
01. 회귀 소개
회귀 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법
Y = W1*X+W2*X+W3*X ... +Wn*X
Y는 종속 변수, X는 독립 변수, W는 회귀 계수
독립 변수는 피처, 종속변수는 결정값
머신 러닝 회귀 예측의 핵심은 주어진 피처와 결정값 데이터에 기반에서 학습을 통해 최적의 회귀 계수를 찾아내는 것
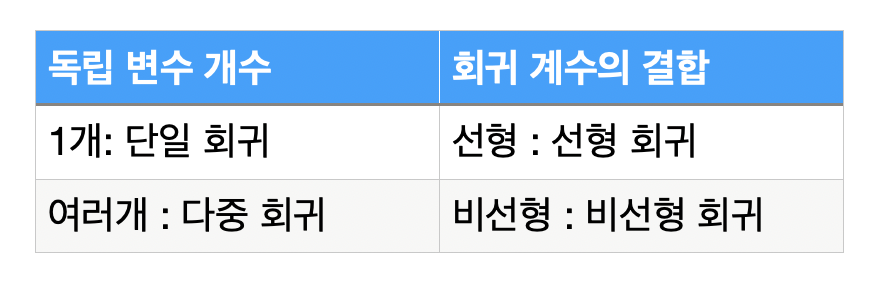
지도학습은 분류와 회귀로 나뉨. 분류는 예측값이 카토고리와 같은 이산형 클래스 값이고, 회귀는 연속형 숫자 값
선형 회귀 모델 종류
- 일반 선형 회귀
예측값과 실제 값의 RSS를 최소화 할 수 있도록 회귀 계수를 최적화하며, 규제를 적용하지 않은 모델- 릿지
선형회귀에 L2 규제를 추가한 회귀 모델. 릿지 회귀는 L2규제를 적용하는데, L2 규제는 상대적으로 큰 회귀 계수값의 예측영향도를 감소시키기 위해서 회귀 계수값을 더 작게 만드는 규제 모델- 라쏘
라쏘 회귀는 선형회귀에 L1 규제를 적용한 방식. L2 규제가 회귀 계수 값의 크기를 줄이는 반해 L1 규제는 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것.- 엘라스틱넷
L2, L1 규제를 함께 결합한 모델- 로지스틱 회귀
사실은 분류에 사용되는 선형모델로 매우 강력한 분류 알고리즘. 이진 분류뿐만이 아니라 희소 영역의 분류, 텍스트 분류와 같은 영역에서 뛰어난 예측 성능을 보임.
02. 단순 선형 회귀를 통한 회귀 이해
회귀 모델을 1차 함수로 모델링 했다면 함수 값에서 실제 값만큼의 오류값을 보정한만큼이 실제 값.
실제 값과 회귀 모델의 차이에 따른 오류 값을 잔차라 부름. 최적의 회귀 모델을 만든다는 것은 바로 전체 데이터의 잔차 합이 최소가 되는 모델을 만든다는 의미
오류 값을 보정하는 방법 2가지는 Mean Absolute Error(절대값을 취해서 더하거나), RSS(오류 값의 제곱을 구해서 더하는 방식) . 일반적으로 RSS를 사용한다.
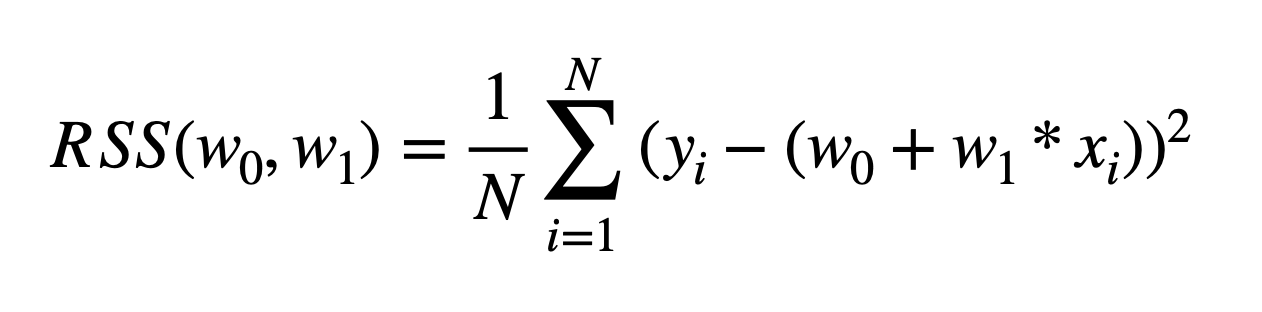
RSS 비용이며 w 변수로 구성되는 RSS를 비용 함수
비용 함수가 반환하는 값을 지속해서 감소시키고 최종적으로 더 이상 감소하지 않는 최소의 오류 값을 구하는 것
03. 비용 최소화하기 - 경사하강법(Gradient Descent)
반복적으로 비용 함수의 반환 값, 예측값과 실제 값의 차이가 작아지는 방향성을 가지고 W 파라미터를 지속해서 보정해 나감
오류 값이 더 이상 작아지지 않으면 그 오류 값을 최소 비용으로 판단하고 그때의 W 값을 최적 파라미터로 반환함.
- w1, w0를 임의의 값으로 설정하고 첫 비용 함수의 값을 계산
- w1을 w1+학습값, w0을 w0+학습값으로 업데이트 한 후 다시 비용함수의 값을 계산
- 비용 함수가 감소하는 방향성으로 주어진 횟수만큼 Step 2를 반복하면서 w1, w0를 계속 업데이트
(학습값)
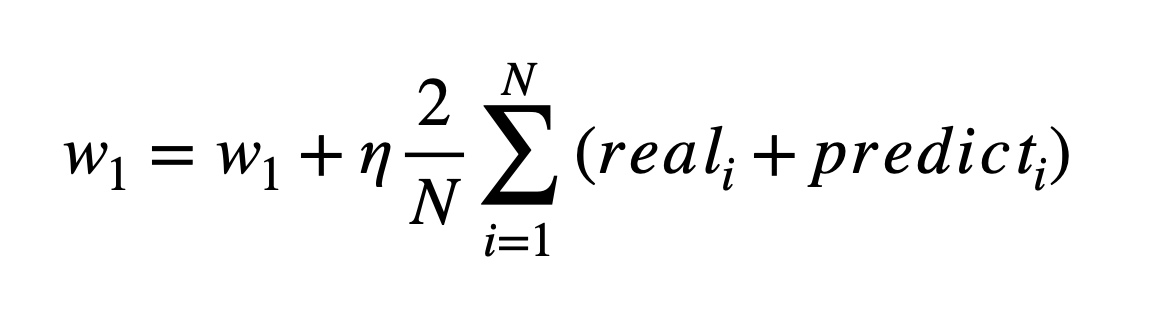
- 단순 선형회귀 예측 데이터 생성
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y-y_pred))/N
return cost
w1, w0 = gradient_descent_steps(X, y, iters=1000)
print("w1:{0:.3f} w0:{1:.3f}".format(w1[0,0], w0[0,0]))
y_pred = w1[0,0]*X + w0
print('Gradient Descent Total Cost:{0:.4f}'.format(get_cost(y, y_pred)))
- 비용함수 정의
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y-y_pred))/N
return cost새로운 w1과 w0을 반복적으로 적용하면서 w1과 w0을 업데이트, ndarray이므로 행렬 수준에서 내적 연산 필요
# 입력 인자 iters로 주어진 횟수만큼 반복적으로 w1과 w0를 업데이트 적용함
def gradient_descent_steps(X, y, iters=10000):
# w0와 w1을 모두 0으로 초기화
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
