Facebook AI Research (FAIR), UC Berkeley의 공동 연구로 ConvNet을 최신 Transformer에 적용된 기술들을 macro/micro-level의 디자인에서 최신화하는 작업을 거쳐 ConvNeXt block을 고안하여 SwinTransformer를 앞선 ConvNet이 있다는 것을 입증함
1. Introduction
2010년대를 돌아보면, 딥러닝의 기념비적인 영향으로 특정지어지고 특히, major driver은 CNN의 르네상스였다.
back-propagation으로 훈련된 ConvNet은 1980년대에 고안되었지만, 2012년에 들어서 AlexNet으로 실제 potential을 봤다.
VGGNet, Inceptions, ResNe(X)t, DenseNet, MobileNet, EfficientNet, RegNet와 같은 대표적인 CNN들은 accuracy, efficiency, scalability 다양한 관점에 집중해서 유용한 설계 이념을 대중화시켰다
computer vision에서 ConvNet의 성공은 우연이 아니었다. 많은 application 시나리오에서 visual processing에서 sliding window라는 전략이 숨어있다. ConvNet은 inductive bias들을 built-in하고 있는데, 그 중 가장 중요한 것은 translation equivariance, 이것은 object detection과 같은 task들에서 요구되는 성질이다. ConvNet은 sliding window 방식을 사용할 때 계산이 공유되는 점에서 본질적으로 efficient 하다.
그러나 2020년대에 들어 NLP에서 좋은 성능을 이끌어낸 Transformer 아키텍처를 computer vision에 적용한 ViT가 나오면서 전세가 역전된다. 이미지를 patch의 sequence로 만들고 image-specific inductive bias 없이 NLP Transformer를 조금 수정하여 적용하는 데에 성공했다. 하지만, image classIfication 외에 다른 task에도 적용하거나 고해상도 input을 감당하기에는 quadratic complexity 문제가 있었다.
slide window 전략을 다시 들고 와서 local windows들로 attention을 하는 Hierarchical Transformer인 Swin Transformer가 위의 문제를 극복하면서 다양한 vision task에서 SOTA 성능을 달성하며 genenric vision backbone이 되는 데에 성공한 milestone work가 되었다.
이러한 관점에서 computer vision에서 Transformer을 발전시키기 위해 convolution을 다시 들고 오고 있다.
sliding window로 self-attention하는 naive한 구현은 무겁고, cycle shifting과 같은 더 나은 방법으로 속도는 최적화될 수 있지만, 훨씬 복잡해진다.
아이러니하게 ConvNet은 간단한 방식이지만 이미 그러한 성질들을 만족시키고 있다.
ConvNet이 힘을 잃고 있는 것처럼 보이는 이유는 Transformer이 성능을 앞서고 있기 때문이고 성능적 차이는 Transformer의 엄청난 scaling behavior로부터 기인한다.
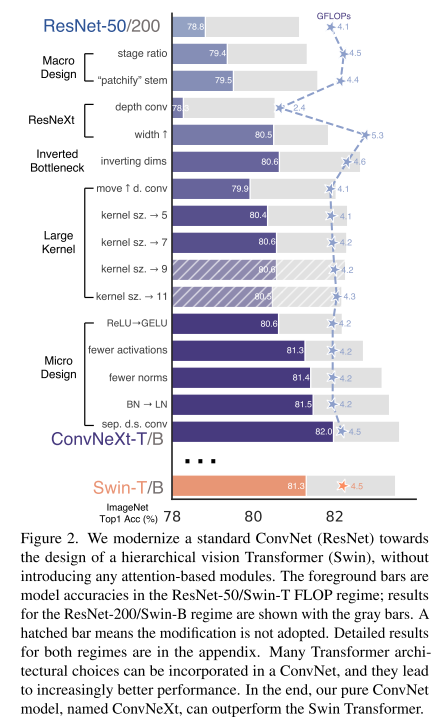
system-level에서 Swin Transformer와 ResNet을 비교하는데, 저자는 ResNet을 가지고 Swin Transformer의 구조로 점진적으로 최신화하면서 어떤 디자인들이 Transfomer의 어떤 디자인이 ConvNet 성능에 영향을 끼치느냐를 탐구한다.
그리하야 Transformer와 경쟁할 수 있는 ConvNet의 모듈만으로 이루어진 ConvNeXt를 고안한다.
