교수님 논문 작업에 참여하게 되어 적용해보려는 논문을 읽었다.
Tabular data를 Trasnformer의 Encoder를 사용해서 성능을 높인 모델이다.
ABSTRACT
supervised learning과 semi-supervised learning을 사용하여 tabular data에 적용할 수 있는 TabTransformer를 제안
- categorical feature의 contextual embedding을 제공하는 architecture 제안
- missing and noisy data features에도 매우 roburst하고 잘 해석 됨.
- pre-training, fine-tuning을 통한 semi-supervised learning 제안
❓ contextual embedding이란?
단어를 저차원 공간에서 표현하는 기법으로 같은 단어더라도 문맥에 따라 그 표현방법이 바뀔 수 있는 개념의 Embedding이다.
1. Introduction
기존에 tabular data를 모델링하는 방법론들이 존재했다.
✅ Gradient boosted decision trees(GBDT)
- tree based ensemble 선호하는 이유 : 높은 예측 정확도 달성, 훈련 속도 빠름, 해석 쉬움
- 그러나 한계점도 존재
1️⃣ streaming data를 사용한 훈련엔 적합 x
2️⃣ tabular data와 함께 multi-modality한 경우 image/text encoder의 end-to-end 학습이 가능 x
3️⃣ tree based tree learner가 예측에 대한 신뢰할 수 있는 확률 추정을 생성하지 못하기 때문에 SOTA 준지도학습에 적합 x
4️⃣ missing and nosiy data feature를 처리하기 위핸 SOTA 딥러닝 방법 적용 x
✅ MLP
-
MLP 선호하는 이유 : gradient descent를 사용하여 학습하기 때문에 image/text encoder의 end-to-end 학습이 가능함
-
한계점도 존재
1️⃣ 학습되는 embedding과 모델 모두 **해석이 불가능** 2️⃣ missing, noisy data에 모두 **roburst하지 않음** 3️⃣ semi-supervised learning을 하기엔 엄청난 **경쟁력 있는 성능 x** 4️⃣ GBDT같은 tree-based 모델의 성능까지 도달 x
두 모델의 성능 gap 차이를 해소하기 위해 여러가지 시도를 했으나 줄이지 못했음.
⇒ 해당 논문에선 MLP의 한계점과 존재하는 deep learning model를 처리하는 TabTransformer제안
해당 논문의 contribution은 다음과 같다.
1️⃣ categorical feature의 contextual embedding을 제공하고 명시하는 구조인 TabTransformer를 제안한다.
2️⃣ resulting contextual embeddings를 조사하고 기존 기술로 달성된 paramteric context free embedding과 달리 해석 가능성을 강조한다.
3️⃣ noisy와 missing data에 대한 TabTransformer의 robustness을 증명한다.
4️⃣ semi-supervied learning의 SOTA를 능가하는 2단계 pretraining 후 fine tuning을 한다.2. TabTransformer
TabTransformer Architecture는 다음과 같이 구성
- column embedding layer
- N개 Transformer layer
- multi head self attention
- position wise feed forward layer
- multi layer perceptron
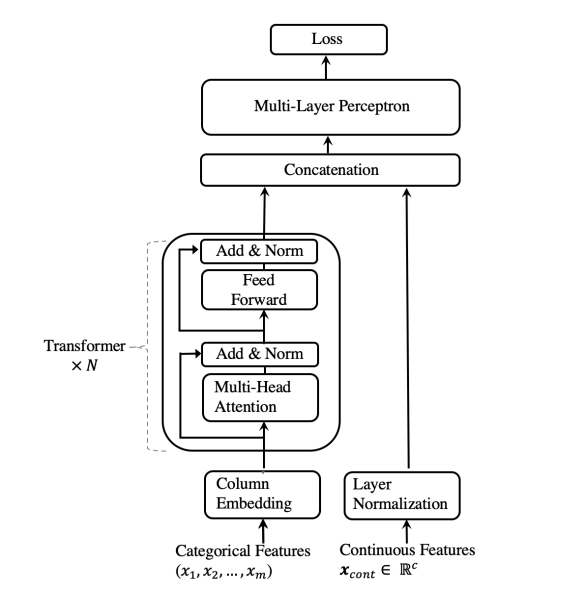
작동 방식
- Input
- categorical feature : {}
- continuous feature : layer normalization 후 transformer의 통과한 categorical feature의 representation과 concat됨
- MLP를 통과하여 loss 계산
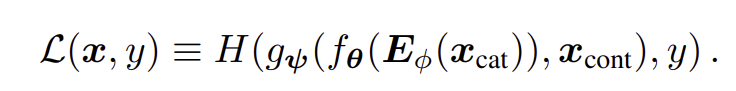
Column embedding.
