ABSTRACT
MOT(Multi-Object Tracking)은 비디오에서 객체의 bounding box와 객체를 추정하는 것을 목표로 한다.
- 대부분의 방식 : detection box의 confidence score가 임계값(threshold)보다 높을 때 객체 결정
- 문제점 : 낮은 탐지 점수의 객체는(예 : occluded objects)는 단순히 버려지기 때문에 occlusion이 발생하거나, 다양한 원인들로 인해 trajectory가 분리되어 성능이 하락
➡️ confidence score가 낮은 detection box에 대해서도 고려할 수 있는 association method(=tracking algorithm)를 제시
1. Introduction
Tracking-by-detection은 현재 MOT에서 가장 효과적인 패러다임이다.
기존 SOTA MOT 방법들은 low confidence detection box를 제거하기 위해 detection box로 인한 true positive / false positive 문제를 다뤘다.
그러나 모든 low confidence detection box를 제거하는 것이 올바른 방법일까? 에 대한 저자의 답은 No였다. 왜냐하면 Low confidence detection box도 object의 존재를 나타낼 수 있기 때문이다.
이러한 객체들을 filtering out 하는 것은 MOT에 대해 irreversible error의 원인이 되고 detection 문제와 fragmented trajectory 문제를 일으킬 수 있다.

(a) 모든 detection box와 score를 보여준다.
(b) score가 threshold(예 : 0.5)보다 높은 detection box를 연결하는 원래의 방법으로 얻은 tracklet를 보여준다. 동일한 상자 색상은 동일한 ID를 나타낸다.
(c) Bytetrack을 이용하여 얻은 tracklet를 보여준다. 점선으로 나타낸 박스는 칼만 필터를 이용한 이전 예측 박스의 tracklet를 나타낸다.
- 기존 방법 : (b)에서 Frame t1에서 초록색, 빨간색, 파란색 detection box를 생성하여 ID를 부여했다. 그리고 Frame t2에서 초록색 사람에 의해 occlusion이 발생하면서 visual information들이 소실됨에 따라 빨간색 사람의 confidence score이 0.5보다 낮아지며 해당 박스는 filtering out 된다.
- Bytetrack : (c)와 같이 빨간색 box의 score가 낮더라도 프레임과 tracklet의 유사도가 높으면 filtering out 되지 않고 그대로 유지하여 tracking이 가능하다.
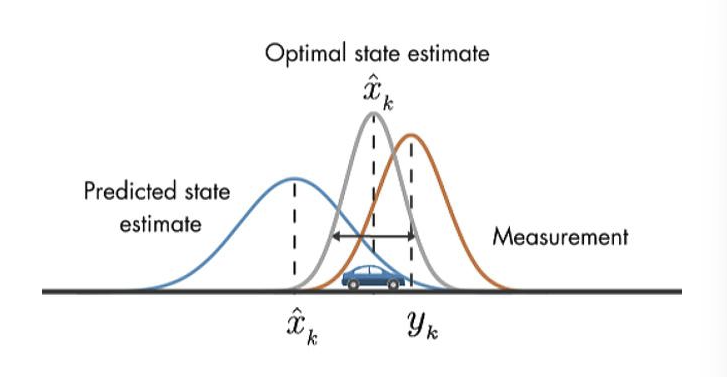
✨ Kalman Filter
이전 프레임에 등장한 개체를 이용하여 다음 프레임의 개체의 위치를 예측하고 측정한다
- Predicted state estimate : 예측한 값(예측모델) / Measurement : 실제 측정 값(측정 모델)
→ 두 모델을 가지고 ‘더 잘 추측’하기 위해 상태를 업데이트한다.
Predicted state estimate(예측한 값) + Measurement(측정값)
⇒ Optimal state estimate(최적 추정 값)- Kalman filter를 object tracking에서 사용하는 이유는?
- Detection 중 발생하는 Noise를 처리하는데 도움이 된다.
- 영상에서 선형성(물체가 순간적으로 사라지거나 나타나지 않음)을 나타내기 때문에 적합하다
- Bounding Box 의 구성요소(위치, 크기정보)로 데이터를 처리한다
➡️ 이 요소들로 object를 추적하고, 실제 측정된 값들과 비교하며 상태를 업데이트한다.
