
01. 자전거 대여 수요 예측
자전거 대여 시스템
• 도시 전역의 키오스크 위치 네트워크를 통해 회원가입,대여 및 자전거 반환 프로세스가 자동화되는 자전거를 대여하는 수단
• 전세계 500개 이상의 자전거 대여 프로그램이 있음
=> 자전거 대여 시스템에서 생성된 데이터는 여행 기간, 출발 위치, 도착 위치 및 경과 시간이 명시적으로 기록되기 때문에 센서 네트워크로서 기능하며, 이는 도시의 이동성을 연구하는 데 사용 가능
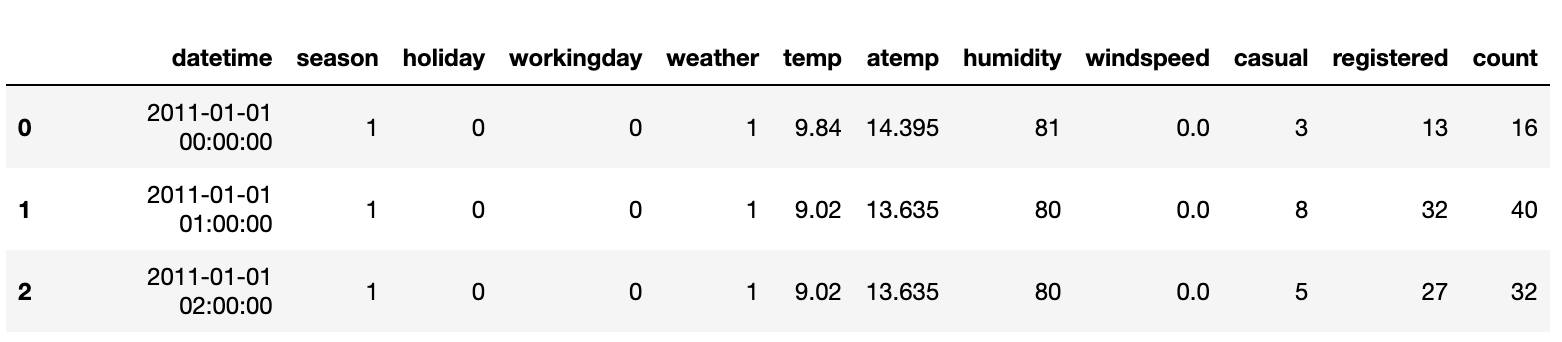
Data Description
- datetime : hourly date + timestamp
- season : 1= 봄, 2= 여름, 3= 가을, 4= 겨울
- holiday: 1= 토, 일요일의 주말을 제외한 국경일 등의 휴일, 0= 휴일이 아닌 날
- workingday: 1= 토, 일요일의 주말 . 및휴일이 아닌 주중, 0= 주말 . 및휴일
- weather
- 1 = 맑음, 약간 구름 낀 흐림
- 2 = 안개, 안개 + 흐림
- 3 = 가벼운 눈, 가벼운 . 비+ 천둥
- 4 = 심한 눈/비, 천둥/번개
- temp : 온도(섭씨)
- atemp: 체감온도(섭씨)
- humidity: 상대습도
- windspeed: 풍속
- casual: 사전에 등록되지 않는 사용자가 대여한 횟수
- registered: 사전에 등록된 사용자가 대여한 횟수
- count: 대여 횟수
데이터 클렌징 및 가공과 데이터 시각화
모델을 학습해 대여 횟수(count)를 예측
- 데이터 확인
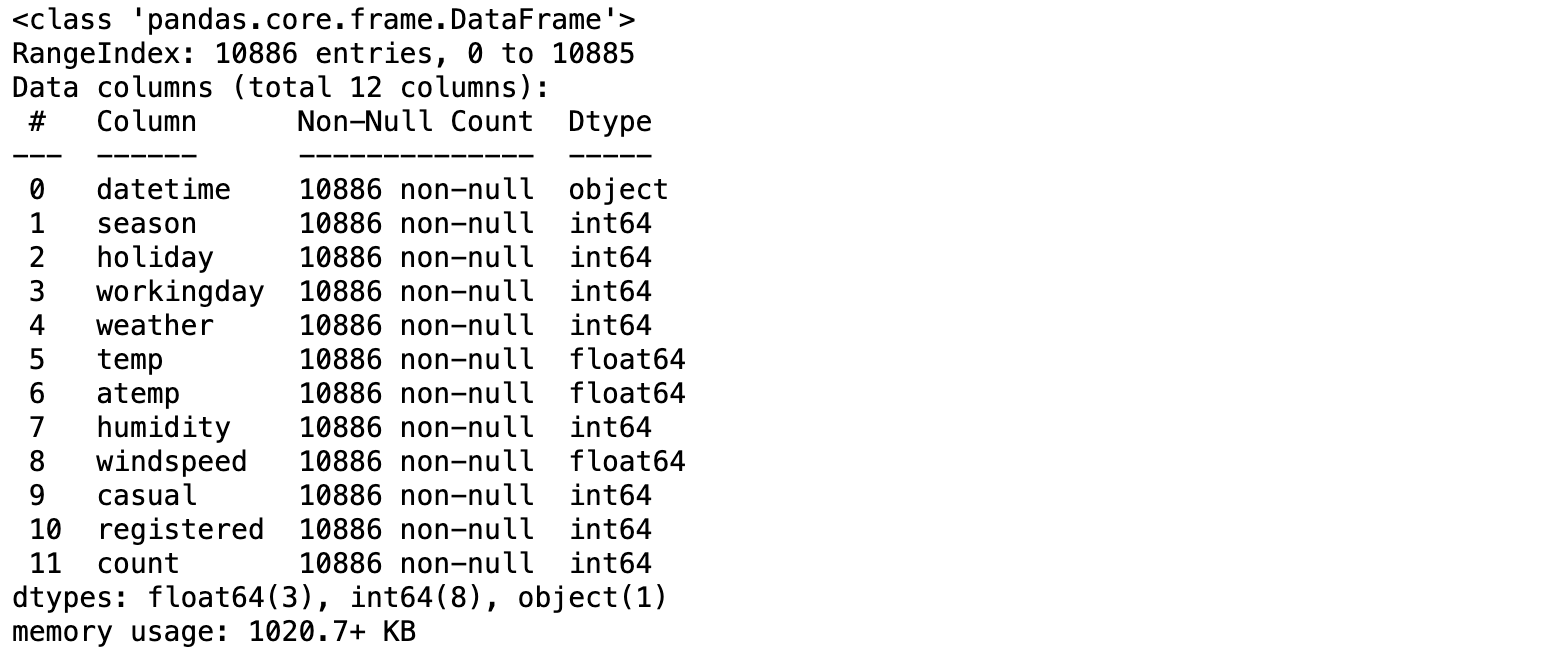
>> date 칼럼만 object형
년/월/일/시간이 4개 속성으로 분리
# 문자열을 datetime 타입으로 변경.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
# datetime 타입에서 년, 월, 일, 시간 추출
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)
bike_df.head(3)- 칼럼 삭제
casual + registered = count
상관도가 높은 두 칼럼은 예측을 저해할 우려가 있으므로 두 칼럼 삭제
- Target인 count 분포 파악
(1) 시각화
fig, axs = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
cat_features = ['year', 'month','season','weather','day', 'hour', 'holiday','workingday']
# cat_features에 있는 모든 칼럼별로 개별 칼럼값에 따른 count의 합을 barplot으로 시각화
for i, feature in enumerate(cat_features):
row = int(i/4)
col = i%4
# 시본의 barplot을 이용해 칼럼값에 따른 count의 합을 표현
sns.barplot(x=feature, y='count', data=bike_df, ax=axs[row][col])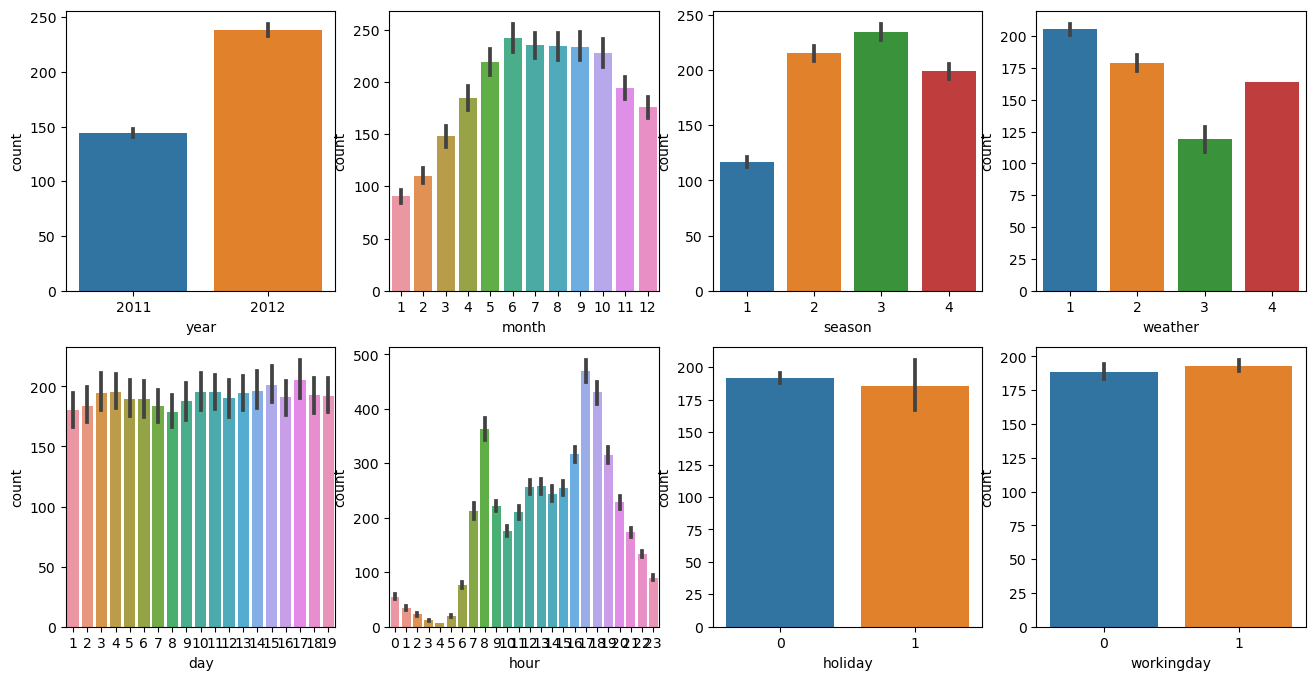
(8개 칼럼과 count 상관관계 그래프)
year별 count를 보면 시간이 지날 수록 자연거 대여 횟수가 증가하고 있음을 알 수 있음 / month의 경우 6, 7, 8, 9가 높음/ season은 여름, 가을이 높음 / weather은 맑거나, 안개가 있는 경우가 높음 / hour의 경우는 오전 출근 시간과 오후 퇴근 시간이 상대적으로 높음 / day는 차이가 크지 않으며 / holiday 또는 workingday는 주중일 경우 상대적으로 약간 높음.
- 모델 훈련 시작
각 회귀모델별로 RMSLE 출력 (자전거 데이터 세트에 가장 적합한 회귀모델 찾기)
RMSLE(Root Mean Square Log Error)
1) outlier에 덜 민감함 (outlier 가 있더라도 값의 변동폭이 크지 않음)
2) 상대적 Error를 측정함 (값의 절대적 크기가 커지면 RMSE의 값도 커지지만, RMSLE는 상대적 크기가 동일하다면 RMSLE의 값도 동일함)
3) Under Estimation에 큰 패널티를 부여함
log1p()를 이용해 언더플로우를 방지한다(expm1()함수로 복원 = exp(X)+1)

rmsle 구현 함수
from sklearn.metrics import mean_squared_error, mean_absolute_error
# log 값 변환 시 NaN등의 이슈로 log() 가 아닌 log1p() 를 이용하여 RMSLE 계산
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred) ** 2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
# 사이킷런의 mean_square_error() 를 이용하여 RMSE 계산
def rmse(y,pred):
return np.sqrt(mean_squared_error(y,pred))
