ABSTRACT
본 연구에서는 작은 규모의 뇌파(EEG) 데이터셋을 사용하여 뇌 활동에서 이미지를 합성하기 위한 프레임워크를 제안했다. 제안된 프레임워크에서 contrastive learning 방법을 사용하여 EEG signal에서 feature를 추출하고 conditional GAN을 사용하여 추출된 feature에서 이미지를 합성한다. 소수의 이미지를 사용하여 GAN을 훈련시키기 위해 손실 함수를 수정하며 128 × 128 이미지를 합성할 수 있도록 한다. 더불어, 작은 뇌파 데이터셋을 사용한 제안된 프레임워크의 효과를 다른 SOTA 방법과 비교하기 위해 소거 실험 및 실험을 실시한다.
1. INTRODUCTION
연구 기여는 다음과 같다.
- 소규모 EEG 데이터셋을 사용하여 이미지를 합성할 수 있는 프레임워크
- EEG signal에서 특징을 학습하기 위해 semi-hard triplet loss 사용
→ softmax 대비 k-means 정확도가 우수함을 보여줌- 고품질 이미지를 합성하기 위해 GAN을 수정하는데 mode seeking regularization 및 데이터 증강 사용
→ conditional GAN 사용해 고품질 이미지 합성하는데 도움
3. PROPOSED METHOD
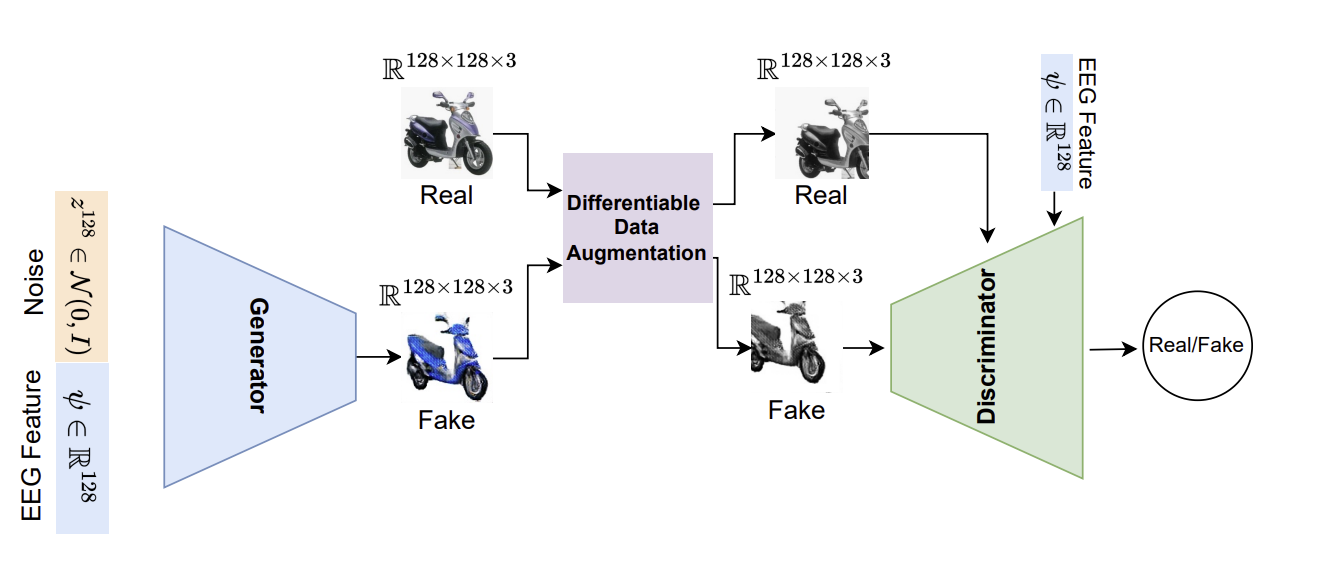
본 연구에선 뇌 활동 EEG signal을 시각화하기 위해 위의 프레임워크를 제안했다.