✨ Tracklet
Tracklet은 시간에 따라 움직이는 객체를 추적하기 위해 사용되는 단위로 객체의 ID 값을 유지하는데 구하는 짧은 구간에서의 경로를 의미한다.
즉, 위의 사진에서 물체 바운딩 박스를 순서대로 모아놓으면 각각 노란색, 초록색, 파란색으로만 이루어진 3개의 배열(sequence) 이 만들어지는데 이 배열들을 tracklet이라고 부른다.

2. BYTE
해당 논문에선 간단하고 효과적이며 일반적인 데이터 association 방법인 BYTE를 제안한다.
- 기존 연구 : threshold를 넘는 detection box(high score detection box)만 사용
- bytetrack : 거의 모든 detection box를 사용하고 high score box와 low score box로 나눔
- 먼저, high score detection box를 tracklet에 associate
- occlusion, motion blur, size changing 등이 발생할 때에는 일부 tracklet은 high score detection box와 matching x
- low score detection box와 unmatched tracklet과 association하며 동시에 background를 filtering out

- Input
- : video sequence
- : object detector
- : detection score의 threshold - Output
- : video tracksAlgorithm
- 6 - 13 : threshold τ보다 높은 detection boxes들은 에 저장하고 τ보다 낮은 detection boxes들은 에 저장
- 14 - 16 : 이전 프레임까지의 tracklet과 kalman filter를 이용하여, 현재 프레임에서의 prediction boxes를 생성하여 저장
- 17 - 19 : first association
IoU distance를 기준으로 Hungarian algorithm을 사용하여 tracklet과 를 association을 수행함. 이 때, matching되지 못한 detection boxes들은 에 저장하고 남은 track은 에 저장
- 20 - 25 : second association
과 를 IoU distance를 기준으로 assocation을 수행함. 여기서도 남게 된 track은으로 저장한 후 matching이 되지 않아 남은 즉, detection box는 새로운 tracklet으로 추가
MOT의 SOTA 성능을 향상시키기 위해, 성능이 높은 detector인 YOLOX를 우리의 association 방법인 BYTE와 함께 사용하여 ByteTrack이라는 simple하고 strong한 tracker를 설계한다.
3. Experiment
Datasets.
- MOT17, MOT20 사용
- validation data 없이 train data와 test data로 구성 - Ablation study에선 training을 위해 video 전반부 사용, 검증을 위해 후반부 사용
- HiEve, BDD100K 데이터셋으로 ByteTrack test
- train : validation : test = 1400 : 200 : 400
Implementation details
