
05. GBM(Gradient Boosting Machine)
부스팅 알고리즘
여러개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식
🅰 AdaBoost(Adaptive boosting)
🅱 Gradient Boost
- Ada boost
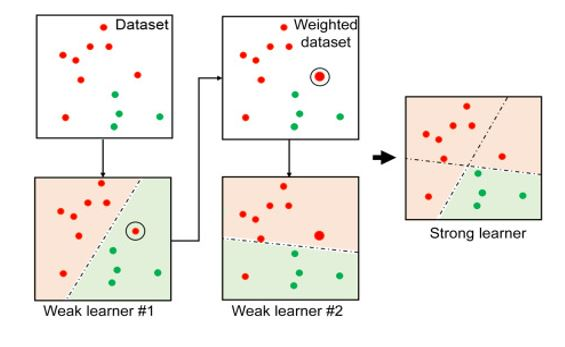
- 약한 학습기가 분류기준 1로 분류 시행
- 잘못된 분류된 오류 데이터에 대해 가중치 값을 부여
- 1-2과정을 반복
- 에이다 부스트는 약한 학습기가 순차적으로 오류값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행
- GBM
에이다부스트와 유사하나 가중치 업데이트를 경사하강법을 이용하는 것이 큰 차이
반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법
GBM이 랜덤 포레스트보다는 예측 성능이 뛰어남
GBM은 오래걸리고 하이퍼 파라미터 튜닝도력도 더 필요하다는 단점 있음.
- GBM 하이퍼 파라미터
loss : 손실 정도(평가 척도로 사용됨)
learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률
n_estimators : weak_learner의 개수
subsample: 약한 학습기가 학습에 사용하는 데이터 샘플링 비율06. XGBoost(eXtra Gradient Boost)
트리 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나
✔ 뛰어난 예측 성능
✔ GBM 대비 빠른 수행 시간
✔ 과적합 규제
✔ Tree pruning (나무 가지치기)
✔ 자체 내장된 교차 검증
✔ 결손값 자체 처리
오... 그냥 최강인데???
▶ 초기 독자적인 XGBoost 프레임워크 기반의 XGBoost를 파이썬 래퍼 XGBoost 모듈, 사이킷런과 연동되는 모듈을 XGBoost 모듈
- XGBoost 하이퍼 파라미터
일반 파라미터 디폴트 파라미터 값을 바꾸지 않는 기본 파라미터
부스터 파라미터 트리 최적화 부스팅과 관련 파라미터 등을 지정 (사전조작 파라미터)
학습 태스크 파라미터 학습 수행시 설정하는 파라미터 (학습 파라미터)
[주요 일반 파라미터]
booster
silent
nthread
[주요 부스터 파라미터]
eta[default=0.3, alias: learning_rate]
num_boost_rounds
min_child_weight[default=1]
gamma[default=0, alias: min_split_loss
max_depth[default=6]
sub_sample[default=1]
colsample_bytree[default=1]
lambda[default=1, alias: reg_lambda]
alpha[default=0, alias: reg_alpha]
scale_pos_weight[default=1]