- 각 categorical feature(column) {}에 대한 embedding lookup table 사용
- class가 있는 번째 feature는 embedding table 는 missing value에 해당하는 embedding을 추가하여 embedding 가짐
- 같은 변수의 class끼리 공유하는 parameter 설정
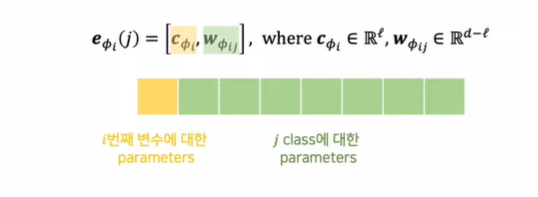
- : 열의 클래스와 다른 열의 클래스를 구분
Pre-training the Embeddings.
contextual embedding은 lableled example을 사용해서 end-to-end supervised training으로 사용
unlabeled example이 더 많은 경우)
unlabeled example로 transformer layer을 훈련하는 pretraining 절차를 거친 후 labeled example를 이용하여 상위 MLP 계층과 함께 pretrained transformer layer를 아래의 식으로 fine-tuning한다.
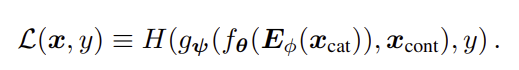
Pre-training embedding은 2가지 유형이 있다
✅ Masked language modeling (MLM)
- k% feature들을 무작위로 선택하고 누락된 것으로 masking
- Transformer layer는 context embedding에서 masking된 feature의 원래 값을 예측
- cross-entropy loss 최소화
✅ Replaced token detection (RTD)
- 원래 feature를 해당 feature의 임의 값으로 대체
