EKS Observability
기본 설정 및 EFS 확인
EFS 확인 : AWS 관리 콘솔 EFS 확인

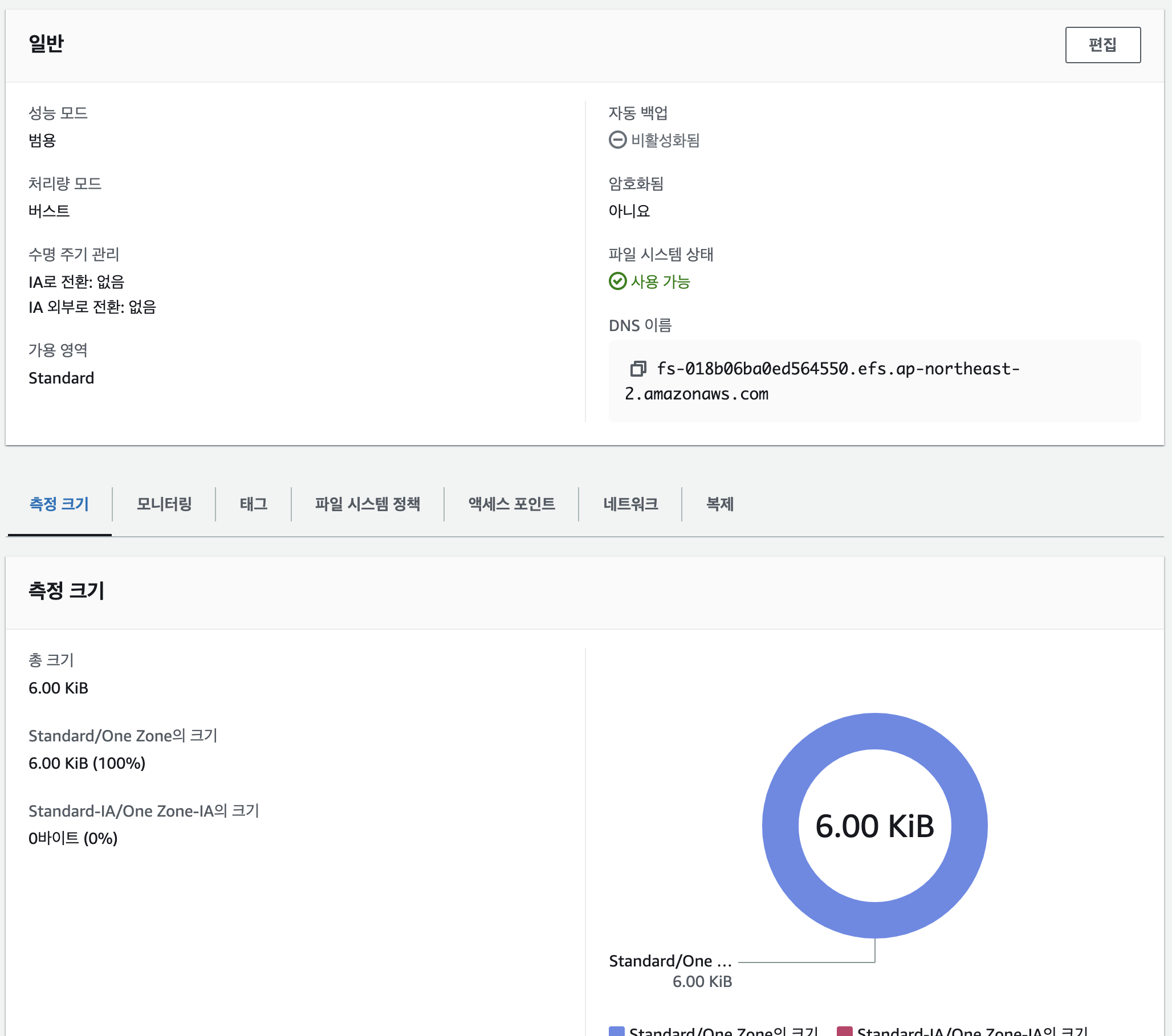
노드 정보 확인

AWS LB/ExternalDNS/EBS/EFS, kube-ops-view 설치
ExternalDNS

kube-ops-view
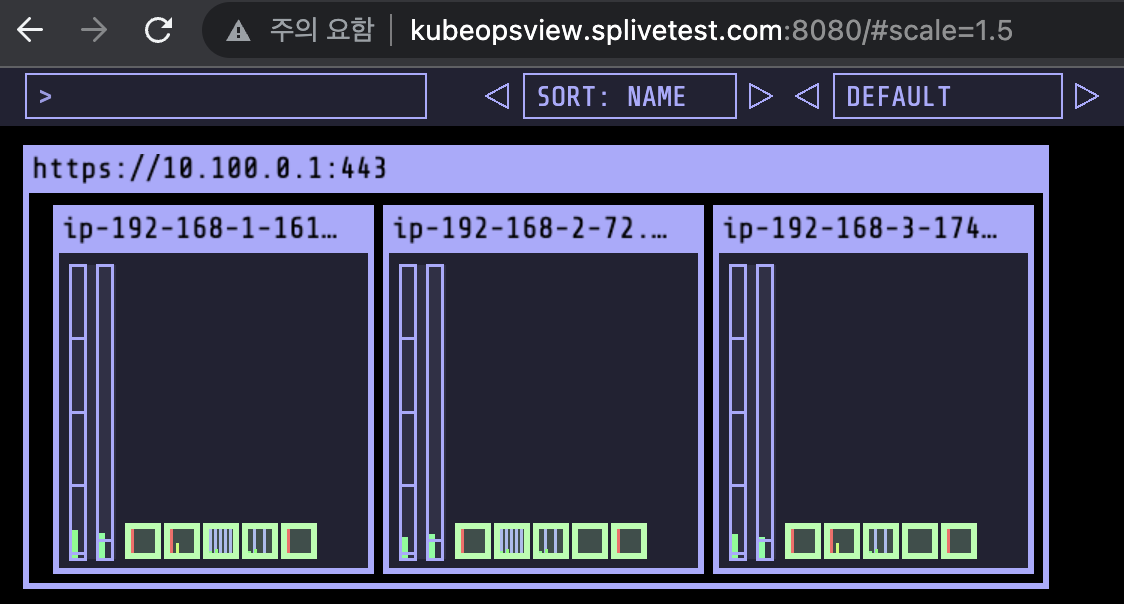
AWS LB Controller

EBS csi driver 설치 확인

gp3 스토리지 클래스 생성

EFS 스토리지클래스 생성 및 확인

설치 정보 확인



EKS Console
쿠버네티스 API를 통해서 리소스 및 정보를 확인 할 수 있음
You will be able to view and explore all standard Kubernetes API resource types such as configuration, authorization resources, policy resources, service resources and more
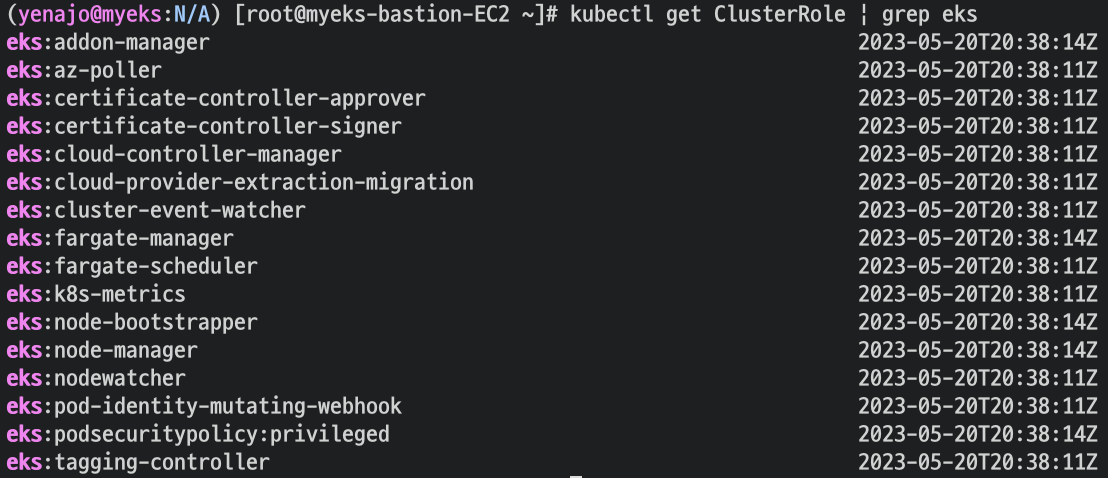
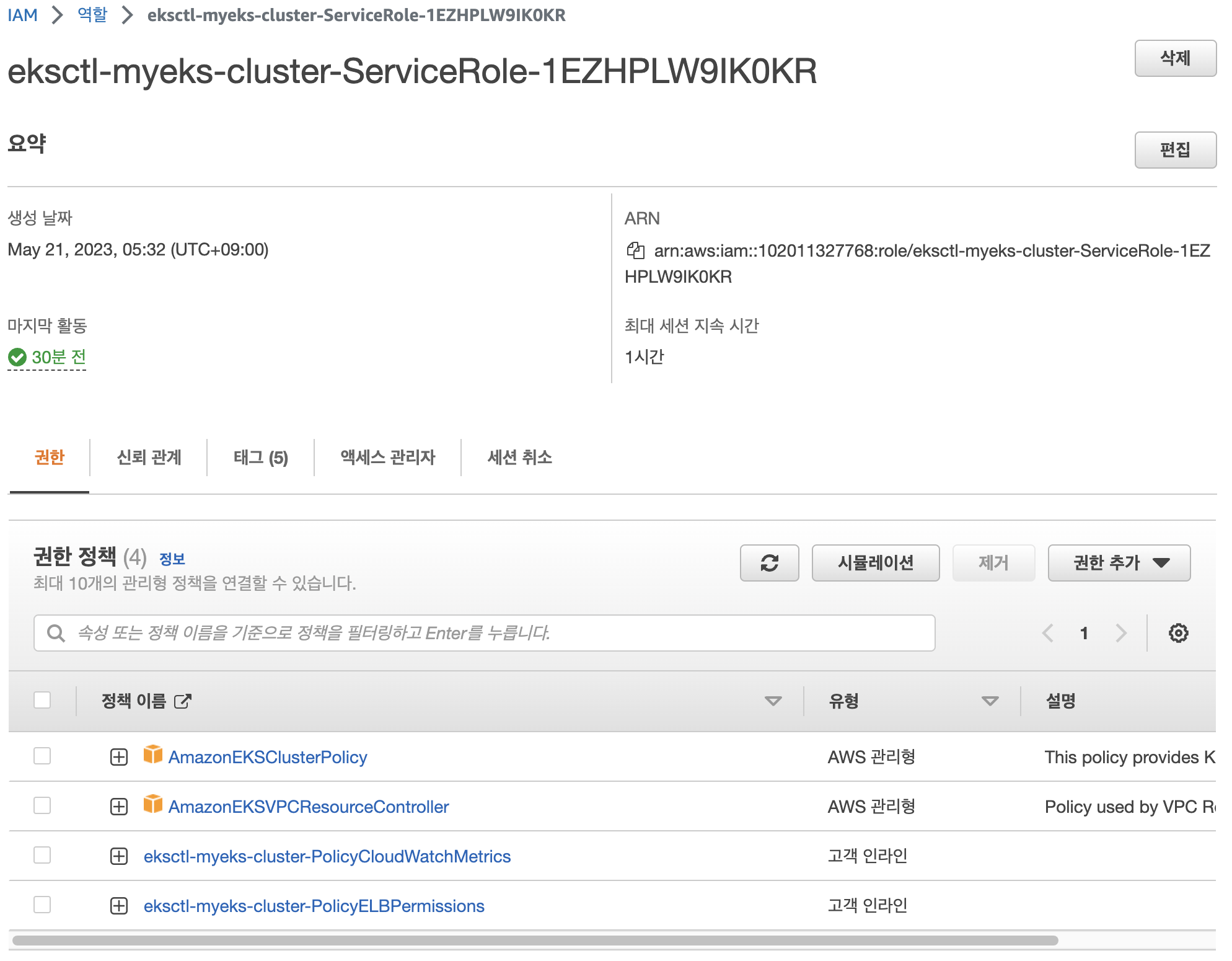
Logging in EKS
Control Plane logging
default 는 로깅이 켜져 있지 않음
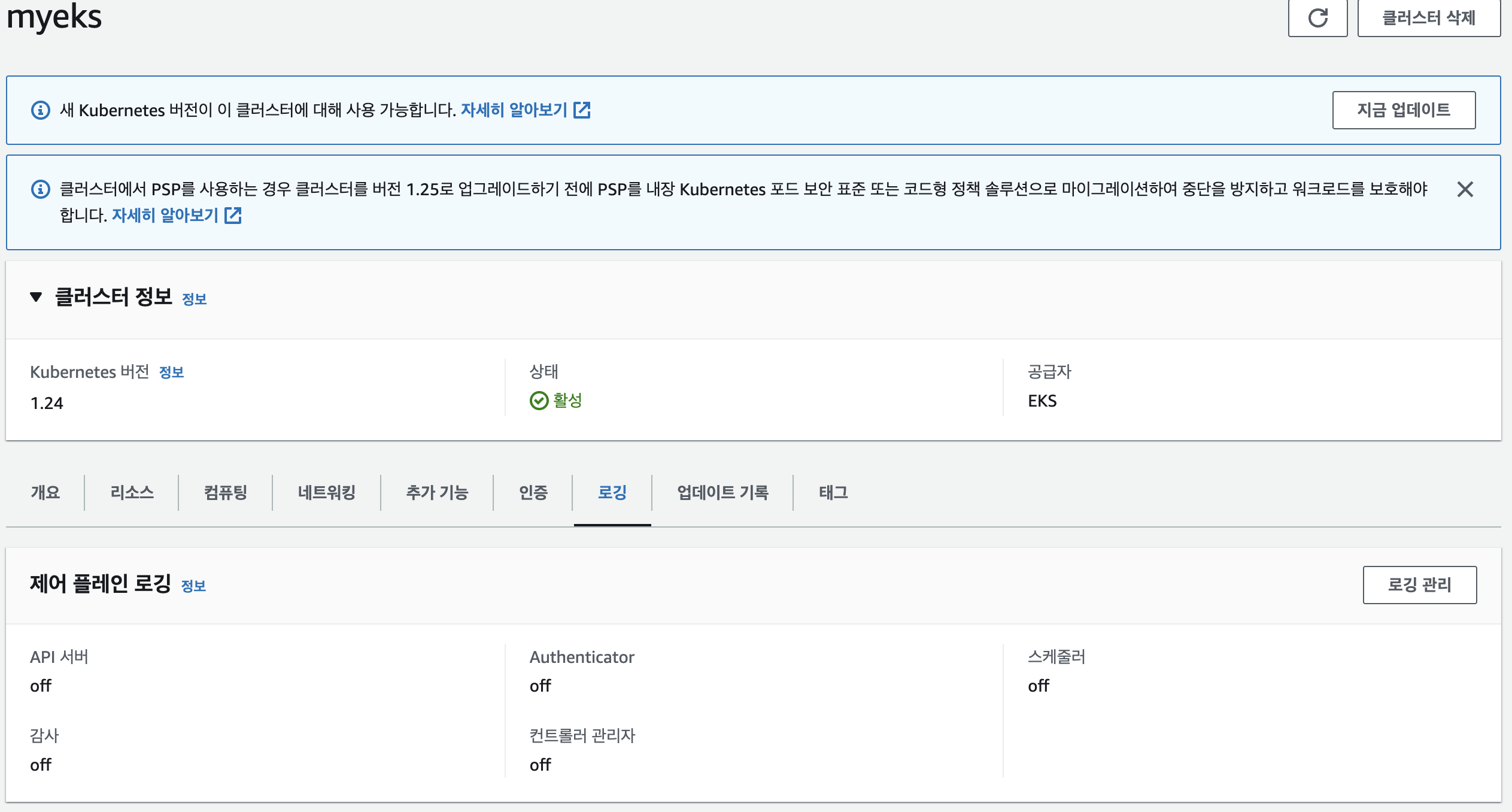
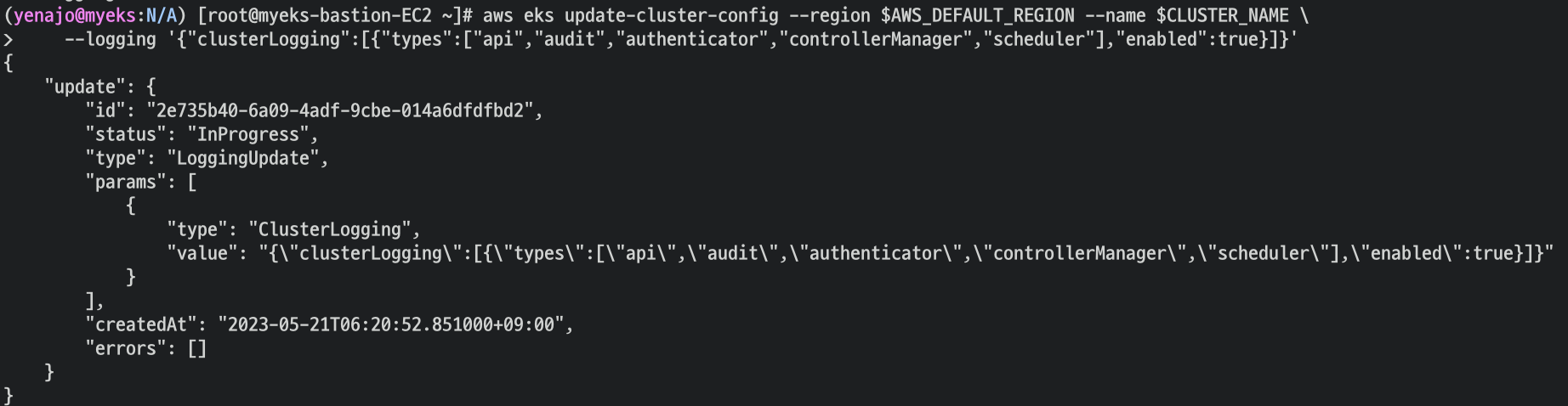
활성화
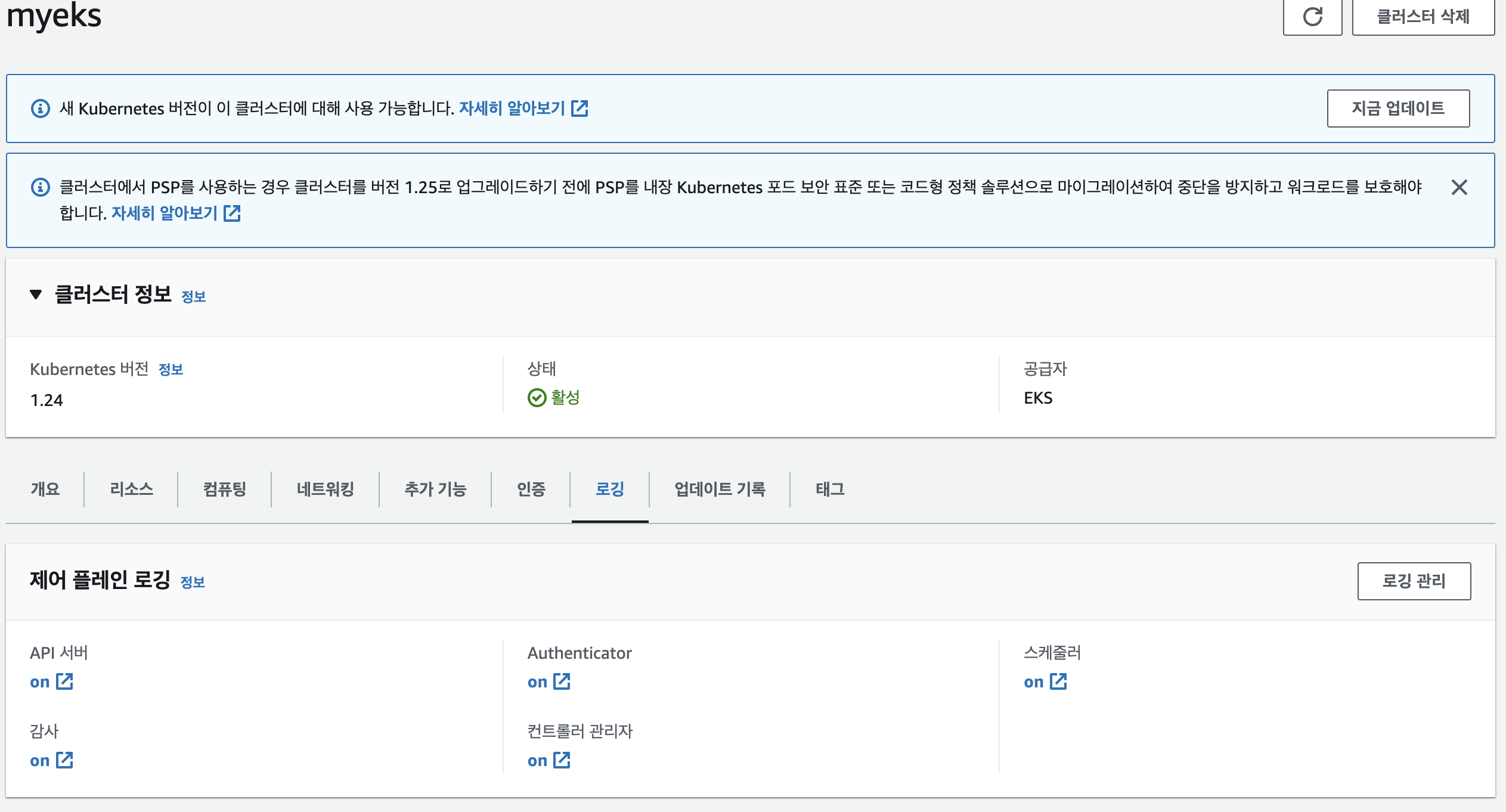
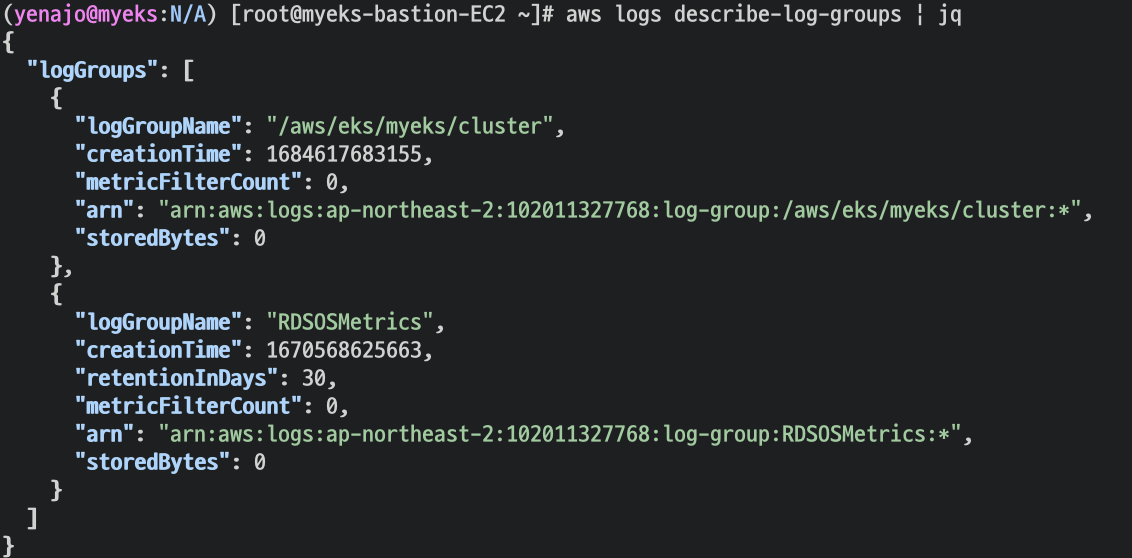
로그 그룹 확인