# MSE, RMSE, RMSLE 를 모두 계산
def evaluate_regr(y,pred):
rmsle_val = rmsle(y,pred)
rmse_val = rmse(y,pred)
# MAE 는 scikit learn의 mean_absolute_error() 로 계산
mae_val = mean_absolute_error(y,pred)
print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))로그 변환, 피처 인코딩과 모델 학습/예측/평가
1. 결괏값이 정규분포인지 확인
- 오류값 비교 (실제값과 예측값 차이 비교)
def get_top_error_data(y_test, pred, n_tops = 5):
# DataFrame에 컬럼들로 실제 대여횟수(count)와 예측 값을 서로 비교 할 수 있도록 생성.
result_df = pd.DataFrame(y_test.values, columns=['real_count'])
result_df['predicted_count']= np.round(pred)
result_df['diff'] = np.abs(result_df['real_count'] - result_df['predicted_count'])
# 예측값과 실제값이 가장 큰 데이터 순으로 출력.
print(result_df.sort_values('diff', ascending=False)[:n_tops])
get_top_error_data(y_test,pred,n_tops=5)예측 오류가 크다는 것을 확인 가능
▶︎ Target 값의 분포가 왜곡된 형태인지 먼저 확인하기(정규분포가 best)
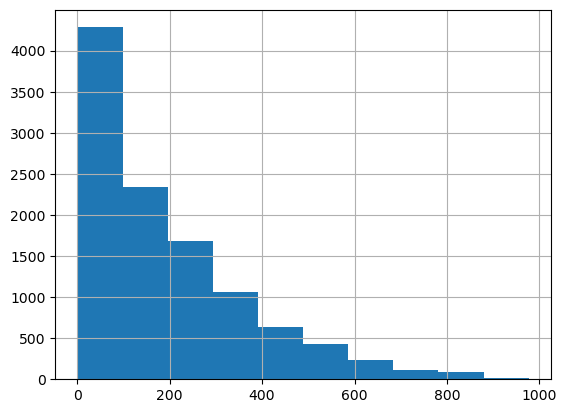
0~200 사이에 왜곡돼 있음
- 로그를 적용해 변환
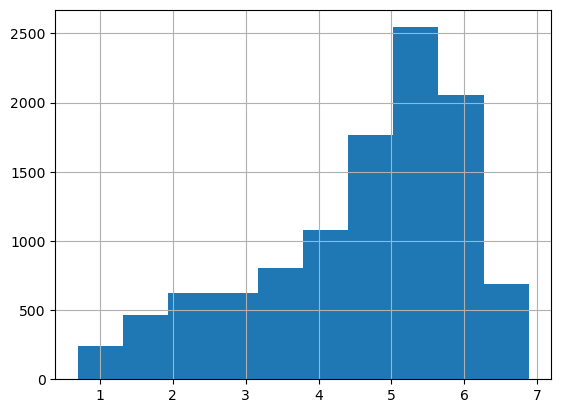
//여기서 더 정규분포로 변환하는 작업을 추가해도 성능이 향상되는 결과를 볼 수 있을듯
2. 개별 피처들의 인코딩
year, hour, month 등은 숫자값으로 표현되었지만 모두 카테고리형 피처
숫자형 카테고리 값을 선형회귀에 사용할 경우 이 숫자형 값에 크게 영향을 받으면 안되므로 원-핫 인코딩을 적용해 변환
#'year', 'month', 'day', 'hour' 등의 피처들을 One Hot Encoding
X_features_ohe = pd.get_dummies(X_features, columns =['year', 'month', 'day', 'hour', 'holiday',
'workingday', 'season', 'weather'])- 선형 회귀 모델
# 원-핫 인코딩이 적용된 피처 데이터 세트 기반으로 학습/예측 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log,
test_size =0.3, random_state=0)
# 모델과 학습/테스트 데이터 세트를 입력하면 성능 평가 수치를 반환
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False):
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1:
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print('###', model.__class__.__name__, '###')
evaluate_regr(y_test, pred)
#end of function get_model_predict
# 모델별로 평가 수행
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha = 0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=True)- 렌덤 포레스트, GBM, XGBoost, LightGBM
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
#랜덤 포레스트 ,GBM , XGBoos(t, LightGBM model별로 평가 수행
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
xgb_reg = XGBRegressor(n_estimators = 500)
lgbm_reg = LGBMRegressor(n_estimators = 500)
for model in [rf_reg, gbm_reg, xgb_reg, lgbm_reg]:
#XGBoost의 경우 DataFrame이 입력될 경우 버전에 따라 오류 발생 가능. ndarray로 변환.
get_model_predict(model, X_train.values, X_test.values, y_train.values,
y_test.values, is_expm1=True)02. 캐글 주택 가격 : 고급 회귀 기법
주택 가격 예측
79개의 설명변수가 미국 아이오와 주의 에임스에 있는 주거용 주택의 거의 모든 측변을 설명함.