2. Modernizing a ConvNet: a Roadmap
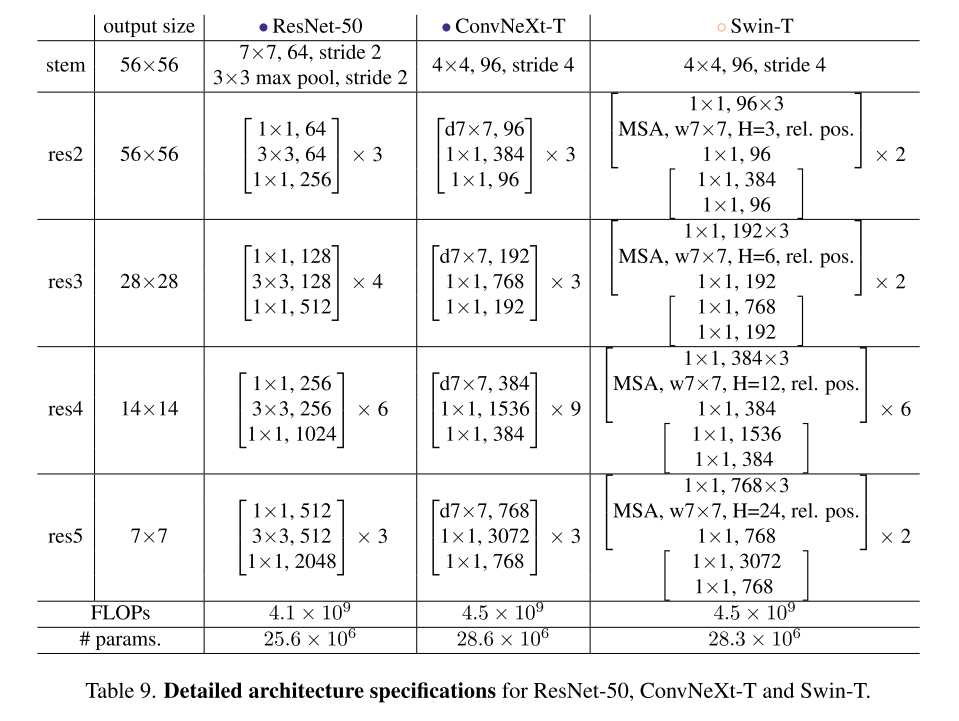
4.5G FLOPs인 ResNet-50/Swin-T를 기준으로 하겠다.
1) macro design, 2) ResNeXt, 3) inverted bottleneck, 4) large kernel size, and 5) various layer-wise micro designs 와 같은 관점에서 design decision을 수행하였다.
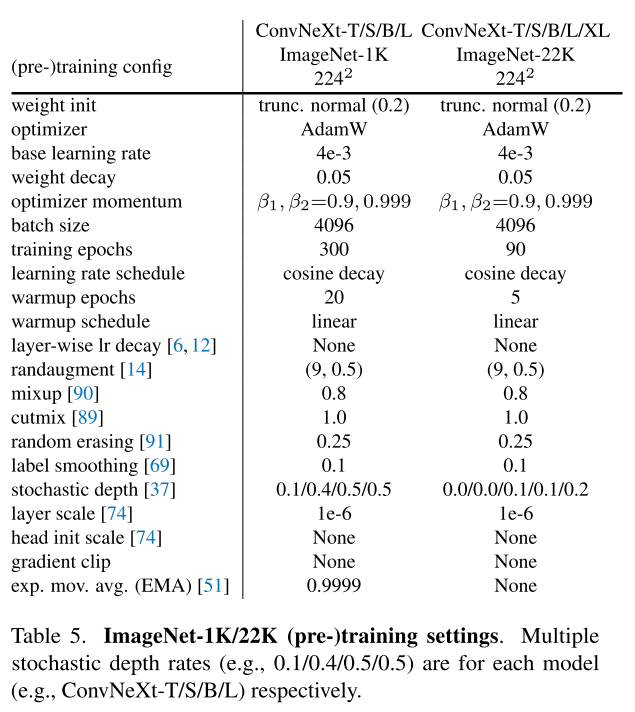
2.1. Training Techniques
architecture와 달리, training procedure도 성능에 영향을 끼치는데, ViT쪽에서 다른 training 기술들을 사용하였음.
