분류 📊
분류는 학습데이터로 주어진 데이터의 피처와 레이블값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델을 생성
분류 머신러닝 알고리즘
- 베이즈 통계와 생성 모델에 기반한 나이브 베이즈
- 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀
- 데이터 균일도에 따른 규칙 기반의 결정 트리
- 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신
- 근접 거리를 기준으로 하는 최소 근접 알고리즘
- 심층 연결 기반의 신경망
- 서로 다른 머신러닝 알고리즘을 결합한 앙상블
앙상블은 매우 많은 여러개의 약한 학습기를 결합해 확률적 보완과 오류가 발생한 부분에 대한 가중치를 계속 업데이트 하면서 예측 성능을 향상시키는데, 결정트리가 좋은 약한 학습기로 사용됨.
01. 결정 트리
결정트리(Decision Tree)는 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 것
규칙노드 노드는 규칙 조건이 되고 리프노드는 결정된 클래스 값
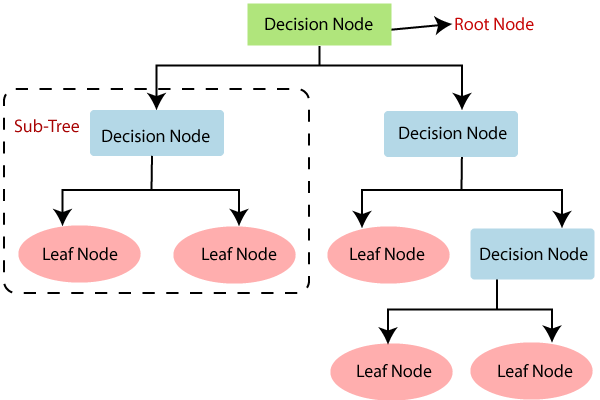
결정노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만듦
1. 서브 데이터 세트 생성
2. 서브 데이터 세트에서 균일도가 높은 자식 데이터 세트 쪼개는 방식을 자식 트리로 내려가며 반복하는 방식
- 정보 균일도
1) 엔트로피를 이용한 정보 이득
1 - 엔트로피 지수
(서로 다른 값이 섞여 있을수록 엔트로피가 높음)
2) 지니 계수 (불평등 지수)
0이 가장 평등하고 1로 갈수록 불평등
지니 계수가 낮은 속성을 기준으로 분할해 데이터 균일도가 높도록 함
- DecisionTreeClassifier
- 결정 트리 룰이 명확
- 어떻게 규칙드와 리프노드가 만들어지는 지 알수 있음
- 시각화로 표현 가능
단, 과적합으로 정확도가 떨어짐 ❗
차라리 모든 데이터 상황을 만족하는 완벽한 규칙은 만들 수 없다고 먼저 인정하는 편이 더 나은 성능을 보장✨
- 결정 트리 시각화
Graphviz 패키지 사용
→ export_graphviz()