- 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more- 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow- 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>- 로그 스트림이름
aws logs tail /aws/eks/CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2- 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m- 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
CloudWatch Log Insights
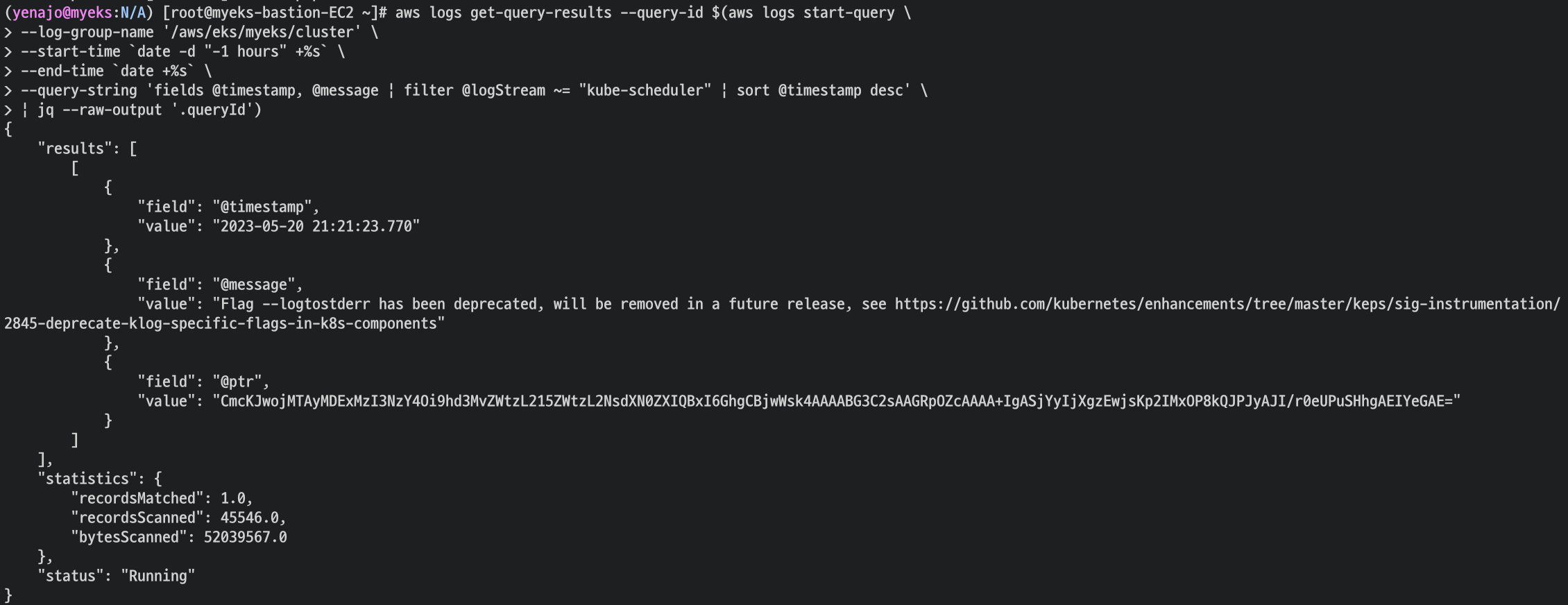
aws logs get-query-results --query-id $(aws logs start-query \
--log-group-name '/aws/eks/myeks/cluster' \
--start-timedate -d "-1 hours" +%s\
--end-timedate +%s\
--query-string 'fields @timestamp, @message | filter @logStream ~= "kube-scheduler" | sort @timestamp desc' \
| jq --raw-output '.queryId')
로깅 끄기
EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
Managing etcd database size on Amazon EKS clusters
How to monitor etcd database size? >> 아래 10.0.X.Y IP는 ETCD IP


컨테이너(파드) 로깅
확인
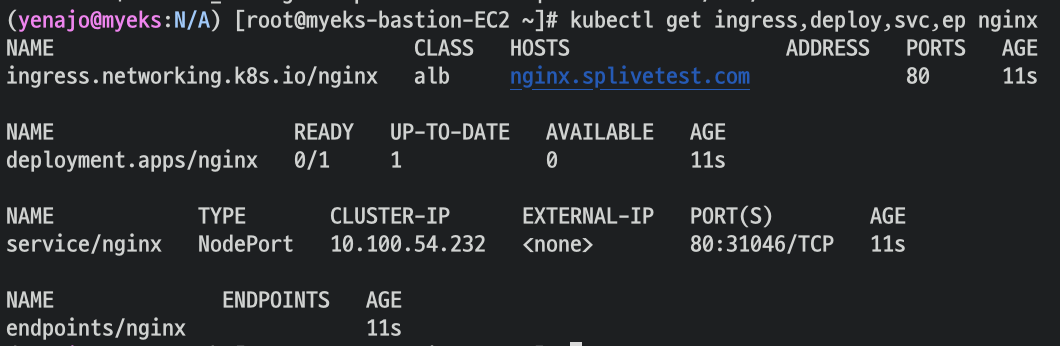
그런데.. 저는 왜 Address에 주소가 안나올까요? 콘솔에는 나오는 것 같은데..