=> 대회는 이를 이용해 각 주택의 최종 가격을 예측하는 데 도전함.
House Price - Advanced Regression Techniques
Data Description
- SalePrice : 부동산의 판매 가격 (단위: 달러)
- GrLivArea : 주거 공간 크기
- CentralAir : 중앙 에어컨
- OverallQual : 전반적인 재료 및 마무리 품질
- OverallCond : 전체 상태 등급
- RoofStyle : 지붕의 유형
- 1stFirSF : 1층 평방 피트
- PaveDrive : 포장된 진입로
- Fence : 울타리 품질
- Sale Type : 판매 유형
- LotFrontage : 재산에 연결된 거리의 선형 피트
- Street : 도로 접근 유형
데이터 불러오기 및 가공

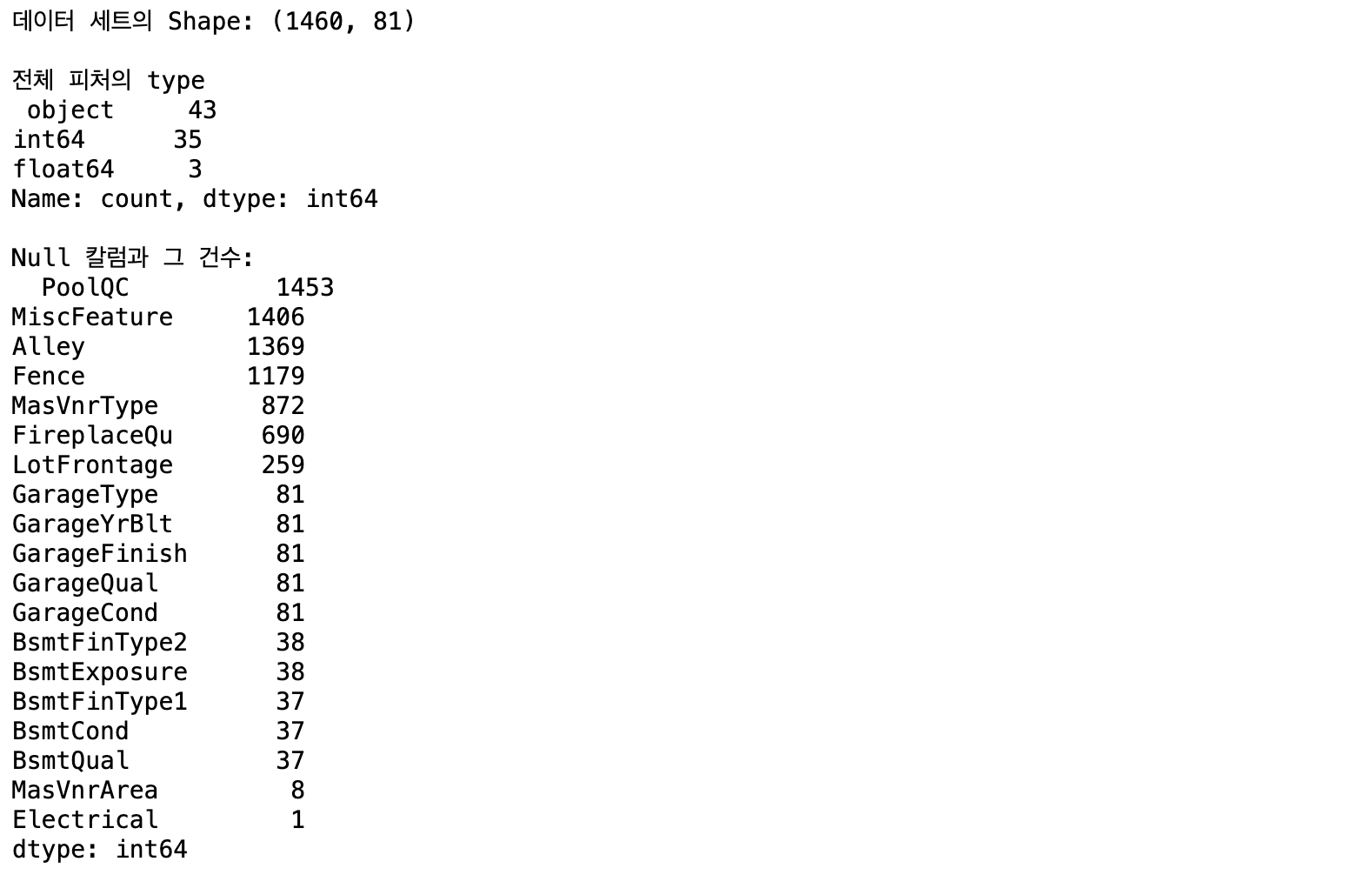
Target 값은 SalePrice. 80개 피처 중 43개가 문자형이며 Null값이 많은 피처도 존재. (PoolQC, MiscFeature, Alley, Fence 1000개가 넘는 데이터가 Null)
- 타깃 값 정규분포
plt.title('Original Sale Price Histogram')
plt.xticks(rotation=45)
sns.histplot(house_df['SalePrice'], kde=True)
plt.show()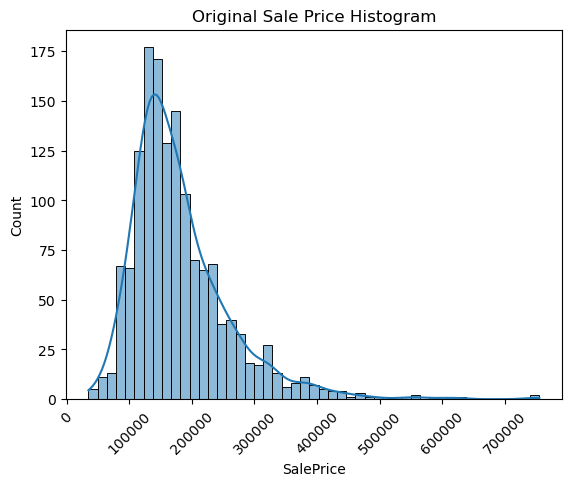
타깃 데이터 값이 중심에서 왼쪽으로 치우친 형태로 정규분포에서 벗어나 있음.
log1p()로 로그변환 후 다시 결괏값을 expm1()로 환원하면 됨.
plt.title('Log Transformed Sale Price Histogram')
log_SalePrice = np.log1p(house_df['SalePrice'])
sns.histplot(log_SalePrice, kde=True)
plt.show()이해가 안됨. 다시 복귀하면 원본이랑 똑같아져서 의미 없어지는 거 아님?