총 두 단계로 구성되어있다.
1. contrastive learning을 사용해 EEG에서 유용한 feature 추출
2. 추출된 EEG feature를 이미지로 변환하기 위해 conditional dataefficient GAN
✨ 해당 연구에서의 좋은 feature란?
이미지에 대한 유용한 정보로 GAN이 해당 이미지를 재구성하는데 도움이 된다.
Feature Extraction
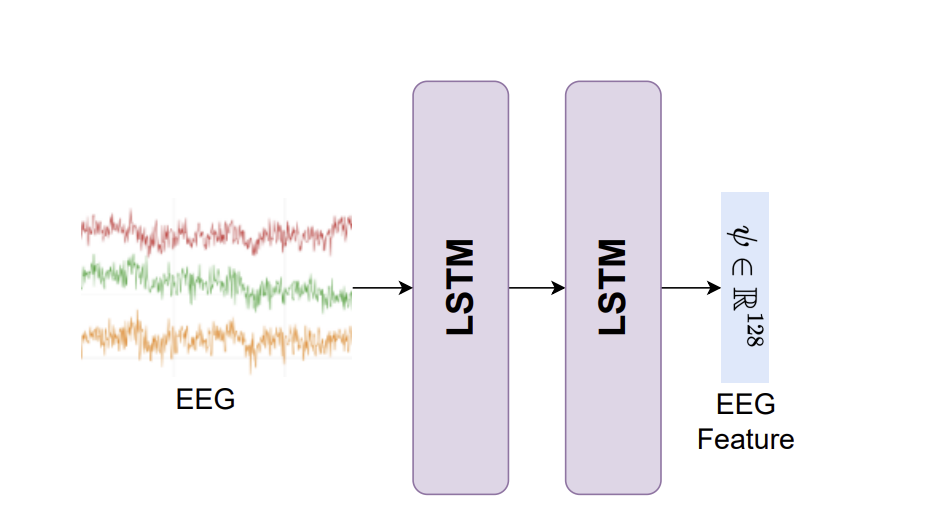
Contrastvie learning 기반 방식이 downstream task(object detection, classification, saliency map from EEG signals)에 대한 일반화된 feature 학습에서 지도 학습 설정을 능가한다는 걸 보여줬다.
→ EEG feature 학습을 위해 제안된 프레임워크에서 Triplet loss 기반 contrastive learning 사용
📌 Triplet loss
- 동일한 레이블의 두 데이터 간의 거리를 최소화(positive )
- 다른 레이블을 가진 두 데이터 간의 거리를 최대화(negative )
- margin term : 각 데이터의 표현을 작은 클러스터로 압축 방지
➡️ 동일한 레이블 데이터의 특징 간 거리가 0에 가깝고 다른 레이블 데이터의 경우 margin보다 크도록 보장
- : EEG signal을 feature space로 매핑하는 에 대한 매개변수화된 함수
()- 목적
- 일반적인 triplet은 Anchor, Positive, Negative 세 가지 샘플로 이루어져 있다.
