Abstract
Text-based diffusion 모델은 주어진 text prompt를 따라 매우 다양한 이미지를 생성할 수 있었다.
- text based 이미지 합성 → 이미지 editing으로 확장 가능
- editing : 원본 이미지를 보존
- 그러나 text based model에서는 text prompt에 약간의 수정을 해도 결과가 완전히 달라짐.
- 기존의 SOTA image editing diffusion : mask를 활용
본 논문에서는 prompt만을 사용하는 prompt-to-prompt editing 프레임워크를 제시한다.
- 이미지의 spatial layout과 prompt의 각 단어의 relation을 컨트롤하는 것
- 핵심은 cross-attention layer
- original image의 attention maps를 diffusion process에 주입하여 edited image의 attention maps을 컨트롤
Introduction
최근 LLI(Large-scale Language Image) 모델이 높은 image generation 성능으로 주목을 받고 있다. 그러나 주어진 이미지의 specific semantic region에 대한 컨트롤에 약한 모습을 보인다.
이를 해결하기 위해 LLI 기반 방법들은 사용자에게 이미지의 일부를 masking해 채워넣을 대상을 지정하고 masking된 영역만 변경하면서 원본 이미지의 배경과 일치하도록 한다.
- 빠르고 직관적인 text based editing을 방해
- 이미지 내의 중요한 구조적 정보를 제거해 특정 object의 texture를 수정하는 등 inpainting scope를 벗어나는 editing 능력 부족
본 논문에서는 사전 훈련된 text condition diffusion model을 사용해 prompt-to-prompt 조작을 통해 이미지를 sementic하게 편집하는 직관적이고 강력한 text editing 방법을 제안한다.
주요 아이디어는 cross attention map을 주입하면서 이미지를 편집할 수 있다는 것이다. 이를 통해 어떤 픽셀이 어떤 diffusion step에서 prompt의 어떤 token에 attention하는지 제어한다.

본 논문에서는 cross-attention maps를 심플하고 semantic한 interface로 컨트롤하기 위한 여러 methods를 제시한다.
- prompt에서 하나의 토큰 값을 변경해 cross attention map을 고정시키면서 장면 구성을 보존한다.(ex 개 → 고양이)
- prompt에 새로운 단어를 추가하여 새로운 attention flow를 허용하면서도, 이전의 token에 대한 attention은 freezing한다.
- 생성된 이미지에서 단어에 대한 semantic effect를 확대하거나 약하게 한다
Method
✅ 목표는 편집된 prompt 에 대해서만 guide되는 입력 이미지를 편집하여 편집된 이미지 를 만드는 것
- : text prompt 와 random seed 를 사용해 text-guided diffusion 모델로 만들어낸 이미지
- “my new bicycle”이라는 prompt로 만들어진 이미지가 있다
- 기존 이미지의 기존 구조를 유지한 상태로 자전거의 색상을 수정하거나, 자전거를 스쿠터로 바꾸고 싶을 것이다.
사용자를 위한 직관적인 인터페이스는 text 프롬프트를 수정하는 것이다.

본 논문에서는 사용자가 정의한 mask에 의존하고 싶지 않았고, 가장 단순한 방식으로 고정된 seed를 사용하고 수정된 prompt로 생성하는 방식을 수행해 보았는데, 위의 그림의 아랫줄과 같이 실패했다.