- 붓꽃 데이터 세트 DecisionTreeClassifier 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf= DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고,학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
# DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, feature_names = iris_data.feature_names, impurity=True, filled = True)
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 주피터 노트북상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)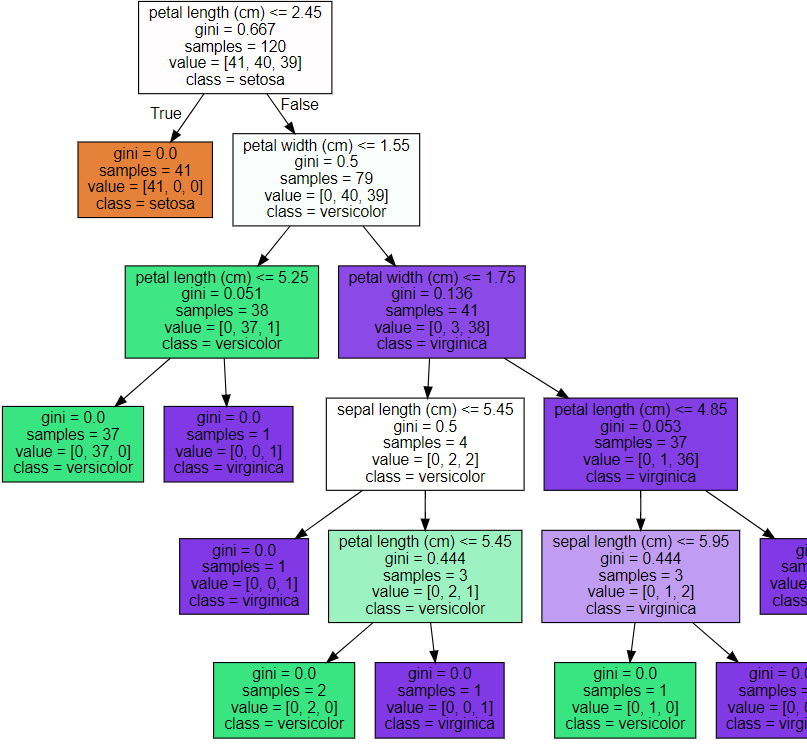
그래프 색깔이 짙어질수록 지니계수가 낮고 해당 레이블에 속하는 샘플 데이터가 많다는 의미
자식노드가 있는 노드 브랜치 노드, 말단 리프 노드
petal_length <= 2.45 규칙이 True 또는 False로 분기하게 되면 2번, 3번 노드가 만들어짐.
➡ 미리 제어하지 않으면 완벽하게 클래스 값을 구별하기 위해 트리 노드를 계속해서 만들어나가는 과적합 문제를 발생
➡ 하이퍼 파라미터 max_depth, min_samples_leaf(자식노드 최소데이터 건수까지만 가지도록 분할)
결정트리는 균일도에 기반해 어떠한 속성을 규칙 조건으로 선택하느냐가 중요한 요건
- 피처별 중요도 추출
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importance:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)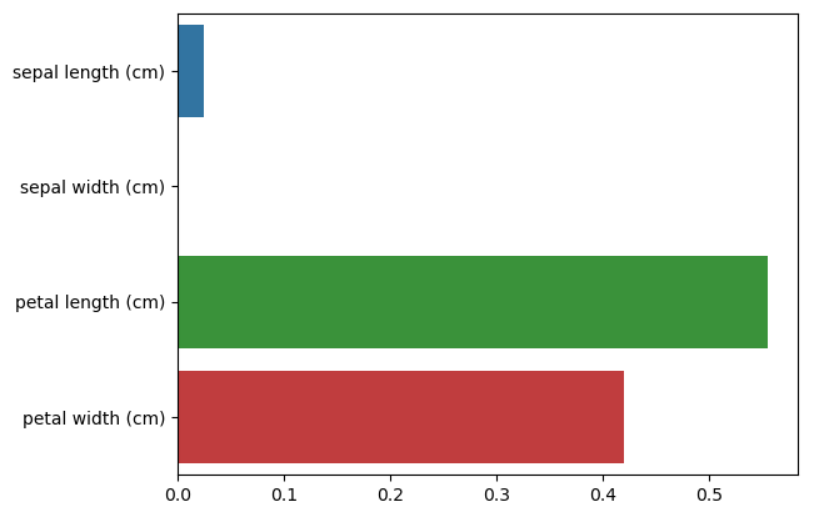
- 결정 트리 과적합
2개의 피처가 3가지 유형의 클래스 값을 가지는 데이터 세트 생성
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
# 2차원 시각화를 위해서 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2, n_classes=3, n_clusters_per_class=1, random_state = 0)