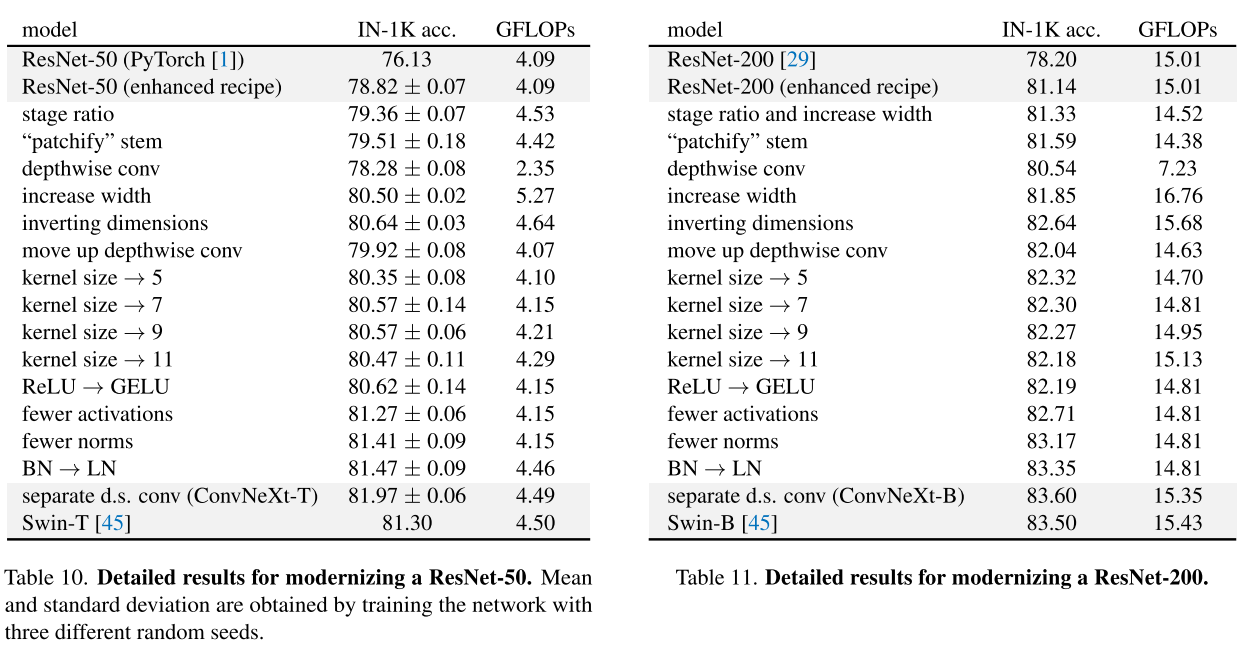
ResNet의 training scheme을 아래와 같이 적용했더니 76.1% -> 78.8% (+2.7%) 성능 향상을 이룸

2.2. Macro Design
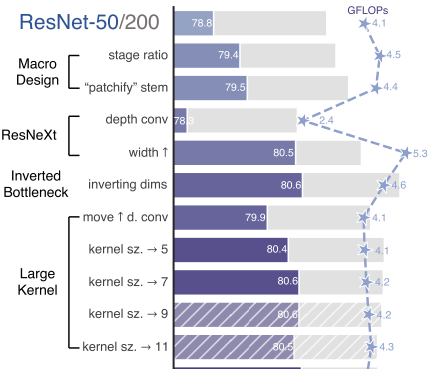
stage compute ratio
stage compute ratio를 Swin Transformer를 참고하여 바꿨음. Swin-T (1:1:3:1), Larger Swin (1:1:9:1)인데, ResNet-50을 Swin-T에 정렬해 (3, 4, 6, 3)에서 (3, 3, 9, 3)으로 바꾸니 78.8% -> 79.4% (+0.6%)
stem to 'Patchify"
자연 이미지의 내재된 중복성으로 인해 ConvNet과 vision Transformer에서 input image를 적당한 feature map size로 공격적으로 downsample한다.
ResNet conv (7x7, stride 2) - max pooling의 stem cell을 사용하는데, Vision Transformer에서 공격적인 patchify는 14x14, 16x16의 큰 kernel size로 non-overlapping하게 convolution하는데, Swin Transformer에서아키텍처의 multi-stage 디자인을 수용하기 위해 좀 더 작은 patch size 4를 사용합니다.
Swin Transformer를 참고하여 conv (4x4, strid 4)로 바꾸니 79.4% -> 79.5%
2.3. ResNeXt-ify
vanilla ResNet보다 더 나은 FLOPs/accuracy trade-off를 가진 ResNeXt. 핵심은 grouped conv인데, high-level로 갈수록 group수를 늘리고 width를 늘리는 전략으로 FLOPs를 크게 줄어드는 걸 capacity loss가 줄어드는 걸 width로 보상한다.