[학습 태스크 파라미터]
objective
bianry:logistic
multi:softmax
multi:softprob
eval_metric과적합 해결 파라미터
- eta 값을 낮춘다 (eta 값 낮출 경우 num_round 값을 높여줘야 함
- max_depth 값을 낮춘다
- min_child_weight 값을 높인다
- gamma 값을 높인다
- subsample과 colsample_bytree를 조정
- 파이썬 래퍼 XGBoost 적용 - 위스콘신 유방암 예측
조기 중단
수행 속도를 향상시키기 위한 기능
예측 오류가 더이상 개선되지 않으면 반복을 끝까지 수행하지 않고 중지해 수행시간을 개선할 수 있음
(1) 조기중단을 수행하기 위해서는 별도의 검증용 데이터 필요
위스콘신 유방암 데이터 세트의 80%를 학습용, 20%를 테스트용으로 추출한 뒤 학습용 데이터에서 90% 최종 학습용, 10%를 검증용으로 분할
(2) DMatrix
학습용, 검증, 테스트용 데이터 세트를 모두 전용의 데이터 객체인 DMatrix로 생성
# 만약 구버전 XGBoost에서 DataFrame으로 DMatrix 생성이 안될 경우 X_train.values로 넘파이 변환
# 학습, 검증, 테스트용 DMatrix를 생성
dtr = xgb.DMatrix(data=X_tr, label=y_tr)
dval = xgb.DMatrix(data=X_val, label=y_val)
dtest = xgb.DMatrix(data=X_test, label= y_test)(3) 하이퍼 파라미터 설정
params = {'max_depth':3,
'eta': 0.05,
'objective': 'binary:logistic',
'eval_metric': 'logloss'
}
num_rounds = 400(4) 조기중단 수행
eval_metric 평가 지표(분류일 경우 logloss 적용)로 평가용 데이터 세트에서 예측 오류를 측정
#학습 데이터 셋은 'train' 또는 평가데이터 셋은 'eval'로 명기합니다.
eval_list = [(dtr,'train'),(dval, 'eval')] # 또는 eval_list = [(dval, 'eval')]만 명기해도 무방
#하이퍼 파라미터와 early stopping 파라미터를 train() 함수의 파라미터로 전달
xgb_model = xgb.train(params = params, dtrain=dtr, num_boost_round=num_rounds, early_stopping_rounds=50, evals=eval_list)[Output]
[0] train-logloss:0.65016 eval-logloss:0.66183
[1] train-logloss:0.61131 eval-logloss:0.63609
[2] train-logloss:0.57563 eval-logloss:0.61144
[3] train-logloss:0.54310 eval-logloss:0.59204
