이 글에서는 Feature Selection 중 Wrapper 방식에 속하는 Boruta algorithm 에 관해 작성해보고자 합니다.
여기서 Wrapper 방식은 변수의 일부만을 사용해 모델링을 수행하고 그 결과를 확인하는 작업을 반복하여 변수를 선택하는 방법으로, 예측 정확도 측면에서 가장 좋은 성능을 보이는 부분집합을 뽑아내는 방법입니다. 일반적으로 Filter 방식보다 정확도가 높습니다. Filter 방식에 관한 글은 여기서 확인할 수 있습니다.
Boruta algorithm
보루타 알고리즘은 랜덤포레스트를 기반으로 변수를 선택하는 Wrapper 방식으로, 기본 아이디어는 기존 변수를 복원추출해서 만든 변수보다 모형 생성에 영향을 주지 못했다고 하면 이는 중요도가 낮은 변수로 인식하여 제거하는 것입니다.
즉, 특성이 타겟 변수에 유의미한 영향을 미치는지 평가하여 중요한 특성만 남기는 것이 알고리즘의 목적인 것이죠.
본격적으로 보루타 알고리즘에 관해 알아보기 전에, 용어 정리를 하고 넘어가겠습니다.
셰도우 변수 (shadow features; permuted copies)
원본 데이터의 독립변수를 복사하여 생성된 변수들로, 이 변수는 원본 변수와 같은 데이터 분포를 가지지만 예측에는 아무런 의미가 없도록 무작위로 섞습니다. 일반적으로 통계를 얻기 위해 5개 이상을 섀도우 변수로 만듭니다.
여기서 왜 랜덤하게 섞는 것일까?
: 타겟변수와의 연관성을 없애기 위함입니다. 원본 특성의 중요도가 무작위 특성보다 통계적으로 유의미하게 높은지를 검정합니다.
그럼 보루타 알고리즘의 절차를 살펴볼까요?
Boruta 알고리즘 절차
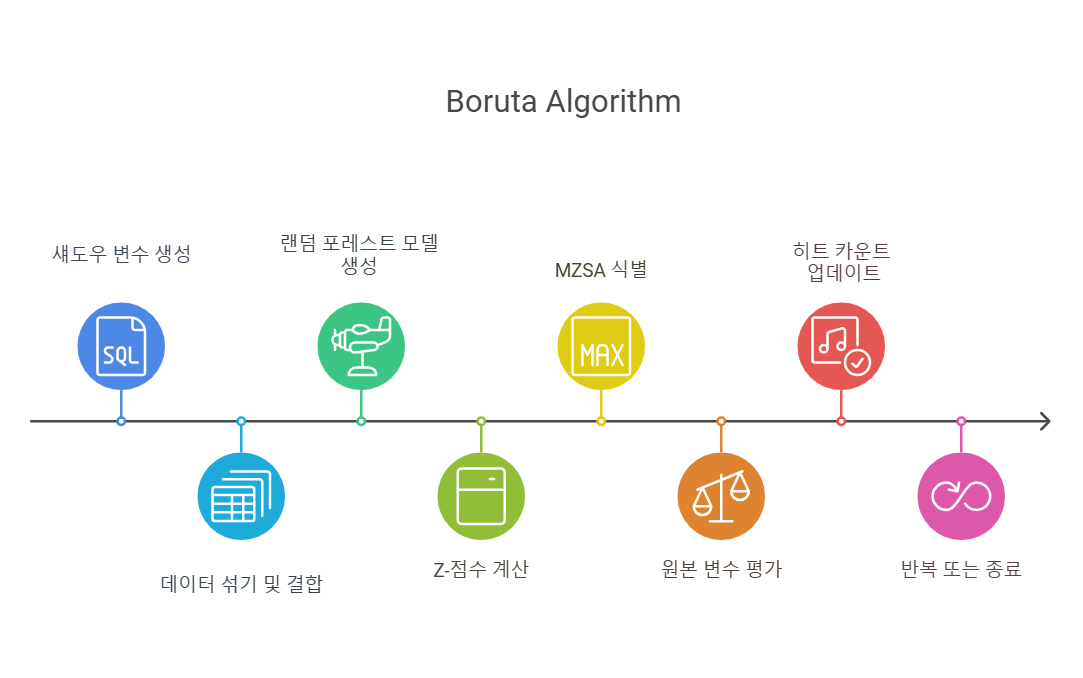
-
섀도우 변수를 생성합니다.
-
반응변수와의 상관을 제거하기 위해 복제된 자료를 랜덤하게 섞고 원본 데이터와 섀도우 변수를 결합합니다.
-
결합된 데이터와 원 데이터에 대해 랜덤포레스트 모형을 생성하고, 변수 중요도를 계산합니다.
- 이때 변수 중요도는 Z-score로 계산합니다.
- ((각 트리에 대한 손실) - (전체 트리의 정확도 손실의 평균)) / (정확도 손실의 표준편차)
- 섀도우 변수 중 가장 높은 Z-score(MZSA, Max Z-score among shadow attributes)가 원본 변수의 Z-score를 평가할 기준이 됩니다.
- 이 값보다 높은 Z-score를 가진 원본 변수가 중요한 변수로 분류됩니다.
-
원 자료에 대한 Z-score가 MZSA보다 큰 경우 Hit을 +1 해줍니다.
-
위 과정을 랜덤포레스트가 수행되는 횟수만큼 또는 모든 변수들이 중요한 변수와 중요하지 않은 변수로 태그될 때까지 반복합니다.
python code
알고리즘 작동 원리에 관해 알아보았으니, 간단히 코드는 어떻게 사용하는지 정리해보겠습니다.
패키지를 불러옵니다.
from sklearn.ensembel import RandomForestRegressor
#pip install boruta
from boruta import BorutaPyrf = RandomForestRegressor(n_estimators=100, random_state=615)
selector = BorutaPy(verbose=2, estimator=rf, n_estimator='auto', max_iter=10)여기서 verbose 매개변수는 BorutaPy 라이브러리에서 실행 중에 출력되는 로그 메세지의 양을 제어합니다. 이 매개변수는 디버깅이나 모델의 동작을 이해하는 데 매우 유용합니다.
- verbose=0: 아무런 메시지도 출력하지 않습니다.
- verbose=1: 기본적인 정보만 출력합니다.
- verbose=2: 상세한 정보를 출력합니다.
accept = X_train.columns[selector.support_].to_list()선택된 변수를 확인할 수 있습니다. 이렇게 선택된 변수를 가지고 다른 모델에 적용해 예측을 해볼 수 있겠죠?
알고리즘의 원리를 알고 코드를 적용해보니 잘 이해가 되었습니다. 처음에 배울 때는 코드에만 집중해서 알고리즘 자체를 모르는 것들이 많은데, 요즘은 왜 알고리즘부터 알아야하는지 느끼고 있습니다. 다음 글에서는 SHAP에 관해 작성해볼 예정입니다 !