하지만, 저자는 greoup의 수와 channe 수가 같은 grouped conv인 depthwise conv를 사용한다. depthwise conv는 이미 MobileNet과 Xception에서 대중화되었다.
depthwise conv는 각 channel마다 spatial dimension에서만 정보를 mixing하는 것으로 self-attention의 weighted sum operation과 유사하다.
depthwise conv와 1x1 conv의 조합은 vision Transformer가 공유하는 속성인 spatial mixing과 channel mixing을 분리하게 만든다.
역시나 depthwise conv를 사용하면 FLOPs가 많이 감소하면서 성능도 줄어든다. ResNeXt의 전략을 따라, Swin-T와 같은 채널인 64->96으로 width를 늘려주면서 80.5%로 성능을 올렸고 FLOPs는 5.3G로 증가했다.
2.4. Inverted Bottleneck
모든 Tranformer block의 중요한 디자인은 inverted block을 만든다는 것이다.
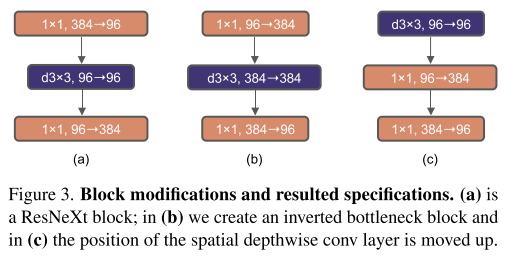
Transformer들은 4의 expansion ratio를 사용하는데, 이 아이디어는 MobileNet이 대중화시켰다.
앞에서 depthwise layer로 FLOPs를 증가시켰는데, inverted bottleneck 디자인을 적용 (Figure 3 a->b) 하면서 donwsampling하는 residual block의 shortcut 1x1 conv layer의 FLOPs 감소로 인해 FLOPs를 다시 4.6G로 감소시켰다.
성능은 80.5% -> 80.6%로 증가했고 ResNet-200에서도 감소된 FLOPs에서 성능 gain을 얻었음
2.5. Large Kernel Sizes
vision Transformer의 구별되는 점 중에 하나는 각 layer가 global receptive field를 가지는 non-local self-attention이다.
ConvNet에서도 예전엔 large kernel size를 사용했었는데, gold standard는 VGGNet에서 대중화된 3x3 커널 conv를 stack하는 것으로 GPU에서 좀 더 효율적인 구현이다.
하지만 Swin Transformer에서 self-attention block의 local window를 소개할 때 kernel size는 7x7이다.
Moving up depthwise conv layer
Figure 3 b->c 처럼 depthwise를 위로 올리는데, 이건 ViT에서 multi-head attention block이 MLP 이전에 있다는 점을 참고함.
FLOPs도 줄었지만, 3x3에선 80.6% (b) -> 79.9% (c) 로 성능 하락
Increasing the kernel size
3, 5, 7, 9, 11로 depthwise conv의 kernel size를 키워봤는데, 7x7에서 80.6%로 다시 성능이 오름 (더 큰 모델도 동일)
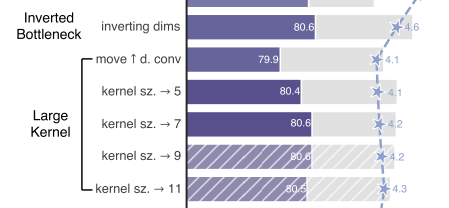
Figure 3. (b)는 4.6G FLOPs인데, 4.2 G FLOPs로 크기를 줄이면서 80.6%
여기까지 macro design (training, patchify, depthwise but wider, inverted block, depthwise first, large kernel)
2.6. Micro Design

ReLU에서 GeLU
Google의 BERT, OpenAI의 GPT-2 등 진보된 NLP 모델들은 Guassian Error Linear Unit (GeLU)를 보통 사용함. 성능 변화 없었음 (80.6%)
Fewer activation functions
Transformer와 ResNet의 minor한 구별점은 Tranformer가 activation function이 적다는 것
Transformer는 key/query/value linear embedding layer, projection layer, MLP block의 two linear layer가 있는데 MLP block에서만 하나의 activation function을 쓴다.
그것을 따라서 Figure 4의 ConvNeXt Block처럼 1x1 layer 사이에 하나의 activation function을 쓰고 81.3%로 성능을 향상시켰다.