[4] train-logloss:0.51323 eval-logloss:0.57329
[5] train-logloss:0.48447 eval-logloss:0.55037
[6] train-logloss:0.45796 eval-logloss:0.52930
[7] train-logloss:0.43436 eval-logloss:0.51534
[8] train-logloss:0.41150 eval-logloss:0.49718
[9] train-logloss:0.39027 eval-logloss:0.48154
[10] train-logloss:0.37128 eval-logloss:0.46990
[11] train-logloss:0.35254 eval-logloss:0.45474
[12] train-logloss:0.33528 eval-logloss:0.44229
[13] train-logloss:0.31892 eval-logloss:0.42961
[14] train-logloss:0.30439 eval-logloss:0.42065
[15] train-logloss:0.29000 eval-logloss:0.40958
[16] train-logloss:0.27651 eval-logloss:0.39887
...- xgboost 모델 훈련
xgboost의 predict()는 예측 결괏값이 아닌 예측 결과를 추정할 수 있는 확률 값을 반환
예측 확률이 0.5보다 크면 1, 그렇지 않으면 0으로 예측값을 결정하는 로직을 추가하면 됨
pred_probs = xgb_model.predict(dtest)
print('predict() 수행 결괏값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10], 3))
#예측 확률이 0.5보다 크면 1, 그렇지 않으면 0으로 예측값 결정하여 lsit 객체인 preds에 저장
preds = [1 if x >0.5 else 0 for x in pred_probs]
print('예측값 10개만 표시:',preds[:10])[Output]
predict() 수행 결괏값을 10개만 표시, 예측 확률 값으로 표시됨
[0.845 0.008 0.68 0.081 0.975 0.999 0.998 0.998 0.996 0.001]
예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]- xgboost 시각화
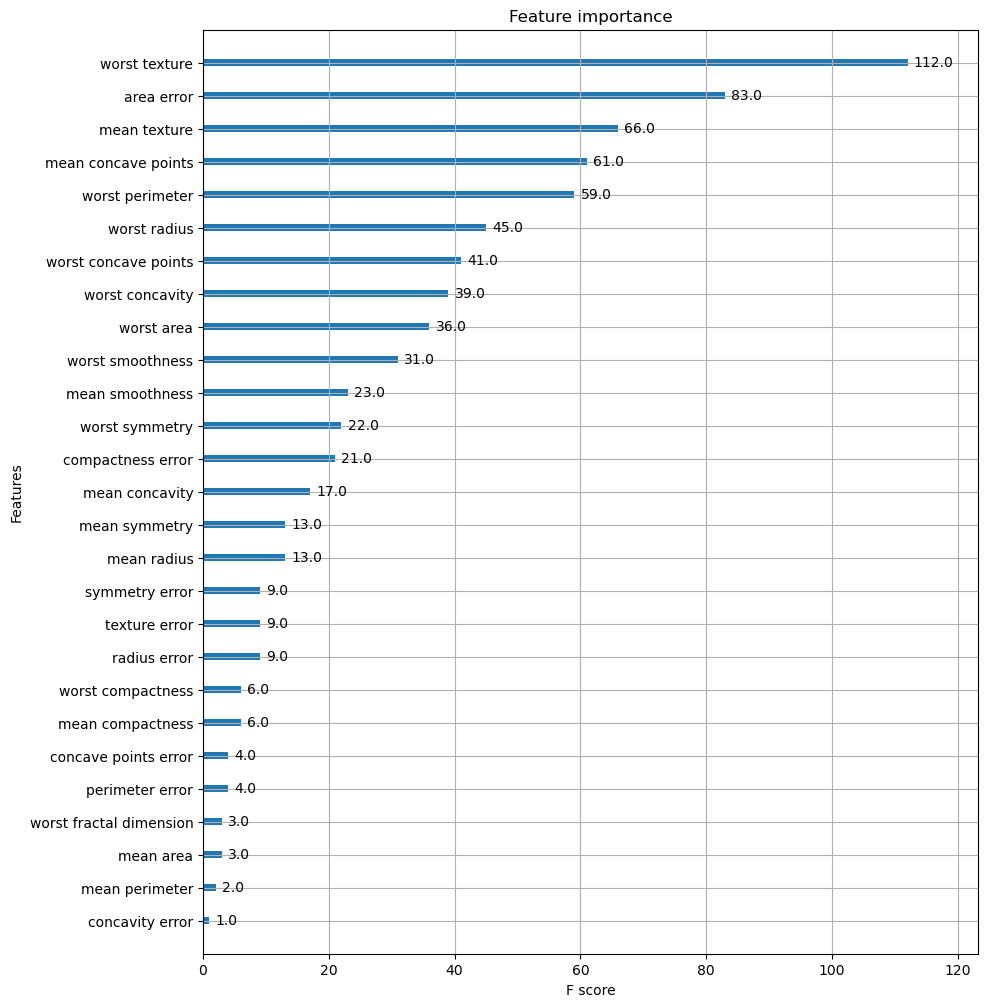
plot_importance() 해당 피처 중요도 그래프 시각화
f 스코어는 해당 피처가 트리 분할 시 얼마나 자주 사용되었는 지를 지표로 나타낸 값
- xgboost 최적 파라미터 구하기
cv() API를 통해 데이터 세트에 대한 교차 검증 수행후 최적 파라미터를 구할 수 있음
07. GBM(LightGBM)
LightGBM 가장 큰 장점은 XGBoost보다 학습에 걸리는 시간이 훨씬 적음. 메모리 사용량도 상대적으로 적음.
