캐글 산탄데르 고객 만족 예측
downloads
- Santnadler Customer Satisfaction
Santnadler Customer Satisfaction
데이터 전처리
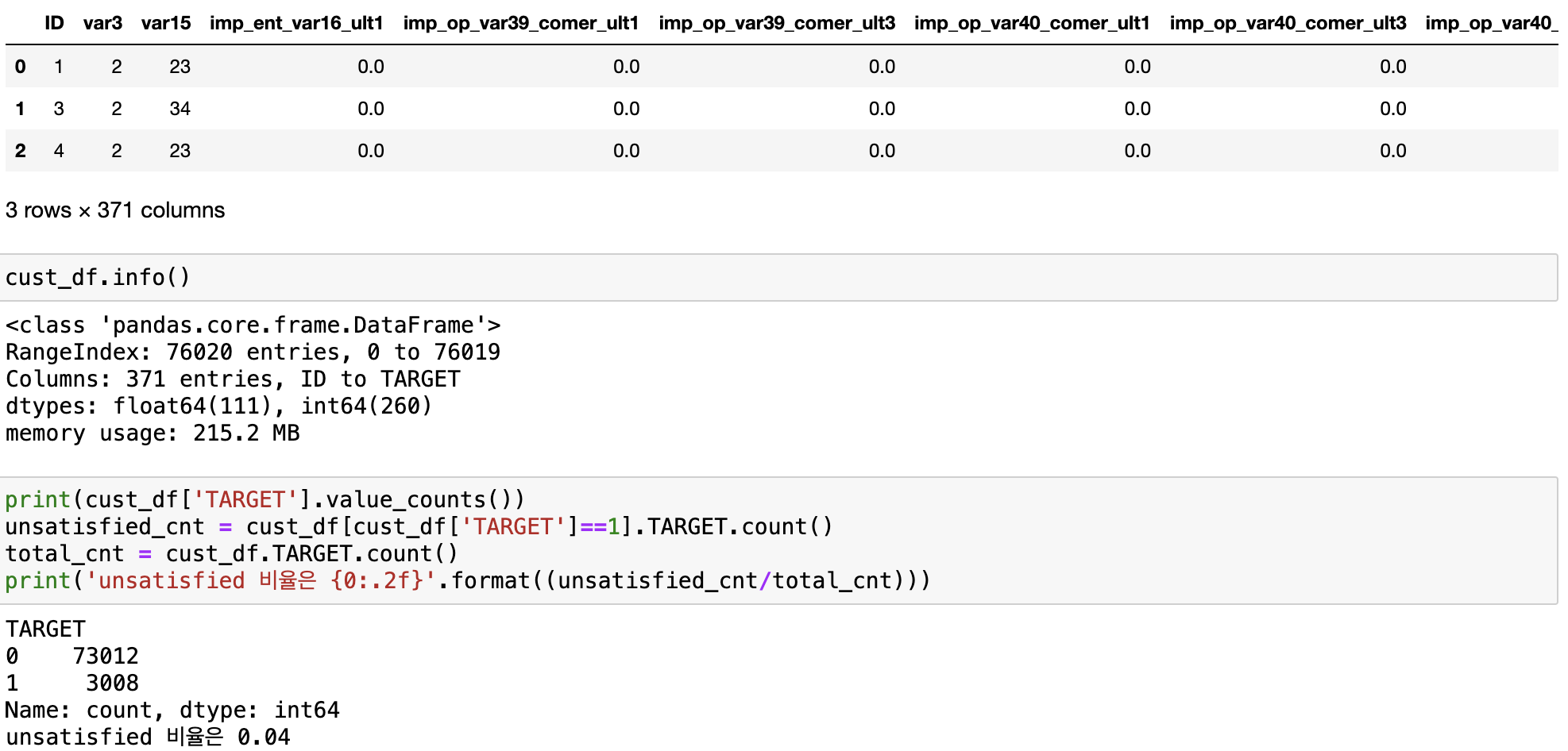
111개의 피처가 float형, 260개의 피처가 int 형으로 모든 피처가 숫자형이며, Null 값은 없다. 레이블 Target에서 대부분이 만족이며 불만족인 고객은 4%에 불과한다.
min값의 -999999을 최다값 2로 변환하고 ID 피처는 단순 식별자이므로 피처를 드롭한다.