- 같은 클래스의 anchor EEG signal (a)와 positive EEG signal (p) 간의 거리를 최소화
- anchor EEG signal와 다른 클래스의 negative EEG signal (n) 간의 거리를 margin로 최대화
- 비슷한 이미지에 대한 뇌 활동에서 생성된 EEG signal이 학습된 특징 공간에서 서로 가까워져야 한다는 것
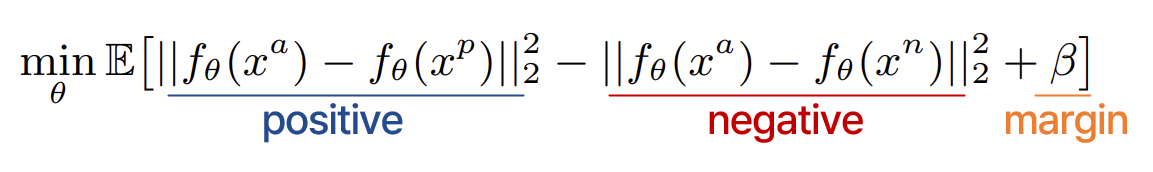
더 나은 특징을 학습하기 위해
1. semi-hard hard triplet 사용
negative sample의 거리가 positive 보다 크지만 margin보다 작은 것을 사용
2. online hard-triplet mining strategy 사용
얼굴 인식 및 유사성 학습에서 사용되는 triplet loss의 효율을 높이기 위한 방법 중 하나이다. 특히 데이터셋이 매우 크거나 높은 차원의 임베딩을 다루는 경우에 유용한데 모든 트리플릿을 고려하는 것이 아니라, loss를 계산할 때 가장 어려운(tricky) 트리플릿을 선택하여 그만큼만 학습에 사용하는 방식이다.
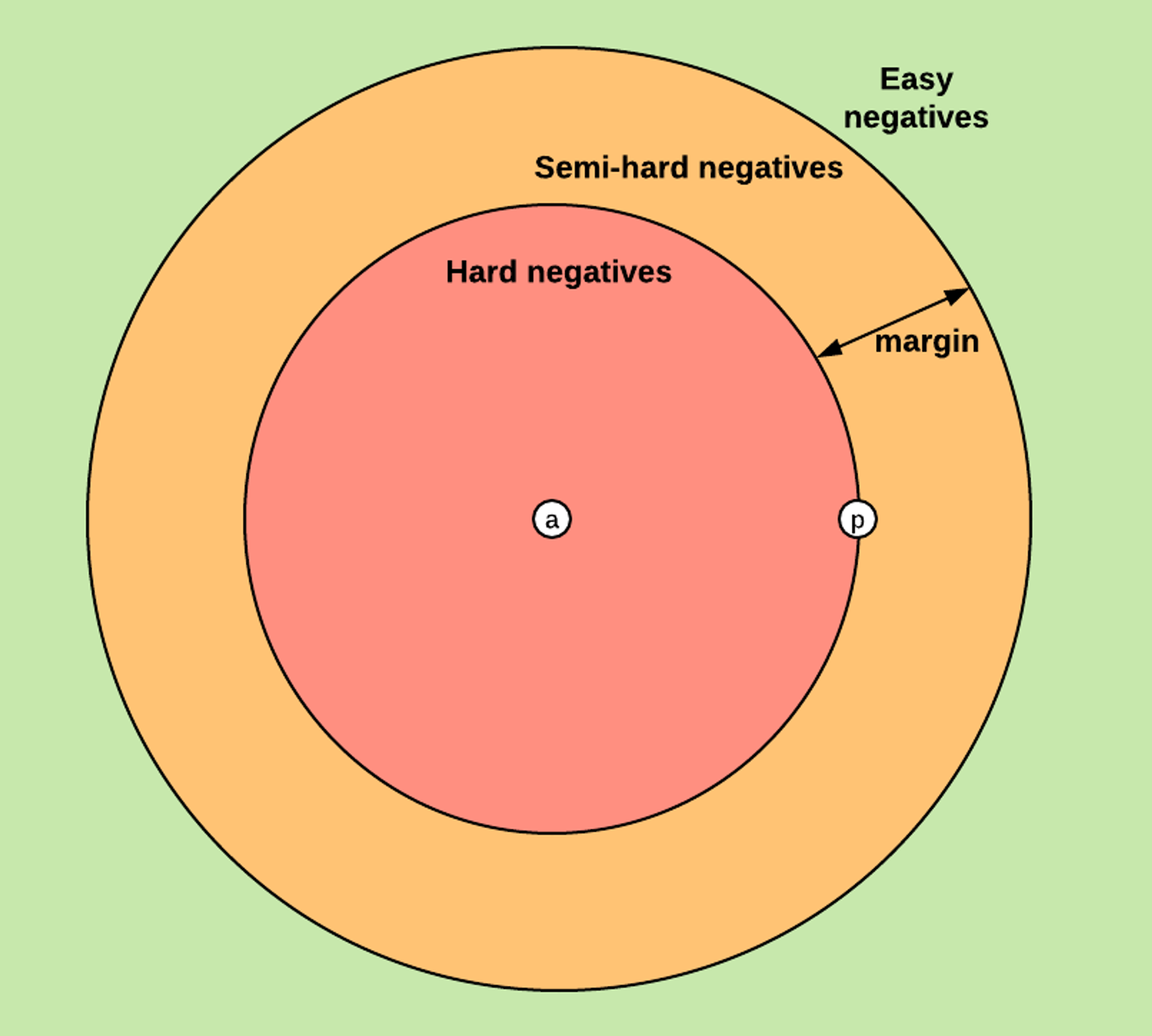
Image Generation
GAN을 사용해 추출된 EEG feature에서 이미지 합성했다.