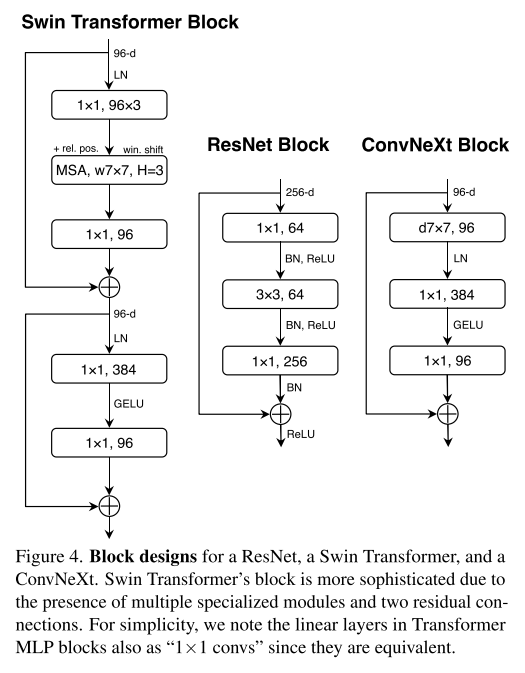
Fewer normalization layers
비슷하게 normalization layer도 적게 사용하는데, 두 개의 Batch Normalization을 제거하고 Batch Normalization을 하나만 사용했고 81.4%로 성능을 더 올렸다.
여기서 Swin-T의 결과를 이미 앞서기 시작했다.
BN to LN
Batch norm은 모델의 convergence를 개선하고 overfitting을 감소시키는 중요한 component인데, 모델 성능에 안 좋은 영향을 끼칠 수 있는 많은 복작서을 가지고 있고 다양한 alternative들이 소개되었다. BN은 여전히 많이 쓰이는 옵션으로 남아있는데, Tranformer에선 Layer Normalization을 사용한다.
BN을 LN으로 대체함으로써 81.5%로 성능이 더 올랐다.
downsampling layers
ResNet에서 spatial downsampling은 각 스테이지 시작의 residual block에서 conv 3x3 with stride 2과 conv 1x1 with stride 2의 shortcut connection에서 수행된다. Swin Transformer에선 stage 사이에 downsampling layer를 분리해놓았다.
그와 유사하게 conv 2x2 stride 2를 사용했는데, 훈련이 발산한다.
여기서 downsampling layer 직전에 Layer norm을 추가하여 훈련을 안정화시켰다.
그 결과 82.0%에 도달했고 이를 ConvNeXt block이라고 얘기한다.
Closing remarks
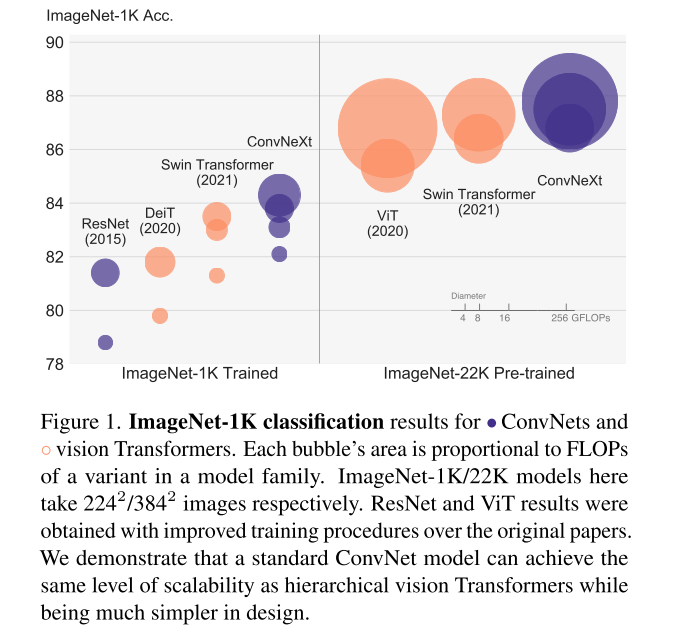
ImageNet-1K classification에서 Swin Transformer를 앞선 ConvNet, ConvNeXt를 발견했는데, 이것이 Tranformer의 design을 따랐다는 것이고 결코 ConvNet에서 novel한 것이 아니라 10년동안 서로 각기 연구되었던 것을 저자들이 합쳐낸 것이다.
Swin Transformer와 거의 같은 FLOPs, parameter 수, throughput을 가지지만, shifted window attention이나 relative position biases와 같은 특별한 module을 요구하지도 않는다.
그럼 object detection, segmentation에서도 잘 될 것이냐와 scalability에 대한 문제를 다루겠다.