- 테스트 세트와 훈련세트 분리 및 검증 세트 생성
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels, test_size=0.2, random_state=0)
train_cnt = y_train.count()
test_cnt = y_test.count()
print('학습 세트 Shape:{0}, 테스트 세트 Shape:{1}'.format(X_train.shape, X_test.shape))
print('학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n테스트 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)
#XGBoost 조기중단을 위해 검증 세트 분리
#X_train, y_train을 다시 학습과 검증 데이터 세트로 분리
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size = 0.3, random_state=0)XGBoost 모델 학습과 하이퍼 파라미터 튜닝
- XGBoost 모델 학습
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
#n_estimators는 500으로, random state는 예제 수행 시마다 동일 예측 결과를 위해 설정
xgb_clf = XGBClassifier(n_estimators=500, learning_rate=0.05, random_state =156)
#성능 평가 지표를 auc로ㅡ 조기 중단 파라미터는 100으로 설정하고 학습 수행
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric="auc", eval_set = [(X_tr, y_tr), (X_val, y_val)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))[Output]
ROC AUC: 0.8429- HyperOpt를 이용해 하이퍼 파라미터 튜닝 수행
- 목적 함수 생성
3 Fold 교차 검증을 이용해 평균 ROC-AUC 값 반환 (-1*ROC-AUC)
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
# fmin()에서 호출시 search_space 값으로 XGBClassifier 교차 검증 학습 . 후 -1*roc_auc 평균 값을 반환
# 목적 함수
def objective_func(search_space):
xgb_clf = XGBClassifier(n_estimators=100, max_depth=int(search_space['max_depth']),
min_child_weight= int(search_space['min_child_weight']),
colsample_bytree = search_space['colsample_bytree'],
learning_rate = search_space['learning_rate'])
#3개 k-fold 방식으로 평가된 roc_auc 지표를 담는 list
roc_auc_list = []
#3개 k-fold 방식 적용
kf = KFold(n_splits=3)
# Xtrain을 다시 학습과 검증용 데이터로 부닐
for tr_index, val_index in kf.split(X_train):
#kf.split(X_train)으로 추출된 학습과 검증 index 값으로 학습과 검증 데이터 세트 분리
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
#early stopping은 30회로 설정하고 추출된 학습과 검증 데이터로 XGBClassifier 학습 수행
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_tr, y_tr), (X_val, y_val)])
#1로 예측한 확률값 추출 후 roc auc 계산하고 평균 roc auc 계산을 위해 List에 결괏값 담음.
score = roc_auc_score(y_val, xgb_clf.predict_proba(X_val)[:,1])
roc_auc_list.append(score)
# 3개 k-fold로 계산된 roc auc 값의 평균값을 반한하되,
# HyperOpt는 목적함수의 최솟값을 위한 입력값을 찾으므로 -1을 곱한 뒤 반환
return -1*np.mean(roc_auc_list)
from hyperopt import fmin, tpe, Trials
trials = Trials()
