ViT(Vision Transformer) : An Image is Worth 16x16 words : Transformers for Image Recognition at Scale
📖Paper
자연어 처리(NLP) 분야에서는 2017년도에 등장한 Transformer 구조가 현재 쓰이고 있다. 이 모델이 소개된 논문의 이름은 ‘Attention is All You Need’이고 제목에서부터 알 수 있듯이 핵심은 Attention 구조이다. NLP분야에서 엄청난 성능을 낸 Transformer를 Vision분야에 적용한 Vision Transformer를 읽어보기로 했다.
Introduction
transformer는 자연어처리에서 많이 쓰이고 있는데 vision분야에서는 제한적으로 적용되어 왔다. vision분야에서 attention은 Convolution Network와 함께 적용되거나 Convolution Network의 특정 요소를 대체하기 위해 사용되어 왔기 때문이다. 기존의 제한적인 attention 메커니즘에서 벗어나 CNN구조 대부분을 transformer로 대체함으로서 더 좋은 이미지 분류 성능을 낸다. 대량의 데이터셋으로 pretrain하고 작은 사이즈의 이미지 데이터셋으로 transfer learning할 시 기존 convolution 기반의 SOTA 결과들과 비교하면 계산량은 적으면서 훨씬 훌륭한 결과를 보여준다.
Method
ViT는 원래 transformer와 가능한 비슷하게 디자인했다. 이러한 심플한 setup을 통해 scaling이 가능하고 효율적인 실행이 가능하다.
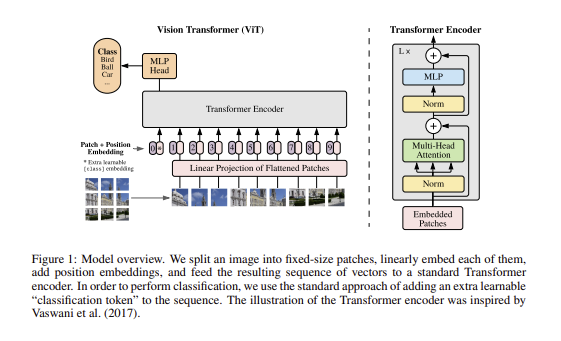
ViT는 Transformer의 Encoder 부분을 가져와서 사용했다.
1️⃣ 먼저 이미지를 패치 단위로 잘라서 이미지 패치의 시퀀스를 입력값으로 사용한다.
2️⃣ 이미지 patch들을 flatten하는 Linear Projection을 진행하여 D차원으로 mapping을 한다. 즉, 2차원 이미지를 1차원으로 매핑을 하는것인데 이미지를 patch별로 자르고 1차원 벡터로 만들어서 이어줬다고 생각하면 된다.
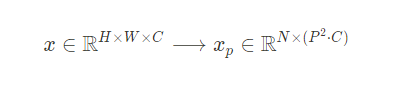
여기서 (P,P)는 각 이미지 패치의 해상도이고 N = HW / P^2는 패치수이다.
3️⃣ 그리고 위치 정보를 포함하도록 패치별로 포지션을 선정하는 Positional Embedding을 더해준다. 논문에서는 2D Positional Embedding도 추가해봤지만 눈에 띄는 성능이 보이지 않아 1D positional Embedding만을 사용했다.
(이미지는 2D이지만 1D Embedding 사용)
그리고 Transformer Encoder에 input값으로 넣는다.
4️⃣그리고 이미지 분류를 위해 classification token을 더해준다.이 때 [class] token의 Embedding을 0번째로 넣어준다. BERT의 [class] 토큰과 비슷하게 학습가능한 Embedding을 Embedding된 패치들의 sequence에 추가하게 되는데, 이 때 transformer encoder의 output에서의 state가 image representation y로 역할을 하게 된다. classification head는 MLP에 의해서 수행되며 pre-training때는 one hidden layer, fine-tuning 할 때는 single linear layer로 수행된다.