해당 논문의 주요한 관찰은 생성된 이미지의 구조와 모습이 random seed뿐만 아니라 diffusion process를 통한 픽셀 간 text embedding간의 상호 작용에도 의존한다는 것이다. cross attention layer에서 발생하는 pixel-to-text 상호 작용을 수정하므로써 prompt-to-prompt image editing을 제공할 수 있다.
보다 정확하게는 이미지 의 cross-attention map을 diffusion process에 주입하여 기존의 구성과 구조를 보존할 수 있다.
Cross-attention in text-conditioned Diffusion Models
- Imagen을 text guided 합성 모델의 backbone으로 사용
- 이미지의 composition과 geometry가 64x64 해상도에서 결정(diffusion process에서 결정)
➡️ text-to-image diffusion model에만 적용하고 SR model는 그대로 사용
각 diffusion step 는 noise image 와 text embedding 을 U자형 network를 사용해 예측하는 과정으로 구성된다. 마지막 단계에서 이 과정은 생성된 이미지 를 얻는다.
가장 중요한 것은 두 가지 modality 간의 상호 작용이 noise 예측 중에 발생한다는 것이다. 이 때 각 textual token에 대한 spatial attention maps를 만들어내는 cross-attention layer가 활용된다.
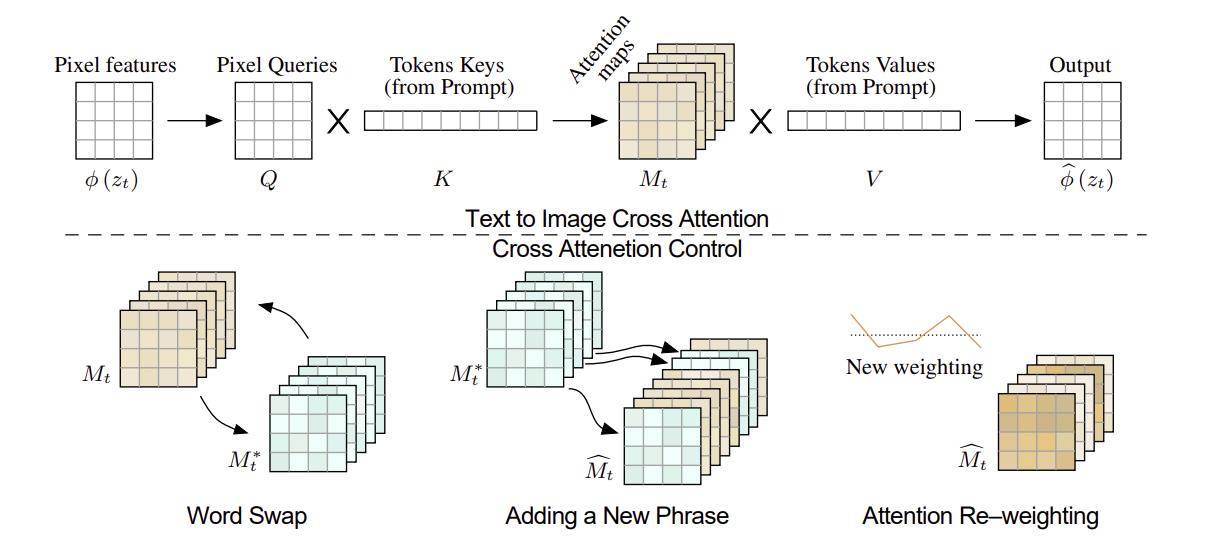
위의 그림에서 설명된 것과 같이 noise image 의 깊은 spatial feature은 query matrix 에 주입되고, textual embedding은 key matrix인 와 value matrix 에 주입된다.
따라서 attention maps는
- cell : pixel 와 연관된 token 값에 대한 weight
- 는 key와 query의 latent projection dimension
- cross-attention output은 로 정의
- spatial feature 를 업데이트 하는데 사용
직관적으로 cross attention output인 는 에 의해 weight된 의 weighted average로 볼 수 있다. 실제로 표현력을 높이기 위해, multi-head attention이 병렬적으로 사용되었다.