#인자로 주어진 iters 만큼 반복적으로 get_weight_updates() 호출해 w1, w0 업데이트 수행
for ind in range(iters):
w1_update, w0_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0- 확률적 경사 하강법
일반 경사하강법은 수행시간이 오래 걸린다는 단점이 있기 대문에 실전에서는 대부분 확률적 경사 하강법 사용. 일부 데이터만 이용해 w가 업데이트되는 값을 계산
전체 X, y 데이터에서 랜덤하게 batch_size만큼 데이터를 추출
def stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000):
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
for ind in range(iters):
np.random.seed(ind)
#전체 X,y 데이터에서 랜덤하게 batch_size만큼 데이터를 추출해 sample_X, sample_y로 저장
stochastic_random_index = np.random.permutation(X.shape[0])
sample_X = X[stochastic_random_index[0:batch_size]]
sample_y = y[stochastic_random_index[0:batch_size]]
#랜덤하게 batch_size만큼 추출된 데이터 기반으로 w1_ypdate, w0_update 계산 후 업데이트
w1_update, w0_update = get_weight_updates(w1, w0, sample_X, sample_y, learning_rate=0.01)
w1= w1 - w1_update
w0= w0 - w0_update
return w1, w0- 피처가 여러개인 경우
피처가 1개인 경우를 확장하게 유사하게 도출
피처가 M개라면 그에 따른 회귀 계수도 M+1개로 도출(1개는 w_0)
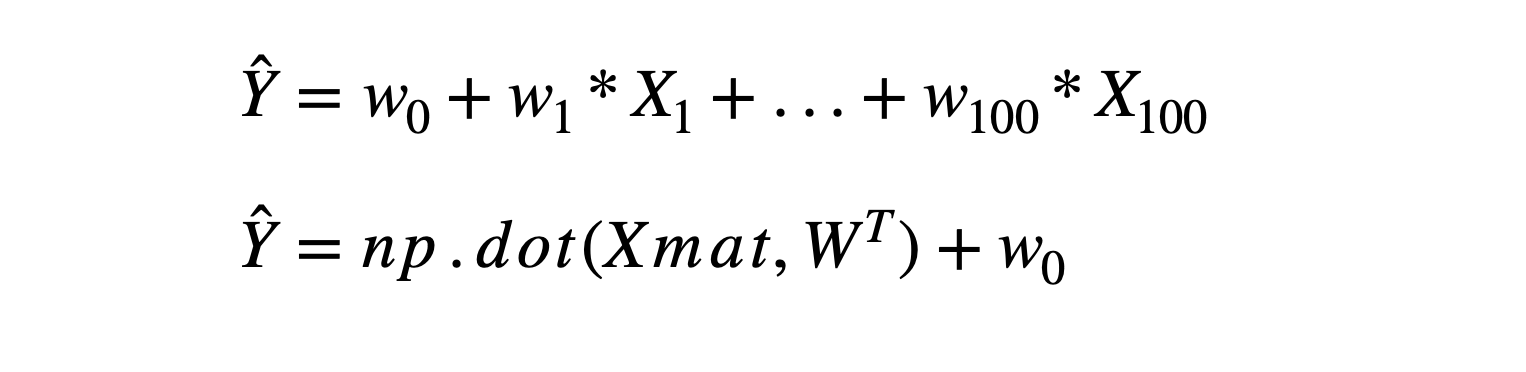
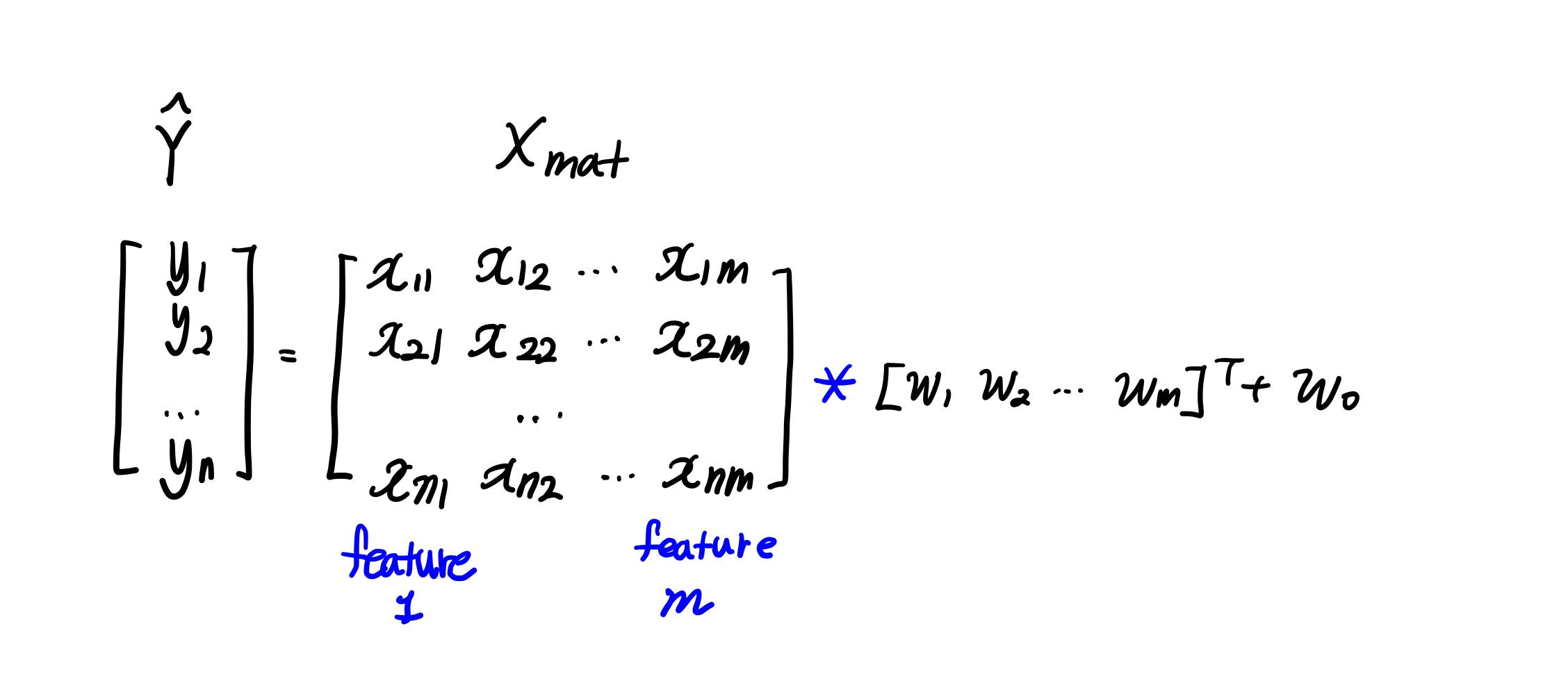
예측 회귀식(1번째 줄)을 예측 행렬 (2번째 줄)로 구할 수 있음
04. 사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측
LinearRegression 클래스 - Ordinary Least Squares
예측값과 실제값의 RSS를 최소화해 OLS 추정 방식으로 구현한 클래스

회귀 평가 지표
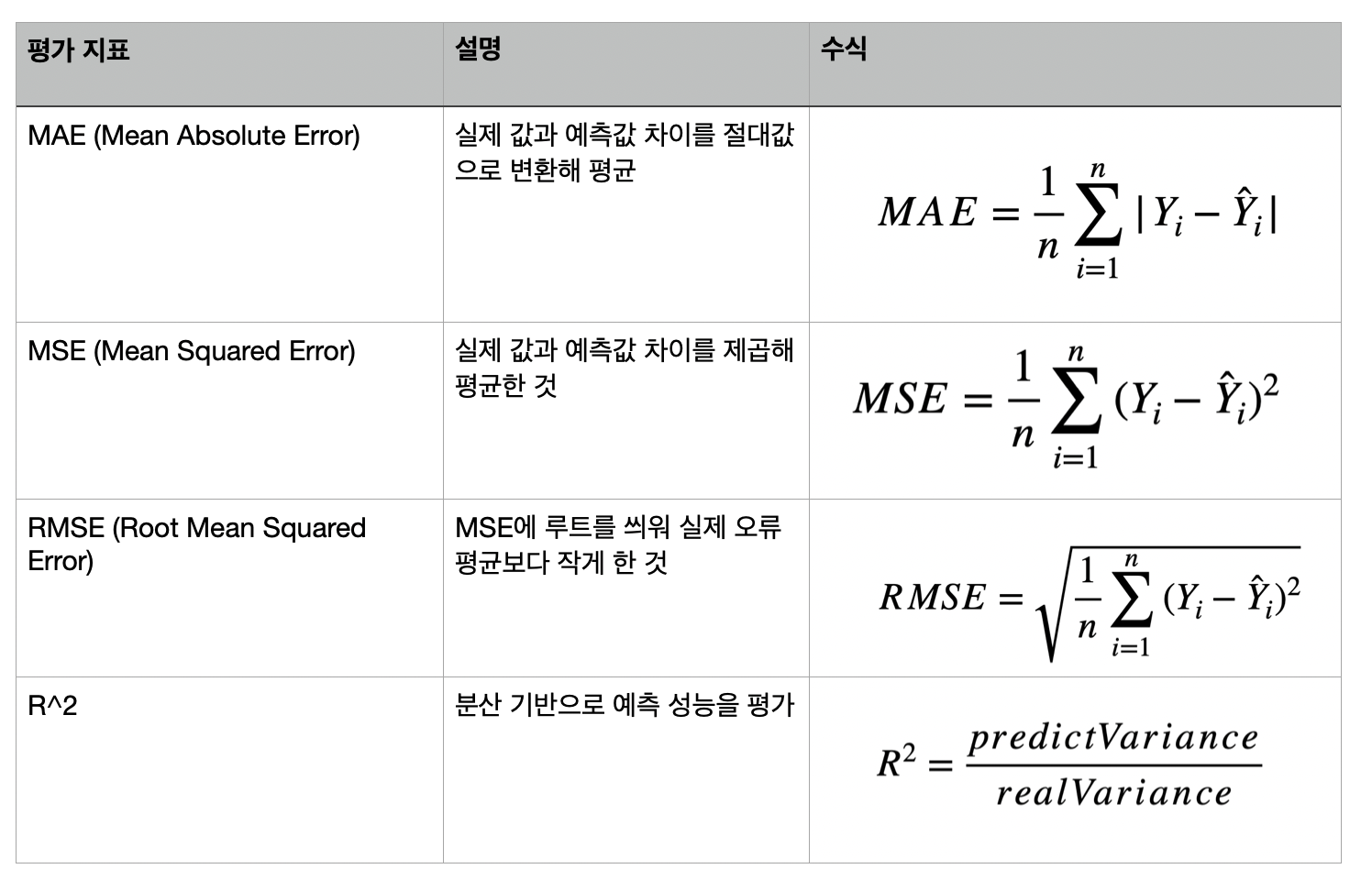
사이킷런은 RMSE를 지원하지 않으므로 RMSE를 구하기 위해서는 MSE에 제곱근을 씌워서 계산하는 함수를 직접 만들어야 함.
- MAE의 scoring 파라미터
neg_mean_absolute_error
사이킷런의 Scoring 함수가 score 값이 클수록 좋은 평가 결과로 자동 평가. 따라서 negative 값으로 변환해 사이킷런에 입력.마지막에 도출 시에는 다시 Positive 값으로 변환하는 작업 필요
LinearRegression을 이용해 보스턴 주택 가격 회귀 구현
⚠️ 보스턴 데이터셋의 윤리적인 문제로 load_boston() 접근 불가
(각 피처의 선택 기준도 비도덕적이며 각 피처와 주택 가격의 관계를 선형성으로 접근하는 것도 올바르지 못함.)
예제 코드 실행X 결과만 참고- 전처리
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.datasets import load_boston
import warnings
warnings.filterwarnings('ignore') #사이킷런 1.2 부터는 보스턴 주택가격 데이터가 없어진다는 warning 메시지 출력 제거
%matplotlib inline
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
print('Boston 데이타셋 크기 :',bostonDF.shape)
bostonDF.head()- 칼럼(피처)의 영향도
칼럼과 PRICE의 상관관계 파악
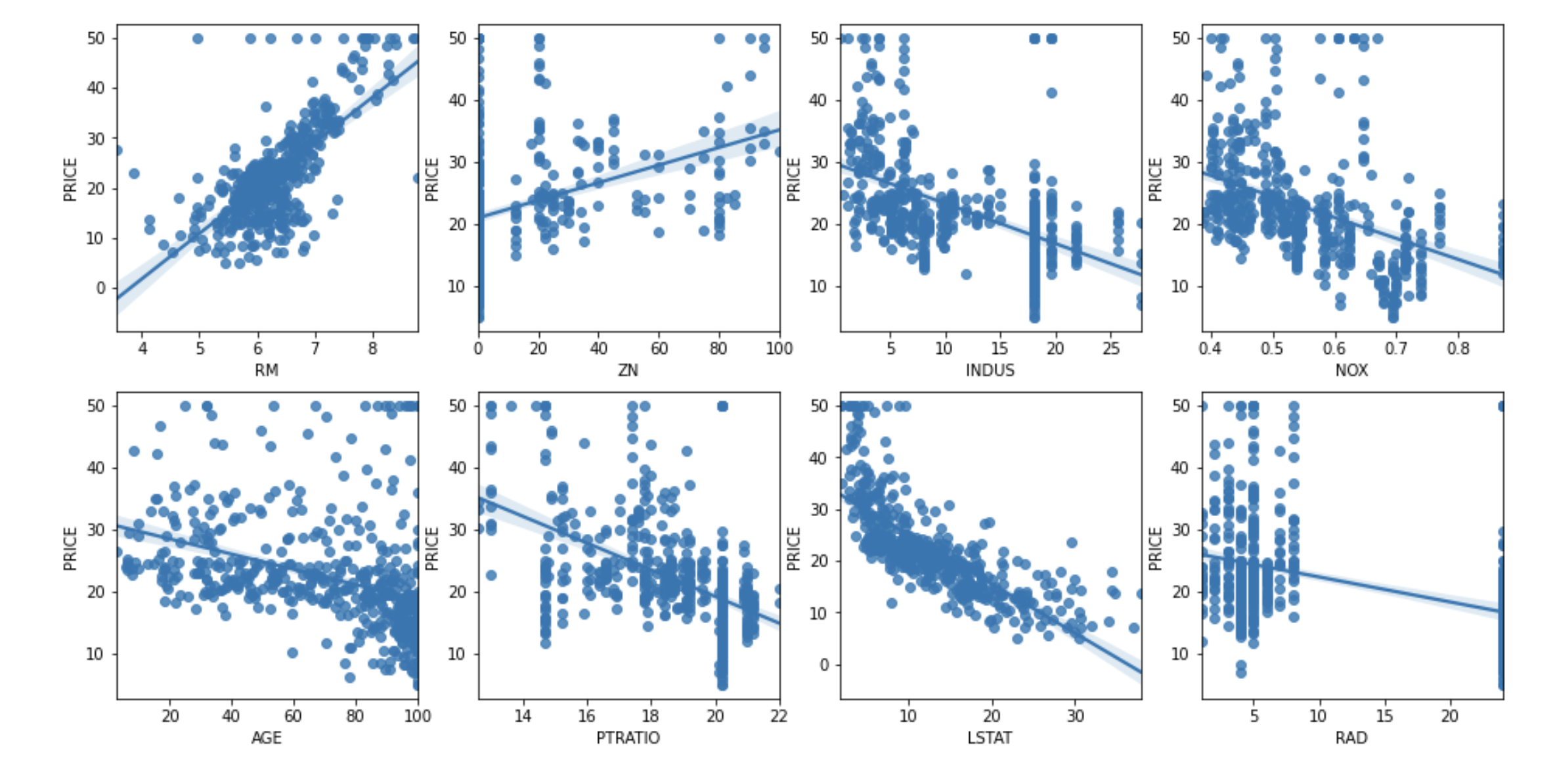
RM은 양 방향의 선형성이 가장 크고 LSAT는 음 방향의 선형성이 가장 큼.