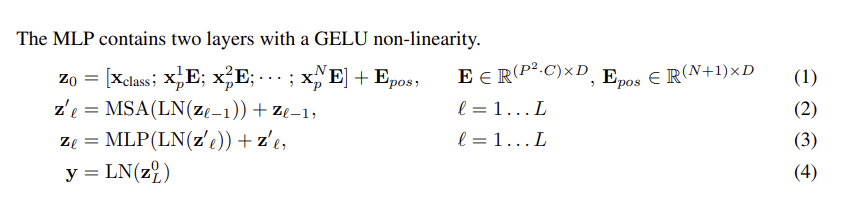
(1) : Xclass는 classifcation token이고 XNpE는 patch로 나눈 각각의 이미지 시퀀스이고 Epos는 각 시퀀스의 순서를 나타내는 Positional Encoding이다.
(2) : Transformer에 해당하는 수식으로 이전 입력 값에 Layer Normalization한 후에, Multi-head Attention을 적용한다. 해당 값을 skip connection해준다.
(3) : MLP head에 해당하는 수식으로 Transformer에서 나온 값은 MLP해준다.
(4): 학습으로 나온 class를 찾는다.
아래 그림은 ViT가 동작하는 과정이다.

Inductive bias
Inductive bias는 모델이 처음 보는 입력에 대한 출력을 예측하기 위해 사용하는 일반화능력이다. 즉, 올바른 예측을 위해 학습할 때 어떤 가정이 필요하다고 미리 정해놓은 것이다. 예를 들면, convolution filter를 활용해 local feature pattern을 추출할 수 있는 것을 inductive bias라고 한다. CNN는 translation equivariance, locality 특성을 갖고 있기 때문에 inductive bias가 강하다. Transformer는 CNN과 다르게 공간에 대한 Inductive bias가 적다. 다시 말해, 학습을 위해 가정된 특성이 적다는 뜻이다. CNN는 stationarity, locality, translation equivariance 같은 가정으로 데이터의 특성을 파악하지만 transformer는 오직 데이터 내의 전체적인 관계성으로 객체를 파악한다. 그래서 transformer가 범용적으로 활용될 수 있는 특징이기도 하지만 CNN보다 더 많은 데이터를 통해 원초적인 관계를 roburst하게 학습시켜야 한다. 그래서 ViT는 MLP layer에서만 Local 및 Translation Equivarance하다.
locality : convolution 연산을 할 떄 이미지의 특정 영역을 보고도 그 안에서 특징을 추출할 수 있다고 가정한 것.
ex> 사람 얼굴이 들어오면, "코"의 특징을 찾고 싶다면 전체 영역이 아닌 주변 영역만으로(코 부녀 영역과 합성곱 연산을 진행하면서) 특징을 찾을 수 있음**translation equivariance** : 입력의 위치가 변하면 출력 또한 동일하게 위치가 변환되어 나온다는 뜻이다.
ex> 동물 이미지가 들어오면, 동물의 귀가 좌측 상단에 위치할 때 feature map의 좌측 상단 부분에 동물의 귀에 대한 특징이 저장됨. 그런데 다른 이미지에서 동물의 귀가 우측 하단에 위치하면 feature map의 우측 하단 부분에 동물의 귀에 대한 특징이 저장됨.Hybrid Architecture
ViT는 기본적으로 Transformer만을 활용하는 것이 목표였으나 본 연구에서는 성능 비교를 위해 CNN과 Transformer를 결합한 모델을 만들어 실험해보는데 이를 Hybrid Architecture라고 부른다. 여기서는 Image patch의 대안으로 CNN의 feature Map의 Sequence를 사용하여 결합한다.
Fine-Tuning & Higher Resolution
전형적으로 ViT는 큰 데이터셋에서 사전학습되고 더 작은 downstream task에서 fine-tuning된다. 이를 위해 연구자들은 사전 학습된 prediction head를 없애고 0으로 초기화된 D*K차원의 feedforward layer를 붙인다. 더 높은 해상도 및 Patch size 동일하게 두는데 이는 더 큰 효과적인 sequence length를 만들어낸다. ViT는 임의의 sequence 길이를 다룰 수 있긴 하지만, 사전 학습된 position embedding은 의미가 없어지기 때문에, Pre-Trained Position Embedding을 2차원 보간하여 오리지널 이미지에서의 위치에 따라 적용한다.
