📖Paper
1.TabTransformer : Tabular Data Modeling Using Contextual Embeddings
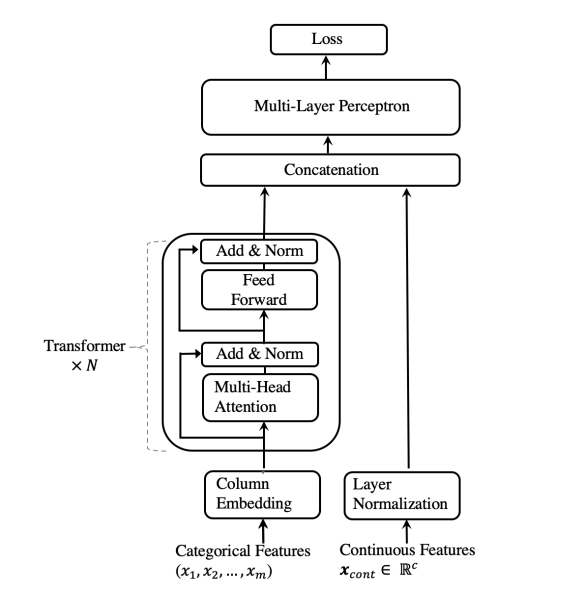
교수님 논문 작업에 참여하게 되어 적용해보려는 논문을 읽었다. Tabular data를 Trasnformer의 Encoder를 사용해서 성능을 높인 모델이다.supervised learning과 semi-supervised learning을 사용하여 tabular da
2.ViT(Vision Transformer) : An Image is Worth 16x16 words : Transformers for Image Recognition at Scale
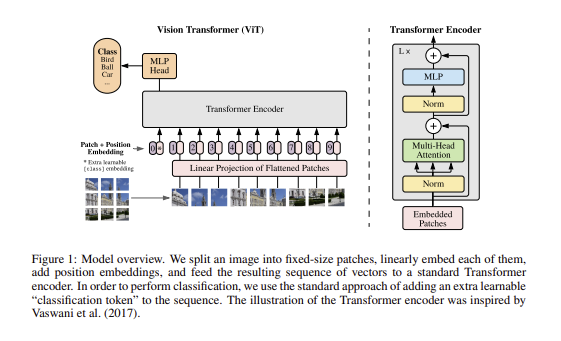
자연어 처리(NLP) 분야에서는 2017년도에 등장한 Transformer 구조가 현재 쓰이고 있다. 이 모델이 소개된 논문의 이름은 ‘Attention is All You Need’이고 제목에서부터 알 수 있듯이 핵심은 Attention 구조이다. NLP분야에서 엄청
3.PIXART-α : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis

해당 논문은 2023년도 10월에 나온 아주 따끈따끈한 논문이다. 성능이 너무 좋아서 궁금해서 읽어봤는데 computing cost를 저렇게 많이 낮추면서 성능까지 좋다니 점점 더 발전해나가는 것 같다,,최근 T2I 생성 모델의 발전이 사실적인 이미지 합성 시대를 열었
4.Prompt-to-Prompt Image Editing with Cross Attention Control

Text-based diffusion 모델은 주어진 text prompt를 따라 매우 다양한 이미지를 생성할 수 있었다. text based 이미지 합성 → 이미지 editing으로 확장 가능editing : 원본 이미지를 보존그러나 text based model에서
5.Bytetrack: Multi-Object Tracking by Associating Every Detection Box

MOT(Multi-Object Tracking)은 비디오에서 객체의 bounding box와 객체를 추정하는 것을 목표로 한다.대부분의 방식 : detection box의 confidence score가 임계값(threshold)보다 높을 때 객체 결정문제점 : 낮은
6.EEG2IMAGE: IMAGE RECONSTRUCTION FROM EEG BRAIN SIGNALS
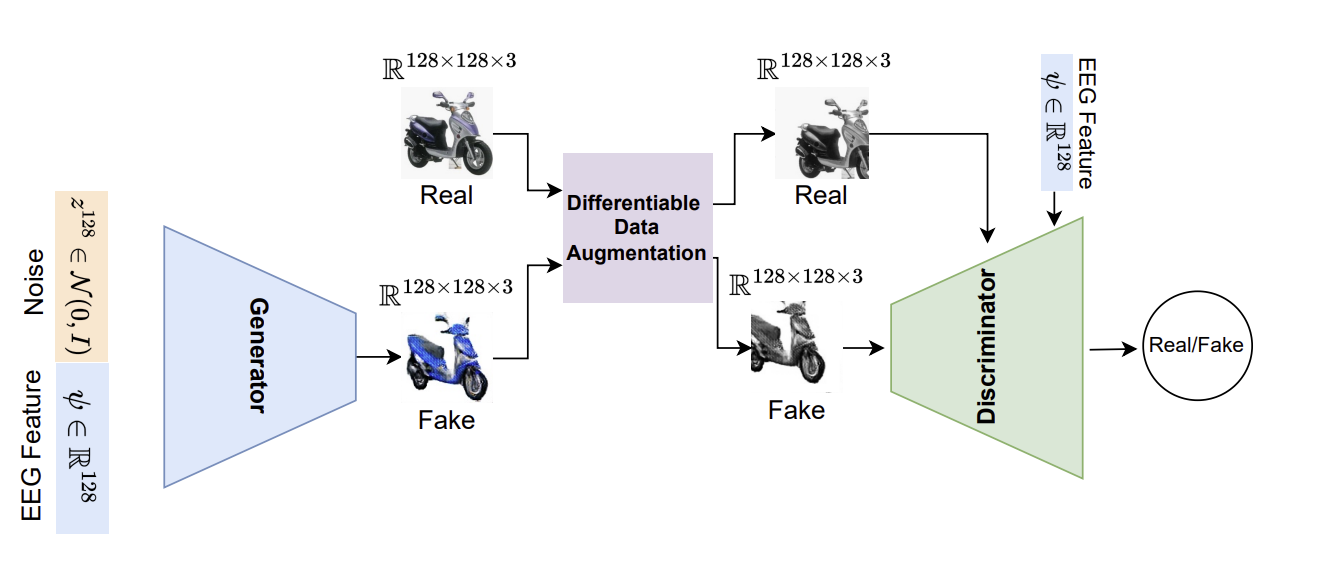
본 연구에서는 작은 규모의 뇌파(EEG) 데이터셋을 사용하여 뇌 활동에서 이미지를 합성하기 위한 프레임워크를 제안했다. 제안된 프레임워크에서 contrastive learning 방법을 사용하여 EEG signal에서 feature를 추출하고 conditional GA