- Feature 값이 대체되었는지 binary classifier로 예측
3. Experiments
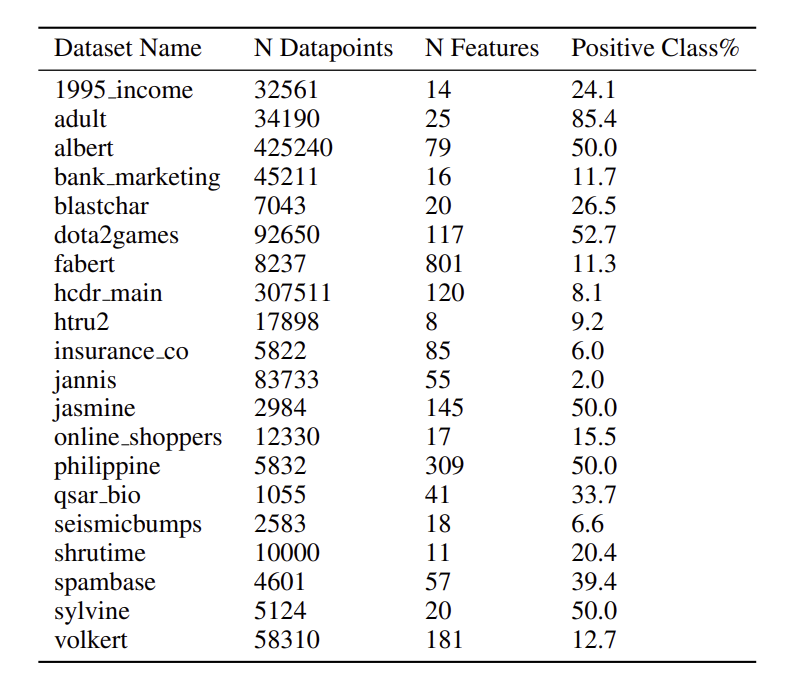
Data
- UCL repository, AutoML Challenge, Kaggle 15개 binary classification dataset
- 각 데이터 셋은 5개 cross-validation으로 분할
- train : validation : test = 65% : 15% 20%
- categorical feature 수는 2 ~ 136
- semi-supervised 에서 학습 데이터의 p만큼 관측치는 labeled data로 사용하고 나머지는 unlabeled data로 사용
- p : 50, 200, 500
Setup
- Hidden embedding dimension : 32
- Number of layers : 6
- Number of attention heads : 8
- MLP layer : {}
- : input size
- Hyperparameter optimization(HPO) : 각 cross validation split 당 20 HPO
- Evaluation metric : AUC
- pre-training은 오직 semi-supervised 시나리오에서만 가능
3.1 The Effectiveness of the Transformer Layers
✅ Transformer layer를 제거하고 나머지 구성 요소를 수정 후 원래 TabTransformer와 비교
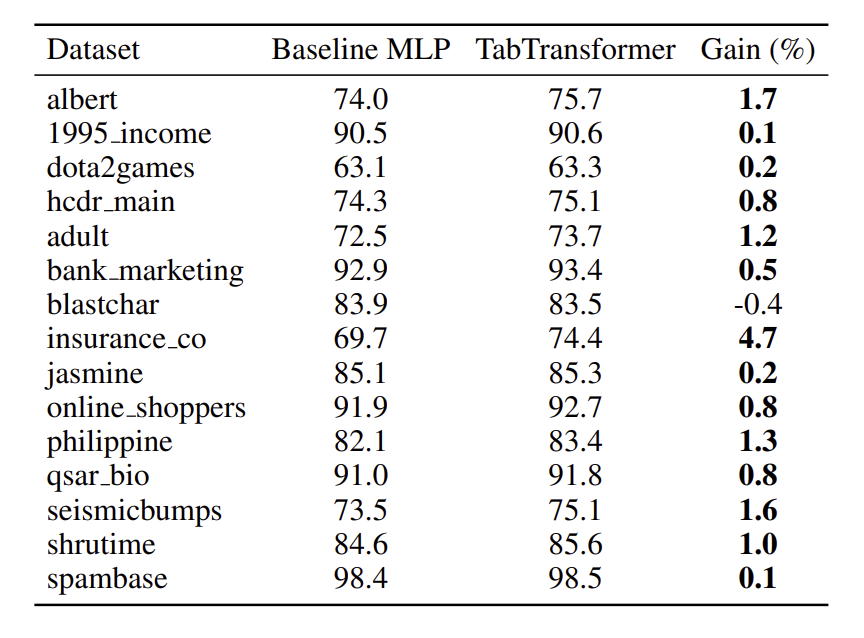
TabTransformer는 15개 dataset 중 14개에서 MLP보다 AUC가 평균 1.0% 향상됨