즉, 정리하자면
- 사전 훈련 때보다 더 높은 해상도로 fine-tuning하는 것이 성능에 더 도움이 된다.
- 더 높은 해상도 이미지를 넣을 때 patch size는 동일하게 하는데 이는 sequence의 길이가 증가한다. 즉, 고해상도 이미지니까 패치수도 많아지고 길이도 길어진다.
- Fine-tuning 시에는 Pre-trained position Embedding은 더 이상 의미가 없다
- pre-trained Position Embedding을 2D 보간 수행했다
Experiments
Set up
ViT는 Image 데이터 셋으로 pre-training후 더 작은 데이터 셋에 대해 Transfer learning을 진행했다. 이 때, pre-training 데이터 셋으로는 ImageNet-1K, ImageNet-21K, JFT-18K를 사용했고 transfer learning에는 Natural, Specialized, Structure에 관한 데이터 셋을 사용했다.
Model Variants
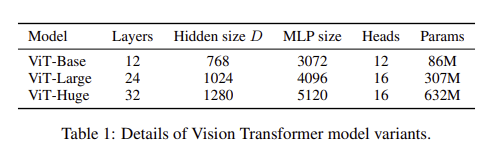
BERT에 사용된 구성을 기본으로 실험을 했다. 매개변수 크기에 따라 Base, Large, Huge 총 3가지의 모델을 구성했다. 이 때, ViT-L/16은 ViT Large 모델에 16x16 input patch를 사용했다는 의미이다. 이 때 ViT-H는 해상도를 높였을 때 성능이 더 잘 나왔다고 한다.
Training & Fine-Tuning
pre-training
사전 학습에 사용된 hyper-parameter는 Adam optimizer의 β1=0.9, β2=0.999, 그리고 batch size는 4096으로 실험했다. weight decay parameter는 0.1로 설정했다.
Fine-Tuning
Stochastic Gradient를 momentum과 함께 사용했는데 여기서 batch size는 512로 설정했다. 이미지는 ViT-L/16에는 resolution 512, ViT-H/14에는 resolution 518을 사용했다.
Comparision to state of the art
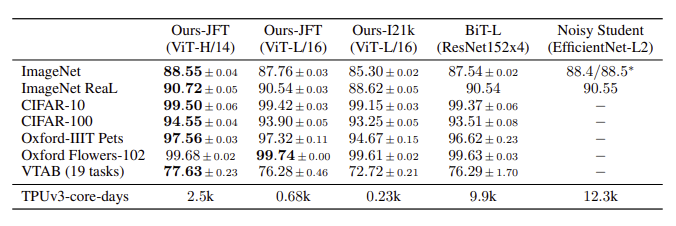
현재 SOTA 모델인 BiT(Big Transfer) 와 EfficientNet에 semi-supervised learning을 활용하여 성능을 향상시킨 Noisy Student 와 비교했다.
그 결과, JFT 데이터 셋으로 pre-train한 결과 CNN 모델보다 성능이 훨씬 좋았다. 수치는 거의 비슷하지만 TPUv3로 학습한 비용을 보면 CNN에 비해 훨씬 적다. 특히, ViT-H/14은 CNN보다 훨씬 더 나은 성능을 보여주고 있다.
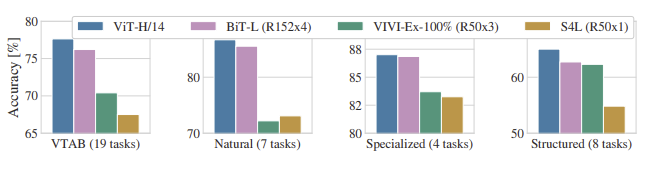
위의 표는 Transfer learning을 진행한 각 데이터셋에서의 성능이다. 모든 task에 대해 ViT가 가장 뛰어난 정확도를 보여주고 있다.
