요즘 학회에서 업무를 하며 실무 경험을 쌓는 도중 느낀 점은 생각보다 실무에서는 모델링할 일이 없다.를 느꼈습니다. 대부분 업무가 요청 받은 업무를 살펴보고 이에 맞는 데이터를 찾아 인사이트를 주는 것에 초점이 맞춰있어서 실제 모델링을 하여 예측하는 일이 거의 없었습니다.
그래서 더더욱 2과목 준비를 하면서 오랜만에 모델링을 해본다고 생각이 들었답니다..😂 오랜만에 하니까 재밌는 거 같기도?
- 데이터 살펴보기 (EDA)
- 데이터 전처리: 결측치 처리, 데이터 타입 확인, 사용할 피처 정하기, ...
- 모델링
크게 이렇게 세 단계를 거쳐 진행하게 됩니다.
Titanic Data
가장 유명한 타이타닉 데이터로 해보았습니다.
어느 정도 개수의 피처가 들어가야 성능이 나오기 때문에, 최대한 많은 피처를 가져가보자는 것이 제 생각이었습니다.
1. 데이터 살펴보기
# 데이터 확인
print(X_train.head())
print(y_train.head())
# 데이터 타입 확인
X_train.info()
# 결측치 확인
X_train.isnull().sum()2. 데이터 전처리
기본적으로 수치형 변수들은 다 가져가고, object 중 범주형은 가져가기로 했습니다.
범주형
따라서, 범주형인 'Embarked'에 대해 최빈값으로 결측치 처리를 해줍니다. 결측치가 하나였기 때문에 최빈값으로 대체했습니다.
# 결측치 처리
X_train['Embarked'] = X_train['Embarked'].fillna(X_train['Embarked'].mode())
X_test['Embarked'] = X_test['Embarked'].fillna(X_test['Embarked'].mode())그 다음, 범주형 중 'Sex'와 'Embarked'는 수치형으로 바꾸기 위해 get_dummies()를 사용합니다.
# object 타입: 원핫인코딩
X_train_dum = pd.get_dummies(X_train[['Sex', 'Embarked']])
X_train = pd.concat([X_train, X_train_dum], axis=1)
X_train.drop(columns=['Sex', 'Embarked', 'Ticket', 'Cabin', 'Name'], inplace=True)
X_test_dum = pd.get_dummies(X_test[['Sex', 'Embarked']])
X_test = pd.concat([X_test, X_test_dum], axis=1)
X_test.drop(columns=['Sex', 'Embarked', 'Ticket', 'Cabin', 'Name'], inplace=True)이렇게 따로따로 해서 합치지 말고, 특정 피처에 대해 바로 수행하는 방법도 있습니다.
X_train = pd.get_dummies(X_train, columns= cols)수치형
수치형 변수 중 'Age'는 결측치가 많았기 때문에 평균 또는 중앙값으로 대체합니다. 이 둘이 비슷했기 때문에, 소수점 방지를 위해 중앙값으로 대체했습니다.
# 결측치 처리: age
X_train['Age'] = X_train['Age'].fillna(X_train['Age'].median())
X_test['Age'] = X_test['Age'].fillna(X_test['Age'].median())모델링에 필요한 데이터셋
'PassengerId'는 훈련에 필요없는 피처이기 때문에 삭제하는데, 나중에 제출 형식과의 충돌이 생길 수 있어 따로 변수에 저장합니다.
# 사용할 데이터 만들기
X = X_train.drop(columns=['PassengerId'], axis=1)
test = X_test.drop(columns=['PassengerId'], axis=1)
y = y_train['Survived']3. 모델링
가장 무난한 RandomForest를 사용하여 예측합니다.
이 문제에서는 생존을 예측하는 거라서 Classifier를 사용해줍니다.