- 기본 detection score threshold $$tau%% : 0.6
- YOLOX를 backbone으로 사용
- COCO pre-trained 모델의 초기화된 가중치 사용
- input image : 1440x880
- Data Augmentation : Mosaic, Mixup
- 학습 시간 : 약 12시간
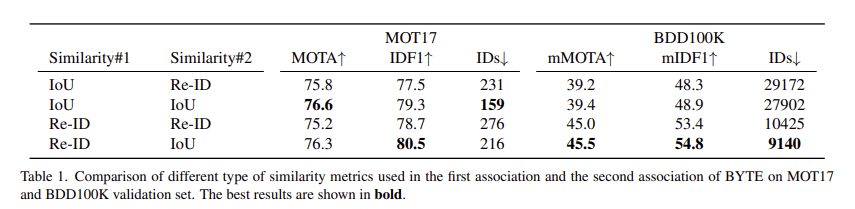
사용된 similarity에 따른 성능 차이
Data Association 방법에 따른 성능 차이
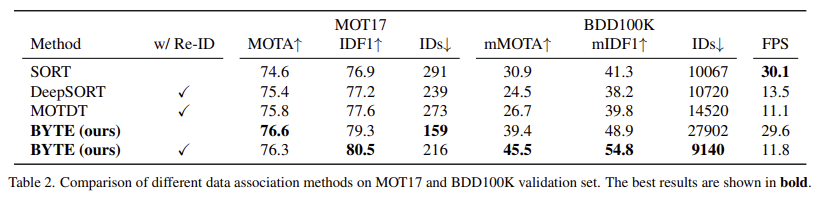
ID switch가 현저하게 줄어들었음을 확인
SORT와 성능 비교
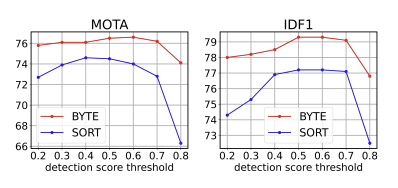
BYTE 알고리즘 적용 시 성능 변화
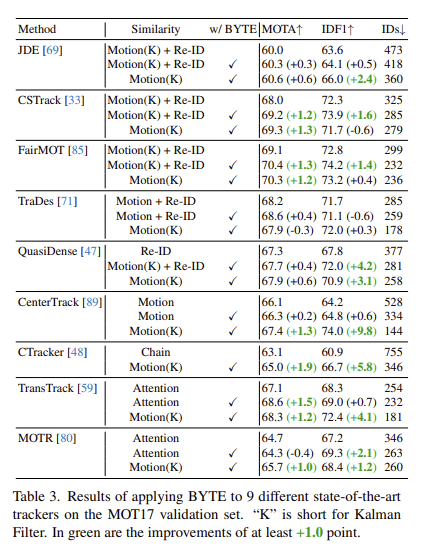
- BYTE 알고리즘을 다른 model에 적용했을 때, 더 좋은 성능을 보였음
- MOTA 기준으로 1-2point 정도
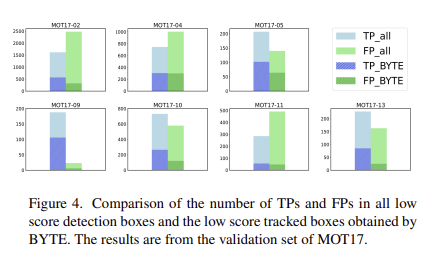
✨ Metrics
- MOTA(Multi Object Tracking Accuracy) : 전체 객체 중 False Positive(FP), False Negatvie(FN), Id switching(IDs)를 종합적으로 반영한 성능지표
- MOTP(Multi Object Tracking Precision) : 매치된 객체들이(두 객체가) 얼마나 떨어져 있는지를 반영한 지표
- HOTA(Higher Order Tracking Acurracy)
- IDF1(Identification F1)
- IDs(ID Switch) : 객체에 부여된 ID가 바뀌어서 판별된 경우
- MT(Mostly Track) : 주로 추적되는 궤적의 수로 추적된 궤적은 생명주기의 최소 80%에 대해 동일한 레이블을 가지고 있음
- ML(Mostly Lost) : MT와 반대로 손실되는 궤적의 수로 손실된 궤적은 생명주기의 최대 20%에 대해 동일한 레이블을 가지고 있음
→ MT는 클수록, ML은 작을수록 좋고 얼마나 궤적을 잘 따르잡느냐를 나타내는 지표
- False Positive(FP) : Object가 있다고 Bounding box를 쳤는데 실제로 아무것도 없는 경우로 맞다고 예측했으나 실제로는 틀린 경우
- False Negative(FN) : Object가 없다고 판별하여 Bounding box를 안 쳤으나 실제로 객체가 있는 경우로 없다고 판별했으나 실제로는 객체가 있는 경우
3. Conclusion
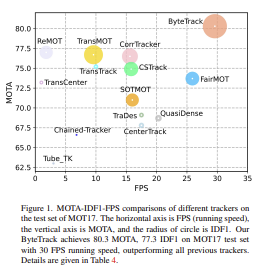
해당 논문에서는 MOT를 위한 간단하지만 효과적인 data association 방법 BYTE를 제시했다. BYTE는 기존 tracker에 쉽게 적용할 수 있으며 지속적인 개선을 할 수 있다. 또한 30 FPS로 MOT17 테스트 셋에서 80.3 MOTA, 77.3 IDF1 및 63.1 HOTA를 달성하며 SOTA 모델을 차지한 강력한 tracker ByteTrack를 제안한다. ByteTrack은 정확한 탐지 성능과 low score detection box를 연결하는데 도움이 되기 때문에 굉장히 roburst하다.