✅ 데이터셋 Bank Marketing categorical feature에 대해 학습된 embedding plot
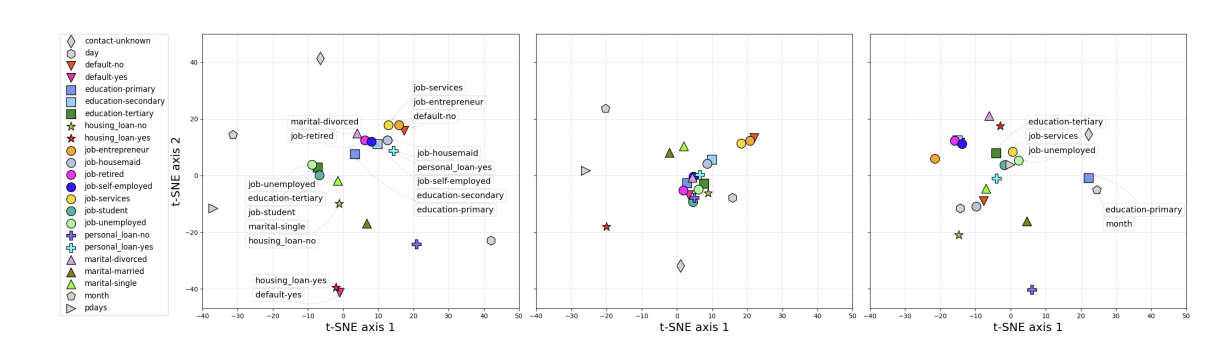
왼쪽부터 TabTransformer, Transformer 통과 전 Embeddding, MLP 의 embedding space
- Test data에 대해 Transformer의 특징 layer에서 모든 context embedding 추출
- 각 marker : 특정 class에 대한 test data point에 대한 2D point 평균
- Embedding space에서 의미적으로 유사한 class들이 더 가깝게 cluster 형성
- MLP embedding : 의미상 유사하지 않은 많은 class feature들끼리 cluster 형성
✅ 각 dataset 및 각 layer에 대해 AUC 평균 CV 점수 계산
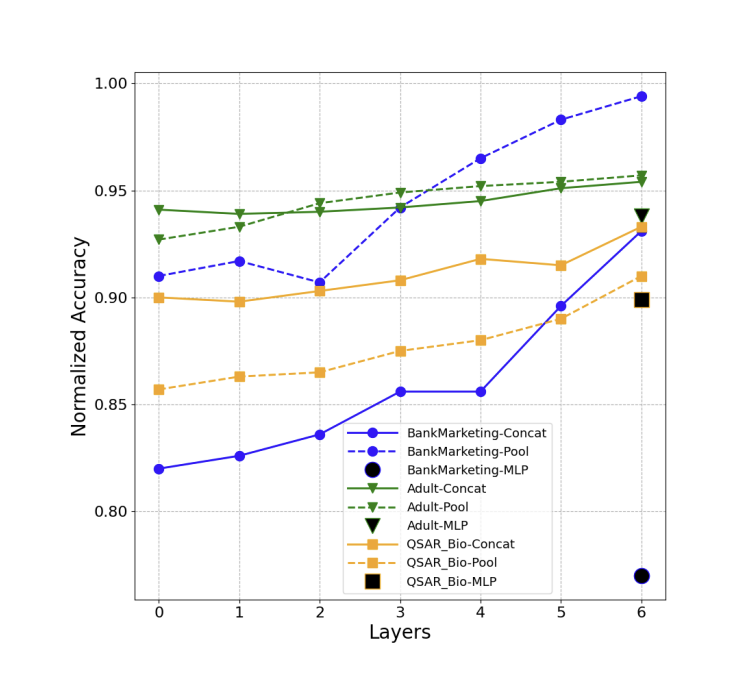
- Transformer layer가 진행됨에 따라 embedding이 더 효과
- MLP(black marker) 는 linear model에서 성능이 저하됨
- 각 라인의 마지막 값이 1.0에 가까울 수록 마지막 embedding layer 계층을 특징하는 linear model이 더 높은 정확도에 달성할 수 있음을 나타냄
3.2 The Robustness of TabTransformer
- MLP에 비해 noisy하고 missing 데이터에 대한 TabTransformer의 robustness 입증
- 구체적으로 증명하기 위해 categorical features만 학습
Noisy Data.