# train
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=64)
model.fit(X, y)
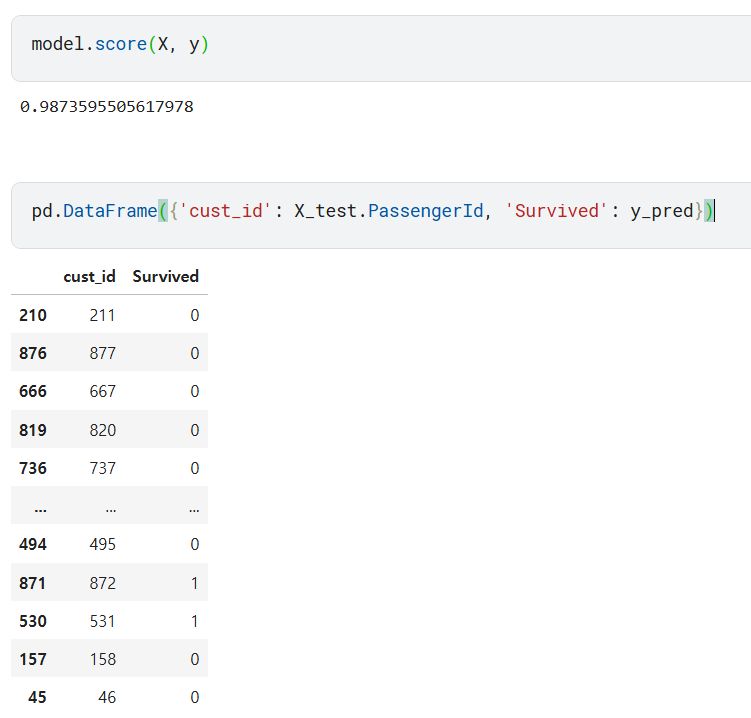
y_pred = model.predict(test)model.score(X, y)RandomForest에서는 .score가 정확도(accuracy)를 의미하는데, 저는 0.987이 나왔으니 좋은 성능을 보였다고 할 수 있습니다.
분류 문제에서 확률로 예측하기
.predict_proba(test)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=2022)
model.fit(train, target)
predictions = model.predict_proba(test)결과 데이터 프레임에 저장
output = pd.DataFrame({'pred': y_pred})결측치 처리 후 원핫인코딩
최빈값으로 결측치 처리 후 최빈값인지 아닌지로 원핫인코딩 진행
fillna(최빈값) -> (X[열]==최빈값).astype(int)
mode_workclass = X_train['workclass'].mode()[0]
X['workclass'] = X_train['workclass'].fillna(mode_workclass)
test['workclass'] = X_test['workclass'].fillna(mode_workclass)
X['workclass_mode'] = (X['workclass'] == mode_workclass).astype(int)
test['workclass_mode'] = (test['workclass'] == mode_workclass).astype(int)
X.drop(columns=['workclass'], inplace=True)
test.drop(columns=['workclass'], inplace=True)특정 데이터타입만 추출
X_train = X_train.select_dtypes(exclude=['object'])범주형 유형이 너무 많을 때, 결측치 처리
from sklearn.impute import SimpleImputer
col = X_train.select_dtypes(include='object').columns
imp = SimpleImputer(strategy = 'most_frequent')
X_train[col] = imp.fit_transform(X_train[col])즉 SimpleImputer를 사용할 때는 범주형과 숫자형을 구분하여 사용해야합니다.
여기서 strategy의 디폴트 값은 평균이므로, 범주형 및 문자형 변수를 넣게 되면 오류가 나는 것이죠.
2과목 파이프라인 정리
- 데이터 확인: .head(), .info(), 결측치 확인
- 데이터 전처리: 결측치 처리, 문자형 변수 처리, 스케일링
- 모델 학습: train 데이터셋을 train과 val로 나누어 훈련하고 모델 평가 후 test 데이터셋 적용해서 결론
(기본) RandomForest -> 과적합 시 max_depth 또는 n_estimators 값 조정
RandomForest 모델의 파라미터 또는 모델 평가 지표에 대한 사용법 혹은 함수가 떠오르지 않는다면,
dir/help를 사용해주면 됩니다.import sklearn.metrics from sklearn.ensemble import RandomForestClassifier print(dir(sklearn.metrics)) print(help(RandomForestClassifier))이때 위와 같이 꼭 import 해준 뒤에 사용해야 올바르게 사용할 수 있습니다.