Controlling the Cross-attention
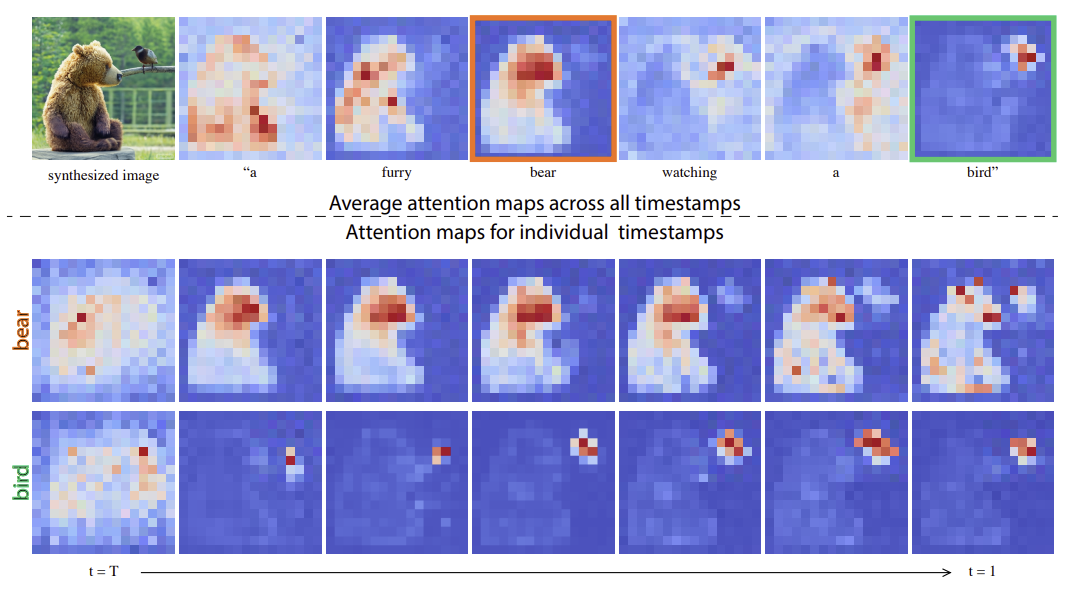
다시 강조하고자 하는 주요 관찰은 생성된 이미지의 spatial layout과 geometry가 cross attention map에 의존한다는 것이다. pixel과 text간의 상호작용은 위의 그림에 나와있고 pixel들은 그들을 표현하는 단어에 더 강하게 attracted 되어있다. 예를 들어, ‘bear’ 같은 경우 pixel들이 더 곰과 연결되어 있다.
주목할만한 것은
1. averaging이 visaulization 목적으로 수행된다는 것
2. attention map이 각각의 목적에 따라 계속해서 분리되어 있다는 것
3. 시각적 구조가 diffusion process의 초기부터 이미 결정되어 있다는 것
- attention이 모든 composition을 반영하기 때문에,
- original prompt 로부터 얻어진 attention map 을 prompt 로 편집하는 second generation 과정에 주입 가능
➡️ attention이 모든 composition을 반영하기 때문
- 이는 편집된 이미지 의 합성과정이 로만 편집되는 것이 아니라 input image 의 구조를 유지할 수 있다는 것을 의미
- 이는 다양한 타입의 직관적 편집이 가능하도록 하는 attention-based manipulation의 한 가지 형태일 뿐
따라서 본 논문에서는 더 general한 framework를 제안한다.
- : noisy image 과 attention map 를 output으로 내는 single step 의 diffusion process 연산이라고 하자.
- 보충 prompt의 value 를 유지하면서도 을 으로 overide하는 diffsuion step으로 나타냈다.
- 수정 prompt 에 대한 attention map을 로 나타냈다.
- 마지막으로 general edit 함을 로 나타냈다.
✅ prompt 변화에 따른 Attention Map Edit 방식
- Word-swap
- Additing a new phrase
- Attention Re-weighting
본 논문의 General Algorithm은 기존 prompt와 수정 prompt를 동시에 사용한다. 또한 inteanl randomness를 고정했는데, 같은 프롬프트라도 다른 seed는 완전 다른 output을 내기 때문이다. editing 알고리즘은 아래와 같다.