Noisy Data를 TabTransformer와 MLP에 학습시킨 AUC값을 나타냄
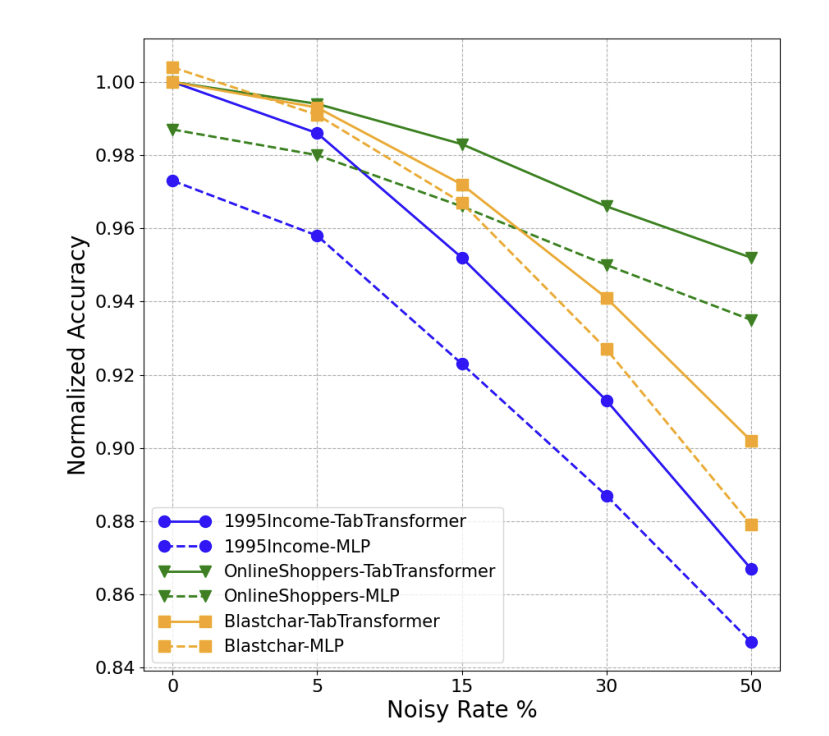
- 특정 수의 값을 무작위로 생성된 값으로 대체하여 오염시킴
- 노이즈가 증가하면서 TabTransformer가 예측 정확도가 더 우수한 성능을 보여줌 → MLP보다 더 강력함
- Blastch dataset
- 노이즈가 증가함에 따라 TabTransformer가 MLP보다 성능 감소 폭이 작음
- Robustness : embedding의 contextual property에서 비롯된다고 가정함
Data with Missing Values.
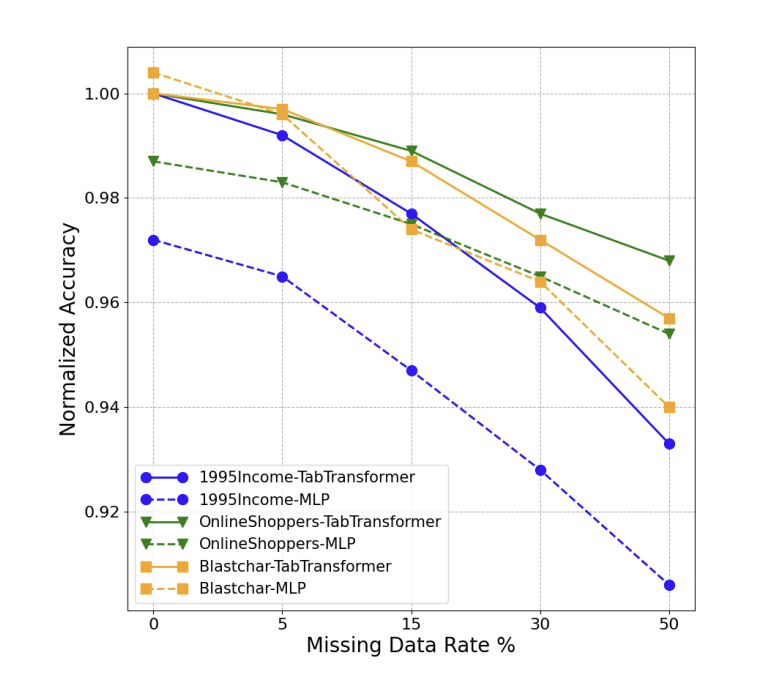
-
특정 수의 값을 인위적으로 missing시켜 데이터 오염
-
Missing value의 embedding을 처리하는 2가지 방법
1️⃣ 해당 열의 모든 class에 걸쳐 학습된 평균 embedding 사용 2️⃣ missing data class에 대한 embedding
→ 1️⃣ 방법 사용했음. Benchmark dataset에 2️⃣를 효과적으로 학습할 충분한 missing value가 없기 때문
- missing value를 처리하는데 TabTransformer가 MLP보다 더 안정성 있음
3.3 Supervised Learning
TabTransformer과 4가지 모델 성능 비교
- 로지스틱 회귀 및 GBDT
- MLP and a sparse MLP