# fmin() 함수를 호출. max_evals 지정된 횟수만큼 반복 후 목적함수의 최솟값을 가지는 최저 입력값 추출.
# 입력 파라미터로 최저 입력값을 추출하는 fmin
best = fmin(fn=objective_func,
space = xgb_search_space,
algo = tpe.suggest,
max_evals = 50, #최대 반복 횟수를 지정합니다
trials = trials, rstate = np.random.default_rng(seed=30))
print('best:', best)
#30분 소요...목적 반환 최솟값을 가지는 최저 입력값 유추
- 찾은 하이퍼 파라미터로 XGBClassifier 재학습
#n_estimators를 500 증가 후 최적으로 찾은 하이퍼 파라미터를 기반으로 학습과 예측 수행
xgb_clf = XGBClassifier(n_estimators=500, learning_rate = round(best['learning_rate'], 5),
max_depth = int(best['max_depth']), #각 하이퍼 파라미터에 최저 입력값(best[] list) 넣기
min_child_weight=int(best['min_child_weight']),
colsample_bytree = round(best['colsample_bytree'], 5)
)
#evaluation metric을 auc로, early stopping은 100으로 설정하고 학습 수행
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=100,
eval_metric="auc", eval_set=[(X_tr, y_tr), (X_val, y_val)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:4f}'.format(xgb_roc_score))LightGBM 모델 학습과 하이퍼 파라미터 튜닝
- LightGBM 모델 학습
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators = 500)
eval_set = [(X_tr, y_tr), (X_val, y_val)]
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric="auc", eval_set= eval_set)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1])
print('ROC AUC:{0:.4f}'.format(lgbm_roc_score))- HyperOpt를 이용해 하이퍼 파라미터 튜닝
lgbm_search_space = {'num_leaves' :hp.quniform('num_leaves', 32, 64, 1),
'max_depth':hp.quniform('max_depth', 100, 160, 1),
'min_child_samples':hp.quniform('min_child_samples', 60, 100,1),
'subsample': hp.uniform('subsample', 0.7, 1),
'learning_rate': hp.uniform('learning_rate', 0.01, 0.2)}
def objective_func(search_space):
lgbm_clf = LGBMClassifier(n_estimators=100,
num_leaves = int(search_space['num_leaves']),
max_depth = int(search_space['max_depth']),
min_child_samples = int(search_space['min_child_samples']),
subsample = search_space['subsample'],
learning_rate = search_space['learning_rate'])
#3개 k-fold 방식으로 평가된 roc_auc 지표를 담는 list
roc_auc_list = []
#3개 k-fold 방식 적용
kf = KFold(n_splits=3)
#X_train을 다시 학습과 검증용 데이터로 분리
for tr_index, val_index in kf.split(X_train):
#kf.split(X_tain)으로 추출된 학습과 검증 index 값으로 학습과 검증 데이터 세트 분리
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
#early stopping은 30회로 설정하고 추출된 학습과 검증 데이터로 XGBClassifer 학습 수행
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric="auc",
eval_set = [(X_tr, y_tr), (X_val, y_val)])
# 1로 예측한 확률값 추출 후 roc auc 계산하고 평균 roc auc 계산을 위해 list에 결괏값 담음.
score = roc_auc_score(y_val, lgbm_clf.predict_proba(X_val)[:,1])
roc_auc_list.append(score)
#3개 k-fold로 계산된 roc_auc 값의 평균값을 반한하되,
#HyperOpt는 목적함수의 최솟값을 위한 입력값을 찾으므로 -1을 곱한뒤 반환.
return -1*np.mean(roc_auc_list)(최적 하이퍼 파라미터로 ROC-AUC 평가 생략)
[Output]
ROC AUC : 0.8446XGBoost와 유사한 결과를 보임. LightGBM의 학습 시간이 XGBoost보다 빠르기 때문에 LightGBM으로 훈련 필요.
캐글 신용카드 사기 검출
downloads
- Credit Card Fraud Detection
언더 샘플링과 오버 샘플링
이상 데이터 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터
이상 레이블을 가지는 데티터 건수는 매우 적기 때문에 제대로 다양한 유형 학습을 못하고 정상 레이블로 치우친 학습을 수행해 제대로 된 이상 데이터 검출이 어려워짐
(평균치로 훈련된 모델은 이상 데이터 검출이 어렵다)
언더 샘플링 많은 데이터 세트를 적은 데이터 세트 수준으로 감소시키는 방식
과도하게 정상레이블로 학습/예측하는 부작용을 개선할 수 있지만, 제대로 된 학습을 수행할 수없는 문제도 발생 가능성
오버 샘플링 이상 데이터와 같이 적은 데이터 세트를 증식하여 학습을 위한 충분한 데이터를 확보하는 방법. 과적합 되기 때문에 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식.
SMOTE (오버샘플링) k-최근접 이웃에서 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터들을 생성하는 방식
데이터 일차 가공 및 모델 학습/예측/평가
- 훈련 세트와 테스트 세트 분리
테스트 세트를 전체의 30%인 Stratified 방식으로 추출해 학습 데이터 세트와 테스트 데이터 세트의 레이블 값 분포도를 서로 동일하게 만듦.