Pre-training data requirements
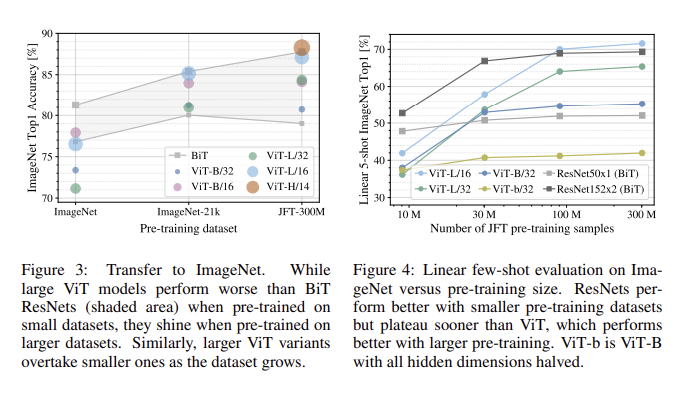
위의 그래프는 데이터 셋의 크기와 성능 간의 관계를 보여준다. CNN과 달리 ViT는 데이터 셋의 크기에 영향을 많이 받음을 알 수 있다. 크기가 큰 데이터 셋에서 사전학습을 시켰을 때에는 충분히 학습이 잘 됐으나 ImageNet과 같은 중간 사이즈의 데이터 셋에서 사전학습했을 때, ViT는 ResNet보다 약간 낮은 정확도를 보인다. 이는 Transformer에는 CNN에 내재되어 있는 inductive biases가 부족했음을 의미한다. 이러한 이유 때문에 중간 사이즈의 데이터 셋은 이 모델을 학습시키기엔 충분하지 않음을 알 수 있다.
Scaling Study
Transformer를 vision에 적용한 기존의 연구들은 scaling이 불가능했었는데 ViT에서는 어떻게 scaling을 가능하게 했는지에 대해 측정했다. 즉, Transformer, Hybird, BiT 모델로 Transfer learning 실험을 진행했다.
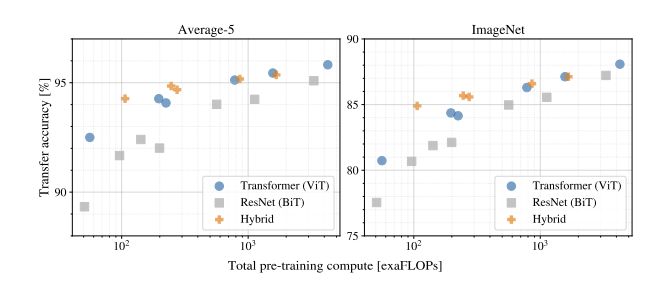
이 때, x축은 pre-training시 필요한 연산량이다.
여기서 우리는 3가지를 알 수 있다.
-
ViT는 동일한 성능을 내기 위해 ResNet보다 절반 정도의 연산량이 필요하다.
-
Hybird 모델은 적은 연산량에서 즉, 작은 크기의 모델에서는 ViT를 능가하지만 연산량을 늘리게 되면 큰 차이가 없게 된다.
-
ViT는 포화(saturate)되지 않는다. 즉, 성능을 더 높일 수 있다.
Inspecting Vision Transformer
다음은 ViT가 어떻게 이미지를 처리하는지에 대한 내용이다.

[Embedding Projection]
위의 그림은 RGB 임베딩 필터들이다. 위는 컬러영상 D개 중 28개를 시각화 한 결과이다. 임베딩 필터는 ViT의 첫 번째 Layer라고 말할 수있는데 이는 CNN의 low level에서도 이런 그림이 나타난다. 즉, 각 filter의 기능이 CNN의 저차원의 filter 기능과 유사하고 학습이 잘 됐음을 알 수 있다.