- LinearRegression
LinearRegression 클래스를 이용해 보스턴 주택 가격의 회귀 모델을 생성.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
X_train , X_test , y_train , y_test = train_test_split(X_data , y_target ,test_size=0.3, random_state=156)
# Linear Regression OLS로 학습/예측/평가 수행.
lr = LinearRegression()
lr.fit(X_train ,y_train )
y_preds = lr.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print('MSE : {0:.3f} , RMSE : {1:.3F}'.format(mse , rmse))
print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds)))절편은 LinearRegression 객체의 intercept_ 속성에, 회귀 계수는 coef_속성에 저장돼 있음.
- 회귀 평가
교차 검증으로 MSE와 RMSE를 측정
from sklearn.model_selection import cross_val_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
lr = LinearRegression()
# cross_val_score( )로 5 Fold 셋으로 MSE 를 구한 뒤 이를 기반으로 다시 RMSE 구함.
neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
# cross_val_score(scoring="neg_mean_squared_error")로 반환된 값은 모두 음수
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 2))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
계산된 MSE(neg_mean_squared_error)에 -1을 곱해서 반환 (그래야 양의 값)
05. 다항회귀와 과대적합/과소적합 이해
다항회귀 이해
다항회귀
다항회귀는 선형회귀 함수이다.
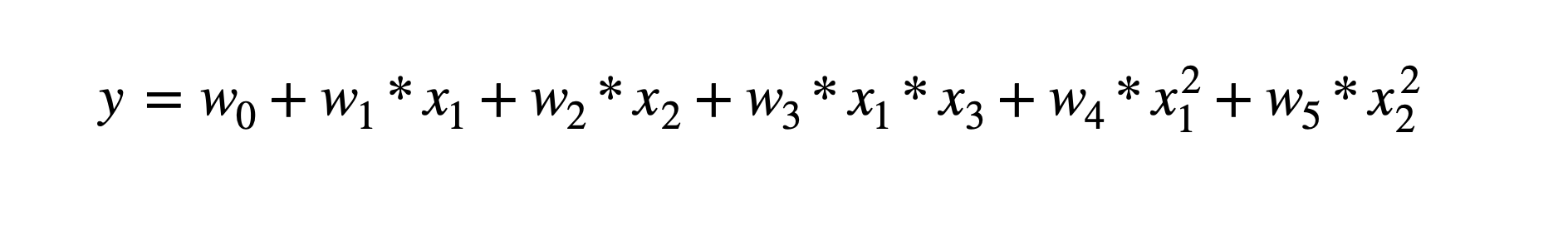
다항 회귀 역시 선형회귀이기 때문에 비선형 함수를 선형 모델에 적용시키는 방법을 사용해 구현
1. PolynomialFeature 클래스를 통해 피처를 Polynomial 피처로 변환
단항식 피처를 degree에 해당하는 다항식 피처로 변환
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# 다항식으로 변환한 단항식 생성, [[0,1],[2,3]]의 2X2 행렬 생성
X = np.arange(4).reshape(2,2)
print('일차 단항식 계수 feature:\n',X )
# degree = 2 인 2차 다항식으로 변환하기 위해 PolynomialFeatures를 이용하여 변환
poly = PolynomialFeatures(degree=2)
poly.fit(X)
poly_ftr = poly.transform(X)
print('변환된 2차 다항식 계수 feature:\n', poly_ftr)[Output]
일차 단항식 계수 feature:
[[0 1]
[2 3]]
변환된 2차 다항식 계수 feature:
[[1. 0. 1. 0. 0. 1.]
[1. 2. 3. 4. 6. 9.]]입력된 x1=0, x2=1에 대한 2차 다항 계수 [1, x_1, x_2, x_1^2, x_1*x_2, x_2^2]를 return
2. 다항식 계수 feature와 다항식 결정값으로 Linear Regression 학습
다항식 계수 feature은 위에서 PolynomialFeature로 구한 계수
다항식 결정값은 원래 함수 대입 값 (예측값이 아닌 실제 함수에 대입한 실제값)
사이킷런은 PolynomialFeatures로 피처를 변환한 후에 LinearRegression 클래스로 다항회귀를 구현
일반적으로 Pipeline 객체를 이용해 1 & 2단계를 한번에 구현
# Pipeline 객체로 Streamline 하게 Polynomial Feature변환과 Linear Regression을 연결
model = Pipeline([('poly', PolynomialFeatures(degree=3)),
('linear', LinearRegression())])다항 회귀를 이용한 과소적합 및 과적합 이해
다항 회귀의 차수를 높일 수록 학습데이터에만 너무 맞춘 학습이 이뤄져서 과적합의 문제가 발생
- 코사인 함수 예제
피처 X와 target y가 잡음이 포함된 코사인 그래프 관계를 가짐. 다항회귀의 참수를 변화시키면서 그에 따른 회귀 예측 곡선과 예측 정확도를 비교하는 예제
target y = X의 코사인 값 + 약간의 잡음 변동
# 임의의 값으로 구성된 X값에 대해 코사인 변환 값을 반환.
def true_fun(X):
return np.cos(1.5 * np.pi * X)
# X는 0부터 1까지 30개의 임의의 값을 순서대로 샘플링한 데이터입니다.
np.random.seed(0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))
# y 값은 코사인 기반의 true_fun()에서 약간의 노이즈 변동 값을 더한 값입니다.
y = true_fun(X) + np.random.randn(n_samples) * 0.1- 다항식 차수를 1, 4, 15로 변경하면서 예측 결과 비교
cross_val_score()로 MSE 값 구해 차수별 예측 성능 비교
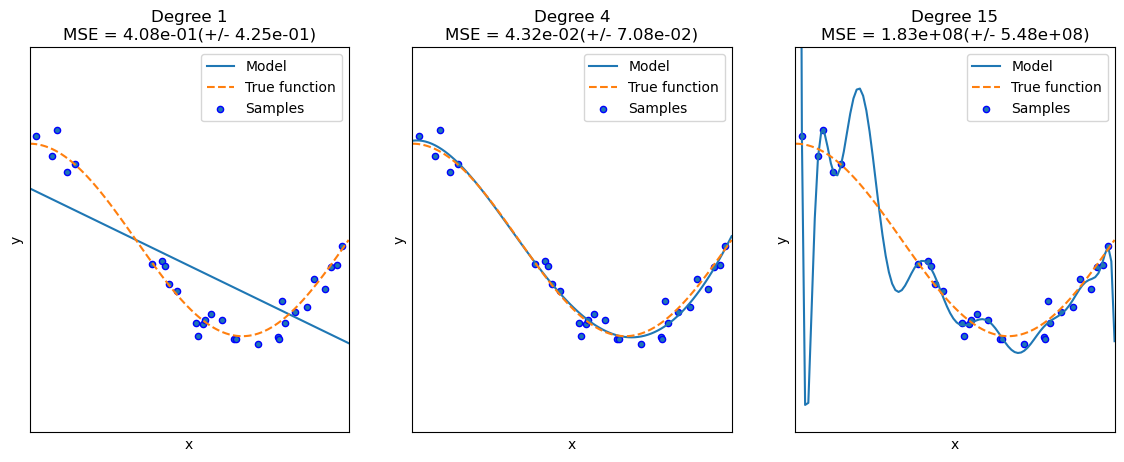
(실선이 다항회귀 예측 곡선/ 점선이 실제 데이터 세트 X, Y의 코사인 곡선)
- Degree1 (MSE=0.41)
너무 단순한 직선 모델. 예측 곡선이 학습 데이터의 패턴을 제대로 반영하지 못하고 있는 과소적합 모델- Degree4 (MSE=0.04)
학습 데이터 세트를 비교적 잘 반영해 코사인 곡선 기반으로 테스트 데이터를 잘 예측한 곡선을 가진 모델이 됨- Degree (MSE=182581084.83)
예측 곡선이 학습 데이터 세트만 정확히 예측하고, 테스트 값의 실제 곡선과는 완전히 다른 형태의 예측 곡선이 만들어짐
편향-분산 트레이드 오프 (Bias-Variance TradeOff)
고편향 - 매우 단순화된 모델로 지나치게 한 방향성으로 치우친 경향 존재
고분산 - 매우 복잡한 모델로 지나치게 높은 변동성을 가짐
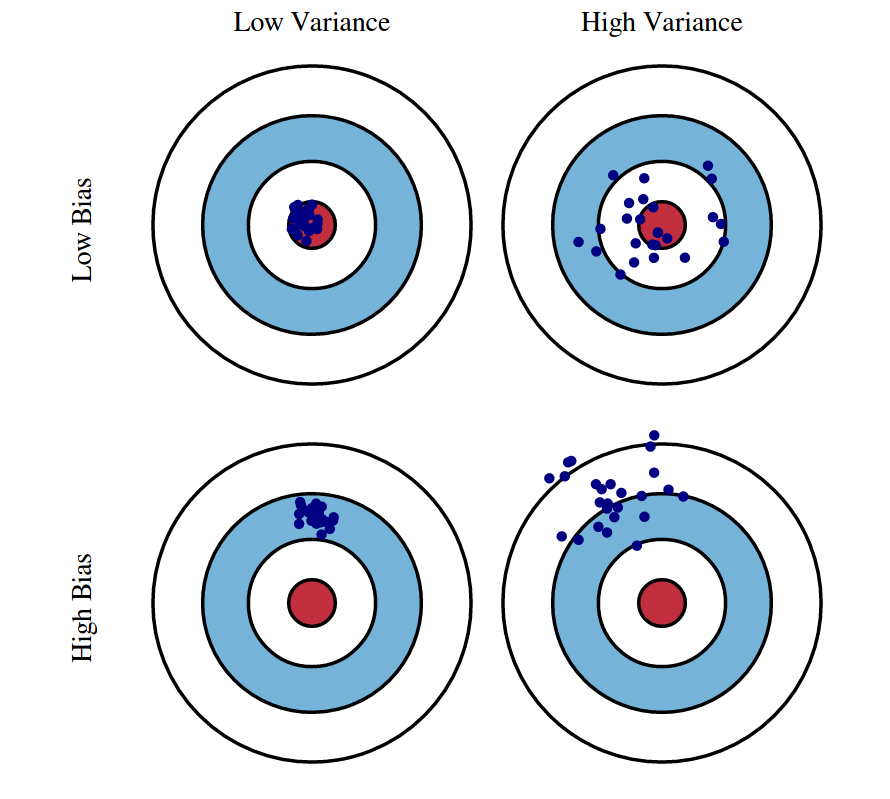

편향과 분산이 서로 트레이드 오프를 이루면서 오류 Cost 값이 최대로 낮아지는 모델을 구축하는 것이 가장 효율적인 머신러닝 예측 모델을 만드는 방법
06. 규제 선형 모델 - 릿지, 라쏘, 엘라스틱넷
이때동안은 RSS를 최소화하는 것만 고려. 학습 데이터에 지나치게 맞추게 되고, 회귀 계수가 쉽게 커짐.