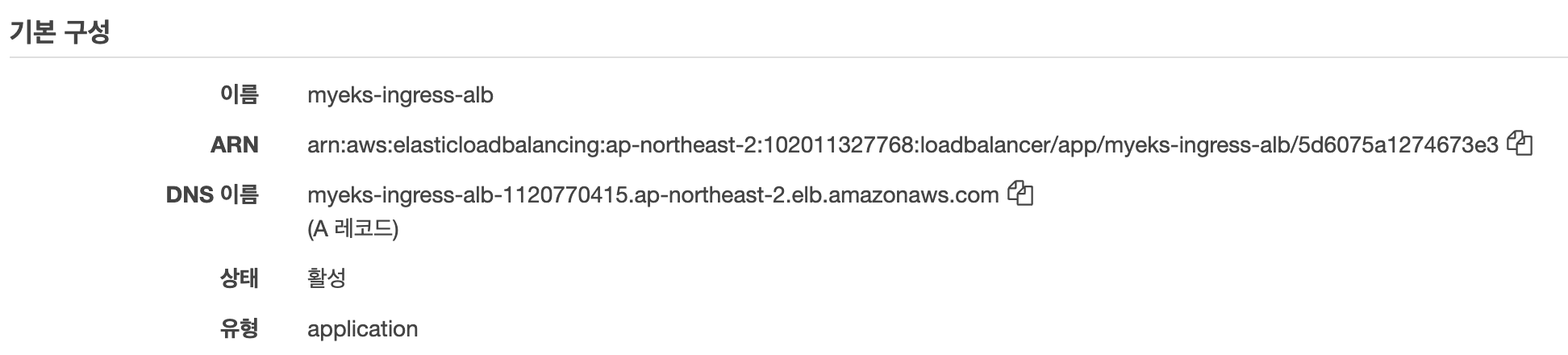
타겟그룹이 안묶이는 것 같은 느낌이다 다시 확인해볼 것
- 컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이,
애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이,
컨테이너 로그 파일 위치 확인

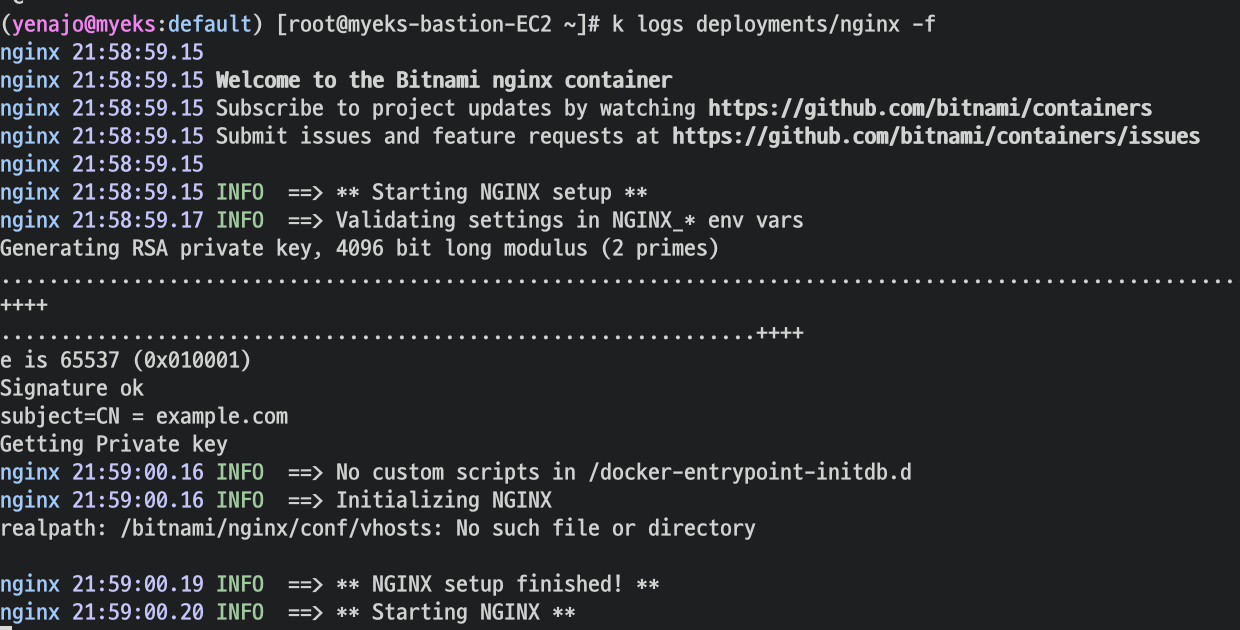
nginx 웹 서버 내에서 위 directory 안에 access , error 로그가 symbolic 링크가 걸려 있다.
kubectl logs로 pod내 로그가 output으로 나오는 것이 가능한 이유는
container이미지를 만들 때 중요한 로그를 stdout를 symbolic link를 걸고 error는 stterr로 symbolic link를 건다
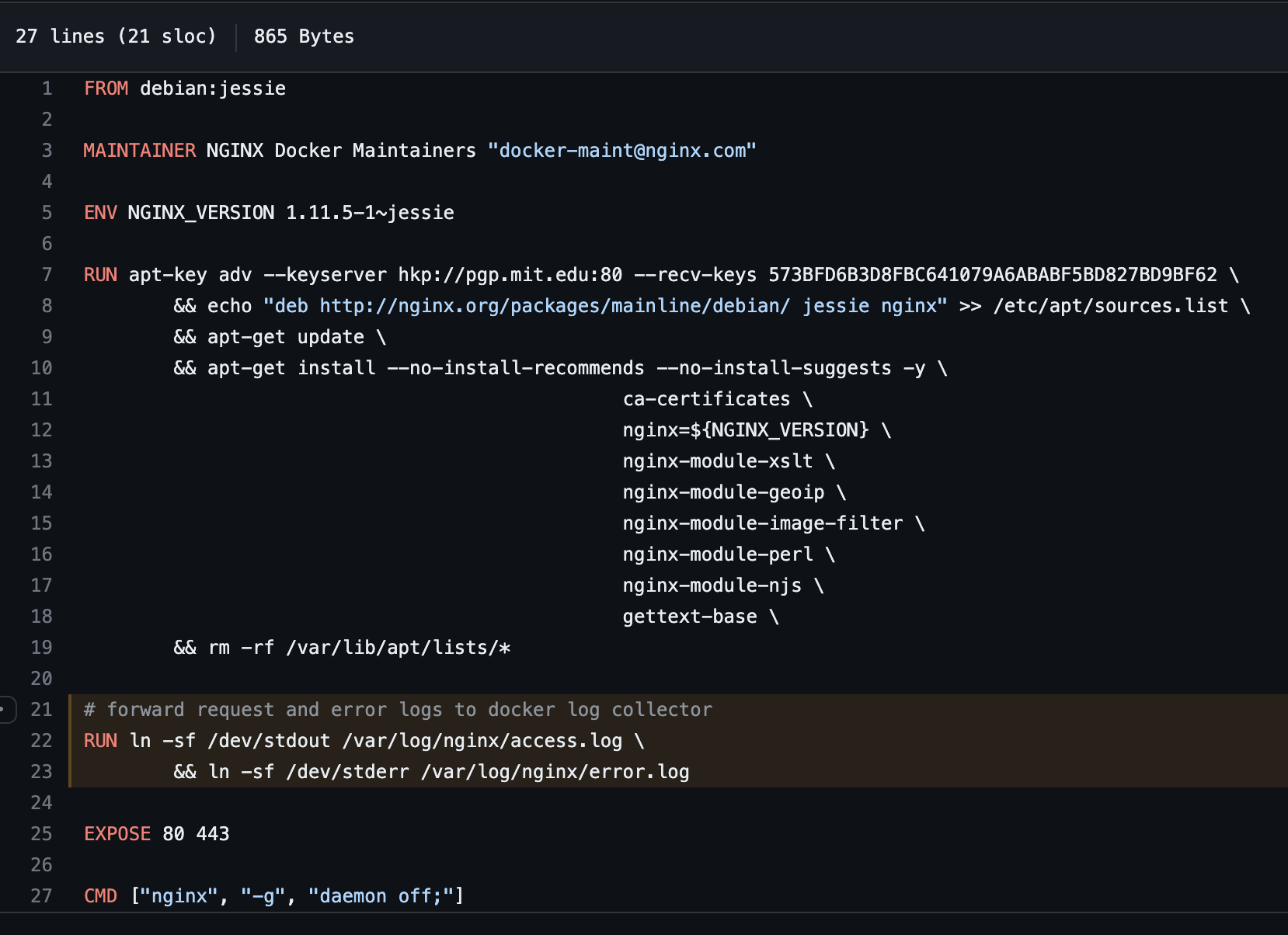
그래서 pod 내 직접 들어가지 않고도 로그 확인 가능한 것
이렇게 로그를 확인 하는 것의 단점은
1. 명령어로 확인이 가능하다
2. kubelet 기본 설정은 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하는 로그는 전체 로그 조회가 불가능함
Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
- CCI : CloudWatch Container Insight : 노드에 CW Agent 파드와 Fluent Bit 파드가 데몬셋으로 배치되어 Metrics 와 Logs 수집
- Fluent Bit (as a DaemonSet to send logs to CloudWatch Logs) Integration in CloudWatch Container Insights for EKS
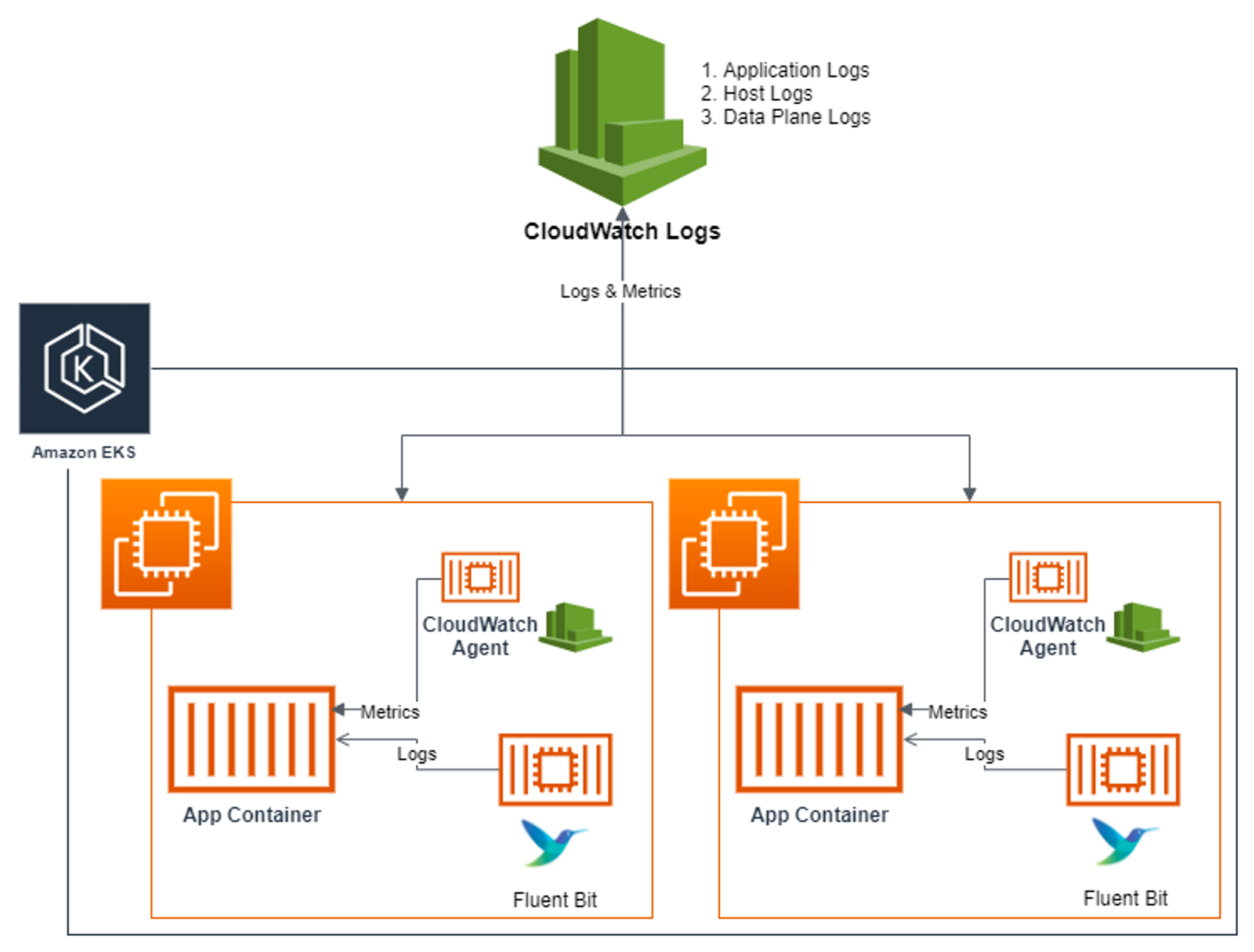
출처 : https://aws.amazon.com/ko/blogs/containers/fluent-bit-integration-in-cloudwatch-container-insights-for-eks/
(사전 확인) 노드의 로그 확인
- application 로그 소스(All log files in /var/log/containers → 심볼릭 링크 /var/log/pods/<컨테이너>, 각 컨테이너/파드 로그
로그 위치 확인
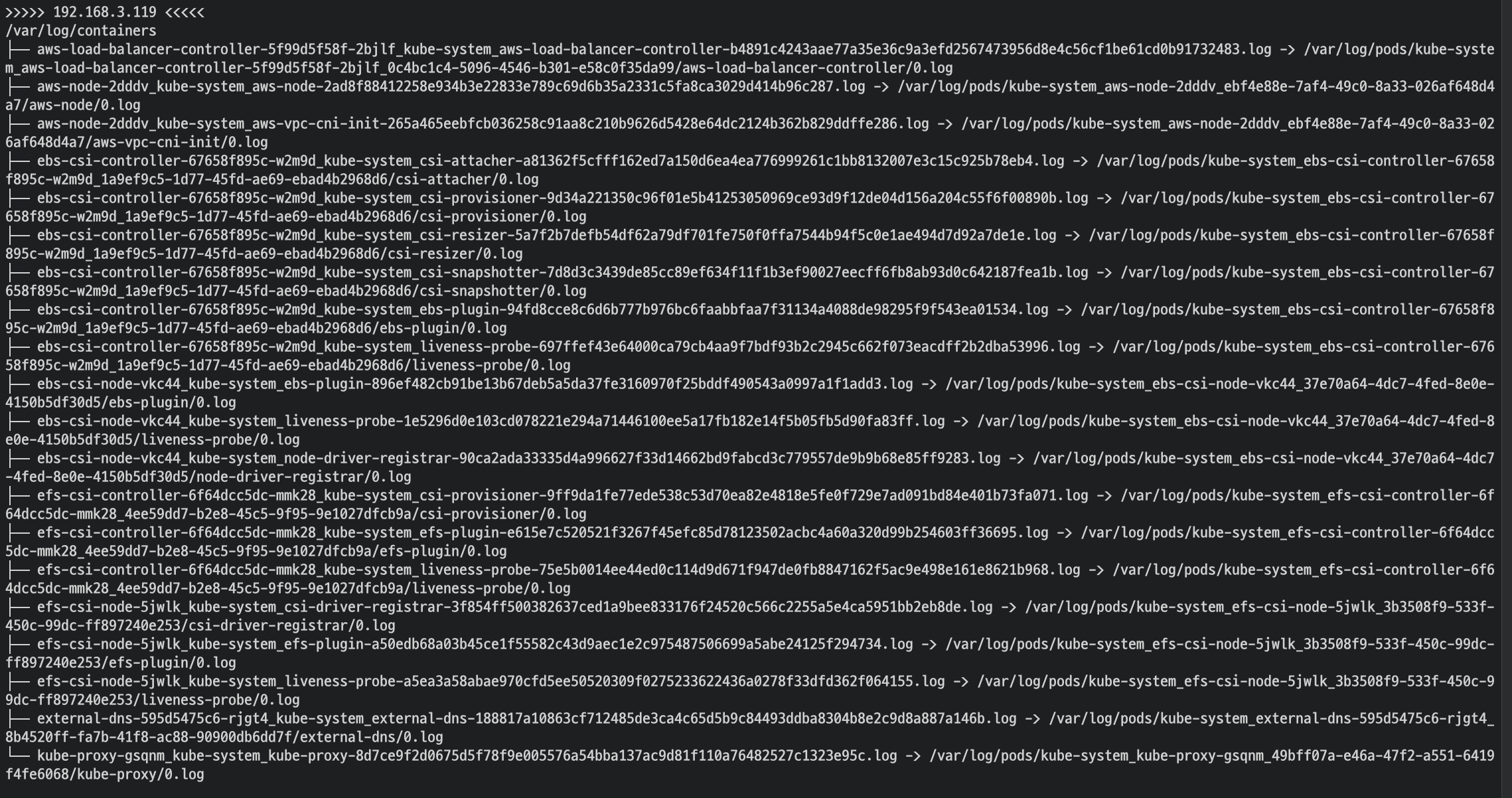
경로에 들어가 보면 각 pod의 로그 확인 가능하다
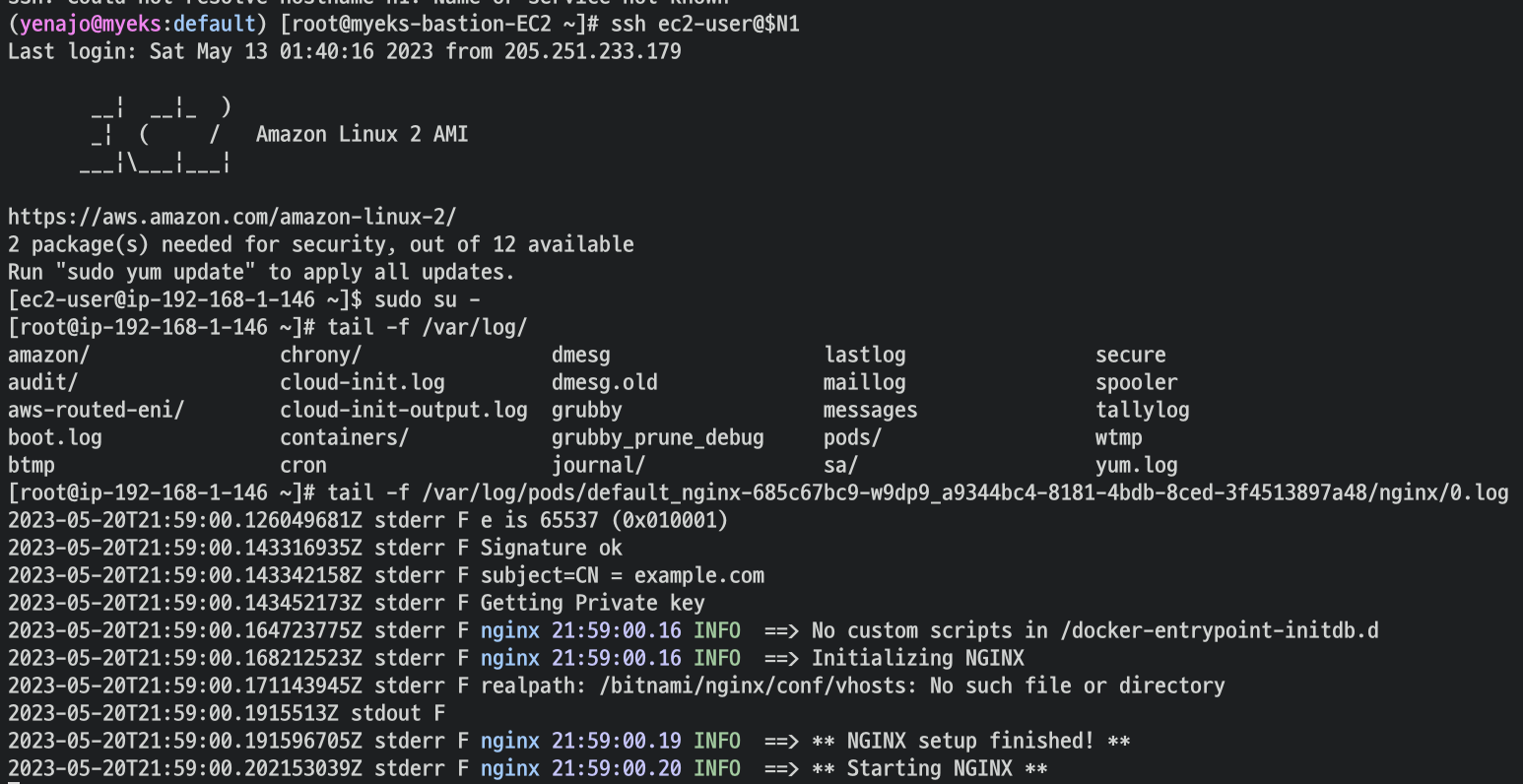