# 그래프 형태로 2개의 피처로 2차원 좌표 시각화, 각 클래스 값은 다른 색깔로 표시됨.
plt.scatter(X_features[:,0], X_features[:,1], marker='o', c=y_labels, s=25, edgecolor='k')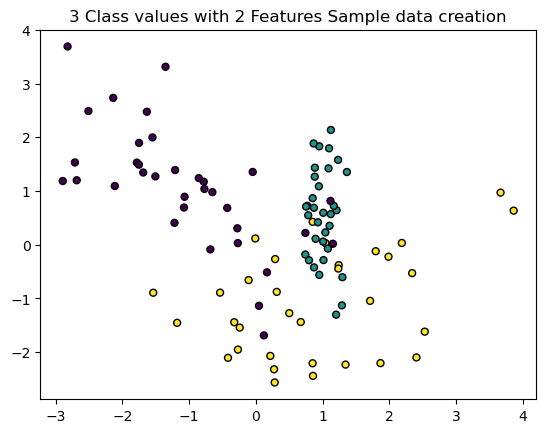
x, y축이 2개의 X_feature, 3가지 종류의 색이 3가지 유형의 클래스 값 y_labels 의미
[특정한 트리 생성 제약 없는 결정트리]
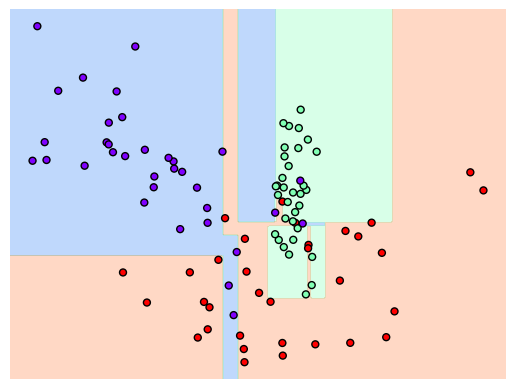
결정 기준 경계가 매우 많아져 예측정확도가 떨어지게 됨
[min_samples_leaf=6]
# min_samples_leaf=6으로 트리 생성 조건을 제약한 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf = 6, random_state=156).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)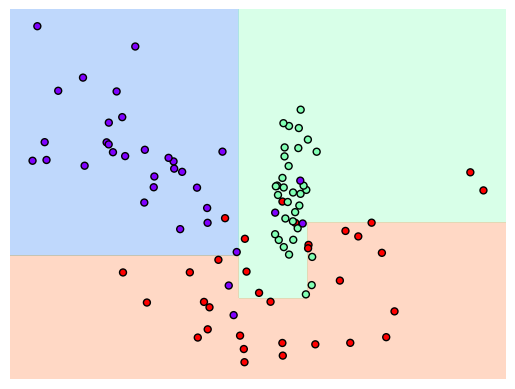
02. [실습] 사용자 행동 인식 데이터 세트
import pandas as pd
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예제 반복 시마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('결정 트리 예측 정확도: {0:4f}'.format(accuracy))
# DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터:\n', dt_clf.get_params())- 트리 깊이 하이퍼파라미터
GridSearchCV 이용
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20,24],
'min_samples_split': [16],
}
grid_cv = GridSearchCV(dt_clf, param_grid= params)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터:', grid_cv.best_params_)
max_depths = [6,8,10,12,16,20,24]