3. Empirical Evaluations on ImageNet
Swin-T/S/B/L처럼 ConvNeXt-T/S/B/L이꼬 ConNeXt-T는 ResNet-50의 최신화고 -B는 ResNet-200의 최신화다.
ConvNeXt-XL은 scalability를 더 보기 이해 만들었다.

3.1. Settings
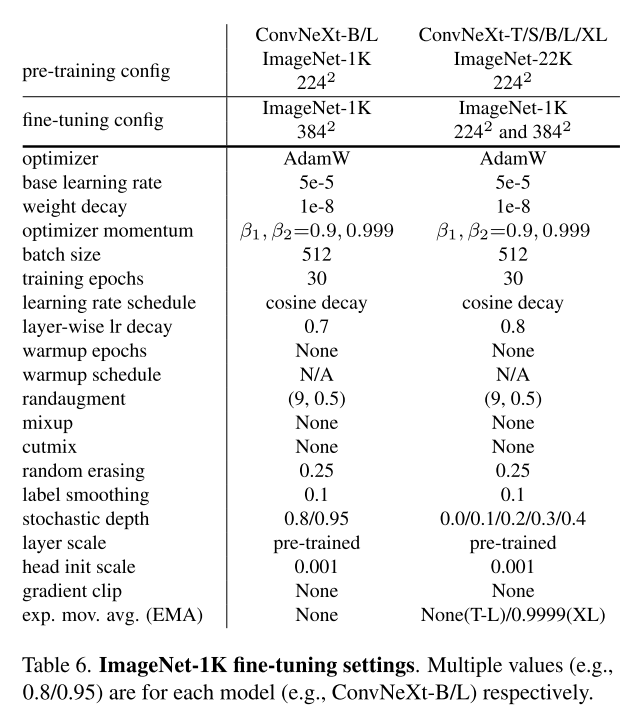
ImageNet-1K는 1000 class에 1.2M training image로 구성되어있고, ImageNet-1K validation set에서 top-1 accruacy를 report한다. 또한, ImageNEt-22K (21841 class ~14M images)에서 pre-train하고 ImageNet-1K에서 평가를 위해 fine-tune했다.

Stochstic Depth, Label Smoothing, Layer Scale of initial value 1e-6.. 각각의 영향은 모르겠네
큰 모델의 overfitting을 완화하는 Exponential Moving Average (EMA)
pre-train warm up 쓰고 fine-tune때는 안 쓰고
ViTs/Swin Transformer와 비교하여, ConvNeXt는 fully convolutional이기 때문에 different resolution에서 input patch size를 조정하거나 absolute/relative position biases를 interpolate해야되는 필요가 없어 더 간단하다.
3.2. Results
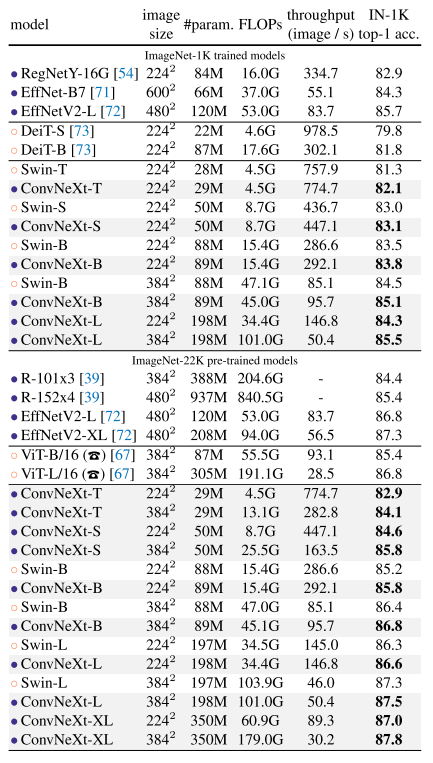
22K pre-trained model이 모두 더 나았고, ConvNeXt가 같은 연산 cost 대비해서 Swin Transformer는 다 이김
XL로 성능을 더 올리면서 ConvNeXt가 scalable한 것도 보임
이미지 사이즈가 크다면 EfficientNet이 효율적인 것 같기도 하고..