- 리프 중심 트리 분할
대부분 과적합을 방지하기 위해 균형 트리 분할 방식을 사용
LightGBM의 리프 중심 트리 분할 방식은 트리의 균형을 맞추지 않고, 최대 손실 값을 가지는 리프노드를 지속적으로 분할
→ 균형 트리분할 방식보다 예측 오류 손실 최소화 기대
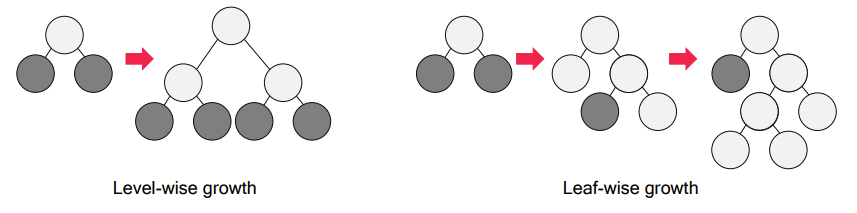
LightGBM의 XGBoost 대비 장점
- 더 빠른 학습과 예측 수행 시간
- 더 작은 메모리 사용량
- 카테고리형 피처의 자동 변환
- LightGBM 하이퍼 파라미터
[주요 파라미터]
num_iterations : 반복수행하려는 트리 개수 지정
learning_rate : 업데이트 되는 학습률 값
max_depth
min_data_leaf
num_leaves : 하나의 트리가 가질 수 있는 최대 리프 개수
boosting
bagging_fraction : 데이터를 샘플링하는 비율 지정
feature_fraction : 무작위로 선택하는 피처 비율
lambda_l2 : L2 regulation 제어를 위한 값
lambda_l1 : L1 regulation 제어를 위한 값
[Learning Task 파라미터]
objective : 최솟값을 가져야 할 손실 함수 정의과적합 방지 파라미터
num_leaves최대 리프 개수 제한min_child_samplesmat_depth명시적으로 깊이 크기를 제한
파이썬 래퍼 LightGBM과 사이킷런 래퍼 XGBoost, LightGBM 하이퍼 파리미터 비교
<표 사진>
- LightGBM 적용 - 위스콘신 유방암 예측
# LighttGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier 임포트
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
cancer_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
cancer_df['target']=dataset.target
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:,-1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test = train_test_split(X_features, y_label, test_size=0.2, random_state=156)
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=156)