은별 💬
훈련할 때만 로그 변환을 적용함. 그리고 계속 처리할 데이터는 원래 스케일로 복귀하기
훈련할때만 정규화 된 결과를 적용하기
- Null 값 피처 삭제
PoolQC, MiscFeature, Alley, Fence, FireplaceQu 삭제
나머지 Null피처는 숫자형의 경우 평균값으로 대체
# SalePrice 로그 변환
original_SalePrice = house_df['SalePrice']
house_df['SalePrice'] = np.log1p(house_df['SalePrice'])
# Null 이 너무 많은 컬럼들과 불필요한 컬럼 삭제
house_df.drop(['Id','PoolQC' , 'MiscFeature', 'Alley', 'Fence','FireplaceQu'], axis=1 , inplace=True)
# Drop 하지 않는 숫자형 Null컬럼들은 평균값으로 대체
house_df['LotFrontage'].fillna(house_df['LotFrontage'].mean(),inplace=True)
house_df['MasVnrArea'].fillna(house_df['MasVnrArea'].mean(),inplace=True)
house_df['GarageYrBlt'].fillna(house_df['GarageYrBlt'].mean(),inplace=True)
# LotFrontage , MasVnrArea, GarageYrBlt has null
# Null 값이 있는 피처명과 타입을 추출
null_column_count = house_df.isnull().sum()[house_df.isnull().sum() > 0]
print('## Null 피처의 Type :\n', house_df.dtypes[null_column_count.index])책에서 에러 발생하는 부분 수정
- 문자형 피처는 원-핫 인코딩 변환
get_dummies()는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값을 0으로 변환, 별도의 Null 값을 대체하는 로직이 필요 없음.
선형 회귀 모델 학습/예측/평가
타깃값인 SalePrice 로그 변환, 예측값 로그 변환된 SalePrice 값을 기반으로 예측하므로 원본 SalePrice 예측값의 로그 변환 값
>> 따라서 예측 결과 오류에 RMSE만 적용 하면 RMSLE가 자동으로 측정
def get_rmse(model):
pred = model.predict(X_test)
mse = mean_squared_error(y_test, pred)
rmse = np.sqrt(mse)
print(model.__class__.__name__, '로그 변환된 RMSE:', np.round(rmse, 3))
return rmse- 선형 회귀 모델 학습
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice',axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2, random_state=156)
# LinearRegression, Ridge, Lasso 학습, 예측, 평가
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge()
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso()
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)[Output]
LinearRegression 로그 변환된 RMSE: 0.01
Ridge 로그 변환된 RMSE: 0.01
Lasso 로그 변환된 RMSE: 0.018
[0.010481899993240616, 0.00997580081727205, 0.01795924469011489]>> 라쏘 회귀의 경우 많이 떨어지는 결과를 보임
- 회귀 계수 시각화
회귀 계수 값의 상위 10개, 하위 10개의 피처에 대한 막대 그래프 출력
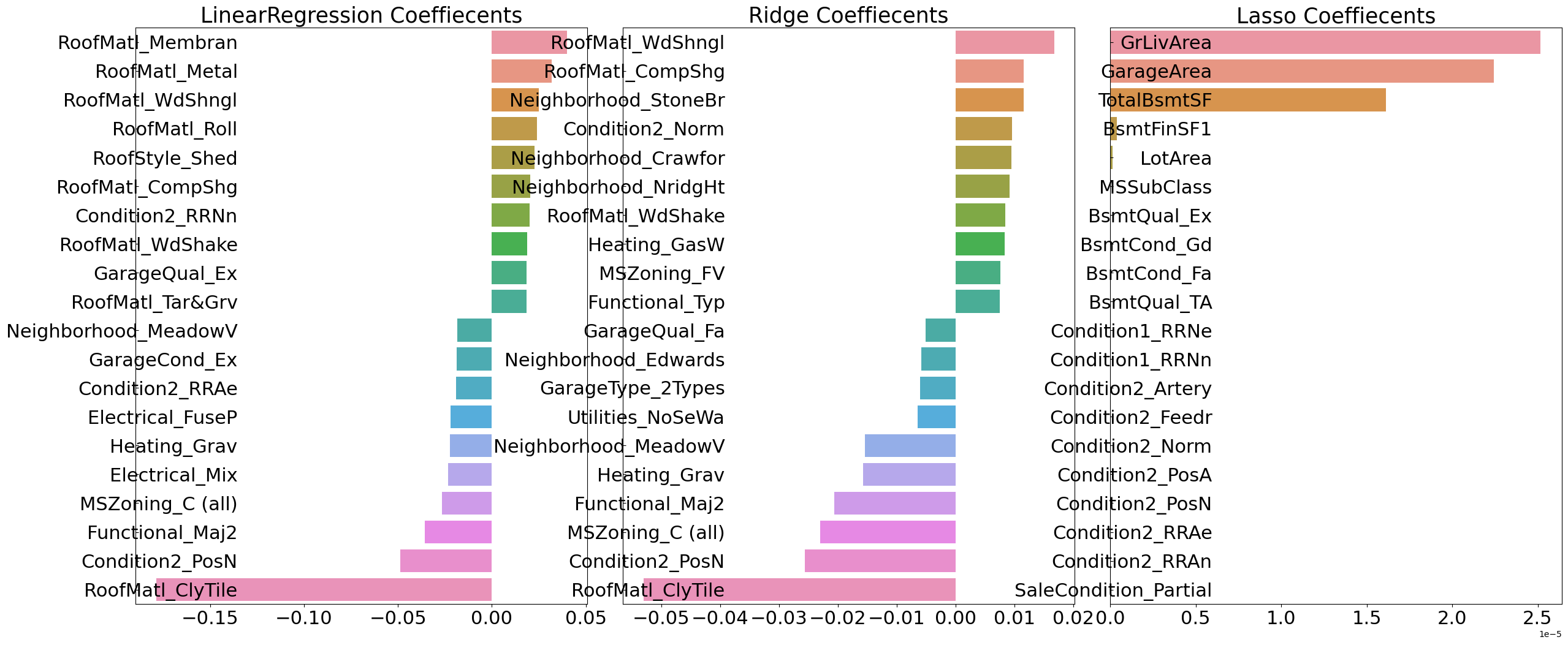
라쏘의 전체적 회귀 계수값이 매우 작고, YearBuilt가 가장 크고 다른 피처의 회귀 계수는 너무 작음.
I. 라쏘 회귀 개선
1. 학습 데이터 분할 방식 개선
5개 교차 검증 폴드 세트로 훈련세트 분할
from sklearn.model_selection import cross_val_score
def get_avg_rmse_cv(models):
for model in models:
#분할하지 않고 전체 데이터로 cross_val_score() 수행. 모델별 CV RMSE값과 평균 RMSE 출력
rmse_list = np.sqrt(-cross_val_score(model, X_features, y_target,
scoring="neg_mean_squared_error", cv=5))
rmse_avg = np.mean(rmse_list)
print('\n{0} CV RMSE 값 리스트: {1}'.format(model.__class__.__name__, np.round(rmse_list, 3)))
print('{0} CV 평균 RMSE 값: {1}'.format(model.__class__.__name__, np.round(rmse_avg, 3)))
# 앞 예제에서 학습한 ridge_reg, lasso_reg 모델의 CV RMSE 값 출력
models = [ridge_reg, lasso_reg]
get_avg_rmse_cv(models)2. 릿지와 라쏘 모델에 대한 최적 alpha 하이퍼파라미터 찾기
from sklearn.model_selection import GridSearchCV
def print_best_params(model, params):
grid_model = GridSearchCV(model, param_grid = params,
scoring = 'neg_mean_squared_error', cv=5)
grid_model.fit(X_features, y_target)
rmse = np.sqrt(-1*grid_model.best_score_)
print('{0} 5 CV 시 최적 평균 RMSE 값:{1}, 최적 alpha: {2}'.format(model.__class__.__name__,
np.round(rmse, 4), grid_model.best_params_))
ridge_params = {'alpha':[0.05, 0.1, 1, 5, 8, 10, 12, 15, 20]}
lasso_params = {'alpha': [0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1, 5, 10]}
print_best_params(ridge_reg, ridge_params)
print_best_params(lasso_reg, lasso_params)최적 alpha 값으로 모델의 학습/예측/평가를 재수행
II. 데이터 전처리
1. 피처 데이터 세트의 데이터 분포
피처 데이터 세트에 지나치게 왜곡된 피처가 존재할 경우 회귀 예측 성능을 저하시킬 수 있음
skew()
skewness(왜도), 데이터 분포에 비대칭 정도를 보여주는 수치
왜도 1이상의 값을 반환하는 피처만 추출해 왜곡 정도를 완화하기 위해 로그 변환을 적용. 숫자형 피처의 칼럼 index 객체를 추출해 숫자형 칼럼 데이터 세트의 apply lambda식 skew()를 호출해 숫자형 피처의 왜곡 정도 출력