2. host 로그 소스(Logs from /var/log/dmesg, /var/log/secure, and /var/log/messages), 노드(호스트) 로그
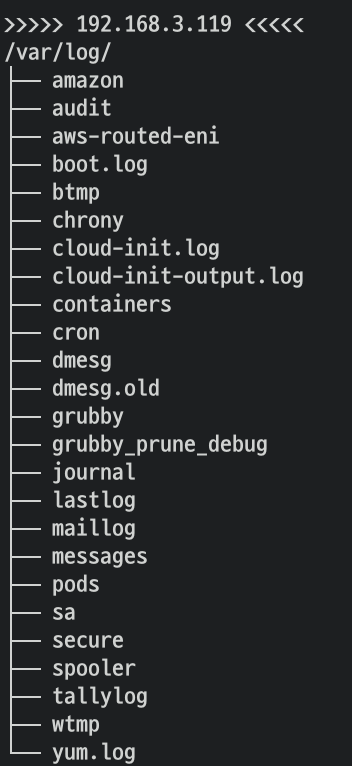
- dataplane 로그 소스(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그
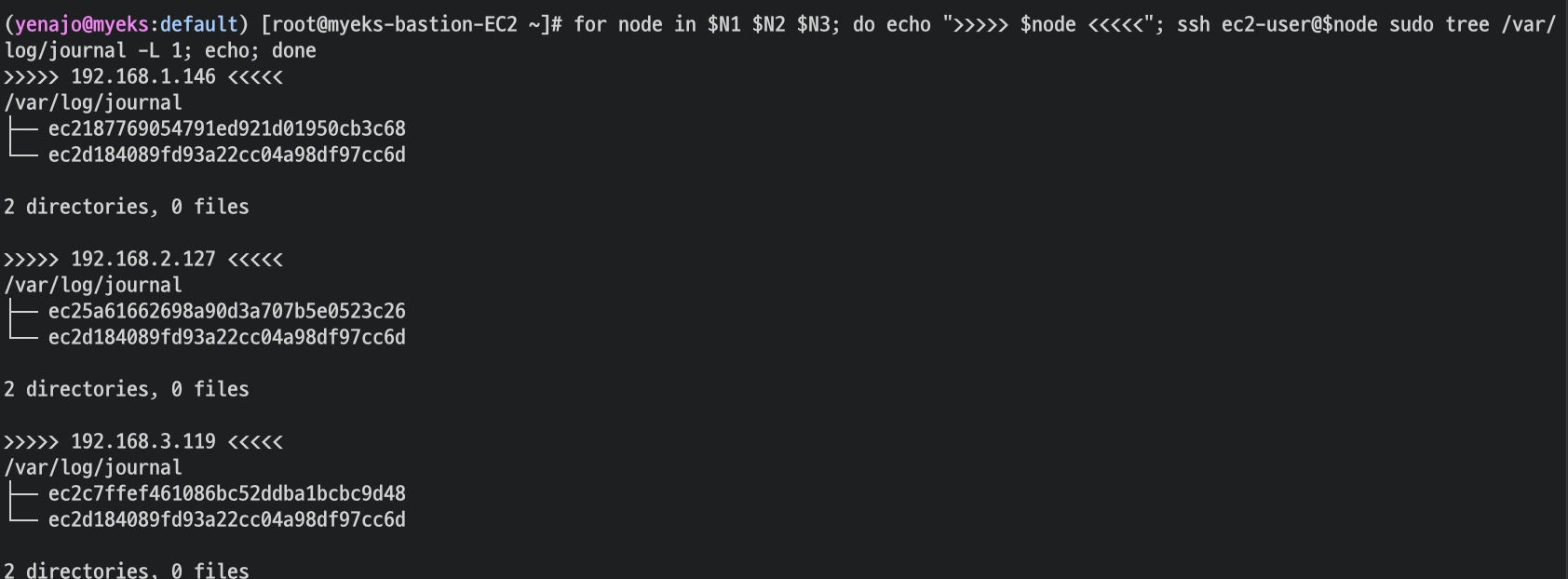
CloudWatch Container Insight 설치 : cloudwatch-agent & fluent-bit - 링크 & Setting up Fluent Bit - Docs

- 설치 확인
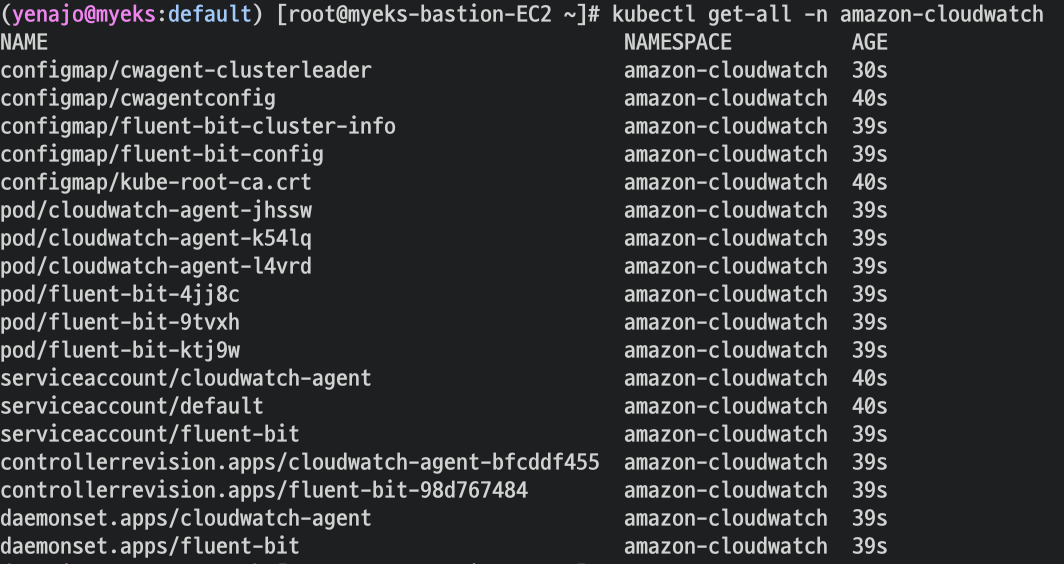
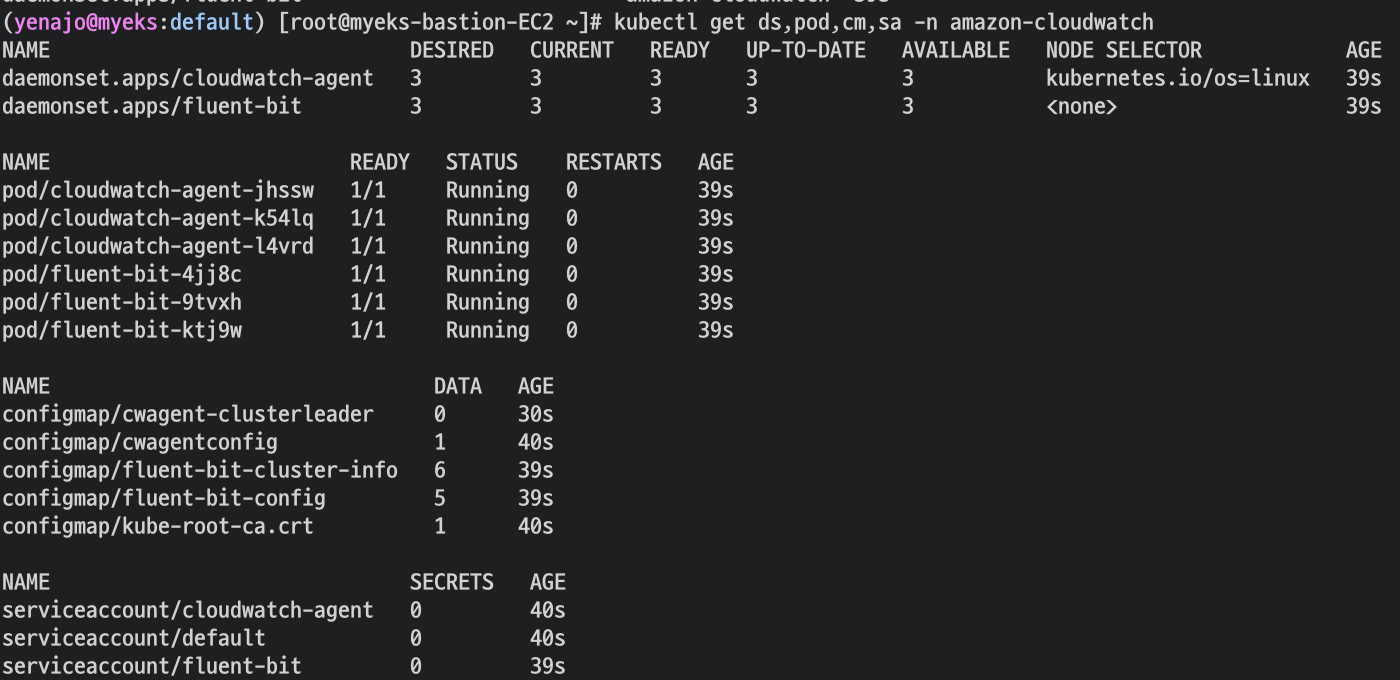
- 클러스터 롤 확인
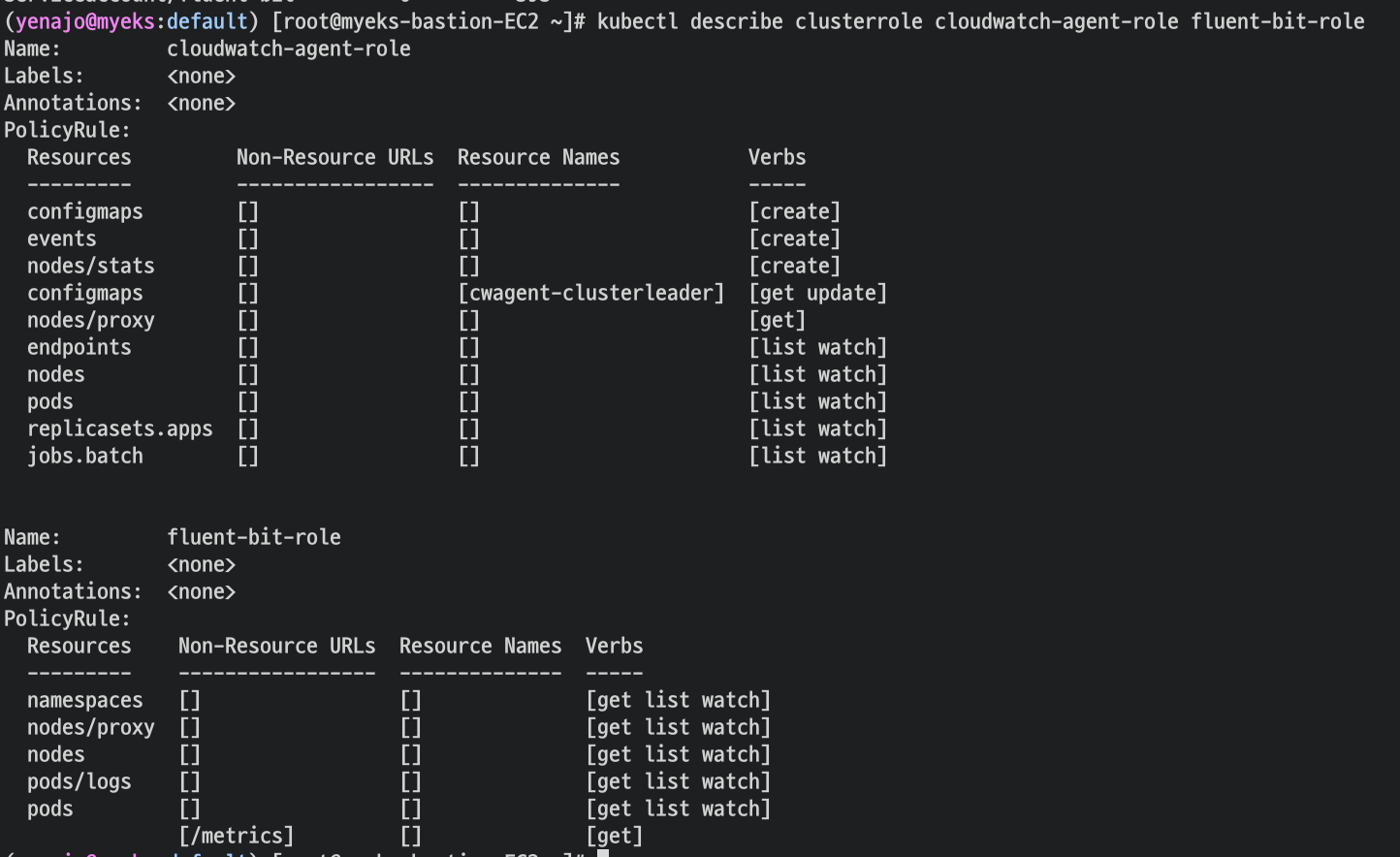
- 클러스터 롤 바인딩 확인
- 파드 로그 확인

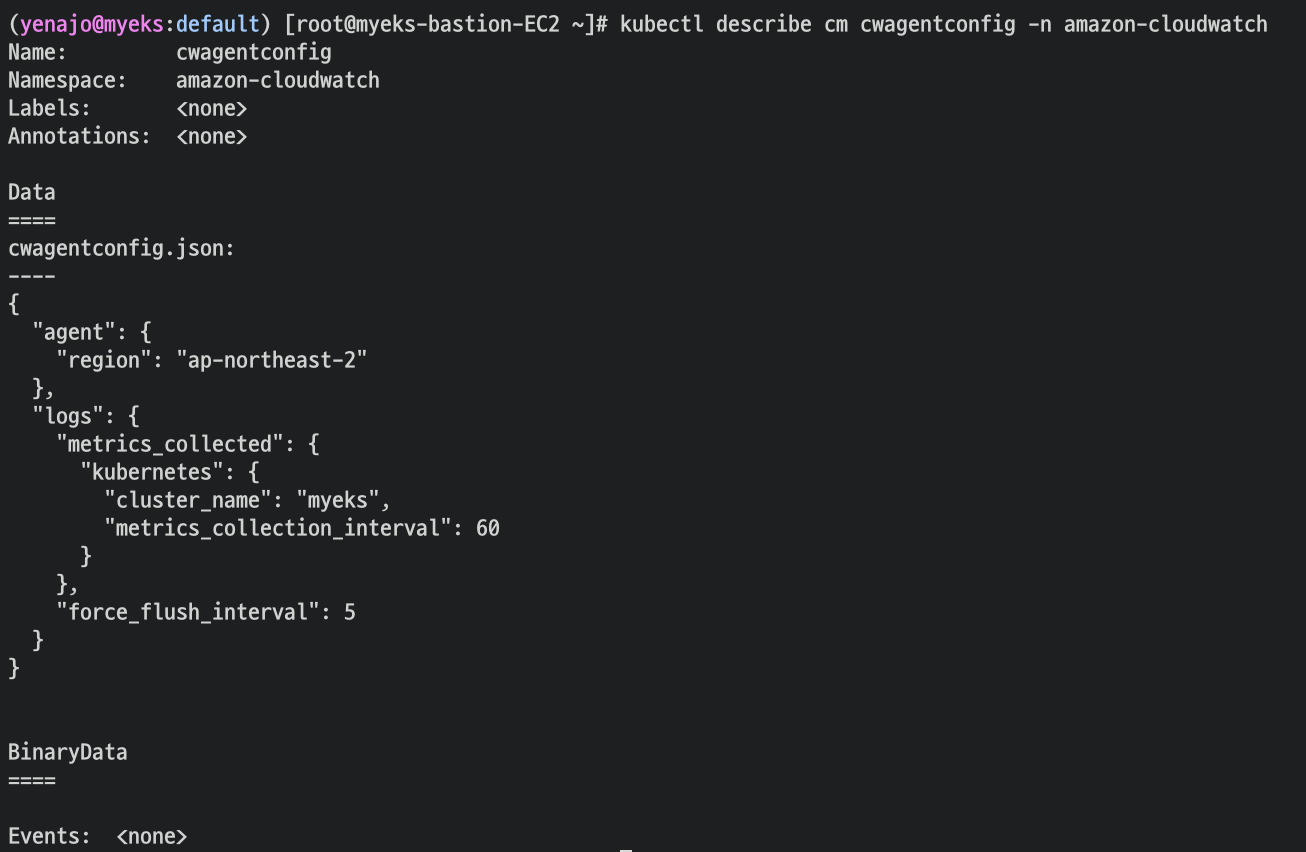
- cloudwatch-agent 설정 확인
- CW 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자!
