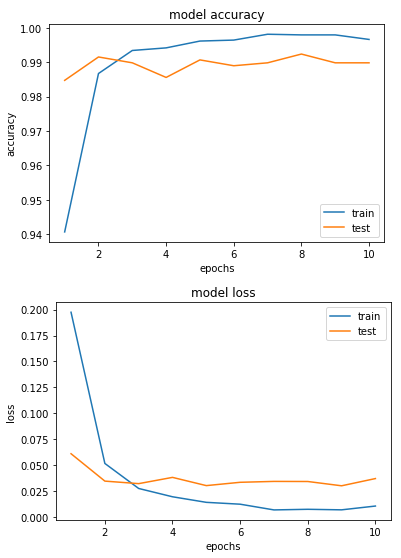
Evaluate
이제 테스트 세트에 넣어서 평가해보자.
위에서 했던 것처럼 테스트 세트에도 똑같이 토큰화를 한 후 패딩을 해 준다.
X_test = tokenizer.texts_to_sequences(X_test)
X_test = pad_sequences(X_test, maxlen=max_len)이후에 모델에 넣고 정수 시퀀스로 변환한다.
y_predicted = model.predict(X_test)
y_predicted = y_predicted.argmax(axis=-1) # 예측된 정수 시퀀스로 변환y_test와 y_predicted모두 정수 시퀀스를 레이블에 해당하는 텍스트 시퀀스로 변환해준다.
y_predicted = idx_encode.inverse_transform(y_predicted)
y_test = idx_encode.inverse_transform(y_test) 정확도를 확인해보자.
print('accuracy: ', sum(y_predicted == y_test) / len(y_test))
print("Precision, Recall and F1-Score:\n\n", classification_report(y_test, y_predicted))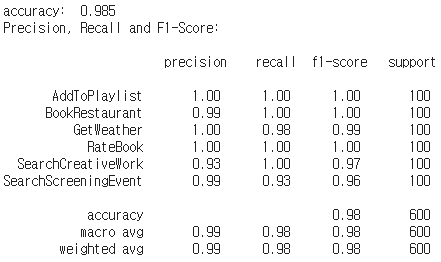
정확도는 98.5%, F1-score에서는 98%의 정확도를 얻었다.
여기서 설명을 마친다.