GAN
- Generator(G)와 Discriminator(D)로 구성
- 목적 : latent distribution()와 실제 데이터 분포()간의 변환을 학습하는 것
- 해당 논문 : latent distribution을 isotropic Gaussian 으로 가정하고 noise vector 을 샘플링
- Discriminator
- 실제 이미지와 합성된 이미지를 구별하는 것을 학습
- 실제 이미지 에 대한 점수를 최대화
- 생성된 이미지 에 대한 점수를 최소화
- Generator
- 최소화
- 최소화하는 유일한 방법은 generator가 사실적인 이미지를 합성할 때
- 최적화 과정
Thoughtviz와 유사하게 해당 논문은 소규모 EEG 데이터셋을 활용하여 EEG 신호로부터 이미지를 생성하는 프레임워크를 개발하는 것을 목표로 한다.
Thoughtviz에서 소규모 데이터셋의 문제를 극복하기 위해 학습 가능한 가중치 가우시안 레이어 사용했는데, 이는 인코딩된 EEG 신호의 평균 () 및 분산 ()을 학습한다.
✨ weighted trainable한 가우시안 레이어 도입이 문제 극복한 이유
Thoughtviz에서 weighted trainable한 가우시안 레이어 도입을 하면서 매핑학습을 더 쉽게 했다. 그 이유는 다양하고 복잡한 distribution을 모델링을 유연하게 할 수 있기 때문이다.
trainable한 가우시안 레이어의 특징 중 크게 2가지를 보면 알 수 있다.
1. 유연한 분포 표현
가우시안 레이어는 평균과 분산을 조절할 수 있는 학습 가능한 매개변수를 가지고 있어 매개변수들을 조절하면서 레이어의 출력 분포를 조절할 수 있다.
2. 분포 맞춤
데이터의 분포에 더 잘 맞출 수 있도록 자동으로 조절되기 때문에 오히려 데이터의 특성에 민감하게 반응하여 학습 데이터의 특이한 패턴이나 구조를 놓치지 않도록 도와준다.
본 연구에서는 Conditional DCGAN 아키텍처를 사용
- DCGAN
 Fully-connected 구조의 대부분을 CNN 구조로 바꾼 Deep Convolution GAN
Fully-connected 구조의 대부분을 CNN 구조로 바꾼 Deep Convolution GAN
random noise 값을 넣어 batchnormalization을 하면서 upsampling과 convolution을 하고 discriminator에서는 convolution하며 기존의 GAN과 같이 마지막엔 flatten하여 출력 output을 1로 설정해 판별한다.
-
안정적인 GAN 학습을 위해 hinge loss을 사용
-
생성자와 판별자 사이에 DiffAug 블록을 추가했는데, 이는 작은 데이터 크기에서의 학습을 돕는다
-
GAN의 모드 다양성을 보장하기 위해 mode seeking regularization를 사용
GAN의 기본 공식이 모드 축소(mode collapse)와 불안정한 훈련 문제를 겪는다는 것을 보였다.