# 앞서 XGBoost와 동일하게 n_estimators는 400 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400, learning_rate=0.05)
# LightGBM도 XGBoost와 동일하게 조기중단 수행 가능
evals = [(X_tr, y_tr), (X_val, y_val)]
lgbm_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric="logloss", eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:,1][Output]
[1] training's binary_logloss: 0.625671 valid_1's binary_logloss: 0.628248
[2] training's binary_logloss: 0.588173 valid_1's binary_logloss: 0.601106
[3] training's binary_logloss: 0.554518 valid_1's binary_logloss: 0.577587
[4] training's binary_logloss: 0.523972 valid_1's binary_logloss: 0.556324
[5] training's binary_logloss: 0.49615 valid_1's binary_logloss: 0.537407
[6] training's binary_logloss: 0.470108 valid_1's binary_logloss: 0.519401
[7] training's binary_logloss: 0.446647 valid_1's binary_logloss: 0.502637
[8] training's binary_logloss: 0.425055 valid_1's binary_logloss: 0.488311
[9] training's binary_logloss: 0.405125 valid_1's binary_logloss: 0.474664
[10] training's binary_logloss: 0.386526 valid_1's binary_logloss: 0.461267LightGBM도 조기 중단이 가능하다
08. 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝
지금까지는 하이퍼 파라미터 튜닝을 위해 사이킷런에서 제공하는 Grid Search 방식을 적용
- 베이지안 최적화 개요
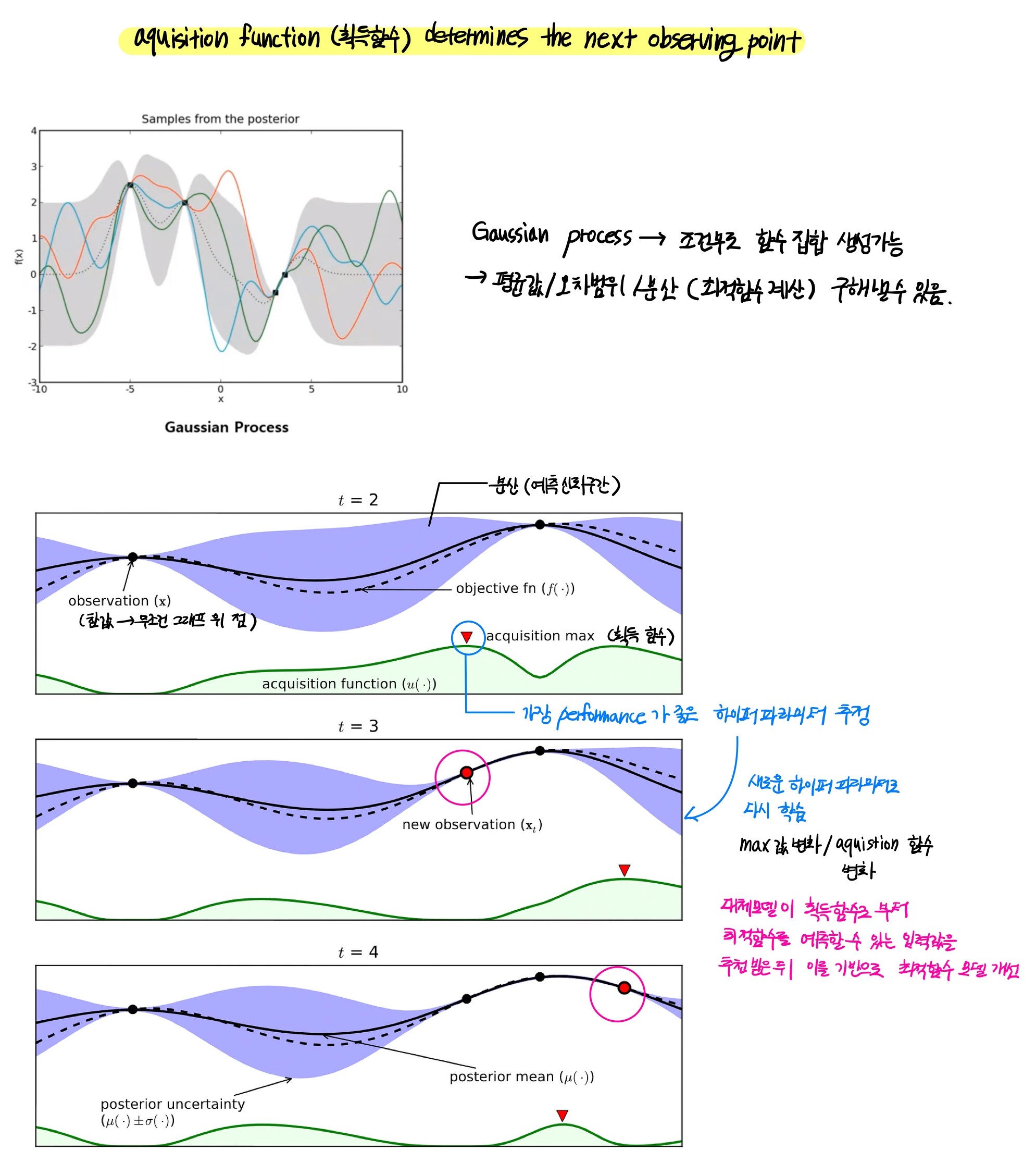
베이지안 최적화는 목적함수 식을 제대로 알 수 없는 블랙 박스 형태의 함수에서 (최종 함수를 모름) 최대 또는 최소 함수 반환 값을 만드는 최적 입력값을 가능한 적은 시도를 통해 빠르고 효과적으로 찾아주는 방식
베이지안 최적화
베이지안 확률에 기반을 두고 있는 최적화 기법.