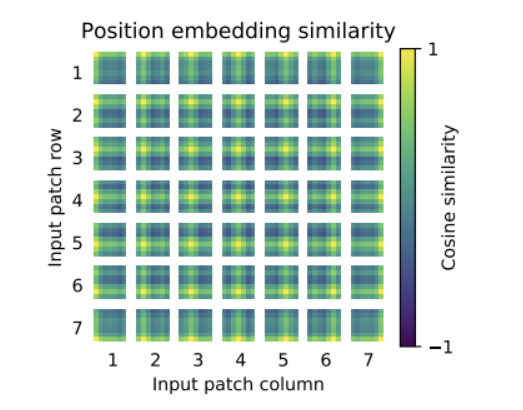
[Position Embedding]
위의 그림은 Position Embedding에 사용된 position encoding filter의 유사성을 나타낸 것이다. 즉, 패치 간의 유사성을 시각화한 결과이다. 1행 1열에 위치한 패치에서, 49개의 패치와의 유사성을 시각화 한 것인데 좌측 상단쪽은 유사성이 높고, 우측 하단쪽으로 갈 수록 유사성이 낮아진다. 즉, 가까운 패치간의 유사도가 높았는데 이는 Input Patch 간의 공간정보가 잘 학습됨을 의미한다.
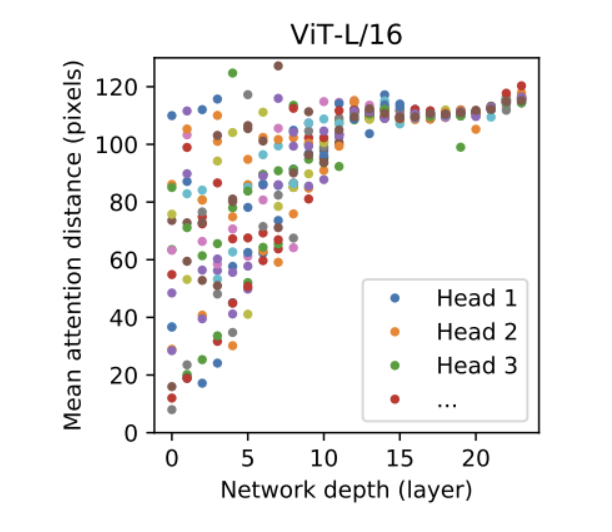
[self-attention]
위의 그림은 Self-Attention을 활용해 전체 이미지 정보의 통합 가능 여부를 확인했다. 여기서 ViT는 가장 하위의 layer에서도 전체 이미지에 대한 정보를 통합한다는 것을 알 수 있다. 이 때, distance가 클 수록 이미지의 어느 부분이 중요하고 어느 부분이 덜 중요한지 덜 중요한지 정확히 표현할 수 있다는 의미로 attention이 잘 학습됐다고 볼 수 있다.
Network depth가 작을 떄는 큰 head와 작은 head 모두 존재했으나 Network depth가 클 때는 큰 head만 존재했다. 즉, CNN과 유사하게 Network가 깊을수록 이미지의 전체적인 부분을 잘 파악함을 알 수 있다.
결국 layer를 깊게 쌓을수록 전체적인 부분을 더 잘 파악할 수 있다는 것을 나타내는 그림으로써 초반 layer에서는 국소적인 부분을 보고 후반 layer에서는 전체적인 부분을 보는 CNN과 비슷한 맥락이라고 이해할 수 있다.

마지막으로 attention을 시각화 했을 때 이미지에서 중요한 부분을 잘 나타내고 있다.
Self-Supervision
Transformer의 성공은 대규모의 self-supervised pre-training 때문이라고 보는 연구도 있다. 그래서 BERT에서 수행된 mask개념을 가져와서 self-supervision도 시도했다. ViT-B/16 모델이 79.9%의 우수한 성능을 냈으나 Supervised Learning 보다는 4% 정도 낮은 성능이였다.
Conclusion
CNN 모델에서 사용하던 inductive bias를 초기 image patch에서만 사용하고 self-attention을 사용하여 CNN보다 우수한 성능을 냈다. 그리고 대용량 데이터 셋에서는 매우 우수한 성능을 내고 있고 사전 학습 비용이 CNN보다 상대적으로 저렴하다.
그러나 3가지 정도의 challenge도 남아있다.
-
Detection, Segmentation과 같은 task에 적용할 것.
-
pre-training의 데이터 셋이 엄청나게 커야 하기 때문에 이에 관해 연구를 할 것. 즉, self-supervision과 연결시킬 것.
-
ViT가 아직 더 높은 성능을 낼 수 있기 때문에(scaling 여지가 남아있다) 더 확장시켜 성능을 향상시키는 것.