from scipy.stats import skew
# object가 아닌 숫자형 피처의 칼럼 index 객체 추출.
features_index = house_df.dtypes[house_df.dtypes != 'object'].index
# house_df에 칼럼 index를 [ ]로 입력하면 해당하는 칼럼 데이터 세트 반환. apply lambda로 skew( ) 호출
skew_features = house_df[features_index].apply(lambda x : skew(x))
# skew(왜곡) 정도가 1 이상인 칼럼만 추출.
skew_features_top = skew_features[skew_features > 1]
print(skew_features_top.sort_values(ascending=False))❗️ 원-핫 인코딩 카테고리 숫자형 피처는 제외 - 인코딩 시 당연히 왜곡될 가능성 큼
추출된 왜곡 정도가 높은 피처를 로그변환
house_df[skew_features_top.index] = np.log1p(house_df[skew_features_top.index])2. 이상치 데이터
3개 모델에서 모두 가장 큰 회귀 계수 GrLivArea 피처의 데이터 분포 분석
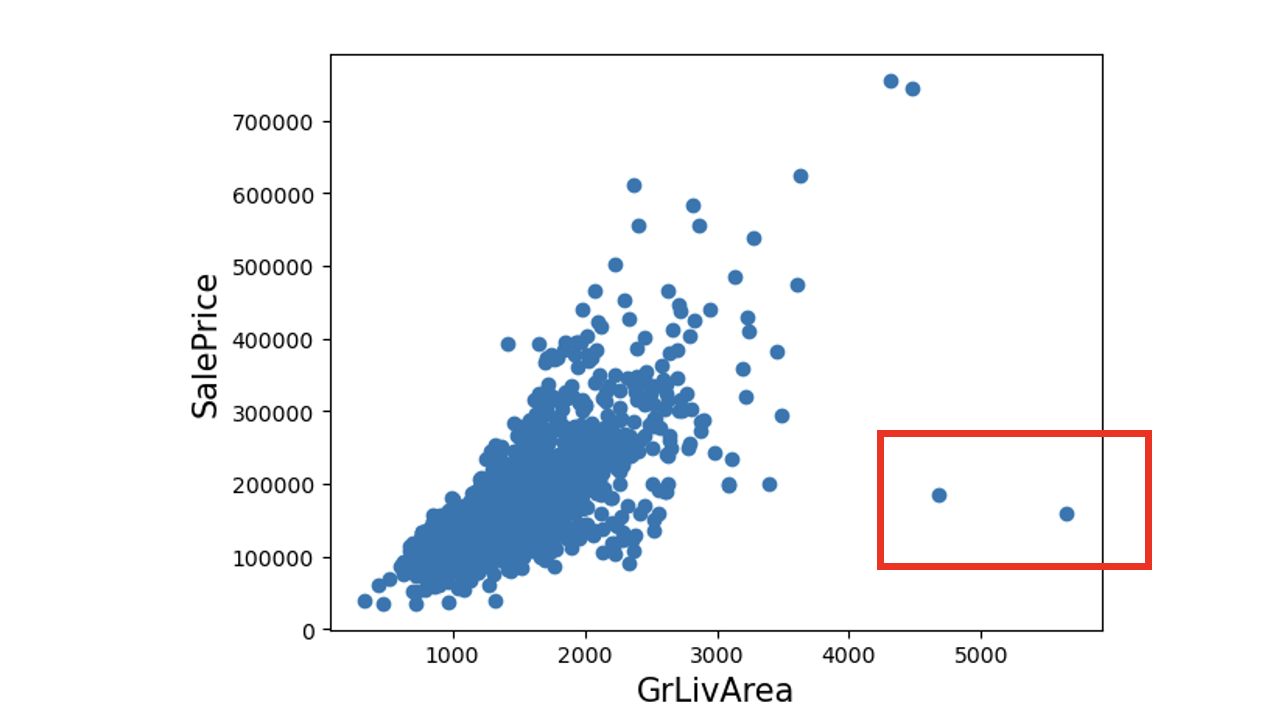
outlier 데이터로 간주하고 전부 삭제
(단 모두 로그 변환된 데이터이므로 이를 반영해 이상치 데이터로 분류해야 됨 -> log1p(x)로 제한)
# GrLivArea와 SalePrice 모두 로그 변환되었으므로 이를 반영한 조건 생성.
cond1 = house_df_ohe['GrLivArea'] > np.log1p(4000)
cond2 = house_df_ohe['SalePrice'] < np.log1p(500000)
outlier_index = house_df_ohe[cond1 & cond2].index"머신러닝 알고리즘을 적용하기 이전에 완벽하게 데이터의 선처리 작업을 수행하라는 의미는 아닙니다. 일단 대략의 데이터 가공과 모델 최적화를 수행한 뒤 다시 이에 기반한 여러 가지 기법의 데이터 가공과 하이퍼 파라미터 기반의 모델 최적화를 반복적으로 수행하는 것이 바람직한 모델 생성 과정" (p.390, 파이썬 머신러닝 완벽 가이드)
회귀 모델의 예측 결과 혼합을 통한 최종 예측
개별 회귀 모델의 예측 결괏값을 혼합해 이를 기반으로 최종 회귀 값을 예측
➢ 서로 다른 모델의 예측값을 합쳐도 됨!
- A모델과 B 모델, 두 모델의 예측값이 있다면 A모델 예측 값의 40%, B 모델 예측값의 60%를 더해서 최종 회귀 값으로 예측하는 것
Ex) A 회귀 모델 예측값 [100. 80, 60]
B 회귀 모델 예측값 [120. 80, 50]
최종 회귀 예측값 : [100*0.4 + 120*0.6, 80*0.4 + 80*0.6, 60*0.4 + 50*0.6] = [112, 80, 54]pred = 0.4 * ridge_pred + 0.6 * lasso_pred
각 모델의 예측값을 계산한 뒤 개별 모델과 최종 혼합 모델의 RMSE 구하기
def get_rmse_pred(preds):
for key in preds.keys():
pred_value = preds[key]
mse = mean_squared_error(y_test , pred_value)
rmse = np.sqrt(mse)
print('{0} 모델의 RMSE: {1}'.format(key, rmse))
# 개별 모델의 학습
ridge_reg = Ridge(alpha=8)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
# 개별 모델 예측
ridge_pred = ridge_reg.predict(X_test)
lasso_pred = lasso_reg.predict(X_test)
# 개별 모델 예측값 혼합으로 최종 예측값 도출
pred = 0.4 * ridge_pred + 0.6 * lasso_pred
preds = {'최종 혼합': pred,
'Ridge': ridge_pred,
'Lasso': lasso_pred}
#최종 혼합 모델, 개별모델의 RMSE 값 출력
get_rmse_pred(preds)스태킹 앙상블 모델을 통한 회귀 예측
분류에서 배운 스태킹 앙상블 하나도 기억나지 않는다...
2가지 모델 필요, 개별적인 기반 모델과 이 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
- 최종 메타 모델이 학습할 피처 데이터 세트는 원본 학습 피처 세트로 학습한 개별 모델의 예측값을 스태킹 형태로 결합한 것
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수.
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds ):
# 지정된 n_folds값으로 KFold 생성.
kf = KFold(n_splits=n_folds, shuffle=False)
#추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0] ,1 ))
test_pred = np.zeros((X_test_n.shape[0],n_folds))
print(model.__class__.__name__ , ' model 시작 ')
for folder_counter , (train_index, valid_index) in enumerate(kf.split(X_train_n)):
#입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 셋 추출
print('\t 폴드 세트: ',folder_counter,' 시작 ')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
#폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행.
model.fit(X_tr , y_tr)
#폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장.