Stratified Sampling
임의 추출은 데이터 비율을 반영하지 못한다는 단점이 있어, 계층 추출이 권장됨
ex) StratifiedShuffleSplit(), StratifiedKFold(), train_test_split()
# 사전 데이터 가공 후 학습과 테스트 데이터 세트를 반환하는 함수
def get_train_test_dataset(df=None):
#인자로 입력된 DataFrame의 사전 데이터 가공이 완료된 복사 DataFrame 반환
df_copy = get_preprocessed_df(df)
#DataFrame의 맨 마지막 칼럼이 레이블, 나머지 피처들
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:,-1]
#train_test_split()으로 학습과 테스트 데이터 분할. stratify=y_target으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(X_features, y_target, test_size =0.3, random_state =0, stratify = y_target)
#학습과 테스트 데이터 세트 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)- Logistic 회귀와 LightGBM 훈련
1) Logistic
[Output]
오차 행렬
[[85281 14]
[ 58 90]]
정확도: 0.9992, 정밀도: 0.8654, 재현율: 0.6081, F1:0.7143, AUC:0.9703
2) LightGBM
[Output]
오차 행렬
[[85281 14]
[ 58 90]]
정확도: 0.9992, 정밀도: 0.8654, 재현율: 0.6081, F1:0.7143, AUC:0.9703
LightGBM이 로지스틱 회귀보다 높은 수치를 나타냄.
데이터 분포도 변환 후 모델 학습/예측/평가
로지스틱 회귀와 같이 선형 모델은 중요 피처들의 값이 정규 분포 형태를 유지하는 것을 선호
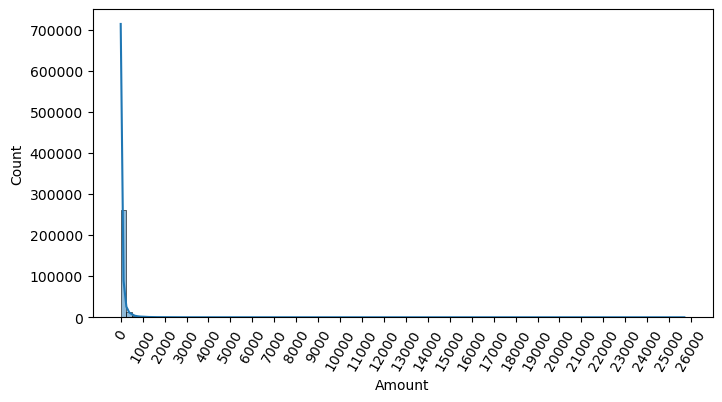
- Amount를 표준 정규 분포 형태로 변환
Amount feature 분포도
from sklearn.preprocessing import StandardScaler
# 사이킷런의 StandardScaler를 이용하여 정규분포 형태로 Amount 피처값 변환하는 로직으로 수정.
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
# 데이터 정규화
amount_n = scaler.fit_transform(df_copy['Amount'].values.reshape(-1, 1))
# 변환된 Amount를 Amount_Scaled로 피처명 변경후 DataFrame맨 앞 컬럼으로 입력
df_copy.insert(0, 'Amount_Scaled', amount_n)
# 기존 Time, Amount 피처 삭제
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
return df_copy- 로그 변환
loglp()
로그 변환은 데이터 분포도가 심하게 왜곡되어 있을 경우 적용하는 중요 기법 중 하나
def get_preprocessed_df(df=None):
df_copy = df.copy()
# 넘파이의 log1p( )를 이용하여 Amount를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
return df_copy레이블이 극도로 불균일한 데이터 세트에서 로지스틱 회귀는 데이터 변환 시 약간은 불안정한 성능 결과를 보여줌
✅ 이상치 데이터 제거 후 모델 학습/예측/평가
- IQR(Inter Quantile Range)
사분위 값의 편차를 이용하는 기법
25% 구간인 Q1 ~ 75% 구간인 Q3의 범위를 IQR라고 함.