- TabNet
- Variational Information Bottleneck model(VIB)
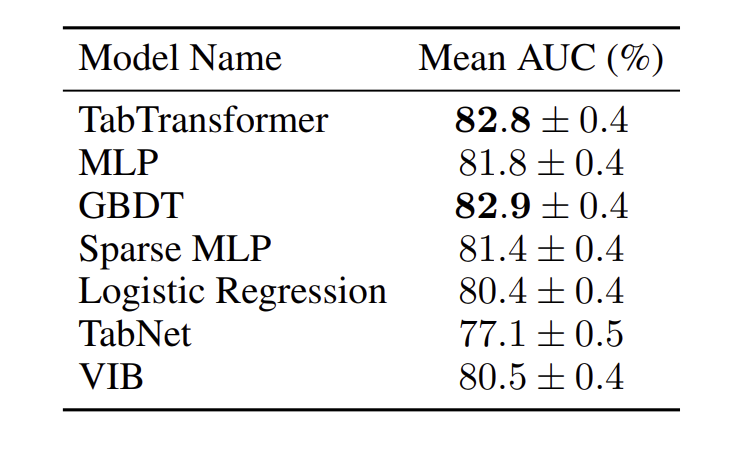
- TabTransformer, MLP, GBDP가 성능 상위 3개 모델
- TabTransformer : 평균 1.0%의 향상된 성능 → MLP를 능가, GBDT와 비슷한 성능
- 최신 deep network인 TabNet / VIB보다 성능 우수
3.4 Semi-supervised Learning
label이 지정되지 않은 데이터들로 TabTransformer 평가함.
특히, RTD/MLM을 pretraining 후 fine-tuning한 TabTransformer와 3가지 모델과 비교
-
Entropy Regularizationcombined with MLP and TabTransformer
-
Pseudo Labeling (PL) combined with MLP, TabTransformer, and GBDT
-
MLP (DAE)(swap noise Denoising AutoEncoder): tabular data의 deep models을 위해 설계된 비지도 사전 훈련 방법
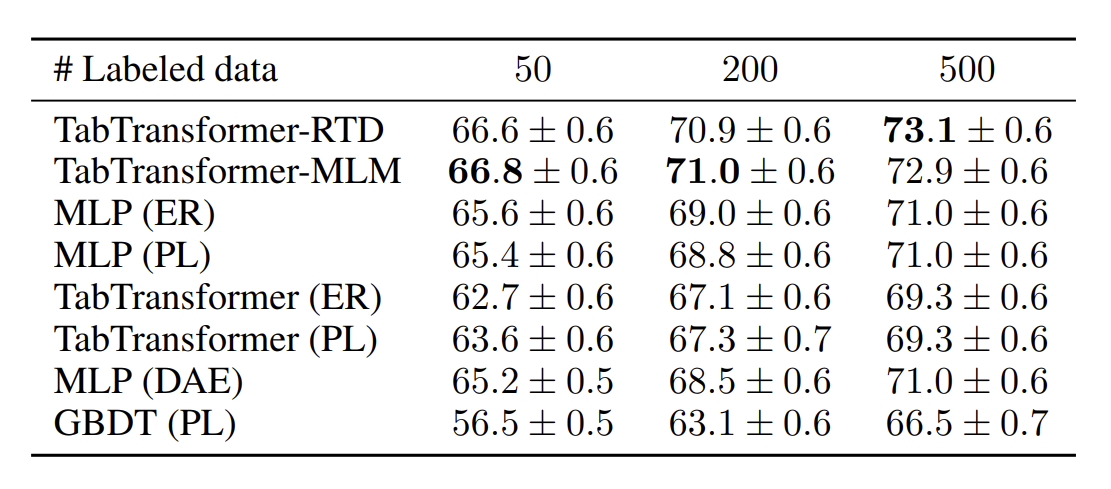
TabTransformer-RTD 및 TabTransformer-MLM이 다른 모델보다 상당히 우수함 -
레이블이 지정된 데이터 포인트 50개, 200개, 500개 시나리오에 대해 평균 AUC에서 최소 1.2%, 2.0%, 2.1% 향상