대체 모델은 획득 함수로부터 최적함수를 예측할 수 있는 입력값을 추천받은 뒤 이를 기반으로 최적 함수 모델을 개선해 나가며, 획득함수는 개선된 예측할 수 있는 입력값을 추천받은 뒤 이를 기반으로 최적 입력값을 계산
- HyperOpt 사용하기
HyperOpt 주요 로직 ⭐
1. 입력 변수명과 입력값의 검색공간 설정
2. 목적함수의 설정
3. 목적함수의 반환 최솟값을 가지는 최저 입력값을 유추하는 것
(1) 입력 변수명과 입력값의 검색공간 설정
{'입력변수명': hp.quniform(label, low, high, q)}
from hyperopt import hp
# -10 ~ 10까지 1간격을 가지는 입력 변수 X와 -15~15까지 1간격으로 입력 변수 y 설정
search_space ={'x':hp.quniform('x', -10, 10, 1), 'y':hp.quniform('y', -15, 15, 1)}(2) 목적 함수를 생성
목적함수는 딕셔너리를 인자로 받고, 특정 값을 반환하는 구조
from hyperopt import STATUS_OK
# 목적 함수를 생성, 변숫값과 변수 검색 공간을 가지는 딕셔너리를 인자로 받고, 특정 값을 반환
def objective_func(search_space):
x= search_space['x']
y= search_space['y']
retval = x**2 - 20*y
return retval반환값이 최소가 될 수 있는 최적의 입력값을 찾아야 됨
📌 fmin()
fmin(objective, space, algo, max_evals, trials)
space : 검색 공간 딕셔너리
algo : 베이지안 최적화 적용 알고리즘
max_evals : 입력값 시도 횟수
trials : (중요) 최적 입력값을 찾기 위해 시도한 입력값 및 해당 입력값의 목적 함수 반환값 결과를 저장하는 데 사용됨✔ Trials 객체
results과 val 속성 가짐
results, vals 속성을 통해 HyperOpt의 fmin() 함수의 수행 시마다 최적화되는 경과를 볼 수 있는 함수 반환값과 입력 변수값들의 정보를 제공
-
results
results는 반복 수행 시마다 반환
{'loss': 함수 반환값, 'status': 반환 상태값} -
vals
함수의 반복 수행시마다 입력되는 입력 변수값을 가짐
{'입력변수명': 개별 수행시마다 입력된 값 리스트}
- HyperOpt를 이용한 XGBoost 하이퍼 파라미터 최적화
앞과 다르게 목적함수에서 XGBoost를 학습시키는 차이점
주의해야될 부분
- 검색 공간에서 목적 함수로 입력되는 목적 인자들은 실수형 값이므로 이들을 XGBoostClassifier의 정수형 하이퍼 파라미터 값으로 설정할 때는 정수형으로 형변환
- HyperOpt의 목적함수는 최솟값을 반환할 수 있도록 최적화해야 하기 때문에 정확도와 같이 값이 클수록 좋은 성능 지표일 경우 -1을 곱한 뒤 반환