-
이상의 데이터 범위를 벗어난 데이터를 이상치로 간주
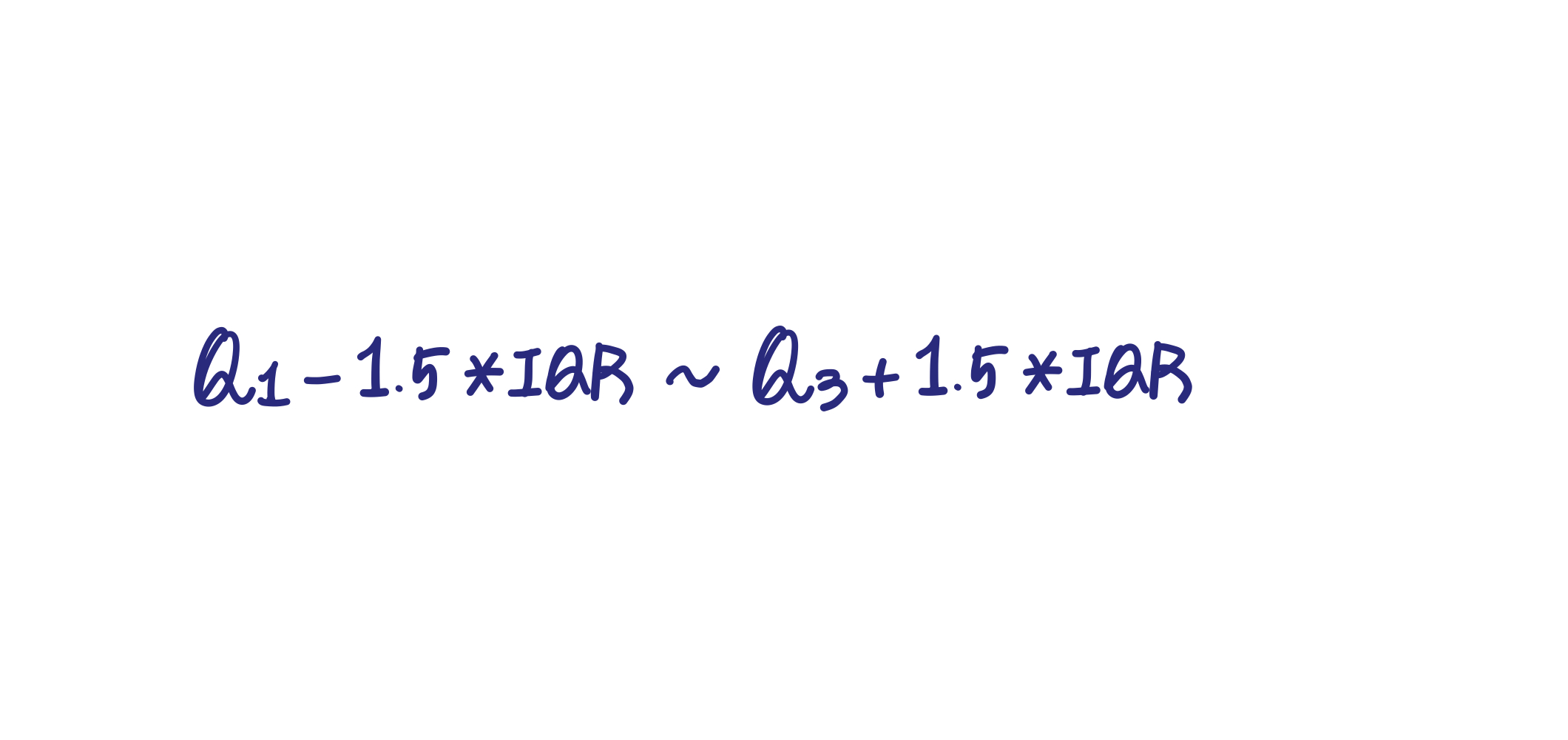
-
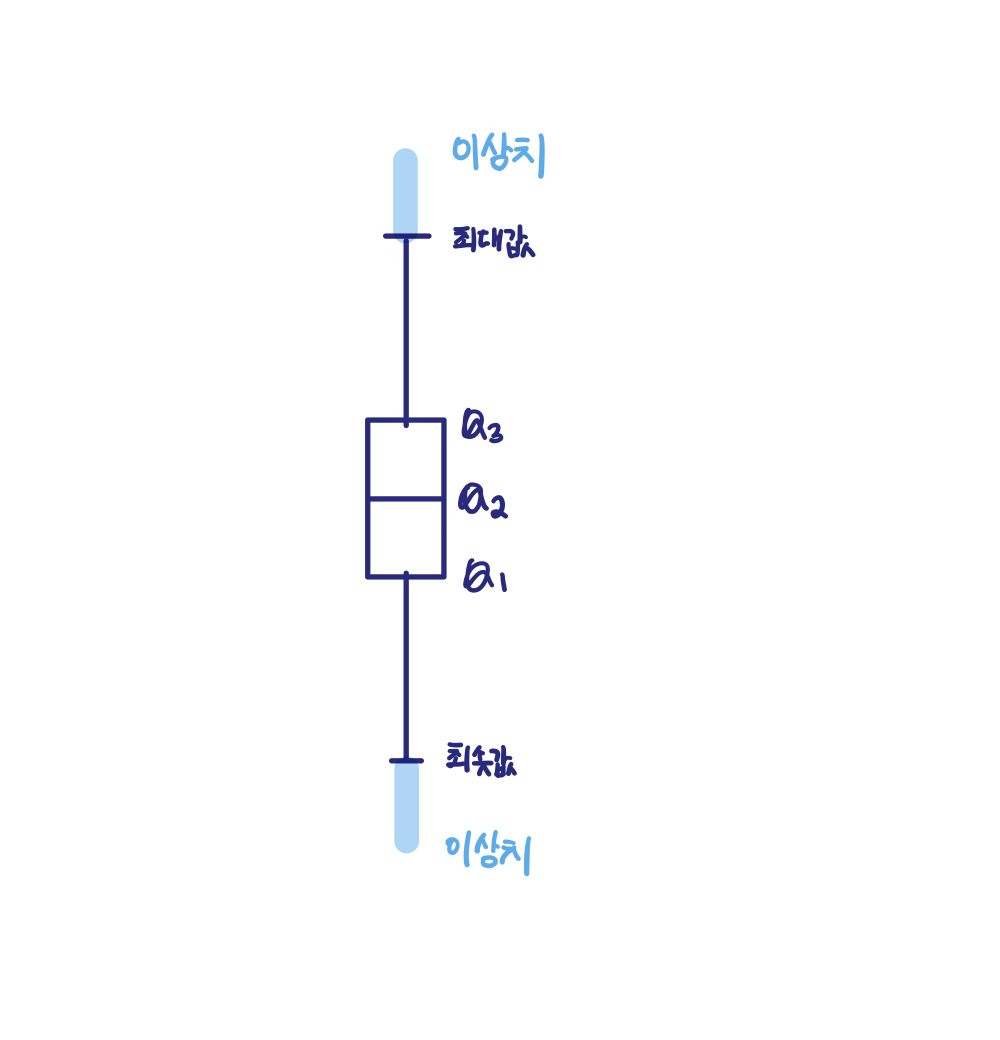
IQR 방식을 시각화한 도표가 박스 플롯
- IQR 적용
-
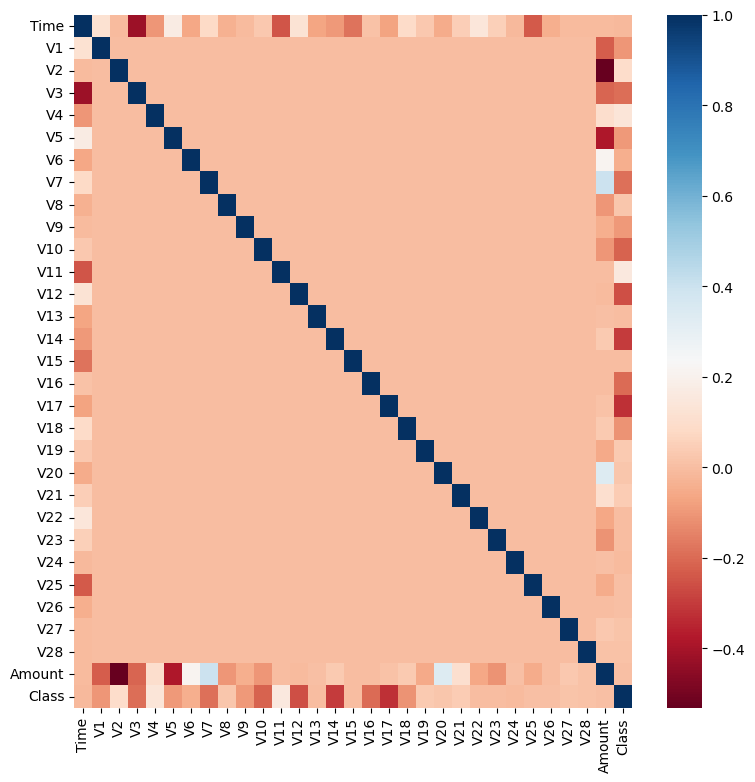
먼저 어떤 피처의 이상치 데이터를 검출할 것인지 선택이 필요
결정값과 가장 상관성이 높은 피처들을 위주로 이상치를 검출하는 것이 좋음
-
V14에 대한 이상치를 찾아 제거
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
# fraud에 해당하는 column 데이터만 추출, 1/4 분위와 3/4 분위 지점을 np.percentile로 구함.
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index- 이상치를 추출하고 삭제하는 로직 추가