3.3. Isotropic ConvNeXt vs. ViT
downsampling layer 없이 feature resolution은 14x14로 유지하는 ViT-style isotropic architecture와 비교
더 낮은 FLOPs, traning memory로 비슷한 성능
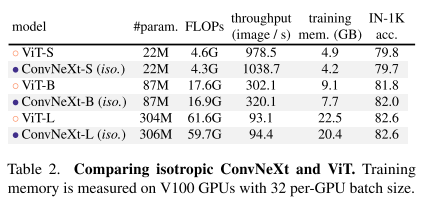
non-hierarchical model에서 사용할 때도 사용할 수 있음을 입증
4. Empirical Evaluation on Downstream Tasks
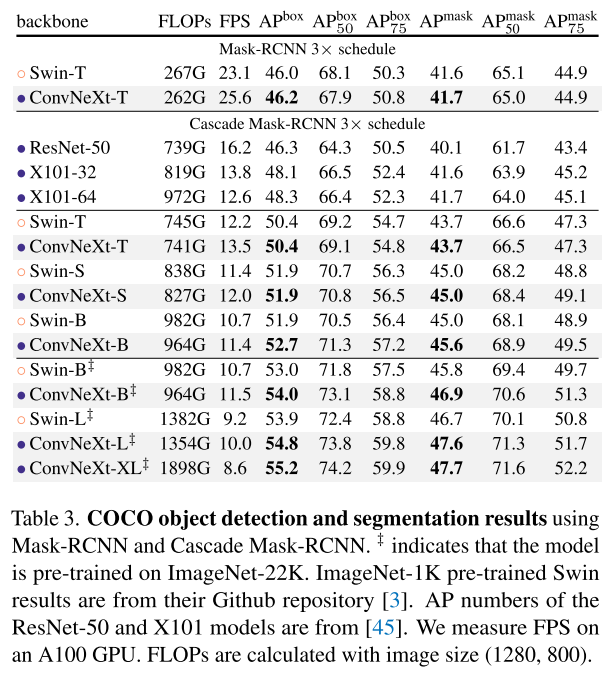
Object Detection and segmentation on COCO
ConvNeXt를 backbone으로 Mask R-CNN, Cascade Mask R-CNN을 finetune
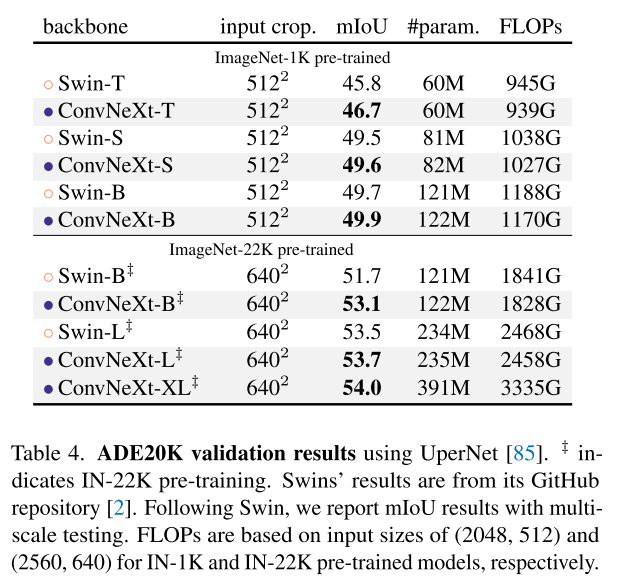
Semantic segmentation on ADE20K
UperNet을 사용해서 훈련시켰고 160K iterations with a batch size of 16
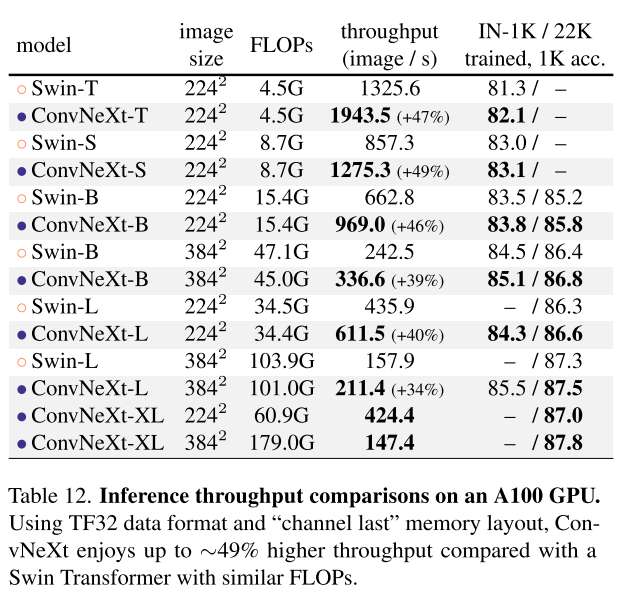
Remarks on model efficiency
비슷한 FLOPs에서 depthwise convolution이 더 느리고 memory를 더 잡아먹는 것으로 알려져있다. 하지만, throughout을 보면 ConvNeXt가 Swin Transformer랑 비슷하거나 앞선다.