-
TabTransformer(ER) 및 TabTransformer(PL)와 트리 기반 semi supervised learning 방법인 GBDT(PL)는 모든 모델의 평균보다 성능
레이블이 지정되지 않은 데이터 수가 줄어드는 경우
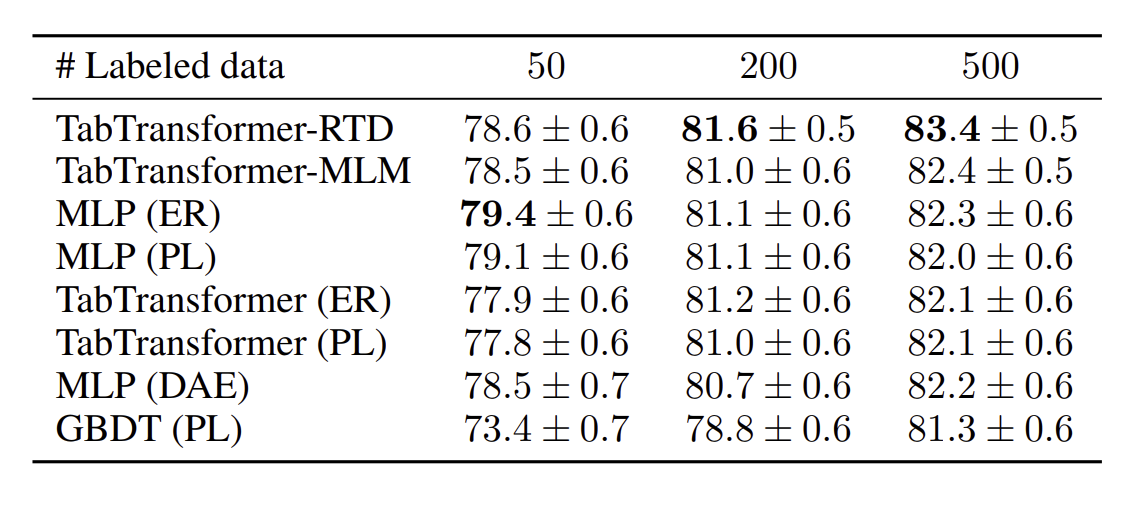
TabTransformer-RTD는 여전히 다른 방법론보다 성능이 우수하지만 약간의 성능이 향상됨.
- TabTransformer-RTD가 MLM보다 쉬운 pretraining task인 덕분에 TabTransformer-MLM보다 더 나은 성능을 보여줌
- labeled data : 50
-
MLP(ER)와 MLP(PL)가 TabTransformer-RTD/MLM을 능가
→ fine-tuning이 성능을 개선시킬 여지가 있다고 봄
→ TabTransformer가 informative embedding을 얻을 수 있으나 classifier 자체의 가중치를 훈련 안하기 때문
-
4. Conclusion
- Transformer encoder를 통해 tabular data를 modeling
- Categorical feature의 context embedding을 제공하는 architecture 제안
- noisy / missing data에도 roburst함
- pretraining, fine-tuning을 통한 semi-supervised learning도 제안