# get_processed_df( )를 로그 변환 후 V14 피처의 이상치 데이터를 삭제하는 로직으로 변경.
def get_preprocessed_df(df=None):
df_copy = df.copy()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
# 이상치 데이터 삭제하는 로직 추가
outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)이상치 데이터를 제거한 뒤, 로지스틱 회귀와 LightGBM 모두 예측 성능이 크게 향상
SMOTE 오버 샘플링 적용 후 모델 학습/예측/평가
반드시 학습 데이터 세트만 오버 샘플링을 해야 됨.
검증/테스트 세트에 적용시 올바른 검증/테스트가 될 수 없음.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
print('SMOTE 적용 전 학습용 피처/레이블 데이터 세트: ', X_train.shape, y_train.shape)
print('SMOTE 적용 후 학습용 피처/레이블 데이터 세트: ', X_train_over.shape, y_train_over.shape)
print('SMOTE 적용 후 레이블 값 분포: \n', pd.Series(y_train_over).value_counts())- 재현율/정밀도
너무나 많은 Class=1 데이터를 학습하면서 실제 테스트 데이터 세트에서 예측을 지나치게 Class=1로 적용해 정밀도가 급격히 떨어지게 됨.
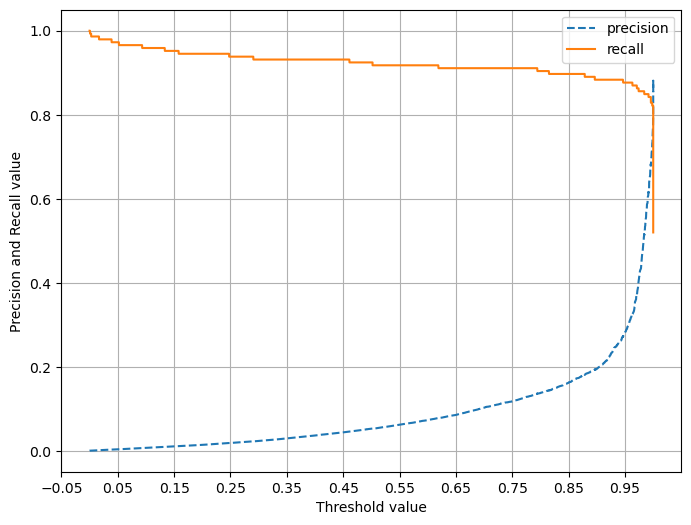
재현율 지표를 높이는 것이 머신러닝 모델의 주요한 목표일 경우 SMOTE를 적용하면 좋음.