(1) Objective func() 만들기
from sklearn.model_selection import cross_val_score
from xgboost import XGBClassifier
from hyperopt import STATUS_OK
# fmin()에서 입력된 search_space 값으로 입력된 모든 값은 실수형임.
# XGBClassifier의 정수형 하이퍼 파라미터는 정수형 변환을 해줘야 함.
# 정확도는 높을수록 더 좋은 수치임. -1 * 정확도를 곱해서 큰 정확도 값일수록 최소가 되도록 변환
def objective_func(search_space):
# 수행 시간 절약을 위해 nestimators는 100으로 축소
xgb_clf = XGBClassifier(n_estimators=100, max_depth=int(search_space['max_depth']),
min_child_weight=int(search_space['min_child_weight']),
learning_rate=search_space['learning_rate'],
colsample_bytree=search_space['colsample_bytree'],
eval_metric='logloss')
accuracy = cross_val_score(xgb_clf, X_train, y_train, scoring='accuracy', cv=3)
# accuracy는 cv=3 개수만큼 roc-auc 결과를 리스트로 가짐. 이를 평균해서 반환하되 -1을 곱함.
return {'loss':-1 * np.mean(accuracy), 'status': STATUS_OK}(2) fmin()을 이용해 최적 하이퍼 파라미터 도출
from hyperopt import fmin, tpe, Trials
trial_val = Trials()
best = fmin(fn=objective_func,
space=xgb_search_space,
algo=tpe.suggest,
max_evals=50, # 최대 반복 횟수를 지정합니다.
trials=trial_val, rstate=np.random.default_rng(seed=9))
print('best:', best)(3) 도출된 최적 하이퍼 파라미터들을 이용해 XGBClassifier 재학습
xgb_wrapper = XGBClassifier(n_estimators=400,
learning_rate=round(best['learning_rate'], 5),
max_depth=int(best['max_depth']),
min_child_weight=int(best['min_child_weight']),
colsample_bytree=round(best['colsample_bytree'], 5)
)
evals = [(X_tr, y_tr), (X_val, y_val)]
xgb_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric='logloss',
eval_set=evals, verbose=True)
preds = xgb_wrapper.predict(X_test)
pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