(6-7) : 원본 prompt 와 타겟 prompt 의 diffusion process에서 attention map 추출(random seed 고정)
8 : attention map 에 대해 cross attention control()을 하여 attention map 를 생성
9 : 타겟 prompt 와 수정한 attention map 로 이미지 생성
또한 diffusion step을 과 를 동시에(병렬로) 적용할 수 있으며 원래 diffusion model의 inference에 비해 하나의 step만 추가된다.
Word Swap
원본 prompt 와 새로운 prompt 내 특정 단어만 바뀐 경우이다.
-
예를 들어, =”a big red bicycle”를 =”a big red car”로 바꾼다.
-
source image에 attention map을 수정된 prompt로 생성할 때 주입
-
그러나 attention injection은 geometry를 과도하게 제한
➡️ soft attention constrain 제안
-
soft attention constrain : 특정 time step 이후부터 수정한 attention map을 사용
- 는 timestamp parameter
- 언제까지 injection이 적용될 것인지 결정한다.
- 이미지 내의 구성이 초기 단계에서 결정된다는 점을 주목
- 따라서, injection step 수를 제한함에 따라, geometry freedom을 새로운 prompt에 부여할 수 있다.
Adding a New Phrase
원본 prompt 에 새로운 문장이 추가된 prompt 인 경우
- 예를 들어, =”a castle next to a river”를 =’children drawing of a castle next to a river”로 바꾼다.
- 공통적인 detail를 유지하기 위해 attention injection은 두 prompt에서 공통 token에만 적용
- 겹치는 문장일 경우 원본 이미지 를 사용하고 아닐 경우 수정한 attention map 사용
- : alignment function. 두 prompt에서 겹치는 부분을 찾아 매칭되는 index 또는 None 반환
는 pixel value에 는 text token에 대응되고, injection step을 조정할 수 있음을 기억하자. 이것은 stylization ,object의 특성 부각, global manipulation 등을 가능하게 한다.
Attention Re–weighting.
prompt 내 특정 단어의 영향력을 조절
- 특정 단어 토큰 에 대해 가중치 조절
- parameter 를 통해 해당 단어의 token 의 attention map을 scale하여 효과 조절
- 나머지 attention map은 바뀌지 않는다
Applications
Text-Only Localized Editing
다음은 attention injection을 통해 내용을 수정한 결과이다.
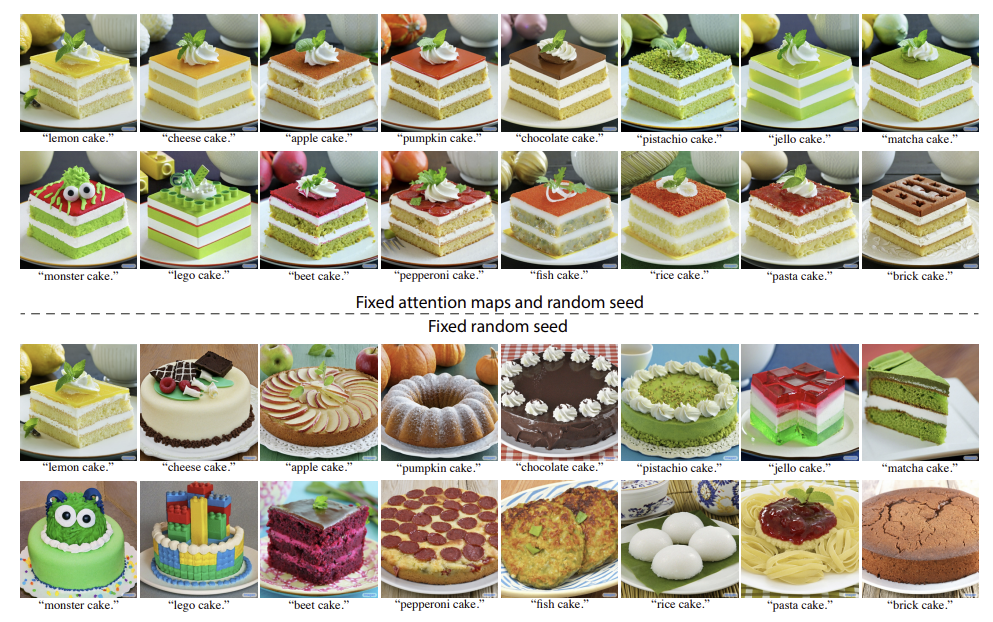
“lemon cake” prompt를 사용해 이미지를 생성하는 예시이다.
- 해당 논문의 방법을 사용
- “lemon”을 “pumpkin”으로 대체할 때 spatial layout, geometry, semantics를 보존
- 배경이 잘 보존되어 왼쪽 위의 lemon이 pumpkin으로 변하는 걸 볼 수 있다.
반면 동일한 random seed를 사용할 때도 "pumpkin cake" prompt를 합성 모델에 단순히 넣으면 완전히 다른 geometry가 나온다.(3번째 행) 해당 논문의 방법은 “pasta cake”과 같이 어려운 prompt에 대해서도 잘 생성해낸다. (생성된 케이크는 파스타 위에 토마토 소스가 올라간 것이다)
다음은 전체 prompt의 attention을 주입하지 않고 특정 단어 butterfly의 attention만을 주입한 예시이다.