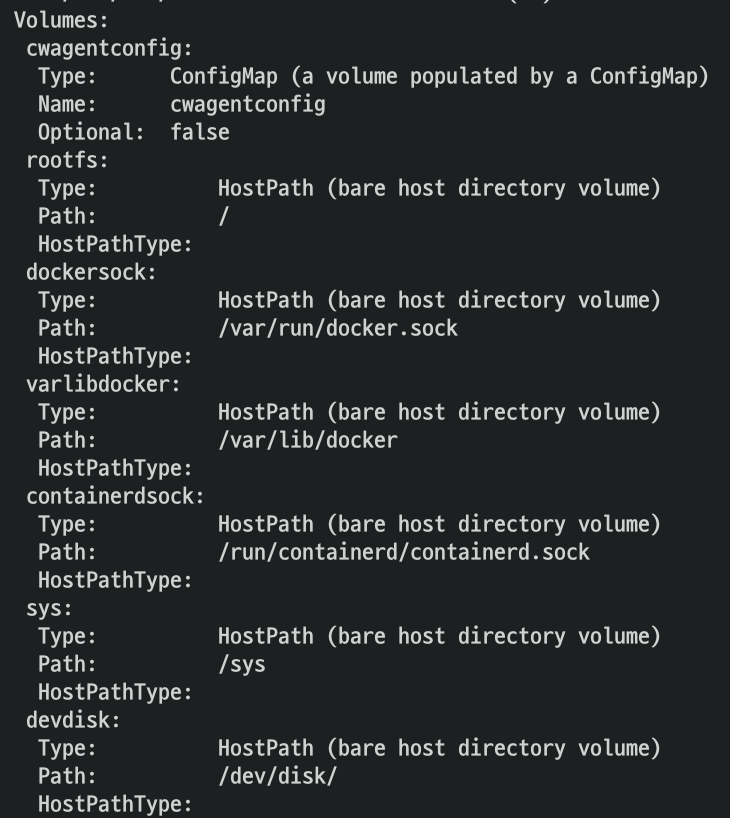
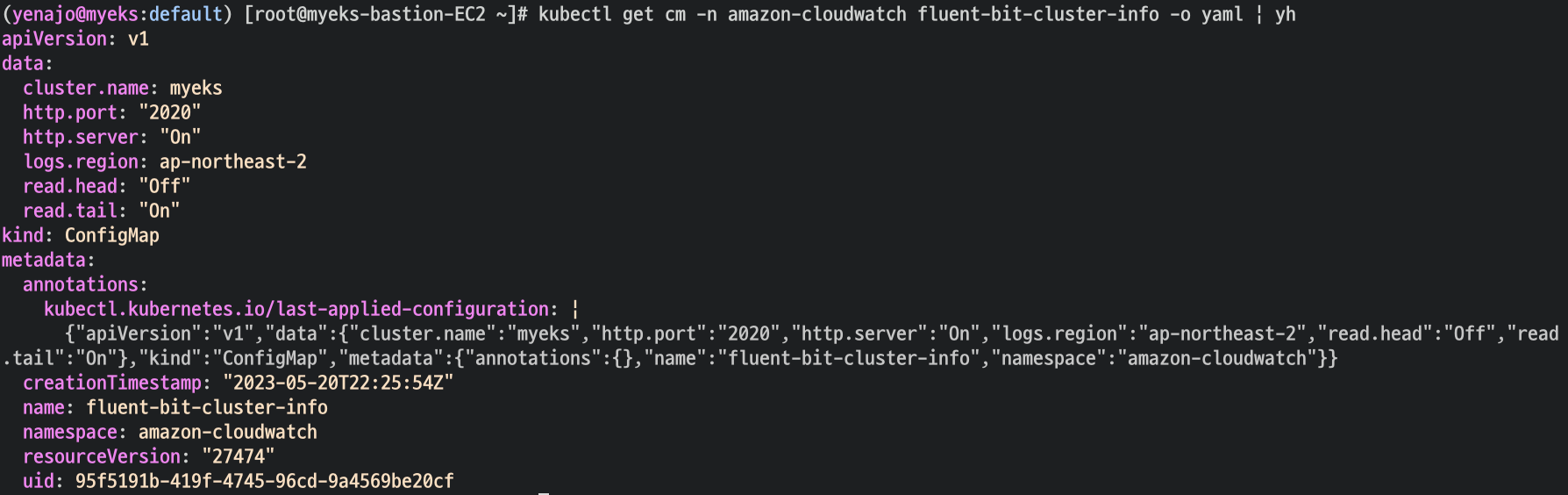
- Fluent Bit Cluster Info 확인
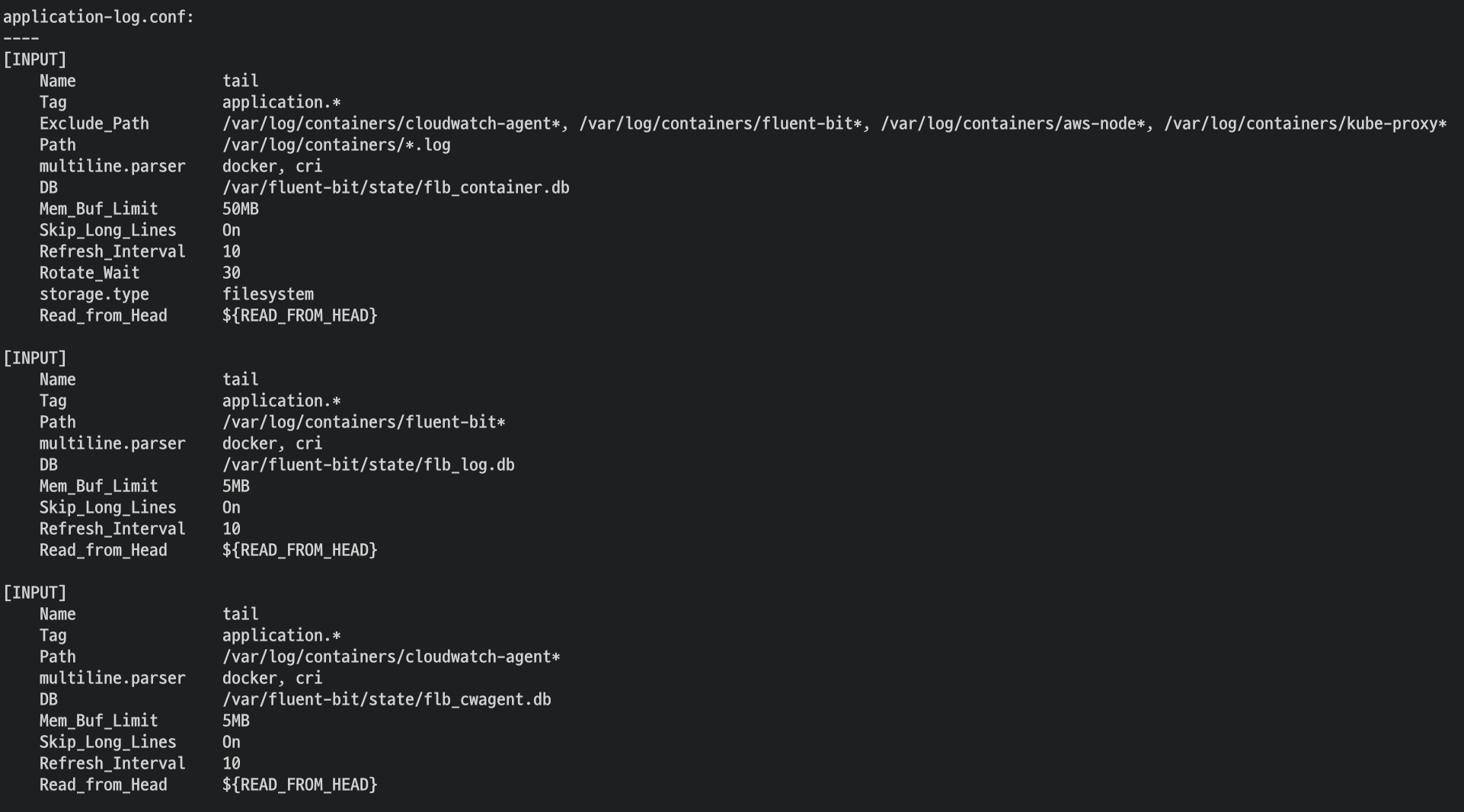
- Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인
등등 확인 가능하다명령어 : kubectl describe cm fluent-bit-config -n amazon-cloudwatch
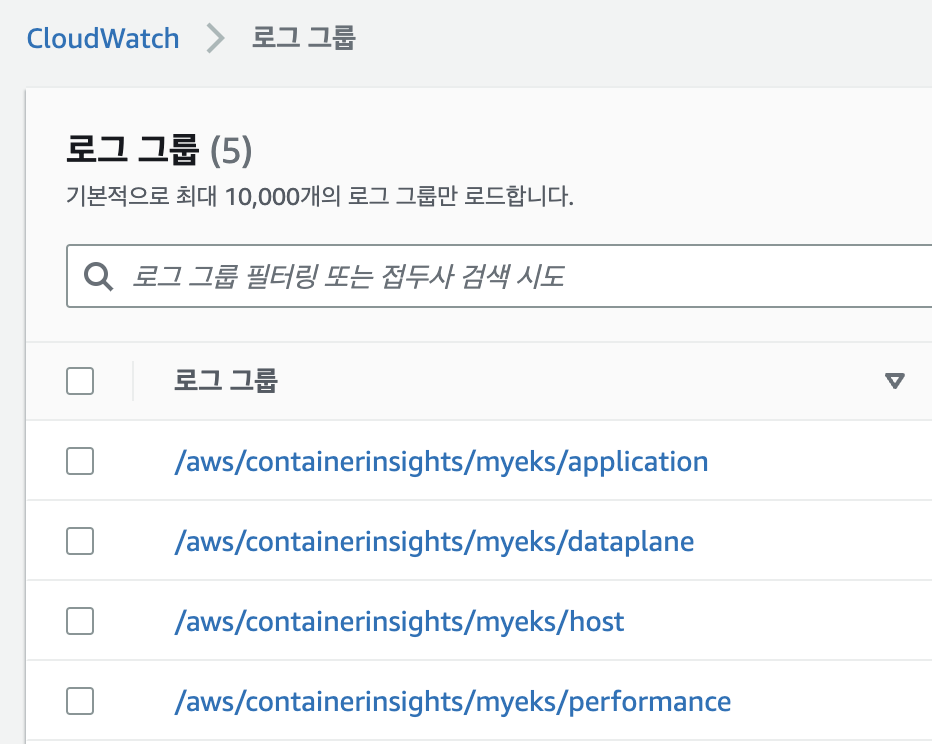
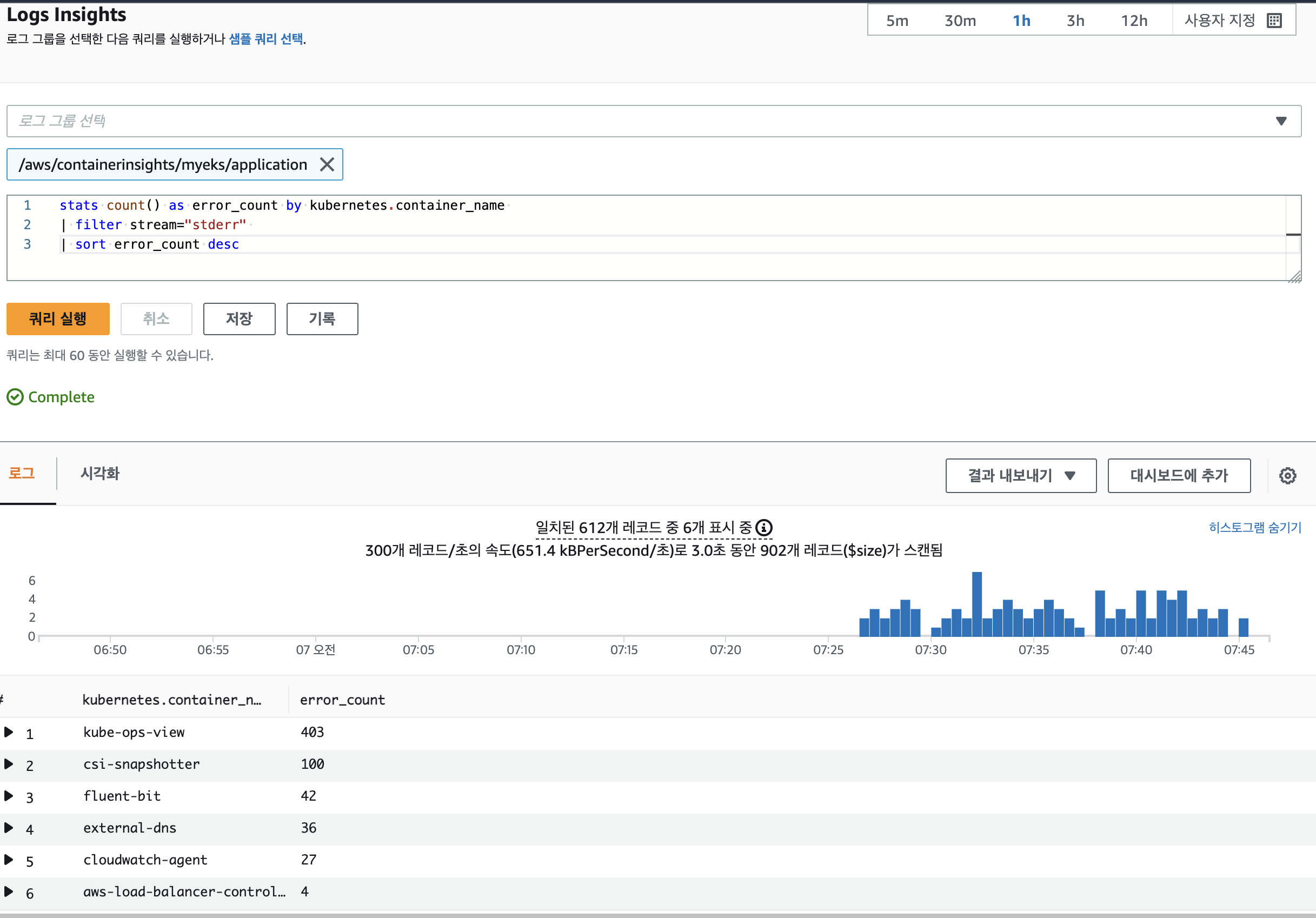
- 로깅 확인 : CW → 로그 그룹
- 메트릭 확인 : CW → 인사이트 → Container Insights
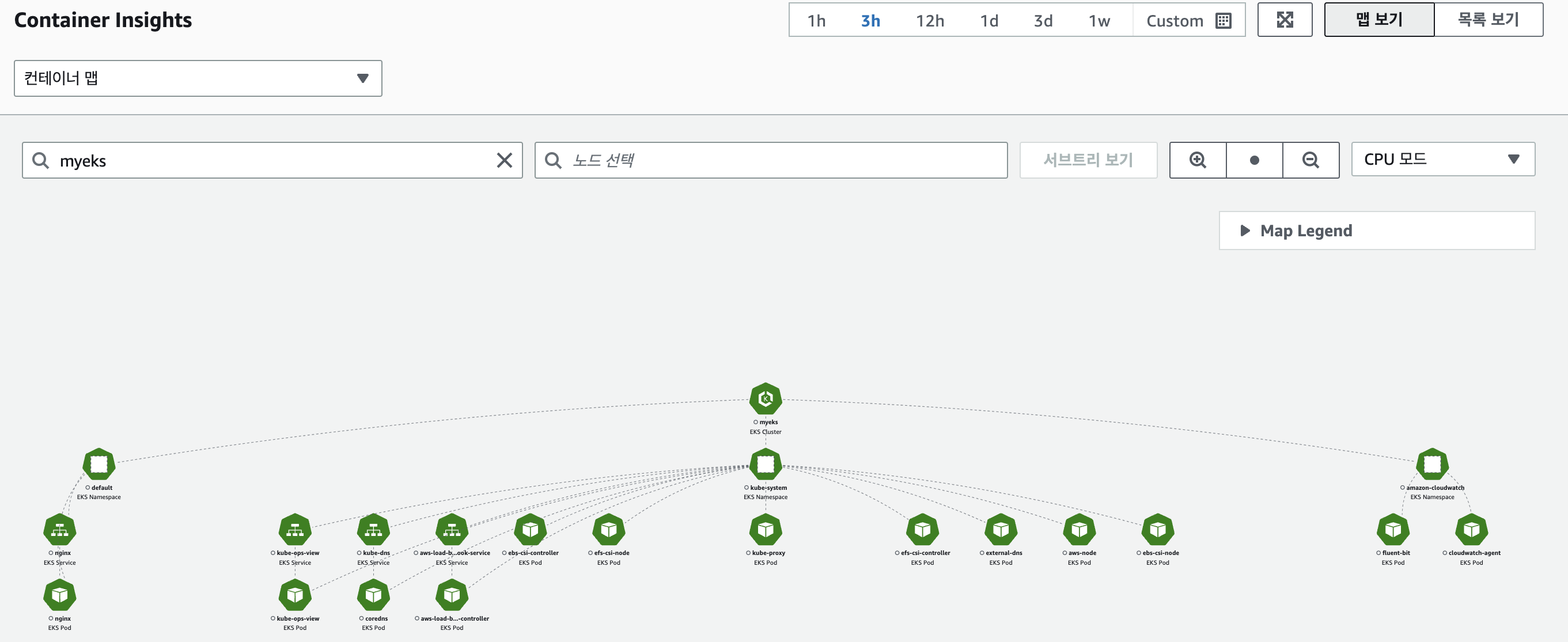
컨테이너맵
로그확인
파드 직접 로그 확인