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1,1)
#입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장.
test_pred[:, folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1,1)
#train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터
return train_fold_pred , test_pred_mean함수 내에서는 개별 모델이 K-fold 세트로 설정된 폴드 세트 내부에서 원본의 학습 데이터를 다시 추출해 학습과 예측을 수행한 뒤 그 결과를 저장합니다. 저장된 예측 데이터는 추후에 메타 모델의 학습 피처 데이터 세트로 이용됩니다. 함수 내에서 폴드 세트 내부 학습 데이터로 학습된 개별 모델이 인자로 입력된 원본 테스트 데이터를 예측한 뒤, 예측 결과를 평균해 테스트 데이터로 생성
- 최종 메타 모델인 라쏘 모델에 적용
# 개별 모델이 반환한 학습 및 테스트용 데이터 세트를 Stacking 형태로 결합.
Stack_final_X_train = np.concatenate((ridge_train, lasso_train,
xgb_train, lgbm_train), axis=1)
Stack_final_X_test = np.concatenate((ridge_test, lasso_test,
xgb_test, lgbm_test), axis=1)
# 최종 메타 모델은 라쏘 모델을 적용.
meta_model_lasso = Lasso(alpha=0.0005)
#기반 모델의 예측값을 기반으로 새롭게 만들어진 학습 및 테스트용 데이터로 예측하고 RMSE 측정.
meta_model_lasso.fit(Stack_final_X_train, y_train)
final = meta_model_lasso.predict(Stack_final_X_test)
mse = mean_squared_error(y_test , final)
rmse = np.sqrt(mse)
print('스태킹 회귀 모델의 최종 RMSE 값은:', rmse)3. Medical Cost Personal
개인 보험료 예측
여러 feature을 가진 사람의 보험료를 예측 (age, sex, bmi, children, smoker, region)
=> 의료보험 데이터를 활용해 한 사람이 보험료를 얼마나 낼지를 예측하는 회귀 문제
분석 방법
- 각 feature 별로 데이터 전처리
- 이상치 데이터 제거
- Linear Model, Decision Tree, Ensemble(Random Forest, AdaBoost, Gradient Bossting), Boosting(XGBoost, LightGBM)
Data Description
Age: 피보험자의 나이
Sex: 피보험자의 성별
BMI: 피보험자의 체질량 지수
Children: 피보험자의 자녀의 수
Smoker: 흡연 여부 (yes / no)
Region: 피보험자가 거주하는 지역 (Southeast / Southwest / Northeast / Northwest)
Charges: 보험료
Exploratory Data Analysis
- object형은 나중에 핫-인코딩 적용 필요
- NaN이나 Null이 없어 따로 null 처리가 필요 없음
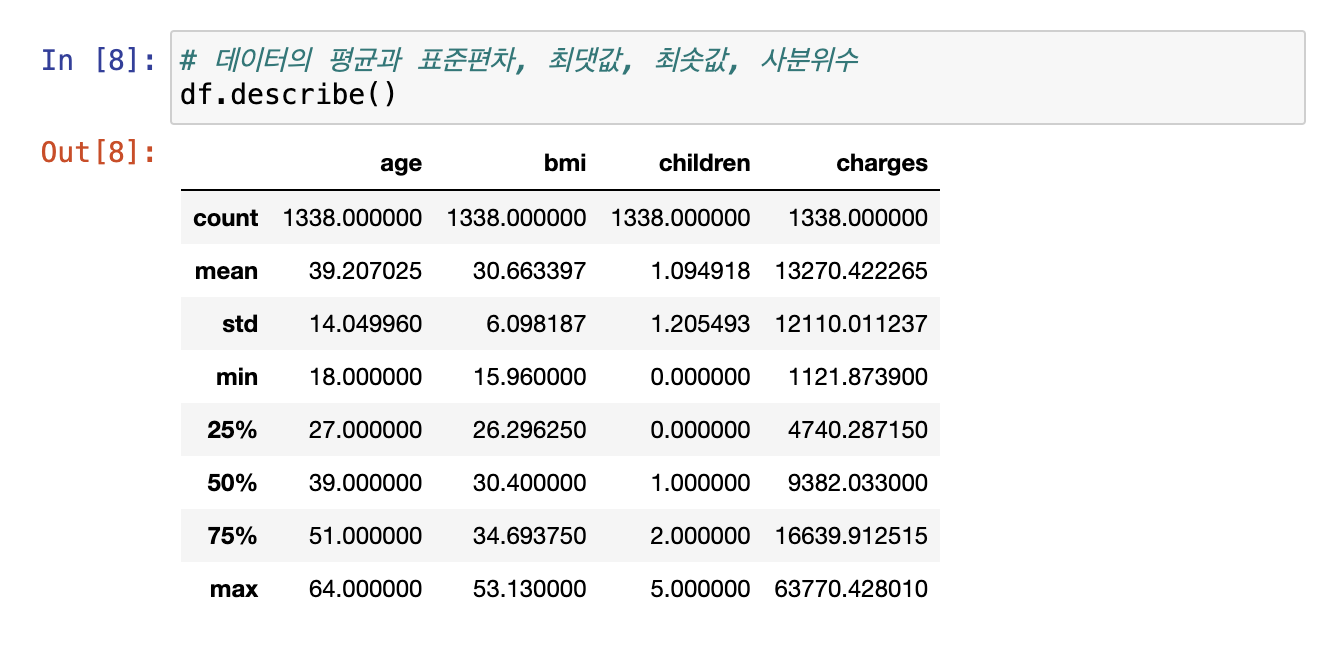
- 자녀의 표준편차가 평균과 유사하다는 문제 존재
- charges 혼자 자리 수 다름! -> 하지만 종속변수이므로 scaling 불필요 (독립변수였다면 scaling 필수)
Visualization
피처들의 분포 확인
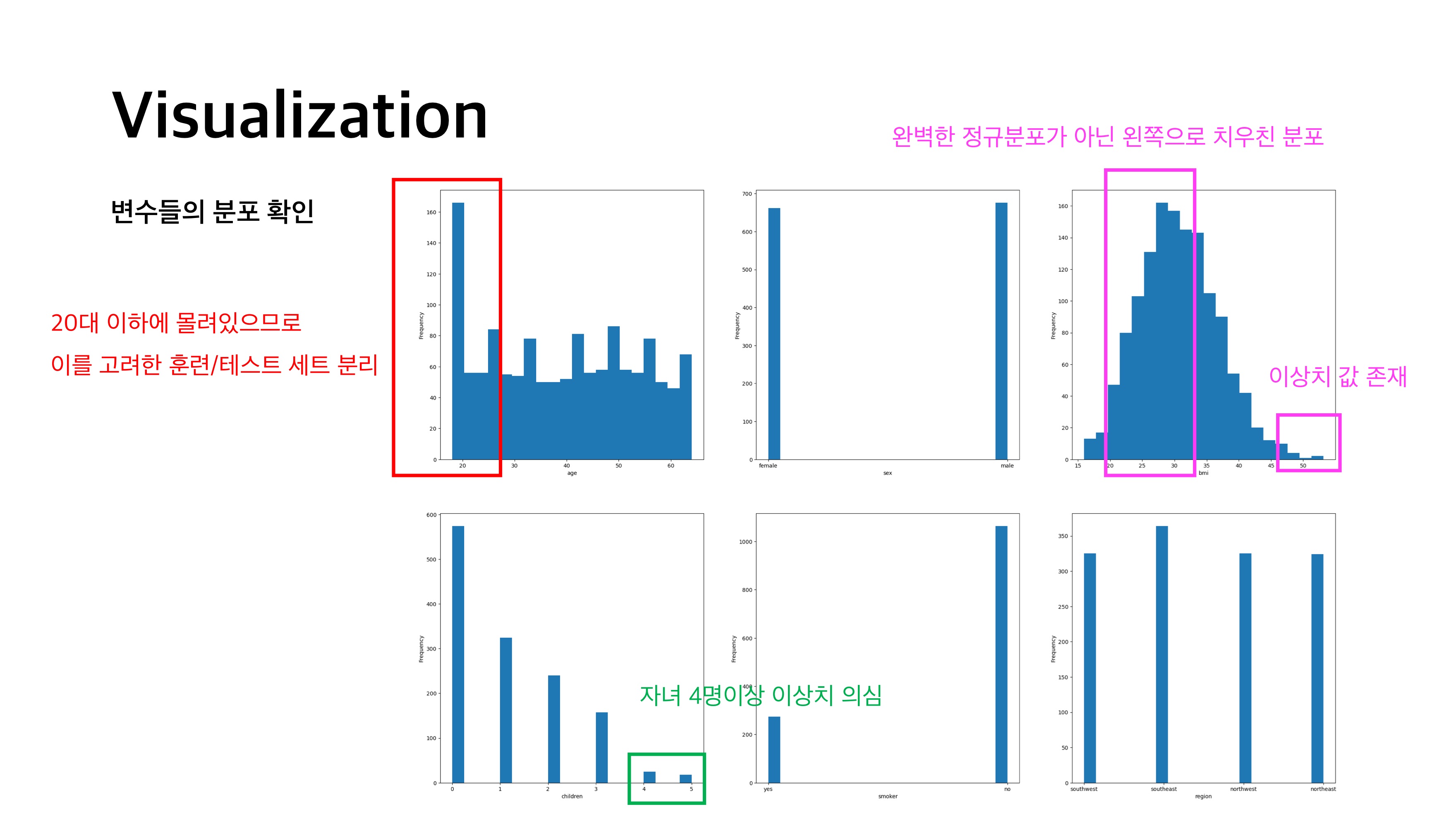
(위 개선사항들을 생각해볼 수 있음 -> 차차 고려해볼 것!)