#max_depth 값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth=depth, min_samples_split=16, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('max_depth = {0} 정확도: {1:.4f}'.format(depth, accuracy))[Output]
max_depth = 6 정확도: 0.8551
max_depth = 8 정확도: 0.8717
max_depth = 10 정확도: 0.8599
max_depth = 12 정확도: 0.8571
max_depth = 16 정확도: 0.8599
max_depth = 20 정확도: 0.8565
max_depth = 24 정확도: 0.8565- 최종 결과
Fitting 5 folds for each of 8 candidates, totalling 40 fits
GridSearchCV 최고 평균 정확도 수치: 0.8549
GridSearchCV 최적 하이퍼 파라미터: {'max_depth': 8, 'min_samples_split': 16}
결정 트리 예측 정확도:0.8717- 피처 중요도
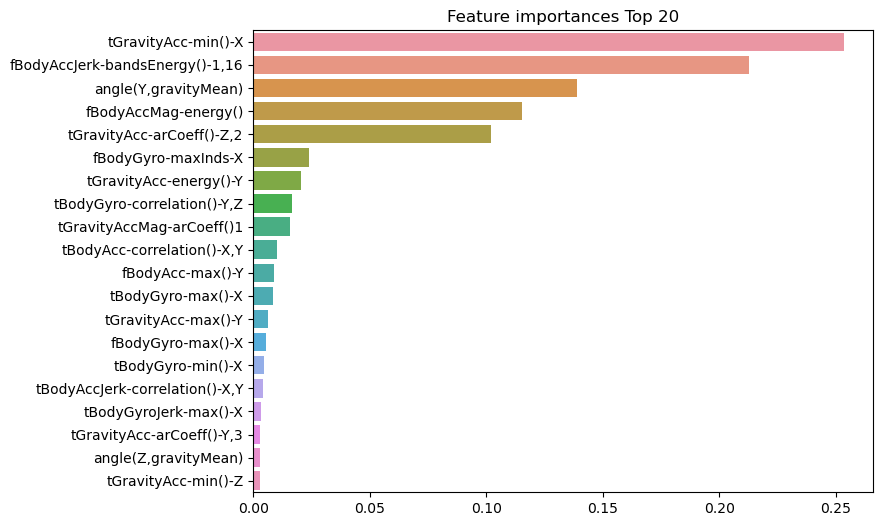
03. 앙상블 학습
앙상블 학습은 여러개의 분류기를 생성하고 그 예측을 결합함으로써 정확한 최종 예측을 도출하는 기법
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
앙상블 알고리즘
- 보팅
- 배깅 랜덤 포레스트
- 부스팅 그래디언트 부스팅, XGboost, LightGBM
- 보팅과 배깅
여러개의 분류기가 투표를 통해 최종 결과를 결정하는 방식
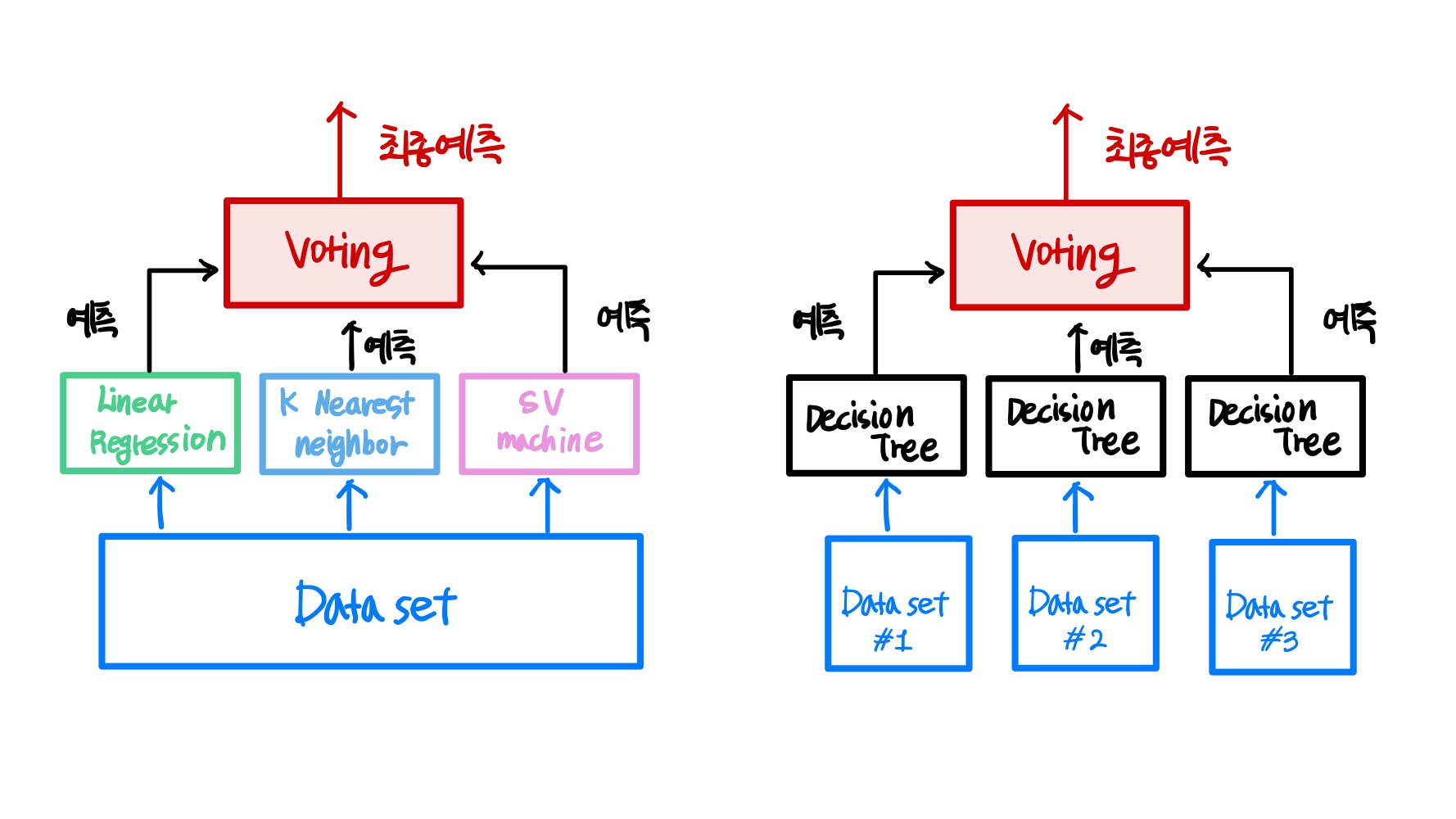
보팅 일반적으로 서로 다른 알고리즘을 결합
배깅 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것
→ 개별 Classifier에게 데이터를 샘플링해서 추출하는 방식을 부트 스트래핑 분할 방식이라 함 ↔ 교차 검증은 중첩을 허용하지 않는 것과 다르게 배깅 방식은 중첩을 허용
- 부스팅
분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에게는 가중치를 부여하면서 학습과 예측을 진행