RSS 최소화 방법과 과적합을 방지하기 위해 회귀 계수 값이 커지지 않도록 하는 방법 사이 균형 필요
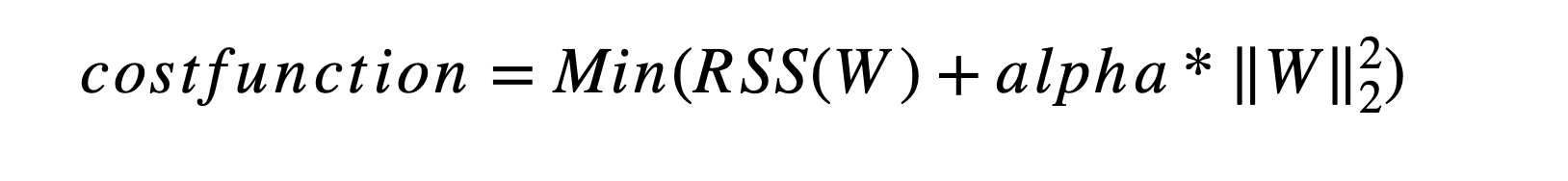
alpha는 학습 데이터 적합 정도와 회귀 계수 값의 크기 제어를 수행하는 튜닝 파라미터
alpha가 0이라면 기존과 동일한 식 (규제를 적용하지 않은 식)
alpha가 무한대라면 비용함수 식에서 W 규제는 매우 커져 0으로 수렴
비용함수에 alpha 값으로 패널티를 부여해 회귀 계수 값의 크기를 감소시켜 과적합을 개선하는 방식을 규제(Regularization)라고 부름
릿지 회귀 (L2 규제)
alpha L2 규제 계수 - L2 규제하는 특정 alpha 정의
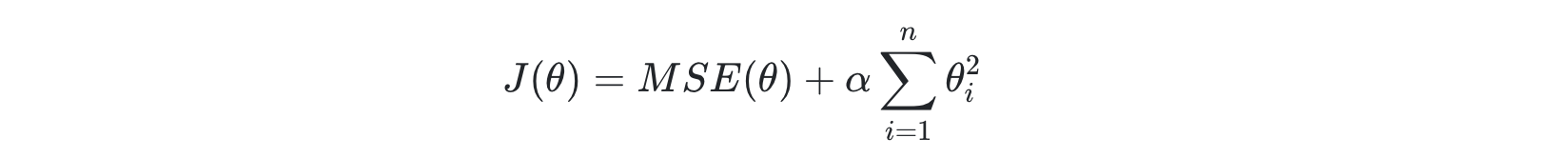
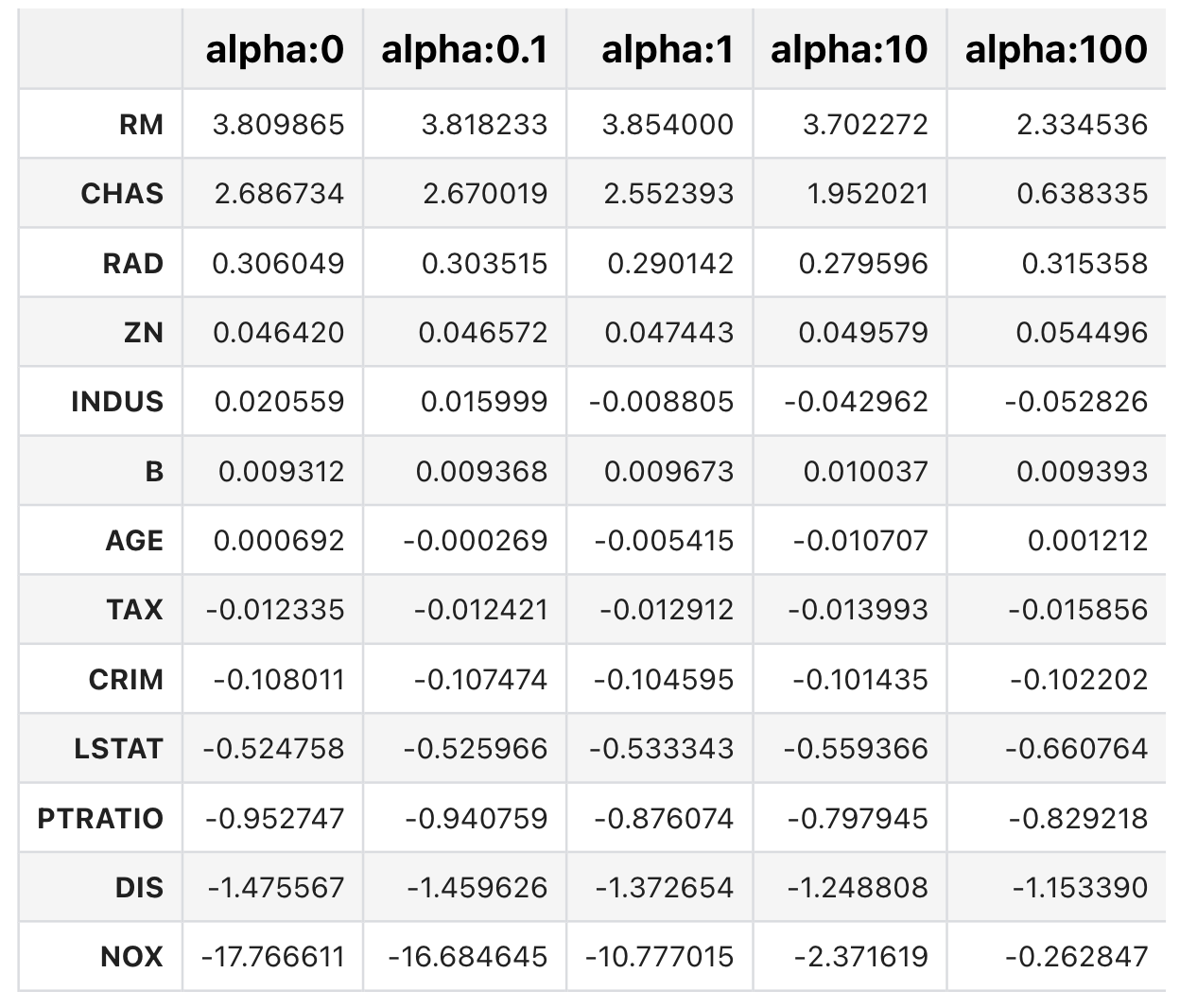
릿지 회귀는 alpha 값이 커질 수록 회귀 계수 값을 작게 만듦
- alpha에 따른 회귀 계수 값
각 피처에 대한 가로막대는 회귀 계수 의미
# 각 alpha에 따른 회귀 계수 값을 시각화하기 위해 5개의 열로 된 맷플롯립 축 생성
fig , axs = plt.subplots(figsize=(18,6) , nrows=1 , ncols=5)
# 각 alpha에 따른 회귀 계수 값을 데이터로 저장하기 위한 DataFrame 생성
coeff_df = pd.DataFrame()
# alphas 리스트 값을 차례로 입력해 회귀 계수 값 시각화 및 데이터 저장. pos는 axis의 위치 지정
for pos , alpha in enumerate(alphas) :
ridge = Ridge(alpha = alpha)
ridge.fit(X_data , y_target)