상관관계
상관관계
두 변수 사이 상관관계 정도를 나타내는 수치
두 변수에 대한 산점도에서 점들이 얼마나 직선에 가까운가의 정도를 나타내는 데 쓰이는 척도
(큰 상관계수 값이 항상 두 변수 사이 어떤 인과관계를 의미하지 않음
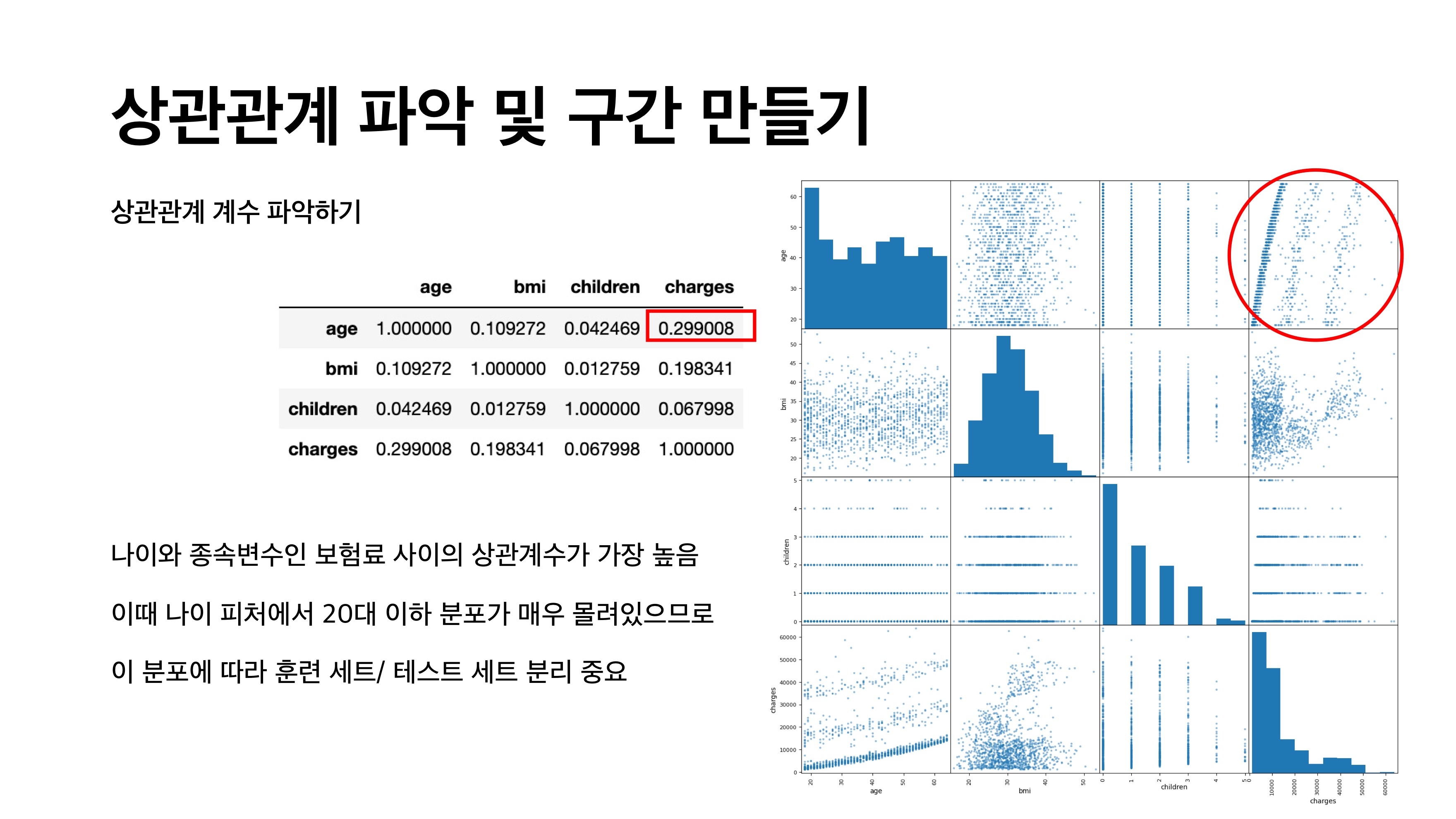
age 피처와 charges 피처의 상관관계 계수 높음 >> 그래프에서 직선형으로 매우 뚜렷함
age 피처에 대한 개선이 ► 전체 모델의 개선으로 이어짐!!
age 구간 나누기
# 연령별 구간 설정
bins = [0, 20, 25, 30, 35, 40, 45, 50, 55, 60, np.inf]
age_bin = pd.cut(df['age'], bins=bins, labels=[i+1 for i in range(len(bins)-1)])
# len(bins)
# age_bin
df['age_bin'] = age_bin
df.head()이상치 탐지
분류 세션에서 배웠던 box plot으로 이상치를 확인해보자면
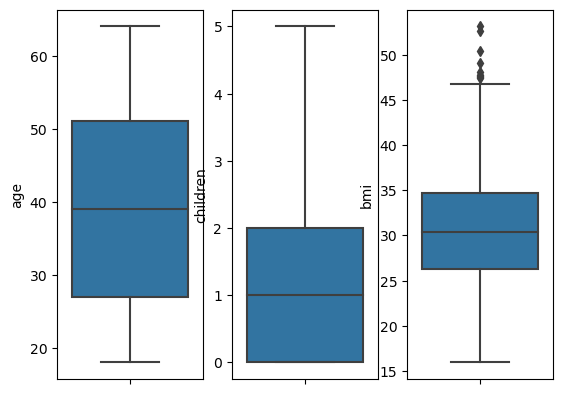
bmi 이상치 있음!! bmi 이상치 제거 필요~!
그럼 이상치를 어떻게 제거하느냐?