get_clf_eval(y_test, preds, pred_proba)[Output]
[0] validation_0-logloss:0.58942 validation_1-logloss:0.62048
[1] validation_0-logloss:0.50801 validation_1-logloss:0.55913
[2] validation_0-logloss:0.44160 validation_1-logloss:0.50928
[3] validation_0-logloss:0.38734 validation_1-logloss:0.46815
[4] validation_0-logloss:0.34224 validation_1-logloss:0.43913
[5] validation_0-logloss:0.30425 validation_1-logloss:0.41570
[6] validation_0-logloss:0.27178 validation_1-logloss:0.38953
[7] validation_0-logloss:0.24503 validation_1-logloss:0.37317
[8] validation_0-logloss:0.22050 validation_1-logloss:0.35628
[9] validation_0-logloss:0.19873 validation_1-logloss:0.33798
[10] validation_0-logloss:0.17945 validation_1-logloss:0.32463
[11] validation_0-logloss:0.16354 validation_1-logloss:0.31384
[12] validation_0-logloss:0.15032 validation_1-logloss:0.3060711. 스태킹 앙상블
Stacking 앙상블
개별 모델로 예측한 결과를 기반으로 다시 최종 예측을 수행하는 방식
다른 앙상블과의 차이점
여러 개별 모델들의 예측 결과를 학습해서 최종 결과를 도출하는 meta 모델
- 구조
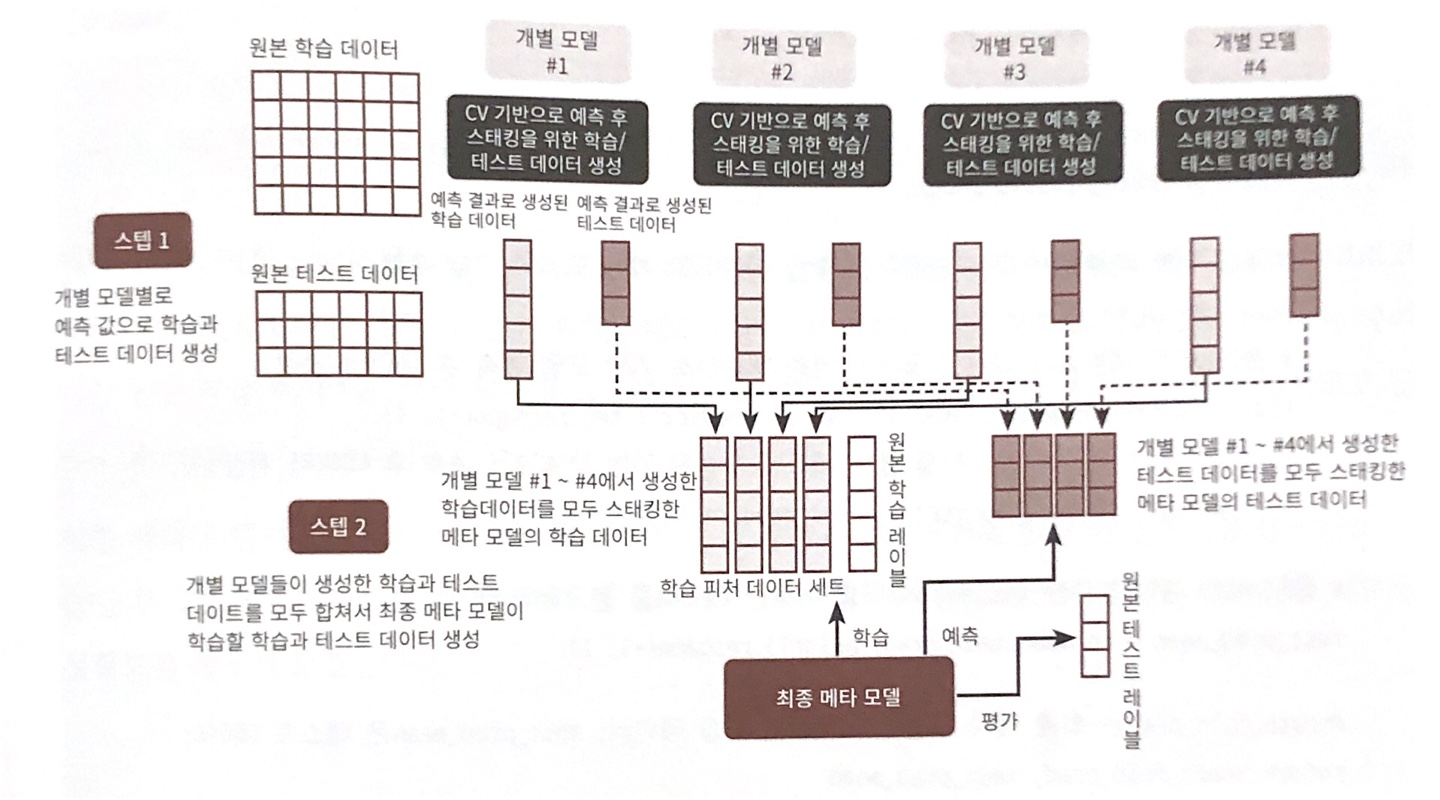
개별 base 모델
최종 meta 모델 : 개별 base 모델의 예측 결과를 학습해 최종 결과를 냄
-> 이때, 개별 모델의 예측 결과를 stacking 형태로 결합해서, 최종 meta 모델의 입력으로 사용
- CV set 기반 Stacking
1) Step 1 : 개별 base 모델 학습, 예측값 도출
학습 데이터를 K개의 fold로 나눔
K-1 개의 fold를 학습 데이터로 하여 base 모델 학습 (K번 반복)
검증 fold 1개를 예측한 결과 (K fold) -> 최종 meta 모델의 학습용 데이터
테스트 데이터를 예측한 결과 (K개) 의 평균 -> 최종 meta 모델의 테스트용 데이터
2) Step 2 : 최종 meta 모델 학습
각 base 모델이 생성한 학습용 데이터를 stacking -> 최종 meta 모델의 학습용 데이터 세트
각 base 모델이 생성한 테스트용 데이터를 stacking -> 최종 meta 모델의 테스트용 데이터 세트
최종 학습용 데이터 + 원본 학습 레이블 데이터로 학습
최종 테스트용 데이터로 예측 -> 원본 테스트 레이블 데이터로 평가