# alpha에 따른 피처별 회귀 계수를 Series로 변환하고 이를 DataFrame의 컬럼으로 추가.
coeff = pd.Series(data=ridge.coef_ , index=X_data.columns )
colname='alpha:'+str(alpha)
coeff_df[colname] = coeff
# 막대 그래프로 각 alpha 값에서의 회귀 계수를 시각화. 회귀 계수값이 높은 순으로 표현
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values , y=coeff.index, ax=axs[pos])
# for 문 바깥에서 맷플롯립의 show 호출 및 alpha에 따른 피처별 회귀 계수를 DataFrame으로 표시
plt.show()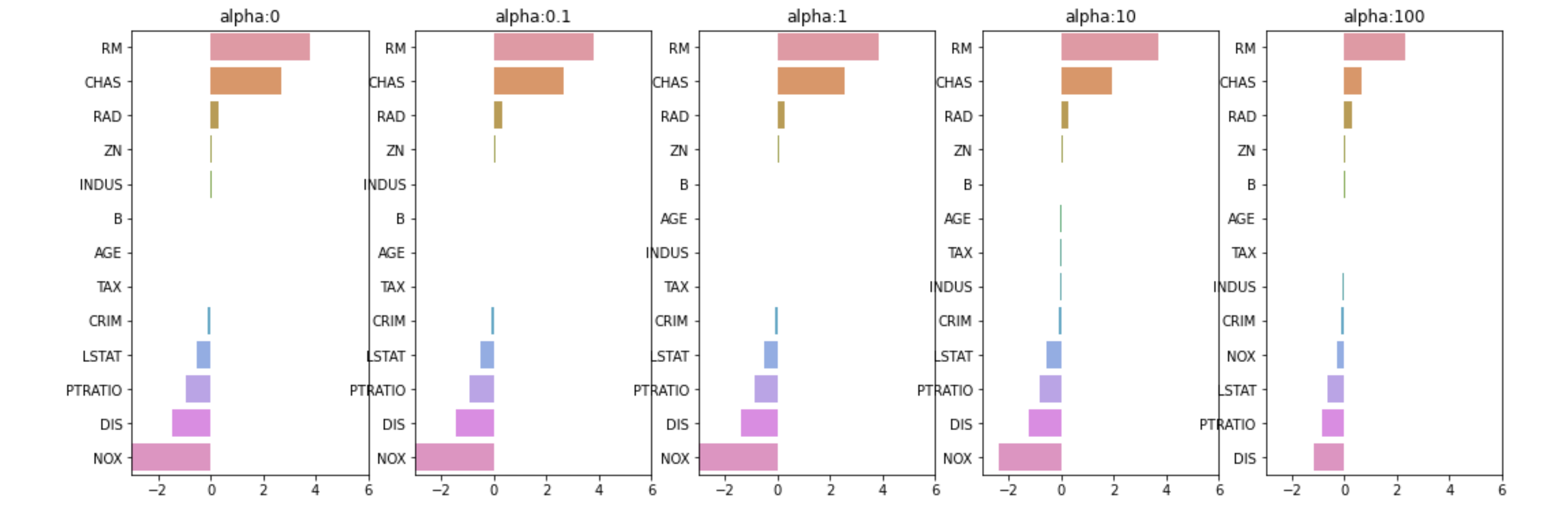
alpha가 커질수록 회귀 계수가 감소함을 확인 가능
라쏘 회귀 (L1 규제)
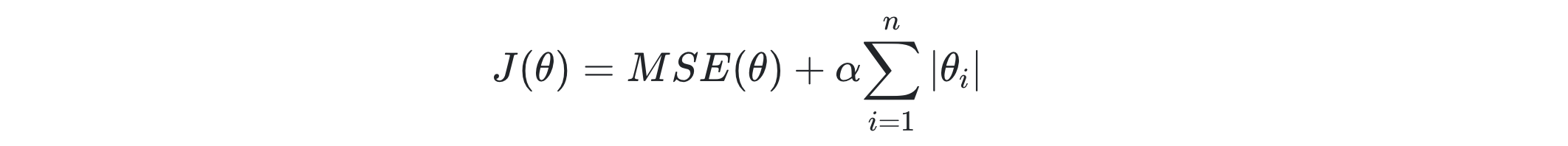
L1 규제는 alpha *||W|| 의미. 적절한 피처만 회귀에 포함시키는 피처 선택의 특성 가짐
L1 규제와 L2 규제의 차이점
L2 규제가 회귀 계수의 크기를 감소시키는 반해 L1 규제는 불필요한 회귀 계수를 급격하게 감소시켜 0으로 만들고 제거
라쏘 회귀의 경우 최적값은 모서리 부분에서 나타날 확률이 릿지에 비해 높기 때문에 몇몇 유의미하지 않은 변수들에 대해 계수를 0에 가깝게 (또는 0) 으로 추정해 feature selection의 효과 를 가져온다. 라쏘는 파라미터의 크기에 관계 없이 같은 수준의 reularizaton 을 적용하기 때문에 작은 값의 파라미터를 0으로 만들어 해당 변수를 모델에서 삭제하고, 따라서 모델을 단순하게 만들어주고 해석을 용이하게 한다. (출처 : velog)
- alpha 값을 변화시키면서 RMSE와 각 피처의 회귀 계수를 출력
from sklearn.linear_model import Lasso, ElasticNet
# alpha값에 따른 회귀 모델의 폴드 평균 RMSE를 출력하고 회귀 계수값들을 DataFrame으로 반환
def get_linear_reg_eval(model_name, params=None, X_data_n=None, y_target_n=None,
verbose=True, return_coeff=True):
coeff_df = pd.DataFrame()
if verbose : print('####### ', model_name , '#######')
for param in params:
if model_name =='Ridge': model = Ridge(alpha=param)
elif model_name =='Lasso': model = Lasso(alpha=param)
elif model_name =='ElasticNet': model = ElasticNet(alpha=param, l1_ratio=0.7)
neg_mse_scores = cross_val_score(model, X_data_n,
y_target_n, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0}일 때 5 폴드 세트의 평균 RMSE: {1:.3f} '.format(param, avg_rmse))
# cross_val_score는 evaluation metric만 반환하므로 모델을 다시 학습하여 회귀 계수 추출
model.fit(X_data_n , y_target_n)
if return_coeff:
# alpha에 따른 피처별 회귀 계수를 Series로 변환하고 이를 DataFrame의 컬럼으로 추가.
coeff = pd.Series(data=model.coef_ , index=X_data_n.columns )
colname='alpha:'+str(param)
coeff_df[colname] = coeff
return coeff_df
# end of get_linear_regre_eval
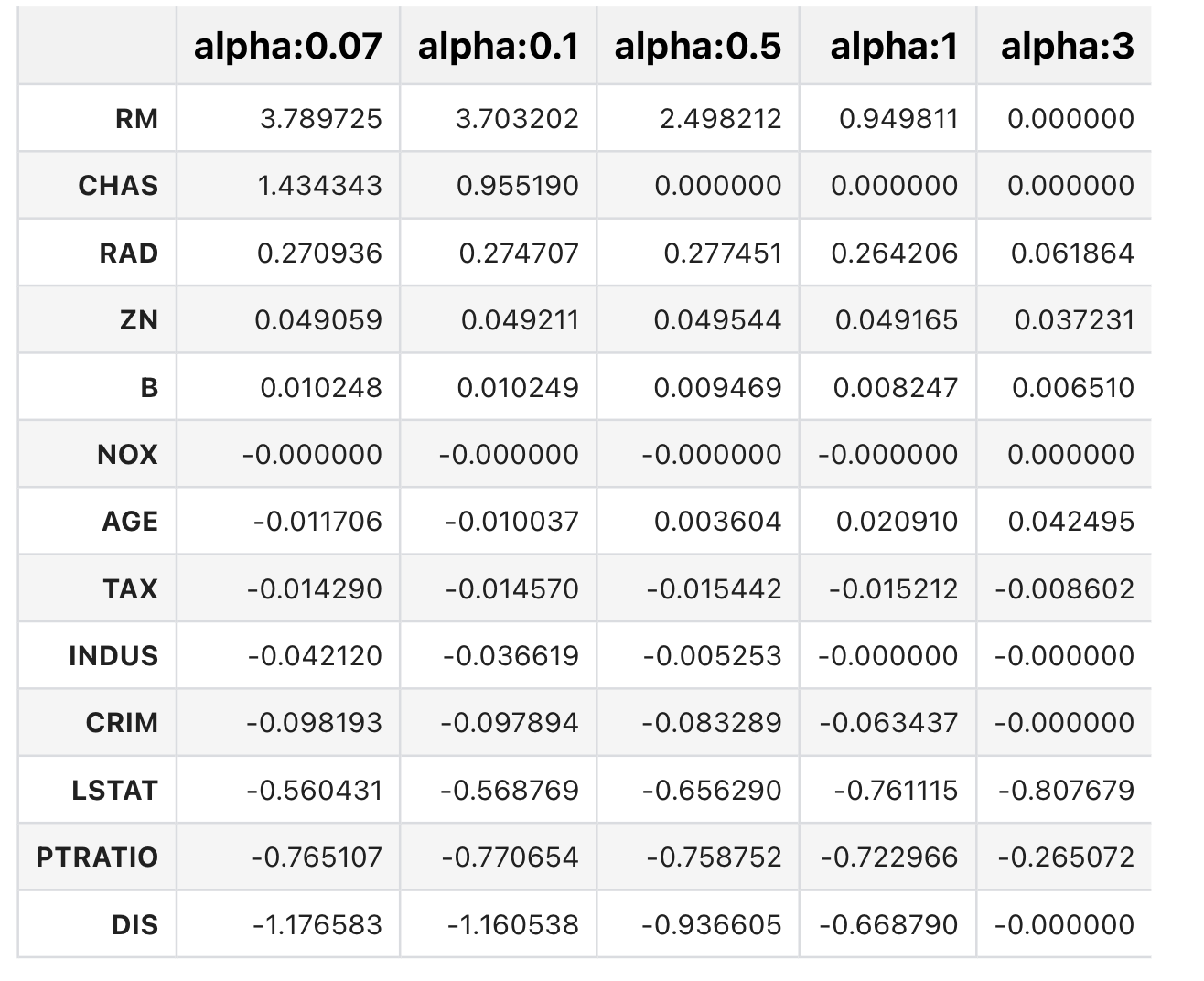
일부 피처의 회귀 계수는 아예 0으로 바뀌고 있음
엘라스틱넷 회귀
L1 규제와 L2 규제를 결합한 회귀
RSS(W) + alpha2 ||W|| + alpha1 ||W|| 을 최소화 하는 W 찾기
(라쏘와 릿지의 alpha 값은 다름!)