➡️ GAN hinge loss로 알려져 있는 SVM의 separating hyperplane 접근법을 제시
❓ hinge loss
주로 이진 분류(binary classification) 문제에서 사용되는 손실 함수 중 하나로 모델의 예측값과 실제 레이블 간의 차이를 측정하여 모델을 훈련시키는 데 사용됩니다. 핵심 아이디어는 정확한 예측을 할 경우 손실이 0이 되고, 오분류된 경우에는 일정한 마진 이상으로 차이가 나야 손실이 발생한다는 것이다.
GAN을 훈련하기 위한 적은 데이터의 문제를 해결하기 위해 생성자와 판별자 사이에 DiffAug 블록을 추가하는 것이 효과적임을 보여주었다.
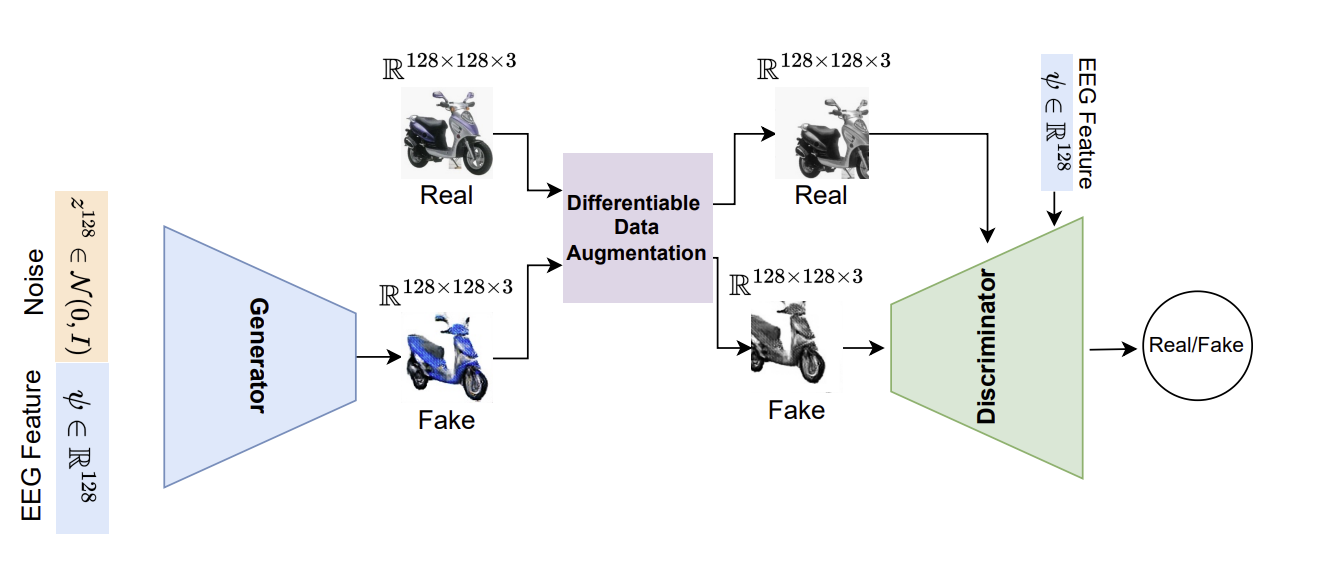
희소한 데이터의 문제는 discriminator가 데이터를 쉽게 암기할 수 있어 generator에 대한 gradient vanishing 문제를 일으킨다.
해당 논문에서의 GAN 네트워크에서 사용한 데이터 증강은 translation과 색상 변형이다.
📌 mode seeking regularization
학습 중에 모델의 출력 분포에 대한 특정 특성을 강조하거나 제어하기 위한 정규화 기법 중 하나이다. 모드란 데이터 분포에서 높은 밀도로 나타나는 분포를 나타낸다.