- 보팅 유형 HardVoting vs SoftVoting
1. 하드 보팅
하드 보팅은 다수의 분류기가 결정한 예측값을 최종 보팅 값으로 선정
2. 소프트 보팅
결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정
✨하드 보팅보다는 소프트 보팅이 예측 성능이 좋아서 더 많이 사용됨
- 보팅 분류기(VotingClassifier)
[실습] 위스콘신 유방암 데이터 세트 예측 분석
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
data_df.head(3)
# 개별 모델은 로지스틱 회귀와 KNN임
lr_clf = LogisticRegression(solver="liblinear")
knn_clf = KNeighborsClassifier(n_neighbors = 8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier(estimators=[("LR", lr_clf), ("KNN", knn_clf)], voting='soft')
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=156)
#VotingClassifier 학습/예측/평가
vo_clf.fit(X_train, y_train)
pred = vo_clf.predict(X_test)
print("Voting 분류기 정확도 : {0:.4f}".format(accuracy_score(y_test, pred)))
# 개별 모델의 학습/ 예측/ 평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print("{0} 정확도 : {1: .4f}".format(class_name, accuracy_score(y_test, pred)))
# 개별 모델의 학습/ 예측/ 평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test, pred)))[Output]
LogisticRegression 정확도: 0.9474
KNeighborsClassifier 정확도: 0.9386보팅으로 여러개의 기반분류기를 결합한다고 해서 무조건 기반 분류기보다 예측 성능이 향상되지는 않음.