유명한 이상치 제거 기법
IQR을 통한 이상치 제거
# IQR(Q3 - Q1)로부터 이상치 파악하기
bmi_q1 = df['bmi'].quantile(q=0.25)
bmi_q3 = df['bmi'].quantile(q=0.75)
iqr = bmi_q3 - bmi_q1
# (q1 - (iqr * 1.5))와 (q3 + (iqr * 1.5))를 벗어난 값이 이상치
condi1 = (df['bmi'] < (bmi_q1 - (1.5 * iqr)))
condi2 = (df['bmi'] > (bmi_q3 + (1.5 * iqr)))
outliers = df[condi1 | condi2]
outliers['bmi'] Scaling, Transforming and Encoding
- Scaling 소개


//ppt 저작권은 저한테 있습니당~
- Scaling 모델 각각 적용해보기
#숫자형 변수에 대해 Box-Cox transformation, Quantile transformation, 그리고 로그 변환
#Scaling
to_scale = ['age', 'bmi', 'children', 'charges']
df_to_scale = df[to_scale].copy()
quantile = QuantileTransformer(n_quantiles=100, random_state=42, output_distribution='normal') #1000개 분위를 사용해 데이터를 균등분포
power = PowerTransformer(method= 'yeo-johnson') #데이터의 특성별로 정규분포형태에 가깝도록 변환
q_scaled = quantile.fit_transform(df_to_scale)
yj = power.fit_transform(df_to_scale)
q_scaled_df = pd.DataFrame(q_scaled, columns=to_scale)
scaled_df = pd.DataFrame(yj, columns=to_scale)
logged_df = pd.DataFrame(np.log1p(df_to_scale), columns=to_scale)
fig, ax = plt.subplots(4, 4, figsize=(40, 30))
for i in range(4):
idx = 0
for j in range(4): #subplot들의 열
colname = to_scale[idx]
if i == 0 :
ax[i][j].hist(df_to_scale[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Frequency')
elif i == 1:
ax[i][j].hist(scaled_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Transformed Frequency')
elif i == 2:
ax[i][j].hist(q_scaled_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Transformed Frequency')
elif i == 3:
ax[i][j].hist(logged_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Logged Frequency')
idx += 1 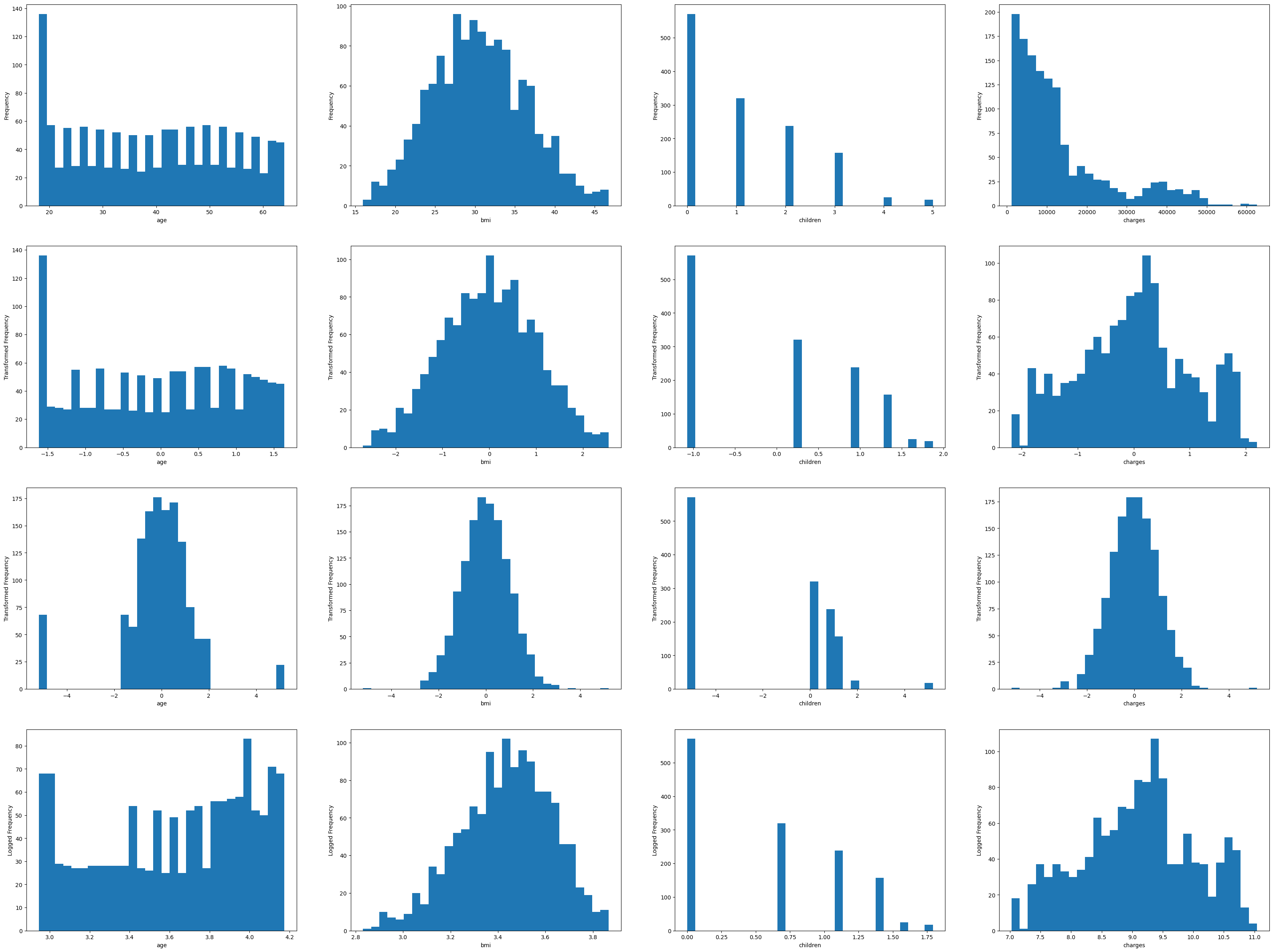
Target값과 BMI가 가장 정규분포화된 QuantileTransformer모델 선택!
QuantileTransformer을 이용해 훈련 세트, 테스트 세트 재처리
#Quantile Transformation
to_scale = ['age', 'bmi']
quantile = QuantileTransformer(n_quantiles=10, random_state=0, output_distribution='normal')
for col in to_scale:
quantile.fit(X_train[[col]])
X_train[col] = quantile.transform(X_train[[col]]).flatten()
X_test[col] = quantile.transform(X_test[[col]]).flatten()이때 BMI 피처만 스케일을 변환했으므로 다른 피처들의 단위 분포를 BMI에 맞춰주기 위해 standard scaling도 진행
- One-Hot encoding
카테고리 피처(문자열 피처)를 정수형으로 변환
/> sex, region, smoker 피처 변환 필요

Model Selection
많은 회귀 모델들을 적용해 어떤 모델이 가장 성능이 좋은지를 판단하자!
# default 모델을 설정한 뒤, cross-validation을 통해 성능을 평가
lr = LinearRegression()
enet = ElasticNet(random_state=42)
dt = DecisionTreeRegressor(random_state=42)
rf = RandomForestRegressor(random_state=42)
ada = AdaBoostRegressor(random_state=42)
gbr = GradientBoostingRegressor(random_state=42)
xgb = XGBRegressor(random_state=42)
lgbm = LGBMRegressor(random_state=42)
models = [lr, enet, dt, rf, ada, gbr, xgb, lgbm]
# 평가지표 RMSE
for model in models:
name = model.__class__.__name__
scores = cross_val_score(model, X=X_train, y=y_train, cv=5, scoring='neg_mean_squared_error', n_jobs=-1)
mse = (-1) * np.mean(scores) # negative mean squared error로 설정했으므로 -1을 곱해 부호를 맞춰줍니다.
print('Model %s - RMSE: %.4f' % (name, np.sqrt(mse)))[Output]
Model LinearRegression - RMSE: 6415.7267
Model ElasticNet - RMSE: 9609.0652
Model DecisionTreeRegressor - RMSE: 6377.2354
Model RandomForestRegressor - RMSE: 4917.3047
Model AdaBoostRegressor - RMSE: 5211.7117
Model GradientBoostingRegressor - RMSE: 4695.0703
Model XGBRegressor - RMSE: 5302.2534
Model LGBMRegressor - RMSE: 4827.5845
Hyperparameter Tuning
Gradient Boosting Regressor, LightGBM, Random Forest 하이퍼파라미터 튜닝