이를 통해 원래의 나비를 보존하면서 내용의 나머지 부분을 변경할 수 있다.
해당 논문의 방법은 “bicycle”를 “car”로 변경하는 구조 editing도 할 수 있다.

cross attention injection X
- single word를 변경하면 완전히 다른 결과가 나타났다.
cross attention injection O
- 왼쪽에서 오른쪽으로, cross attention injection을 적용한 diffusion step 수를 증가시키면서 생성된 이미지이다.
- cross attention injection을 적용한 diffusion step 원래 이미지에 대한 fidelity
- 그러나 꼭 모든 diffusion step에 injection을 적용하면서 최적의 결과를 얻을 필요 x
injection step 수를 변경하면서 사용자에게 더 좋은 원본 이미지에 대한 제어를 제공할 수 있다.
한 개의 단어를 다른 단어로 교체하는 것 대신 사용자는 생성된 이미지에 새로운 specification를 추가하길 원할 수 있다. 이 경우 원래 prompt의 attentio map을 유지하면서 모델이 새롭게 추가된 단어에 대응하도록 한다.

예를 들어, ‘crushed”를 ‘car’에 추구하여 원래 이미지 위에 추가적인 detail를 생성하며 배경은 그대로 유지한다.
Global editing
이미지 구성을 유지하는 것은 local editing뿐만 아니라 global editing에도 중요하다. 이 설정에서 editing은 이미지의 모든 부분에 영향을 미쳐야 하지만 여전히 object의 위치 및 식별과 같은 원래의 구성을 유지해야한다. 위의 그림에서 보듯이 ‘snow’를 추가하거나 조명을 바꾸면서 이미지 내용을 보존한다.

스케치를 사실적인 이미지로 변환하거나 예술적 스타일을 유발하는 예시이다.
Fader Control using Attention Re-weighting
prompt를 편집하여 이미지를 editing하는 것은 매우 효과적이지만 여전히 생성된 이미지에 대한 완전한 control이 아니였다. prompt “snowy mountain”에서 사용자는 눈의 양을 조절하고 싶을 수 있다. 그러나 원하는 눈의 양을 text로 설명하는 것은 매우 어려울 수 있기에 특정 단어에 의해 유발된 효과의 크기를 제어하는 fader control를 제안한다.
Real Image Editing

real image를 editing하려면 입력 이미지가 diffusion process에 입력되면 생성되는 초기 noise vector를 찾아야 한다. 이 과정은 GAN의 최근 연구에서 주목을 받았으나 text guided diffusion model에 대해서는 연구가 완전히 이뤄지지 않았다.
다음은 diffusion model에 대한 일반적인 inversion 기술을 기반으로 실제 이미지에 대한 editing 결과를 보여준다.

먼저 상당히 단순한 접근 방식은 입력 이미지에 gaussian noise를 추가한 다음 미리 정의된 수의 diffusion step을 수행하는 것이다. 이 방법은 왜곡이 있기에 DDIM 대신 DDPm 모델을 기반으로 한 reverse 접근 방식을 사용한다.
즉, 대신 이고 이 때, 는 real image이다.
이 inversion process는 위의 그림처럼 만족스러운 결과들을 생성한다.

그러나 위의 그림처럼 real image와 많이 다른 경우에는 reverse가 정확하지 않을 수 있다. 이는 distortion-editability tradeoff 때문으로 classifier-free guidance parameter(즉, prompt 영향 감소)를 줄이면 reconstructed가 향상되지만 중요한 control를 수행하는 능력이 제한된다.
이러한 제한을 완화하기 위해 mask를 사용해 원본 이미지의 editing되지 않은 영역을 복원하는 방법을 제안한다. 이 mask는 사용자의 guidance없이 attention map에서 바로 추출된다.

위의 그림에서처럼 이 접근 방식은 단순한 DDPM inversion 방식(노이즈 추가 후 노이즈 제거)를 사용해도 잘 생성된다. 고양이의 identity가 다양한 editing에서 잘 유지되는 반면 mask는 prompt자체에서만 생성된다.
5. Conclusion
해당 연구에서는 text-to-image diffusion 모델의 cross-attention layers이 강력한 능력을 가지는걸 발견했다. 이러한 고차원 layer가 spatial maps에 대해 해석가능한 representation을 제공하며, prompt의 단어와 합성된 이미지의 spatial layout을 관계짓는데 중요한 역할을 수행한다.
그러나 여전히 몇 가지 한계점이 존재한다.
- 현재 inversion process는 일부 test image에서 대해 눈에 보이는 왜곡을 만들어 낸다.
- 현재의 attention map은 low resolution를 가지고 있으며, cross attention이 네트워크 bottleneck에 위치하고 있기 때문에 정밀한 editing만 가능하게 한다. 이를 완화시키기 위해서 cross-attention을 highe resolution layer에서도 적용해야한다.
- 본 논문의 방법은 기존 object를 이미지 내에서 물체를 움직일 수 없다.