라쏘 회귀에서 중요 피처를 고르고 다른 피처를 모두 회귀 계수를 0으로 만드는 성향이 강함. 급격히 변동할 수도 있는데, 엘라스틱 회귀는 이를 완화하기 위해 L2 규제를 라쏘 회귀에 추가한 것
단점은 수행시간이 상대적으로 오래 걸림
- ElasticNet 클래스
엘라스틱넷 규제 a * L1 + b * L2
a = L1 규제의 alpha값
b = L2 규제의 alpha값
Elastic alpha 파라미터 값 = a+b
l1_ratio 파라미터 값 = a / (a+b)- l1_ratio를 고정한 alpha값의 단순한 변화
엘라스틱넷에 사용될 alpha 파라미터의 값들을 정의하고 get_linear_reg_eval() 함수 호출
# l1_ratio는 0.7로 고정
elastic_alphas = [ 0.07, 0.1, 0.5, 1, 3]
coeff_elastic_df =get_linear_reg_eval('ElasticNet', params=elastic_alphas,
X_data_n=X_data, y_target_n=y_target)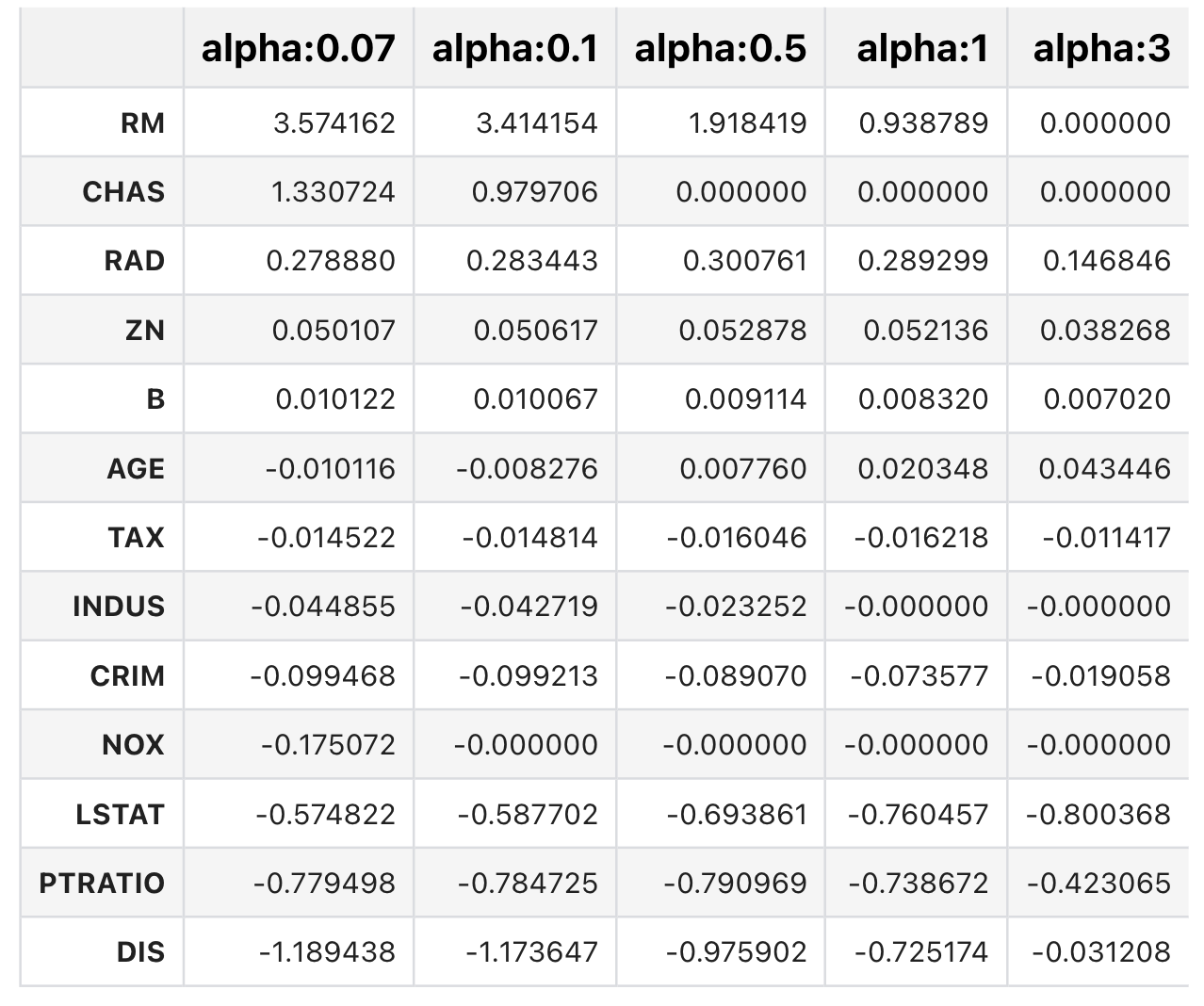
선형 회귀 모델을 위한 데이터 변환
선형 회귀 모델은 데이터 전처리가 중요하다
선형 회귀 모델은 피처값과 타깃값의 분포가 정규분포 형태를 매우 선호. 선형 회귀 모델을 적용하기 전에 먼저 데이터에 대한 스케일링/정규화 작업을 수행하는 것이 일반적
선형 회귀 모델 데이터 전처리 방법 종류
1. 정규화 방법 2가지
StandardScaler 클래스를 이용해 정규분포 데이터 세트로 변환하거나 MinMaxScaler 클래스를 이용해 정규화를 수행
2. 스케일링/정규화를 수행한 데이터 세트에 다시 다항 특성을 적용하여 변환하는 방법
3. 로그 변환
원래 값에 log 함수를 적용하면 보다 정규분포에 가까운 형태로 값이 분포
타깃값의 경우는 일반적으로 로그 변환 적용
- 표준 정규 분포 변환, 최댓값/최솟값 정규화, 로그 변환을 차례로 적용 후 RMSE로 각 경우별 예측 성능을 측정
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
# method는 표준 정규 분포 변환(Standard), 최대값/최소값 정규화(MinMax), 로그변환(Log) 결정
# p_degree는 다향식 특성을 추가할 때 적용. p_degree는 2이상 부여하지 않음.
def get_scaled_data(method='None', p_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data)
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data)
elif method == 'Log':
scaled_data = np.log1p(input_data)
else:
scaled_data = input_data
if p_degree != None:
scaled_data = PolynomialFeatures(degree=p_degree,
include_bias=False).fit_transform(scaled_data)
return scaled_data일반적으로 log()함수보다 1+log() 함수np.log1p() 함수 적용
scale_methods=[(None, None), ('Standard', None), ('Standard', 2),
('MinMax', None), ('MinMax', [원본 데이터,
표준 정규분포,
표준 정규분포를 다시 2차 다항식 변환,
최솟값/최댓값 정규화,
최솟값/최대값 정규화를 다시 2차 다항식 변환,
로그 변환]
2차 다항식 변환 - LinearRegression 훈련 전 1차가 아닌 2차로 변환 (지금 전 과정이 1차 선형 함수로 진행되는 중)
- 결과
[Output]
## 변환 유형:None, Polynomial Degree:None
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330
## 변환 유형:Standard, Polynomial Degree:None
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330
## 변환 유형:Standard, Polynomial Degree:2
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330
## 변환 유형:MinMax, Polynomial Degree:None
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330