생성 모델의 목표는 실제 데이터 분포를 잘 따르는 것이지만, 때로는 학습 중에 모델이 너무 많은 모드를 놓치거나 특정 모드에 치우쳐지는 문제를 완화시키고 다양하고 균형잡힌 결과를 얻기 위해 도입되었다.
mode seeking regularization은 주로 생성된 샘플의 분포를 특정한 모드 주변으로 모으도록 유도하여 특정 모드에 집중되지 않게 만든다.
4. EXPERIMENTS AND RESULTS
Datasets
ThoughtViz의 EEG 데이터 사용했다.
Digits, character, object총 3개의 다른 주제에 대한 EEG signal로 구성되어있다. 해당 논문에서는 character과 object만 사용했다. 왜냐하면 제안하는 프레임워크의 효과를 더 잘 보여줄 수 있는 복잡하고 다양한 데이터셋이기 때문이다.
-
Characters dataset
- 10개의 영어 알파벳 클래스와 Chars74K의 일부
-
Objects dataset
- 10가지 다른 객체 클래스와 ImageNet의 일부
참가자들의 뇌 활동 EEG 신호를 수집할 때 그들에게 한 번에 이 문자/객체 중 하나를 생각하도록 요청했다. 각 데이터셋에 대해 23명의 참가자에게 열 가지 클래스를 시각화하도록 요청했다. 따라서 각 데이터셋 당 230개의 EEG 샘플이 있다. 해당 논문에서는 ThoughtViz의 작성자가 제공한 train-test 분할된 EEG 데이터를 사용했다.
EEG2Feature
제안된 프레임워크의 첫 번째 단계는 EEG signal을 이미지 생성을 위한 유용한 특징으로 변환하는 것이다. 이를 위해 두 가지 체계를 설계했다.
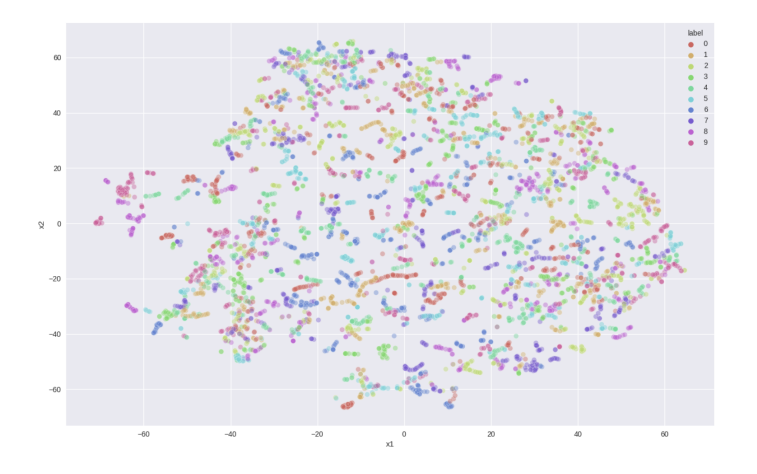
학습된 EEG feature에 대한 metric으로 k-means clustering을 사용하며, 높은 k-means accuracy는 더 나은 학습된 표현을 의미한다.
- EEG feature를 추출하는 classification network 훈련
classifier는 128개의 hidden unit을 가진 LSTM 네트워크로 softmax cross-entropy loss를 사용한다.
테스트셋에 대한 결과
| dataset | accuracy | k-means |
|---|---|---|
| object | 74.3% | 17.8% |
| Character | 75.4% | 16.3% |
아래는 Object 데이터셋의 테스트 데이터 특징 클러스터링을 시각화하기 위한 t-SNE 맵이다.
2. EEG feature를 학습하는 contrastive learning 사용 🌟
LSTM 네트워크(128 개의 hidden unit 사용)를 학습하기 위해 semi-hard triplet loss를 사용했다. Triplet loss의 목표는 positive pair가 서로 가까이 위치하고 negative pair가 멀리 위치하도록 특징 공간을 구조화하는 것이다.
