오늘은 feature selection 중 model dependency를 통한 방법에 관해 이야기해보고자 합니다. filter method에 관해서는 이 글에서 확인 가능합니다.
목차
1. SFS
2. RFE, RFECV
SFS
먼저 SFS는 Sequential Feature Selection으로, feature를 하나씩 추가하거나 제외하면서 모델의 성능을 높이는 변수를 탐색하는 방법입니다. 설명에서도 알 수 있듯, SFS는 모델에 의존하는 model denpendency 방식입니다.
하나씩 feature를 추가하면서 교차 검증을 수행한 후 교차 검색 점수를 최대화하는 feature를 찾으며, 이 때의 교차 검색 점수는 평균 score로 계산됩니다.
코드로 살펴보기 전에, 각 파라미터에 관해 조금 더 알아보겠습니다.
- forward
빈 집합에서 시작하여 특징을 하나씩 추가합니다. - backward
모든 특징을 포함한 상태에서 시작하여 하나씩 제거합니다. - floating
이전 결정들을 재검토하고 모델 성능에 따라 조정함으로써 더 유연하고 최적의 특징 집합을 찾을 수 있게 합니다.
각각은 이렇게 코드로 구현해볼 수 있겠죠?
sfs_forward = SFS(model, k_features= 'best', forward=True, floating=False, scoring='accuracy', cv=3)
sfs_backward = SFS(model, k_features= 'best', forward=False, floating=False, scoring='accuracy', cv=3)
sfs_stepwise = SFS(model, k_features= 'best', forward=True, floating=True, scoring='accuracy', cv=3)
sfs_forward_f = sfs_forward.fit(X_train, y_train)
sfs_backward_f = sfs_backward.fit(X_train, y_train)
sfs_stepwise_f = sfs_stepwise.fit(X_train, y_train)#결과 확인
print('forward 피처 출력: ', sfs_forward_f.k_feature_names_)
print('backward 피처 출력: ', sfs_backward_f.k_feature_names_)
print('stepwise 피처 출력: ', sfs_stepwise_f.k_feature_names_)
저는 가장 대표적인 타이타닉 데이터에서 실행해보았는데, forward와 backward에서 차이가 나타났고, stepwise는 forward 방식에서 floating의 변화만 준 것이라 유사한 결과가 나왔습니다.

시각화한 결과는 다음과 같습니다.
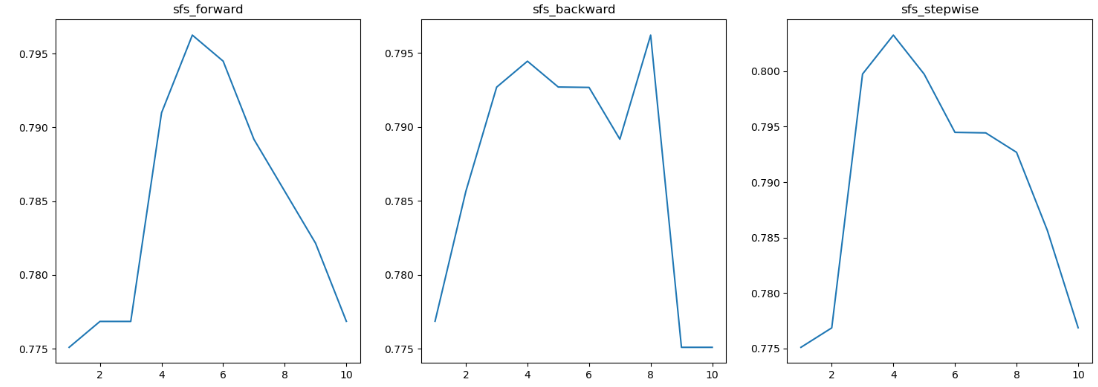
forward에서 x축은 선택된 특징의 개수이며, backward에서 x축은 제외한 특징의 개수입니다.
y축은 각 특징 집합의 평균 점수입니다.
가장 높은 특징 집합의 평균 점수를 갖는 지점에서 feature들을 select했을 것입니다.
RFE, RFECV
RFE는 Recursive Feature Elimination으로 모든 feature들로부터 feature들 하나하나 제거하면서 원하는 개수의 feature가 남을 때까지 이를 반복합니다. 이 방식 역시 회귀나 분류 모델을 학습시키면서 특성의 중요도를 평가하는 model dependency 방식이죠.
모든 feature를 활용하여 모델이 데이터를 학습했을 때, feature importance를 도출하여 가장 낮은 feature를 하나 제거하고 다시 학습합니다. 이 과정을 반복하는 것입니다.
RFECV는 Recursive Feature Elimination with Cross Validation으로, RFE의 확장 버전으로 생각하면 쉽습니다. RFE는 최적 피쳐 수를 지정해주어야하는 반면, RFECV는 교차검증을 통해 최적의 특성 수를 자동으로 결정합니다.
도메인 지식이 없다면, 유용하게 쓰일 방법이라고 생각했습니다. 그럼 코드로 살펴볼까요?
#RFE
selector = RFE(estimator=model, n_features_to_select=2)
selector = selector.fit(X, y)#RFECV
cv = StratifiedKFold(3)
selector = RFECV(estimator = model, step=1, cv=cv)
selector = selector.fit(X, y)이를 타이타닉 데이터에 활용해보았습니다. 또한, 여러 모델에 이를 적용하여 선택된 feature들을 정리해보았습니다.
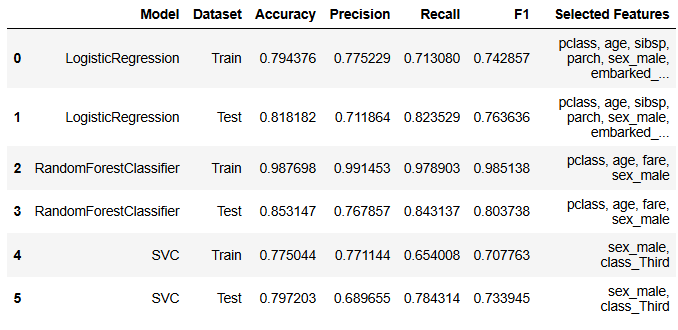
데이터프레임으로 저장한 결과는 다음과 같습니다. 같은 selector인데도 모델에 따라 다른 결과가 나오는 것을 확인할 수 있었습니다.
이를 통해 적용할 후보 모델들에 대해 모두 다르게 실행해보는 것이 필요하겠다고 생각했습니다.
여러 프로젝트를 진행하며 나름대로 전처리를 꼼꼼히 하고 있다고 생각했는데, 요즘 드는 생각은 아직 공부할 게 너무 많다입니다.. 다양한 방식들을 공부하면서 재미를 느끼고 있는 요즘입니다..!ㅎㅎ 계속 배우고 적용하며 제 방식으로 만들어볼게요 !