## 변환 유형:MinMax, Polynomial Degree:2
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330
## 변환 유형:Log, Polynomial Degree:None
##### Ridge #####
alpha: 0.1 일 때 5 folds의 평균 RMSE: 5.788
alpha: 1 일 때 5 folds의 평균 RMSE: 5.653
alpha: 10 일 때 5 folds의 평균 RMSE: 5.518
alpha: 100 일 때 5 folds의 평균 RMSE: 5.330일반적으로 선형 회귀 적용 데이터 세트에 데이터 값 분포가 심하게 왜곡될 경우 로그 변환을 적용하는 것이 좋은 결과 기대 가능
왜 분류가 아닌 회귀에만 규제 적용?
07. 로지스틱 회귀
로지스틱 회귀는 선형 회귀방식을 분류에 적용한 알고리즘. 학습을 통해 선형 함수의 최적선을 찾는 것이 아니라 시그모이드 함수 최적선을 찾고 이 시그모이드 함수의 반환 값을 확률로 간주해 확률에 따라 분류를 결정한다는 것 (회귀 결과값을 분류에 사용한다)
- 시그모이드 함수
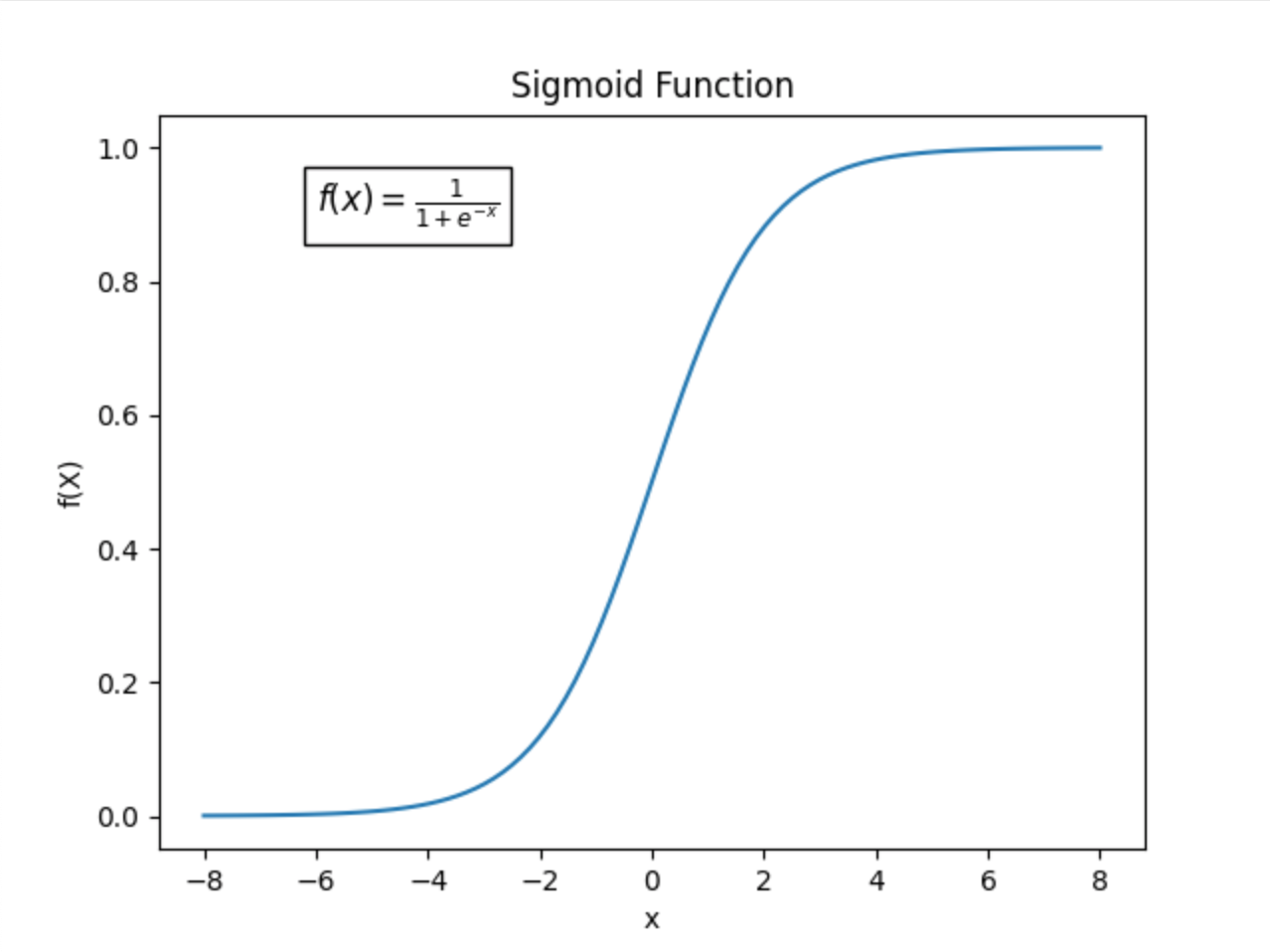
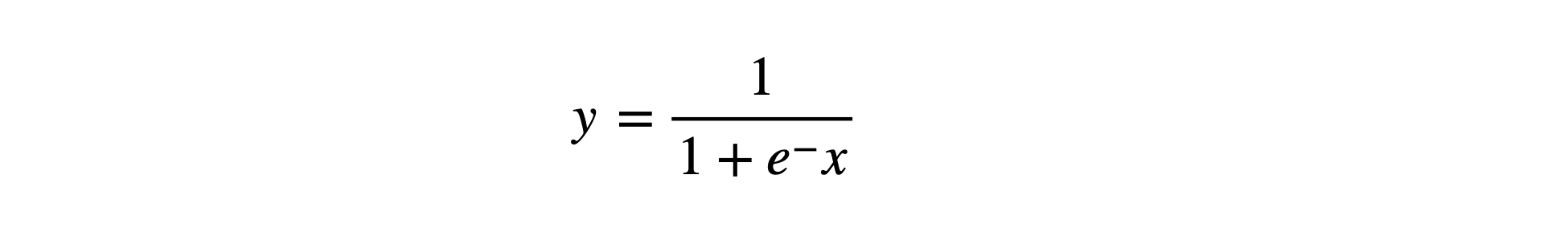
로지스틱 회귀는 회귀 문제가 아닌 분류 문제에 적합
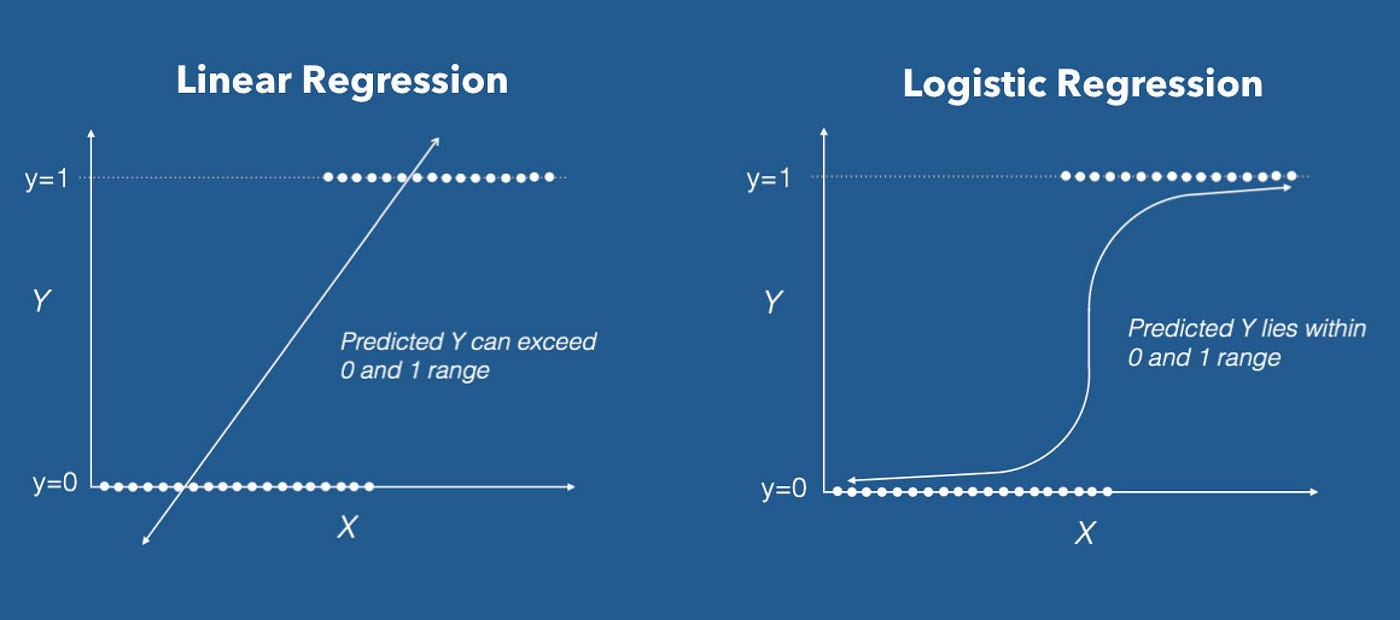
선형회귀 라인은 0과 1을 제대로 분류하지 못하고 있지만 로지스틱 회귀는 선형 회귀 방식을 기반으로한 시그모이드 함수를 이용해 성능이 좋은 분류를 보이고 있음. (이진 분류에 선형 회귀라인보다 시그모이드 함수 라인이 적합)
- Logistic Regression 클래스
- solver 파라미터
(대부분 사용되는 2가지) :lbfgs,liblinear,
기본 solver 값인 lbfgs 보다는 liblinear가 좀 더 빠르게 수행되며 수행성능이 더 나은 결과 보임.
newton-cg,sag(경사 하강법 기반의 최적화를 적용),saga(L1 정규화)- 주요 하이퍼 파라미터
penalty- 규제의 유형을 설정(default=l2, 'l2'= L2규제, 'l1' = L1 규제)
C- 1/alpha (C값이 작을 수록 규제 강도가 큼)
- 유방암 데이터 세트에서 로지스틱 회귀로 암여부 판단
- 데이터 전처리
정규분포 형태의 표준 스케일링을 적용 & 훈련세트와 테스트세트 분리
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# StandardScaler( )로 평균이 0, 분산 1로 데이터 분포도 변환
scaler = StandardScaler()
data_scaled = scaler.fit_transform(cancer.data)
X_train , X_test, y_train , y_test = train_test_split(data_scaled, cancer.target, test_size=0.3, random_state=0)-
로지스틱 회귀 학습 및 예측 수행
시그모이드 함수로 2개 클래스로 자동 분류 -
정확도와 ROC-AUC 값 계산
from sklearn.metrics import accuracy_score, roc_auc_score
# 로지스틱 회귀를 이용하여 학습 및 예측 수행.
# solver인자값을 생성자로 입력하지 않으면 solver='lbfgs'
lr_clf = LogisticRegression() # solver='lbfgs'
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1]
# accuracy와 roc_auc 측정
print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds),
roc_auc_score(y_test , lr_preds_proba)))[Output]
accuracy: 0.977, roc_auc:0.995로지스틱 회귀는 가볍고 빠르지만, 이진 분류 예측 성능이 뛰어나 이진 분류의 기본모델로 주로 사용
08. 회귀 트리
(이전까지는...)
선형 회귀는 회귀 계수를 선형으로 결합하는 회귀 함수를 구해, 여기에 독립변수를 입력해 결괏값을 예측하는 것. 비선형 회귀는 비선형으로 회귀 계수를 결합해 결괏값을 예측
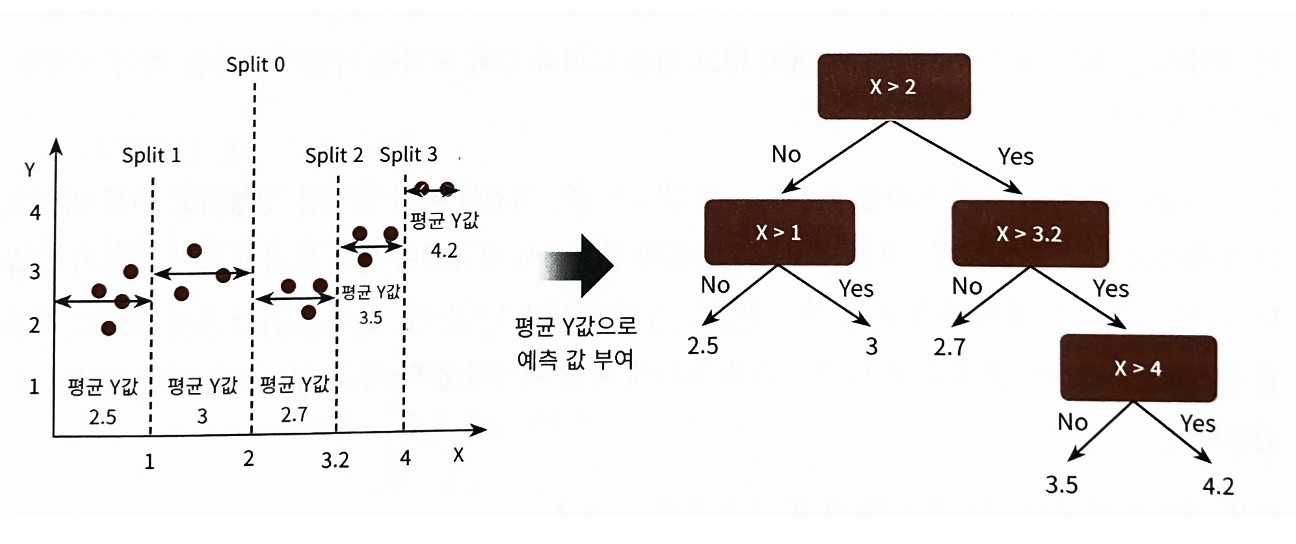
분류 트리가 특정 클래스 레이블을 결정하는 것과는 달리 회귀 트리는 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산
- X값의 균일도(지니계수)에 따라 분할