ML 모델의 성능은 다양한 테스트 데이터 세트에 의해 검증되므로 어떻게 높은 유연성을 가지고 현실에 대처할 수 있는가가 중요한 ML 모델의 평가요소가 됨
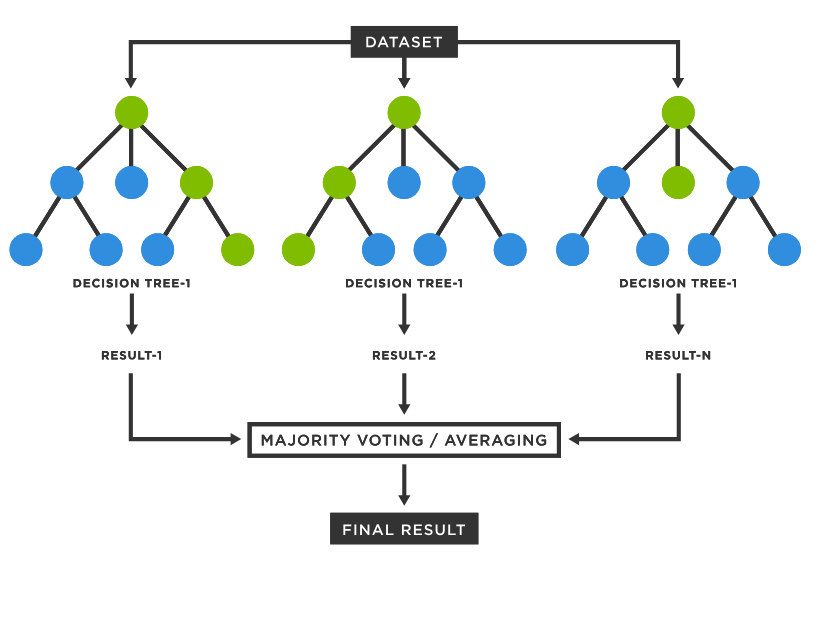
04. 랜덤 포레스트
랜덤포레스트의 기반 알고리즘은 결정트리.
랜덤포레스트는 여러개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 함.
- 부트 스트래핑
여러개의 데이터 세트를 중첩되게 분리하는 것을 부트스트래핑 분할 방식 이라함.
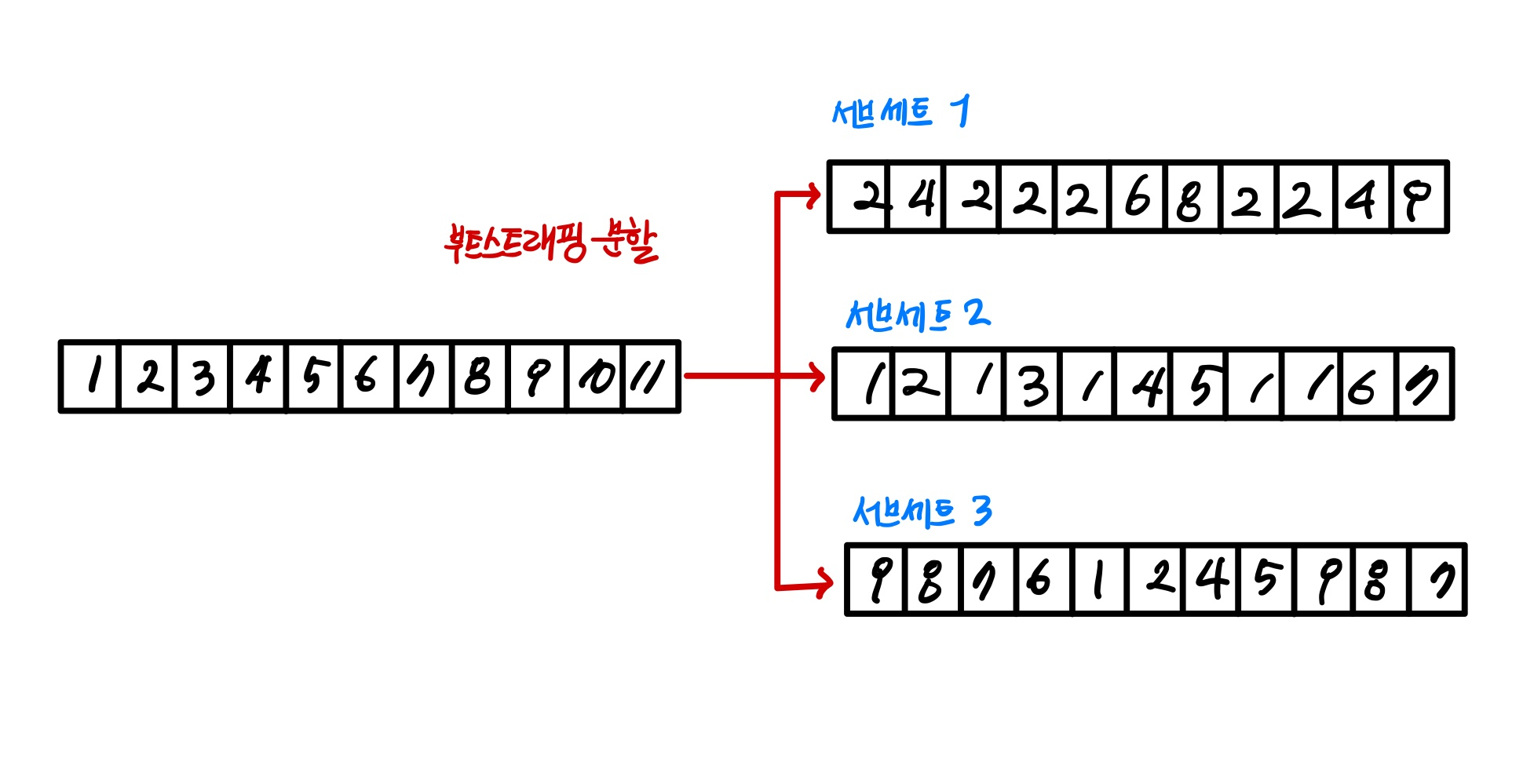
데이터가 중첩된 개별 데이터 세트에 결정 트리 분류기를 각각 적용하는 것이 랜덤 포레스트
