캡스톤디자인도 어느덧 마무리 단계....이여야지만!
내가 존재하는 한 절대 계획대로 흘러갈 수 없다,,,,
최종 발표까진 2주밖에 남지 않았지만 하이브리드 추천시스템까지 어느정도 구축해놨기에 이미지도 추가해서 좀 더 완성도 있는 추천시스템을 구축해보려고 한다!
아이디어는 이미지 내에서 비슷한 색상을 사용하면 분위기도 유사하다고 판단하여 이미지 내의 주요 색상을 추출한 후 유사도를 구하기로 했다.
내가 시도한 방식은 2가지 인데 먼저 실패한 방식을 소개하려고 한다.
1. ExtColors
ExtColors 라이브러리를 사용하면 한 이미지에서 가장 많은 rgb값과 그 비율을 뽑아준다.
해당 라이브러리를 사용해서 가장 많은 rgb값을 사용하려고 시도했다.
colors, pixel_count = extcolors.extract_from_image(img)
pixel_output = 0
for c in colors:
pixel_output += c[1]
print(f'{c[0]} : {round((c[1] / pixel_count) * 100, 2)}% ({c[1]})')
print(f'Pixels in output: {pixel_output} of {pixel_count}')위의 코드를 사용하여 간단하게 추출할 수 있고 결과는 다음과 같다.

또한 해당 결과를 색상대로 컬러 파레트를 시각화할 수 있어서 더 좋았다.
!extcolors b140l4Z_.jpg --image image-palette
그리고 아래는 내가 사용한 이미지이다.

눈으로 보기엔 분홍색이 가장 많은 색상을 차지하고 있었는데 결과는 흰색과 검정이 제일 많이 쓰였고 그 다음으로 분홍색이 2.68%라고 나와서 해당 결과를 사용해서 유사도를 구하기엔 적절하지 않아 보였다.
2. K-means clustering으로 구현하기
위의 방법이 실패했기에 픽셀 별로 rgb를 추출한 다음 군집화 하여 주요 색상을 추출해보기로 했다.
✅ 방법
1. 픽셀 별로 rgb를 추출한다.
2. rgb 별로 clustering을 한다.
3. 최적의 군집에서 최대 군집의 중심 좌표를 추출하면
4. 주요 색상 !
1. 이미지 불러오기
folder_paths = ['/content/drive/MyDrive/캡스톤 디자인/크롤링/이미지/image1~327/',
'/content/drive/MyDrive/캡스톤 디자인/크롤링/이미지/image328~655/',
'/content/drive/MyDrive/캡스톤 디자인/크롤링/이미지/image656~/']
img_path = []
for fp in folder_paths :
images = [os.path.join(fp,f) for f in os.listdir(fp) if f.lower().endswith('.jpg')]
img_path.extend(images)크롤링을 나눠서 했기 때문에 폴더가 여러개라 경로들을 모아 한 리스트에 저장한다.
2. 이미지 픽셀 별로 rgb 추출
def extract_rgb_values(image_path):
# 이미지 불러오기
image = cv2.imread(image_path)
# 이미지의 높이와 너비 가져오기
height, width, _ = image.shape
# 픽셀별 RGB 값을 추출하여 리스트로 반환
rgb_values = []
for y in range(height):
for x in range(width):
pixel_value = image[y, x]
rgb_values.append(pixel_value)
return rgb_values먼저, 이미지 픽셀 별로 rgb를 추출한 다음 rgb_values 리스트에 넣어준다.
3. 최적의 군집 수 확인 및 최대 군집의 중심 좌표 추출
def find_optimal_clusters(image_path, max_clusters=10):
# 이미지에서 RGB 값을 추출
rgb_values = extract_rgb_values(image_path)
# NumPy 배열로 변환
rgb_array = np.array(rgb_values)
# 클러스터 수에 따른 K-Means inertia 계산
inertias = []
for i in range(1, max_clusters + 1):
kmeans = KMeans(n_clusters=i, random_state=42)
kmeans.fit(rgb_array)
inertias.append(kmeans.inertia_)
# Elbow Method를 통해 최적의 클러스터 수 찾기
optimal_clusters = inertias.index(min(inertias)) + 1
# 최적의 클러스터 수로 K-Means 클러스터링 수행
kmeans = KMeans(n_clusters=optimal_clusters, random_state=42)
kmeans.fit(rgb_array)
# 각 클러스터의 레이블 가져오기
labels = kmeans.labels_
# 가장 많은 픽셀을 가지고 있는 클러스터의 인덱스 찾기
dominant_cluster_index = np.argmax(np.bincount(labels))
# 가장 많은 픽셀을 가지고 있는 클러스터의 중심 좌표 가져오기
dominant_color_center = kmeans.cluster_centers_[dominant_cluster_index]
return dominant_color_center 위에서 추출한 RGB값을 NumPy 배열로 변환한 다음 K-Means 알고리즘에 적용한다. 그 후 클러스터 수에 따른 K-Means inertia를 계산하여 리스트에 저장한다. inertia는 클러스터 내의 데이터가 얼마나 가깝게 모여있는지를 나타낸다.
inertia 값이 급격하게 감소하는 지점을 찾아서 최적의 클러스터 수를 결정하는 방법인 Elbow Method를 통해 최적의 클러스터 수를 찾아 K-Means 클러스티링을 수행한다. 그리고 가장 많은 픽셀을 가진 클러스터의 중심 좌표를 반환한다.
3. 중심 좌표 확인
import warnings
warnings.filterwarnings("ignore")
colors = []
for i in tqdm(img_path) :
dominant_color = find_optimal_clusters(i)
colors.append(dominant_color)각 이미지에서 추출한 RGB 값 중에서 최적의 군집 수를 찾고 해당 군집 수로 K-Means 클러스터링을 수행한 뒤에 최대 군집의 중심 좌표를 반환한다.

물론 시간은 오래 걸린다...
4. 결과
print(f"Dominant Color (R, G, B) of the Largest Cluster:")
print(f"R: {int(dominant_color[0])}, G: {int(dominant_color[1])}, B: {int(dominant_color[2])}")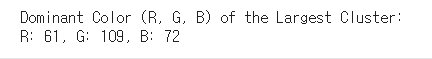
이미지 한 개의 결과를 먼저 추출해봤다.
해당 이미지는 아래와 같은데

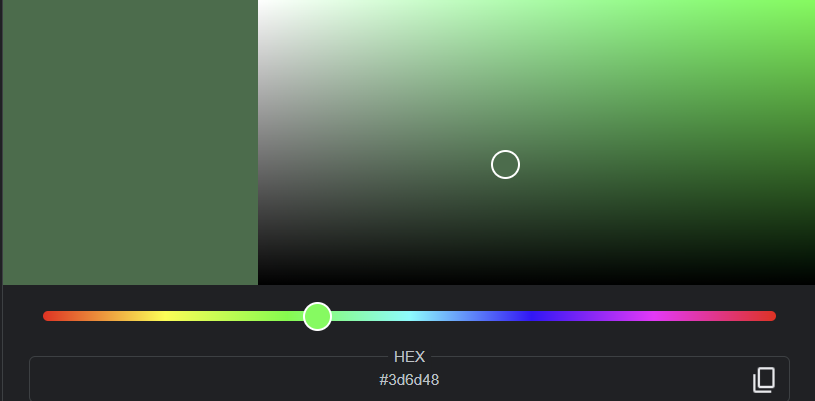
주요 좌표의 RGB색상이다.