테스트셋에 대한 결과
| dataset | k-means |
|---|---|
| object | 53% |
| Character | 49% |
아래는 Object 데이터셋의 테스트 데이터 특징 클러스터링을 시각화하기 위한 t-SNE 맵이다.
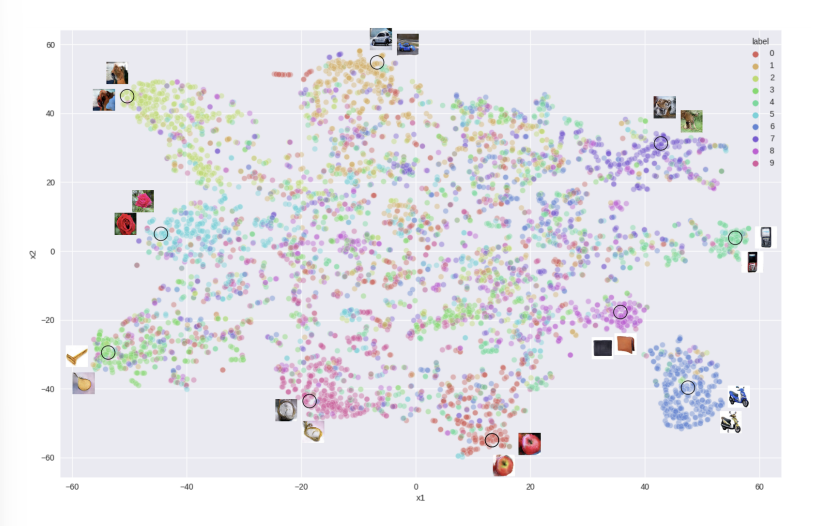
k-means 정확도와 t-SNE 플롯이 두 번째 regime에서 더 나은 것을 볼 수 있다. 따라서 EEG feature 추출기로 contrastive learning 방식을 사용하기로 결정했다.
Feature2Image
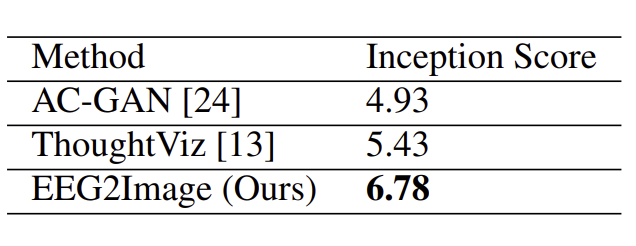
두 번째 단계는 첫 번째 단계에서 추출된 EEG feature를 사용하여 사실적인 이미지를 합성하는 것이다. 이미지를 합성하기 위해 conditional DCGAN을 사용했다. 이미지 품질 비교 메트릭으로 Inception Score (IS)를 사용했다.
아래 표는 해당 논문에서 제안한 GAN 방법이 적은 수의 EEG 데이터로부터 이미지를 합성하는 데 더 나은 성능을 보였음을 보여준다.
아래 표는 Object 데이터셋의 테스트 데이터에 대한 클래스별 Inception Score를 보여준다.

또한 Object 및 Character 데이터셋에 대한 합성 이미지의 질적 분석을 수행했다.

제안된 프레임워크에서 GAN를 훈련시키는 데 각 loss의 중요성을 확인하기 위해 여러 ablation study을 수행했다. 이를 위해 Object 데이터셋 에서 세 가지 다른 regime에 대해 제안된 conditional GAN (cGAN)을 훈련했다.
-
mode seeking regularization 및 DiffAugment 없이 cGAN을 훈련

-
mode seeking regularization term만 추가하고 cGAN을 처음부터 다시 훈련

1보다 개선되었음을 확인
- DiffAugment 블록을 사용하여 cGAN을 훈련

크게 개선되었음.
이 실험을 기반으로 제안된 프레임워크에서는 mode-seeking regularization term과 DiffAugment 블록을 모두 사용한게 성능이 가장 좋았다.