training할때 memory도 덜 먹더라.. ConvNeXt backbone으로 Cascade Mask-RCNN을 가지고 GPU당 2개의 batch를 사용하면 peak memory가 17.4GB인데, Swin은 18.5GB
vanilla ViT에 비해 ConvNeXt와 Swin Transformer 둘 다 local computation으로 인해 전반적으로 accuracy-FLOPs trade off가 좋더라
이 efficiency개선은 ViT의 self-attention mechanism과 관련있는 게 아니라 ConvNet inductive bias의 결과다.
5. Related Work
Hybrid models
ViT이전엔 ConvNet로 long-range dependecies를 capture하기 위해 self-attention/non-local module을 결합하는 연구들이었고
ViT이후 후속 연구들은 다시 convolution priors를 다시 ViT에 접목하는 방향으로 연구가 진행됨
Recent convolution-based approaches
[25] Qi Han, Zejia Fan, Qi Dai, Lei Sun, Ming-Ming Cheng, Ji- aying Liu, and Jingdong Wang. Demystifying local vision transformer: Sparse connectivity, weight sharing, and dy- namic weight. arXiv:2106.04263, 2021.[25]는 local Transformer attention이 inhomogeneous dynamic depthwise conv랑 동일한 것을 보였고 Swin Transformer에서 MSA block을 dynamic or regular depthwise conv로 대체하여 Swin과 비슷한 성능을 보였음
비슷하게 depthwise covnvloution을 mixing 전략으로 사용한 ConvMixer, Fast Fourier Transform을 token mixing에 사용한 GFNet 등과 같은 연구들이 있음
이 연구의 궁극적인 목적은 ResNet을 최신화하는 절차에서 in-depth look을 제공하고 SOTA 성능을 달성한 것이다
6. Conclusions
2020년대에 들어 vision Transformer, 특히 Swin Transformer와 같이 hierarchical한 Transformer가 ConvNet들을 제치고 generic vision backbone이 되었다.
vision Transformer가 더 정확하고 efficient하고 scalable하다는 믿음이 있어왔는데, 이 연구에서 그들과 대적할 수 있는 pure ConvNet인 ConvNeXt를 제안했다.
이 자체로 완성된 것은 아니지만, 이 새로운 결과로 널리 알려진 견해들에 도전하고 computer vision에서 convolution의 중요성을 다시 생각할 수 있도록 prompt하길 빈다.
Comments
Swin Transformer를 본따서 ResNet을 최신화해보니 되잖아? convolution은 죽지 않아!
그리고 다양한 관점에서 common하게 개선 point를 얻을 수 있다.
- ConvNet에다가 Swin Transformer의 최신 훈련 기법만으로도 큰 개선을 이룬다.
- task-specific하게 증강법이나 파라미터가 달라질 순 있지만, 훈련 기법을 고도화하는 일이 필요하다
- larger scale의 dataset에서 fine-grained 문제를 푸는 것으로 pre-train할 수 있으면 성능을 개선할 수 있다.
- 풀려는 task보다 더 어렵고 큰 데이터셋에서 pre-training할 수 있다면 성능을 개선할 수 있다. down stream task에서도
- pre-training set을 구축하고 pre-training을 따로 신경쓰는 것도 중요하다. (GPT-4 pre-training 팀이 따로 있을 정도니)
depthwise conv, 1x1 conv로 spatial/channel attention을 분리하고 inverted block을 만들면서 MSA를 참고하여 spatial 정보를 mixing하는 layer를 앞에 두는 아이디어가 실험결과로 입증되었다는 것이 멋져보인다.
conv 1x1 - depth 3x3 - conv 1x1 inverted block이 4.64G FLOPs인데, depth 7x7 - conv 1x1 - conv 1x1의 inverted block으로 4.15G FLOPs로 줄이면서 거의 비슷한 성능이 나와서 더 efficient하다는 것도 보임
micro design 측면에서 block 수정 외에도 실제적으로 activation 덜 쓰고, downsampling layer를 분리한 게 성능개선 효과가 컸음
다만, aggressive하게 downsampling하는 "patchify"는 pathology image 분석 모델을 만들 때에는 부적합할 수 있다고도 보인다.
Appendix