- [실습] 사용자 행동인식 데이터 세트 RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset()를 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 세트로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0, max_depth=8)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy= accuracy_score(y_test, pred)
print('랜덤 포레스트 정확도:{0:.4f}'.format(accuracy))from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [8, 16, 24],
'min_samples_leaf': [1, 6, 12],
'min_samples_split': [2, 8, 16]
}
#RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
[Output]
최적 하이퍼 파라미터:
{'max_depth': 16, 'min_samples_leaf': 6, 'min_samples_split': 2}
최고 예측 정확도: 0.9165- 피처 중요도
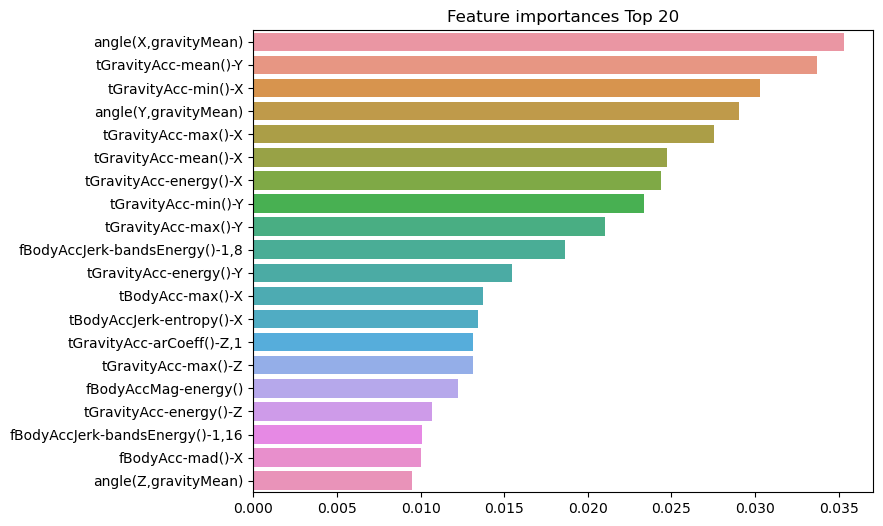
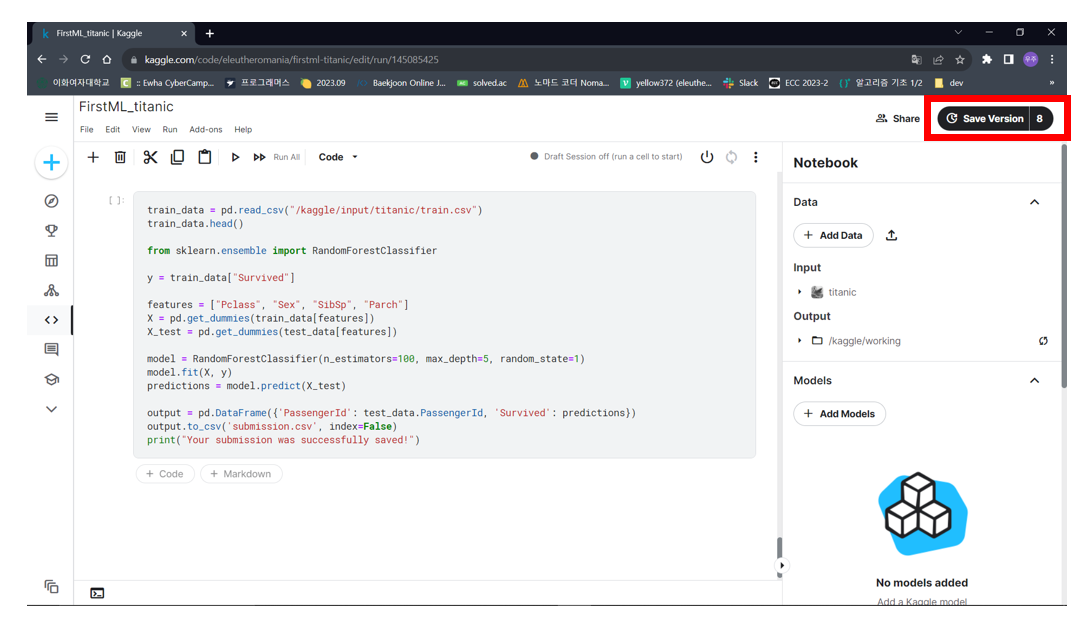
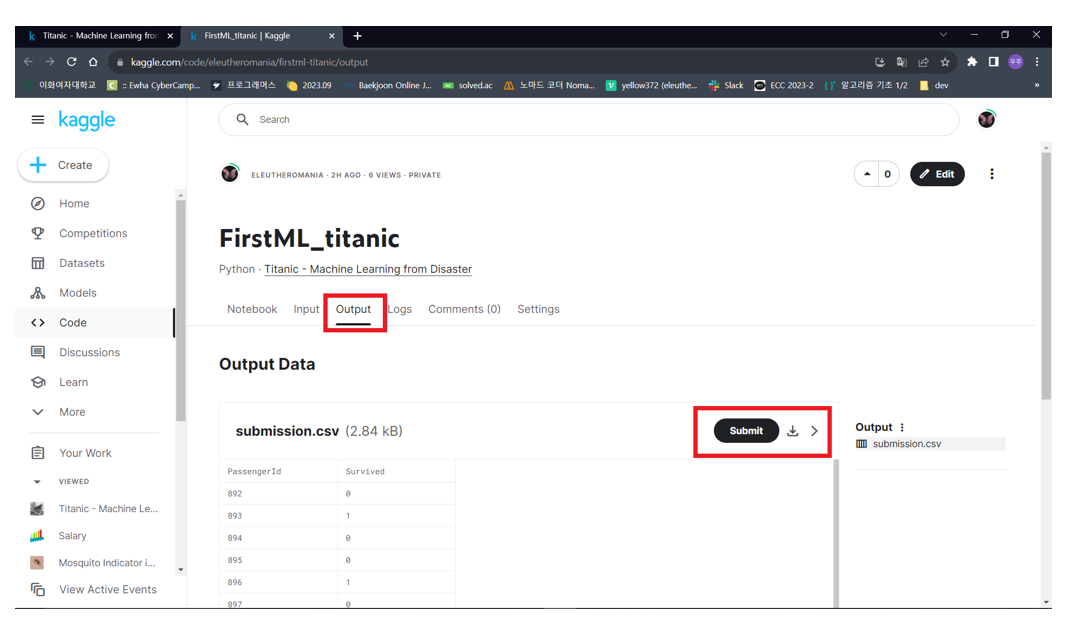
05. 캐글 필사 실습
- First Kaggle submit
titanic : Machine Learning from Distaster Competitions
- Submission
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")