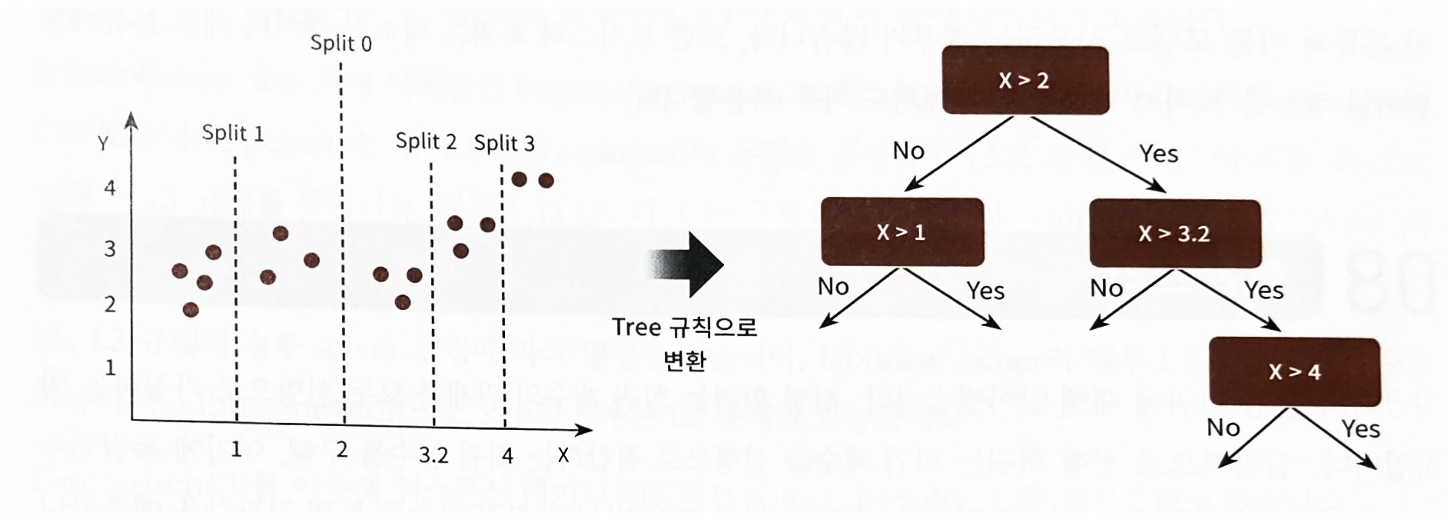
- 트리 분할이 완료됐다면 리프 노드에 소속된 데이터 값의 평균값을 구해서 최종적으로 리프노드에 결정 값으로 할당
- 분류 트리 기반 알고리즘
결정트리, 랜덤 포레스트, GBM, XGBoost, LightGBM 등 분류에서 사용한 트리 기반의 알고리즘은 분류뿐만 아니라 회귀도 가능 (CART 알고리즘, Classification And Regression Trees)
- RandomForestRegressor 보스턴 주택가격 예측
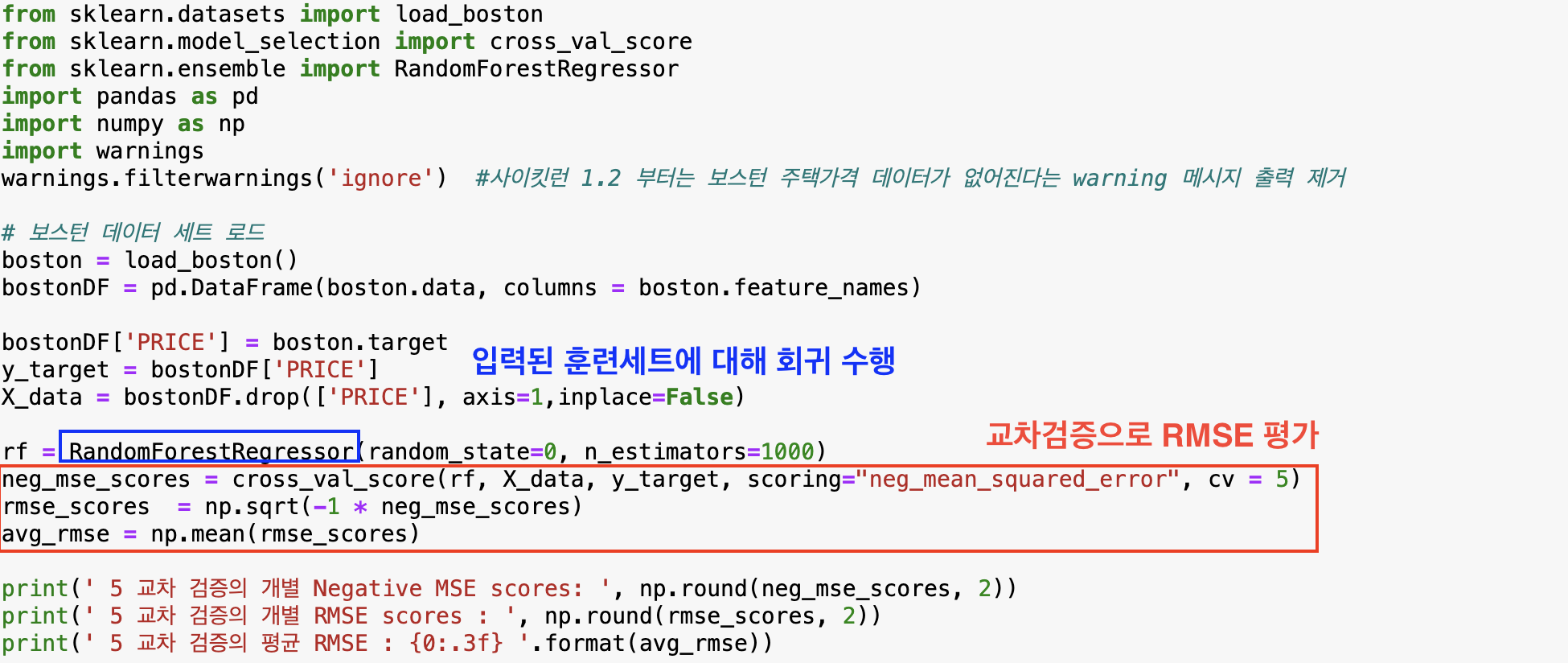
- GBM, XGBoost, LightGBM, 랜덤 포레스트
def get_model_cv_prediction(model, X_data, y_target):
neg_mse_scores = cross_val_score(model, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print('##### ',model.__class__.__name__ , ' #####')
print(' 5 교차 검증의 평균 RMSE : {0:.3f} '.format(avg_rmse))입력 모델과 데이터 세트를 입력받아 교차검증으로 RMSE 계산
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=4)
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
gb_reg = GradientBoostingRegressor(random_state=0, n_estimators=1000)
xgb_reg = XGBRegressor(n_estimators=1000)
lgb_reg = LGBMRegressor(n_estimators=1000)
# 트리 기반의 회귀 모델을 반복하면서 평가 수행
models = [dt_reg, rf_reg, gb_reg, xgb_reg, lgb_reg]
for model in models:
get_model_cv_prediction(model, X_data, y_target)[Output]
##### DecisionTreeRegressor #####
5 교차 검증의 평균 RMSE : 5.978
##### RandomForestRegressor #####
5 교차 검증의 평균 RMSE : 4.423
##### GradientBoostingRegressor #####
5 교차 검증의 평균 RMSE : 4.269
##### XGBRegressor #####
5 교차 검증의 평균 RMSE : 4.251
##### LGBMRegressor #####
5 교차 검증의 평균 RMSE : 4.646- 선형회귀와 회귀 트리 비교
회귀 트리 Regressor가 어떻게 예측값을 판단하는 지 선형회귀와 비교해 시각화
import numpy as np
from sklearn.linear_model import LinearRegression
# 선형 회귀와 결정 트리 기반의 Regressor 생성. DecisionTreeRegressor의 max_depth는 각각 2, 7
lr_reg = LinearRegression()
rf_reg2 = DecisionTreeRegressor(max_depth=2)
rf_reg7 = DecisionTreeRegressor(max_depth=7)
# 실제 예측을 적용할 테스트용 데이터 셋을 4.5 ~ 8.5 까지 100개 데이터 셋 생성.
X_test = np.arange(4.5, 8.5, 0.04).reshape(-1, 1)
# 보스턴 주택가격 데이터에서 시각화를 위해 피처는 RM만, 그리고 결정 데이터인 PRICE 추출
X_feature = bostonDF_sample['RM'].values.reshape(-1,1)
y_target = bostonDF_sample['PRICE'].values.reshape(-1,1)
# 학습과 예측 수행.
lr_reg.fit(X_feature, y_target)
rf_reg2.fit(X_feature, y_target)
rf_reg7.fit(X_feature, y_target)
pred_lr = lr_reg.predict(X_test)
pred_rf2 = rf_reg2.predict(X_test)
pred_rf7 = rf_reg7.predict(X_test)
결정 트리의 하이퍼 파라미터인 max_depth 예측값 확인
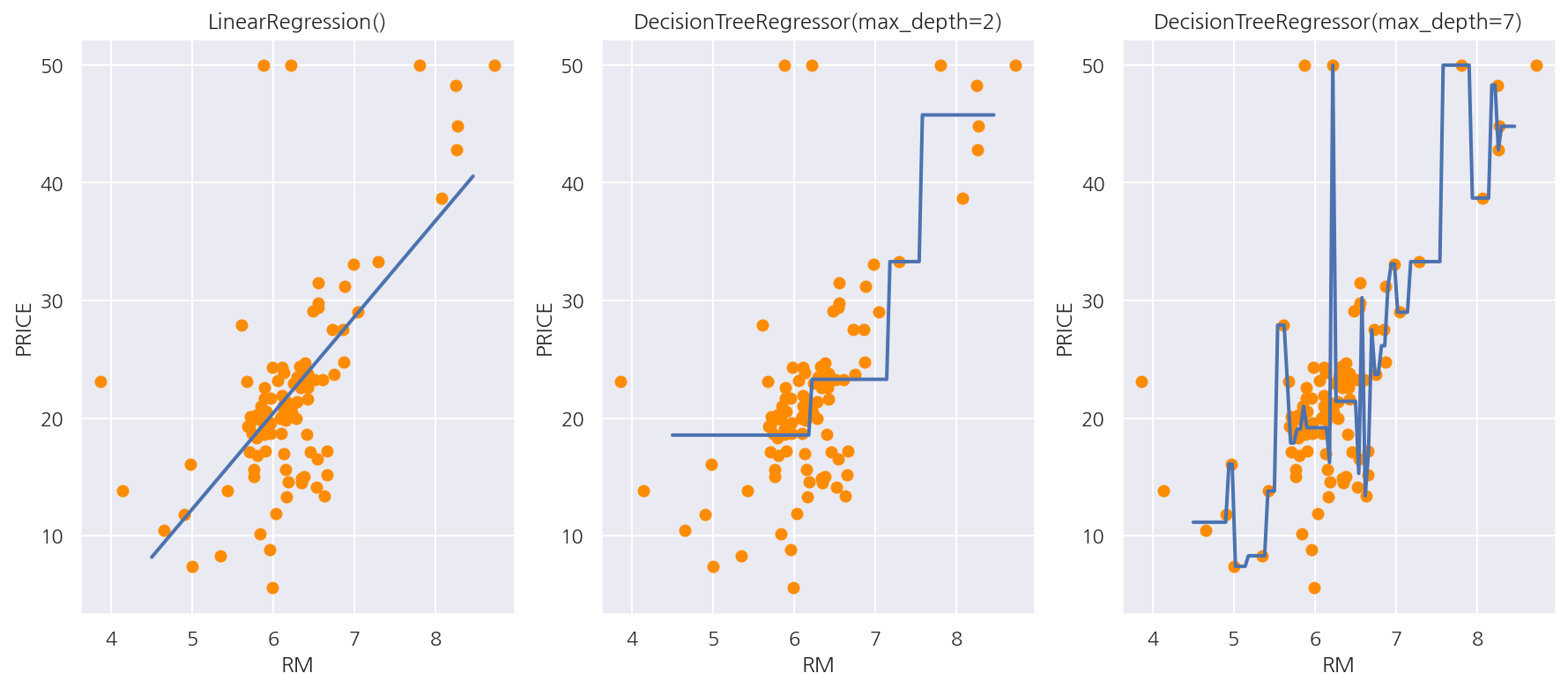
회귀트리의 경우 분할되는 데이터 지점에 따라 브랜치를 만들면서 계단 형태로 회귀선을 생성