Mechanisms of Action (MoA)
downloads
- Mechanisms of Action
- zip 파일 업로드 및 압축 해제
import zipfile as zf
files = zf.ZipFile("lish-moa.zip", 'r')
files.extractall("MoA")
files.close()- category_encoders 설치
pip install category_encoders데이터 전처리
- Framing as a binary classification problem
SEED = 42
NFOLDS = 5
DATA_DIR = './MoA/'
np.random.seed(SEED)- 훈련 세트와 테스트 세트로 나누기
train = pd.read_csv(DATA_DIR + 'train_features.csv')
targets = pd.read_csv(DATA_DIR + 'train_targets_scored.csv')
test = pd.read_csv(DATA_DIR+'test_features.csv')
sub = pd.read_csv(DATA_DIR+'sample_submission.csv')
#drop id col
X = train.iloc[:, 1:].to_numpy()
X_test = test.iloc[:, 1:].to_numpy()
y = targets.iloc[:, 1:].to_numpy()- MultiOutputClassifier
classifier = MultiOutputClassifier(XGBClassifier(tree_method='gpu_hist'))
clf = Pipeline([('encode', CountEncoder(cols=[0, 2])),
('classify', classifier)
])- XGBClassifier 하이퍼 파리미터 설정
params = {'classify__estimator__colsample_bytree': 0.6522,
'classify__estimator__gamma': 3.6975,
'classify__estimator__learning_rate': 0.0503,
'classify__estimator__max_delta_step': 2.0706,
'classify__estimator__max_depth': 10,
'classify__estimator__min_child_weight': 31.5800,
'classify__estimator__n_estimators': 166,
'classify__estimator__subsample': 0.8639
}
_ = clf.set_params(**params)MultiOutputClassifier로 훈련
- kfold 교차 검증
oof_preds = np.zeros(y.shape) #OOF, Out of folds
test_preds = np.zeros((test.shape[0], y.shape[1]))
oof_losses = []
kf = KFold(n_splits = NFOLDS)
#5개 k-fold 방식 적용
for fn, (trn_idx, val_idx) in enumerate(kf.split(X, y)):
print('Starting fold: ', fn)
#kf.split으로 추출된 학습과 검증 index값으로 학습과 검증 데이터 세트 분리
X_train, X_val = X[trn_idx], X[val_idx]
y_train, y_val = y[trn_idx], y[val_idx]
#drop where cp_type==ct1_vehichle (baseline)
ct1_mask = X_train[:, 0] == 'ct1_vehicle'
X_train = X_train[~ct1_mask, :]
y_train = y_train[~ct1_mask]
#MultiOutputClassifier 학습 수행
clf.fit(X_train, y_train)
val_preds = clf.predict_proba(X_val) #list of preds per class
val_preds = np.array(val_preds)[:,:,1].T #take the positive class
oof_preds[val_idx] = val_preds
loss = log_loss(np.ravle(y_val), np.ravel(val_preds))
oof_losses.append(loss)
preds = clf.predict_proba(X_test)
preds = np.array(preds)[:,:,1].T #take the postiive class
test_preds += preds / NFOLDS
print(oof_losses)
print('Mean OOF loss across folds', np.mean(oof_losses))
print('STD OOF loss across folds', np.std(oof_losses))
[Output]
Starting fold: 0
Starting fold: 1
Starting fold: 2
Starting fold: 3
Starting fold: 4
[0.0169781773377249, 0.01704491710861325, 0.016865153552168475, 0.01700900926983899, 0.01717882474706338]
Mean OOF loss across folds 0.017015216403081797
STD OOF loss across folds 0.00010156682747757948- log_loss 출력
# set control train preds to 0
control_mask = train['cp_type']=='ctl_vehicle'
oof_preds[control_mask] = 0
print('OOF log loss: ', log_loss(np.ravel(y), np.ravel(oof_preds)))Analysis of OOF preds
- submission.csv 생성
# set conrol test pres to 0
control_mask = test['cp_type'] == 'ctl_vehicle'
test_preds[control_mask] = 0
#create the submission file
sub.iloc[:,1:] = test_preds
sub.to_csv('submission.csv', index=False)