log insights
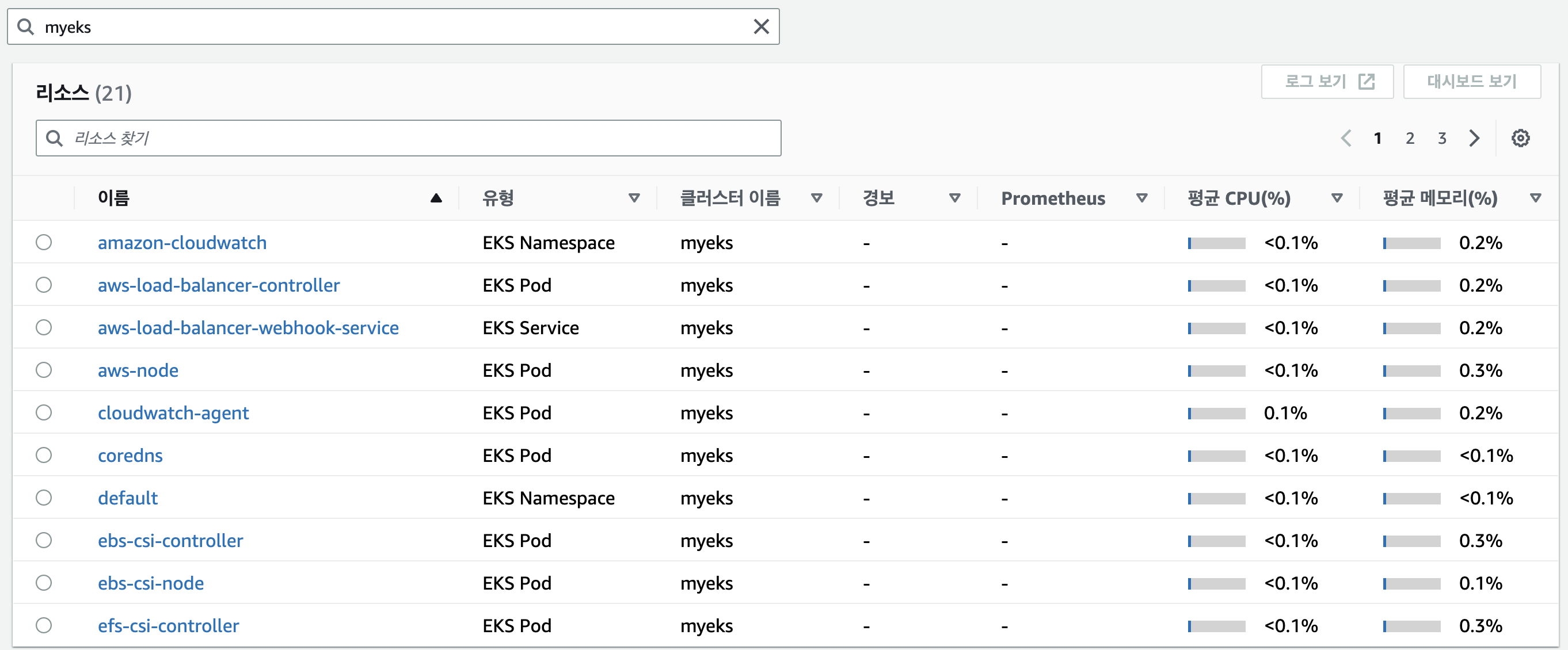
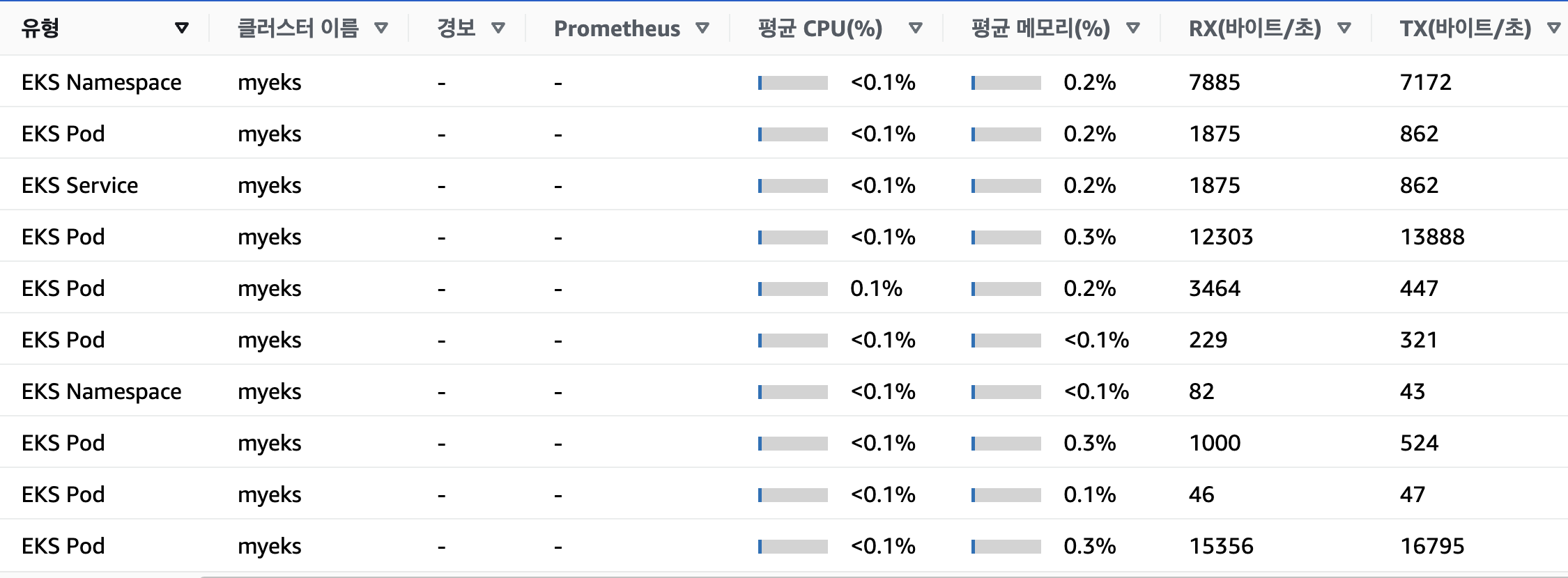
메트릭 확인 : CloudWatch → Insights → Container Insights : 우측 상단(Local Time Zone, 30분) ⇒ 리소스 : myeks 선택
container map
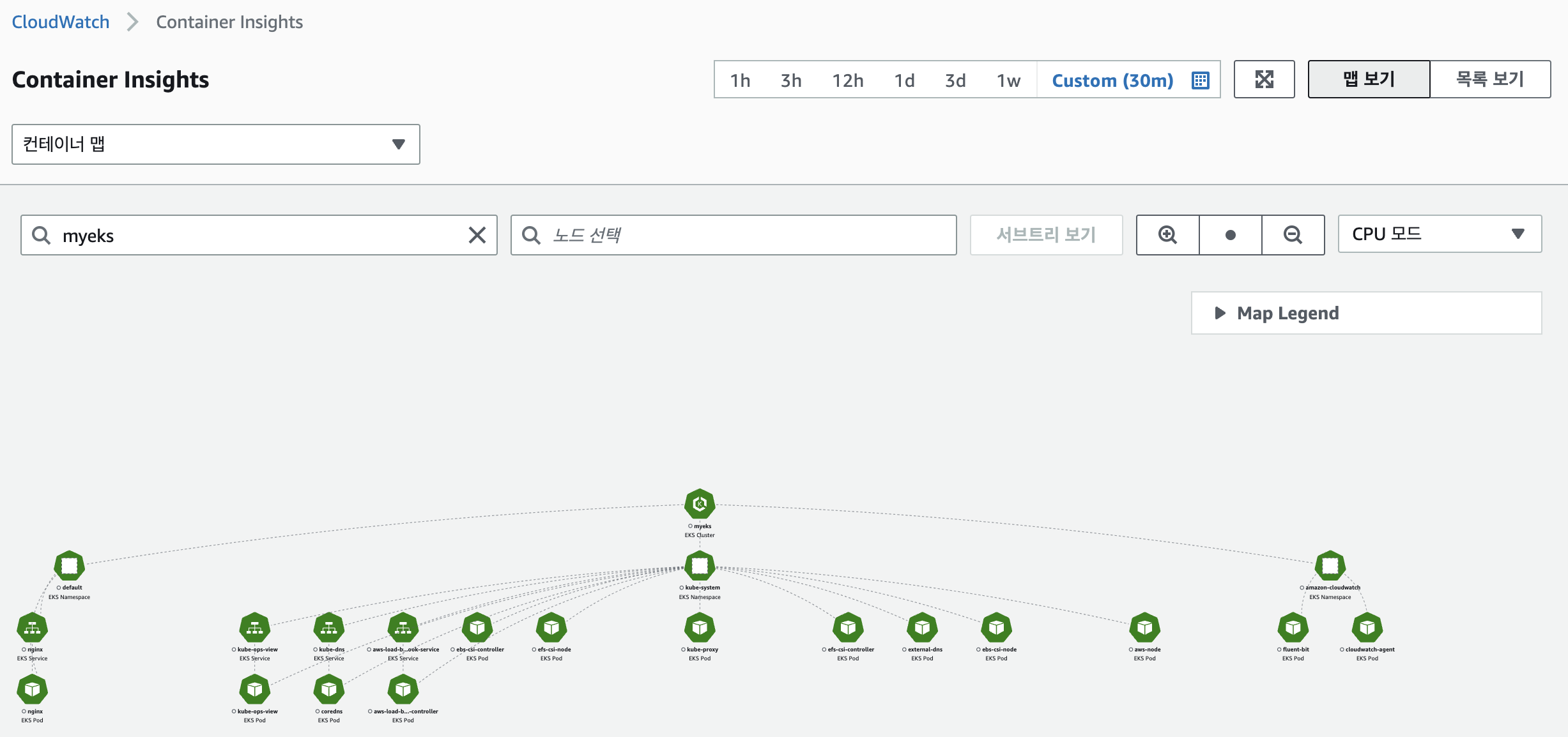
리소스(우측 톱니바퀴에서 TX/RX 활성화)
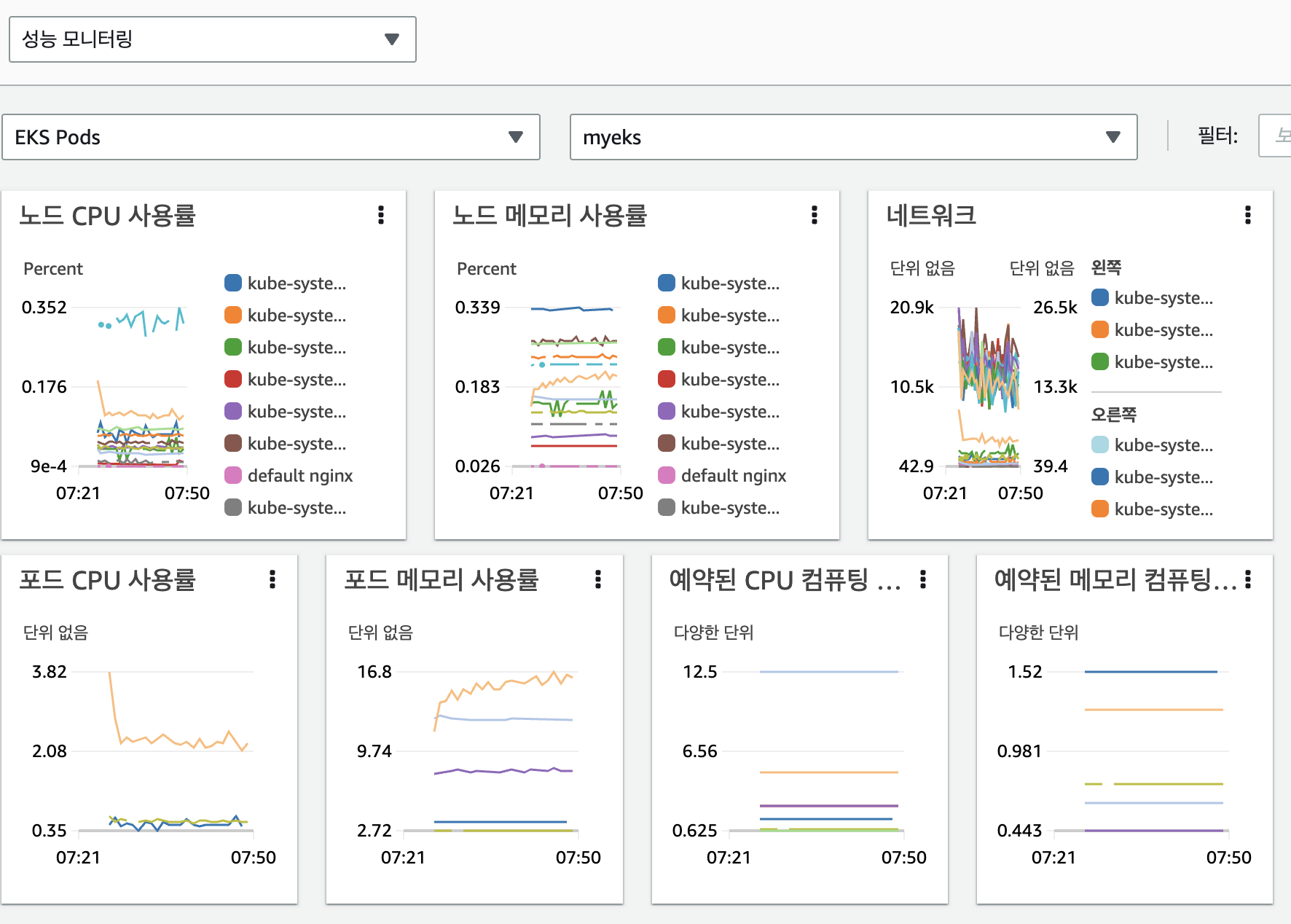
성능모니터링
Metrics-server & kwatch & botkube
Metrics-server 확인 : kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소
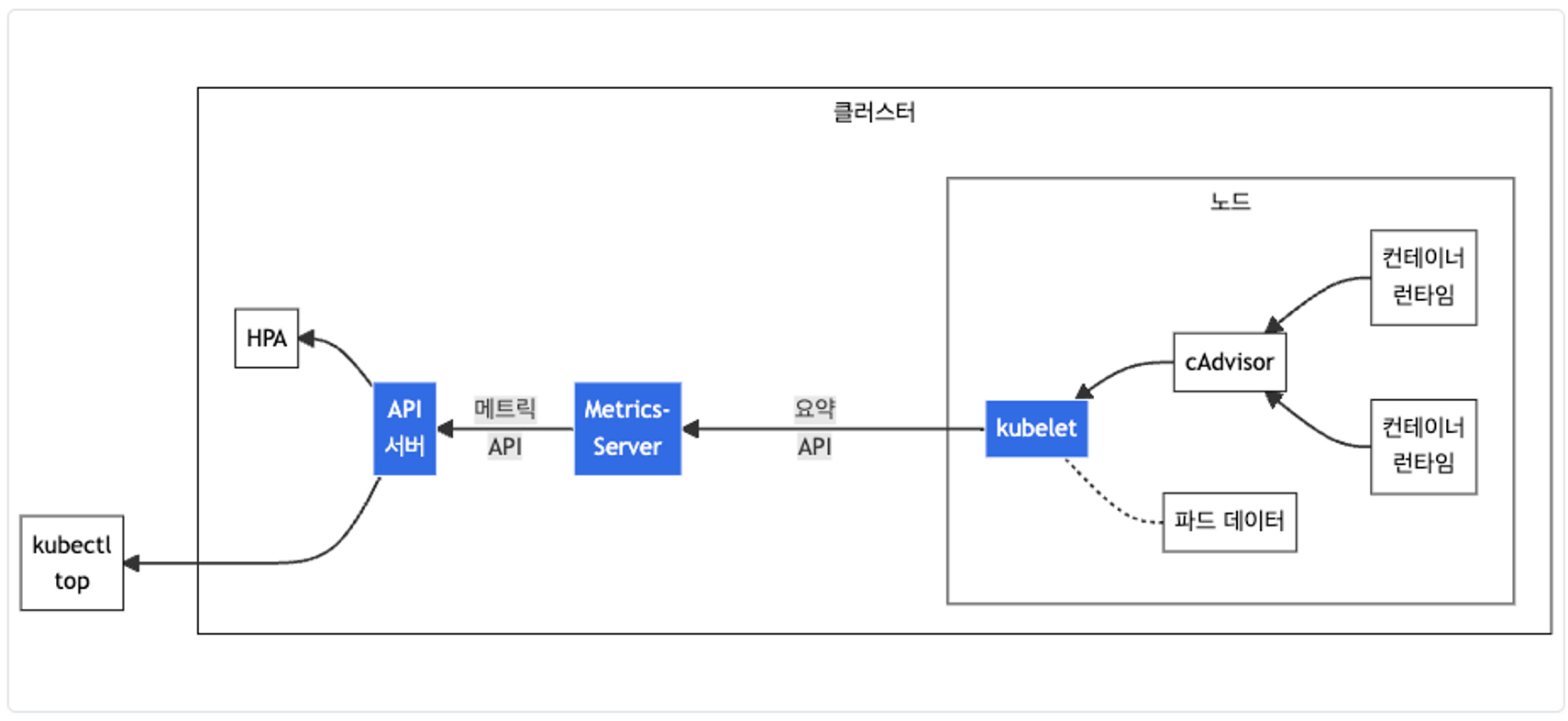
- cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
출처 : https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
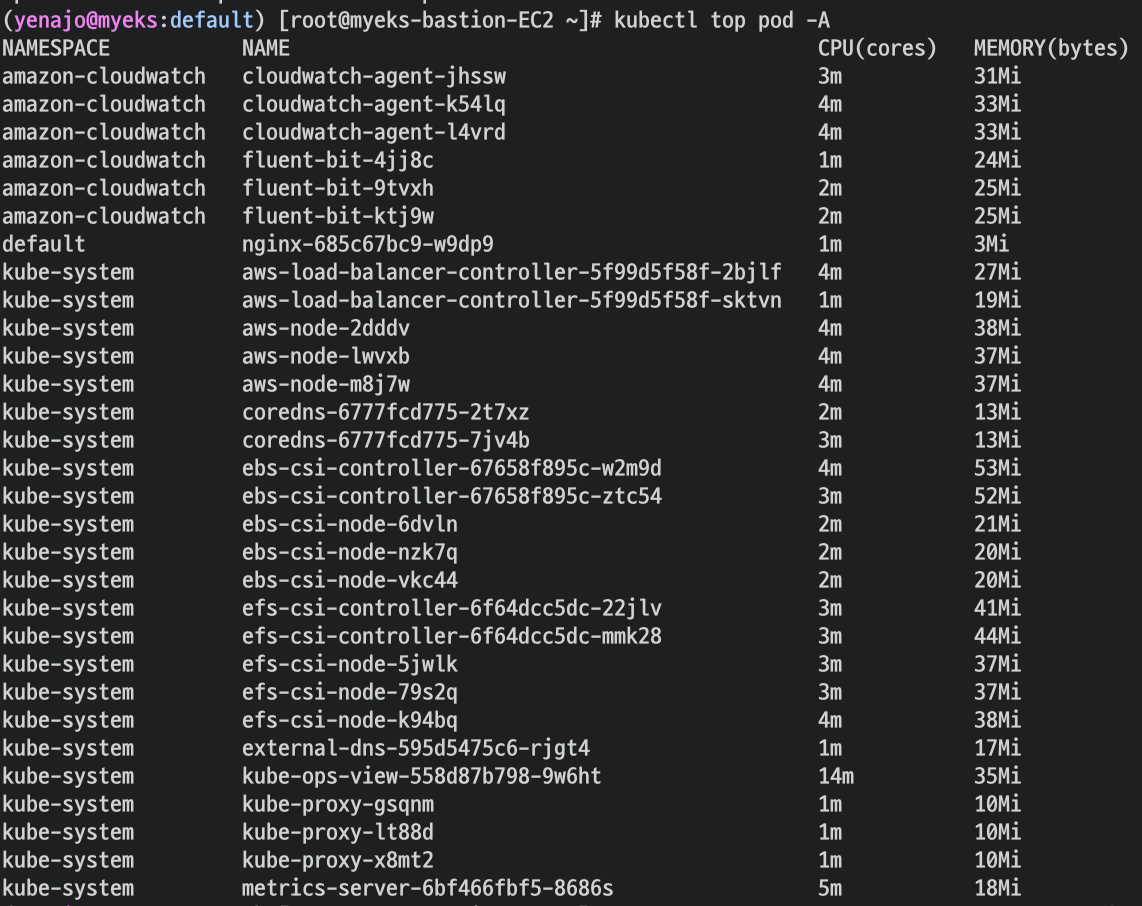
노드 메트릭 확인

POD 메트릭 확인
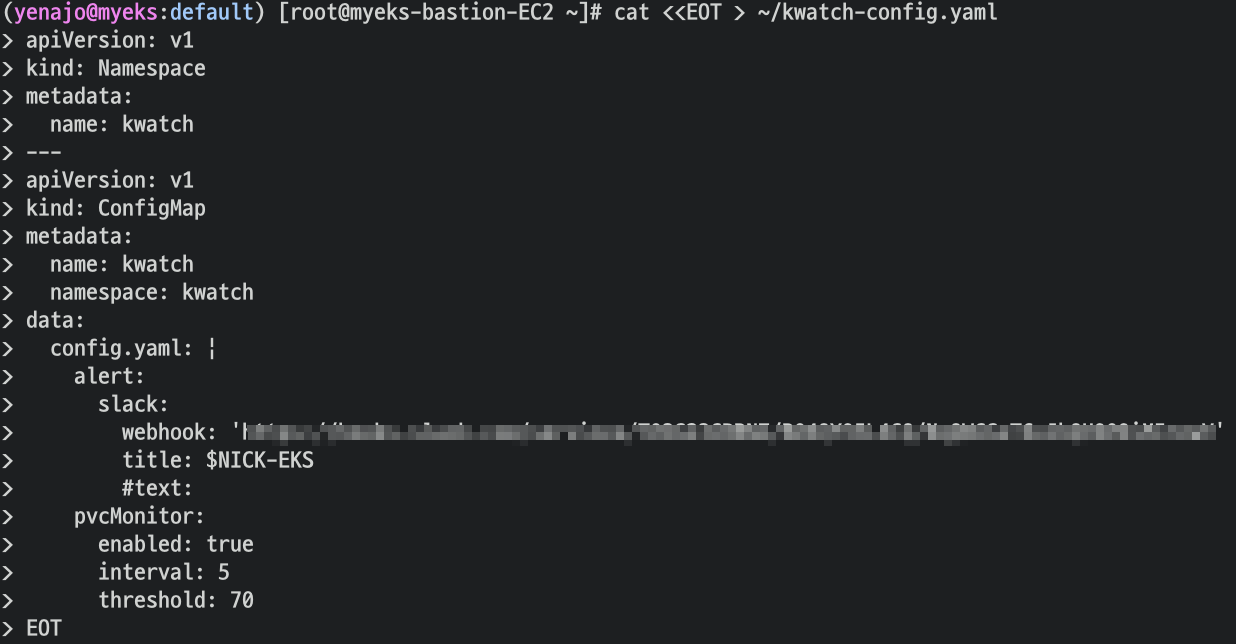
kwatch 소개 및 설치/사용 : kwatch helps you monitor all changes in your Kubernetes(K8s) cluster, detects crashes in your running apps in realtime, and publishes notifications to your channels (Slack, Discord, etc.) instantly
configmap 생성
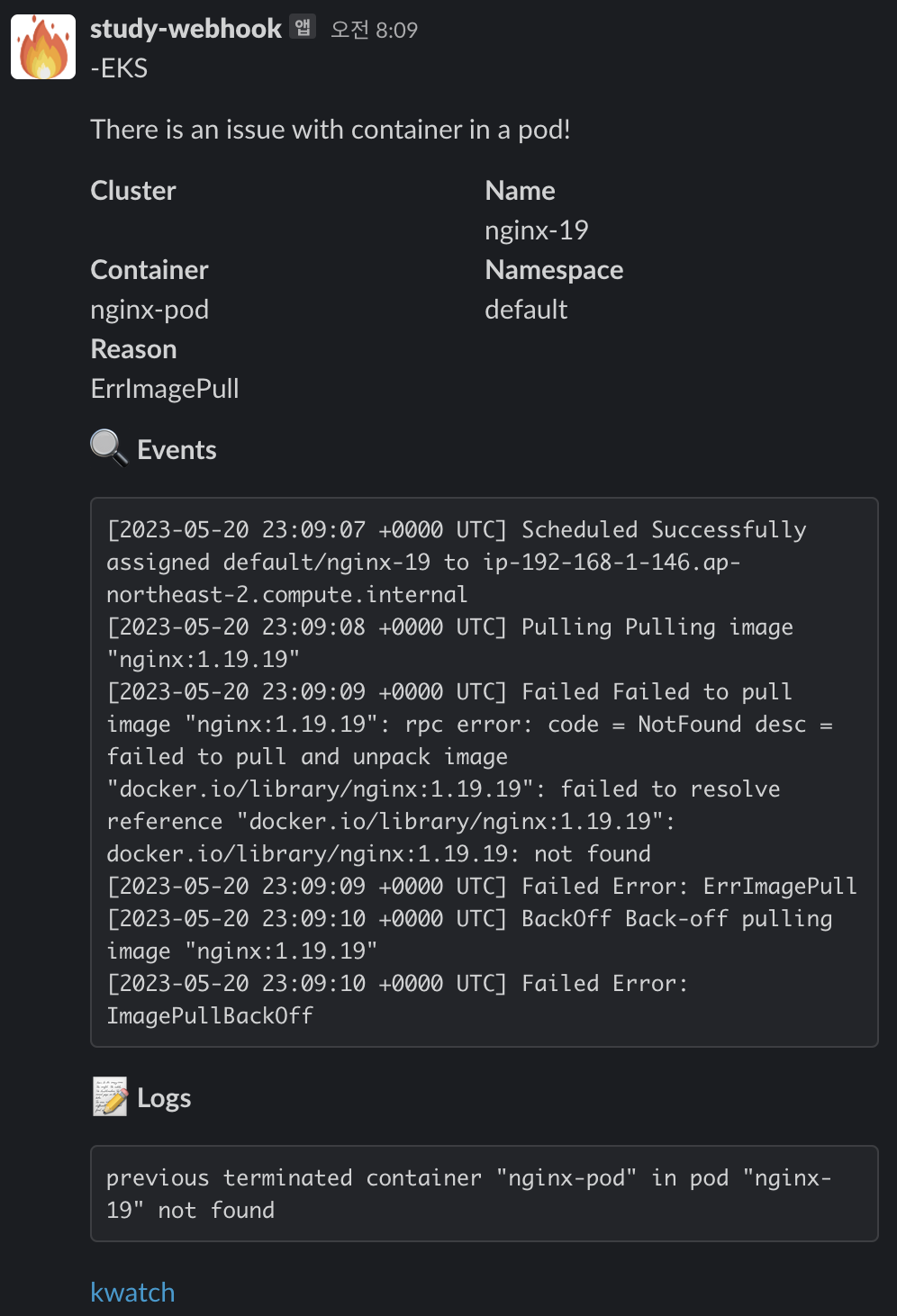
잘못된 이미지 파드 배포 및 확인
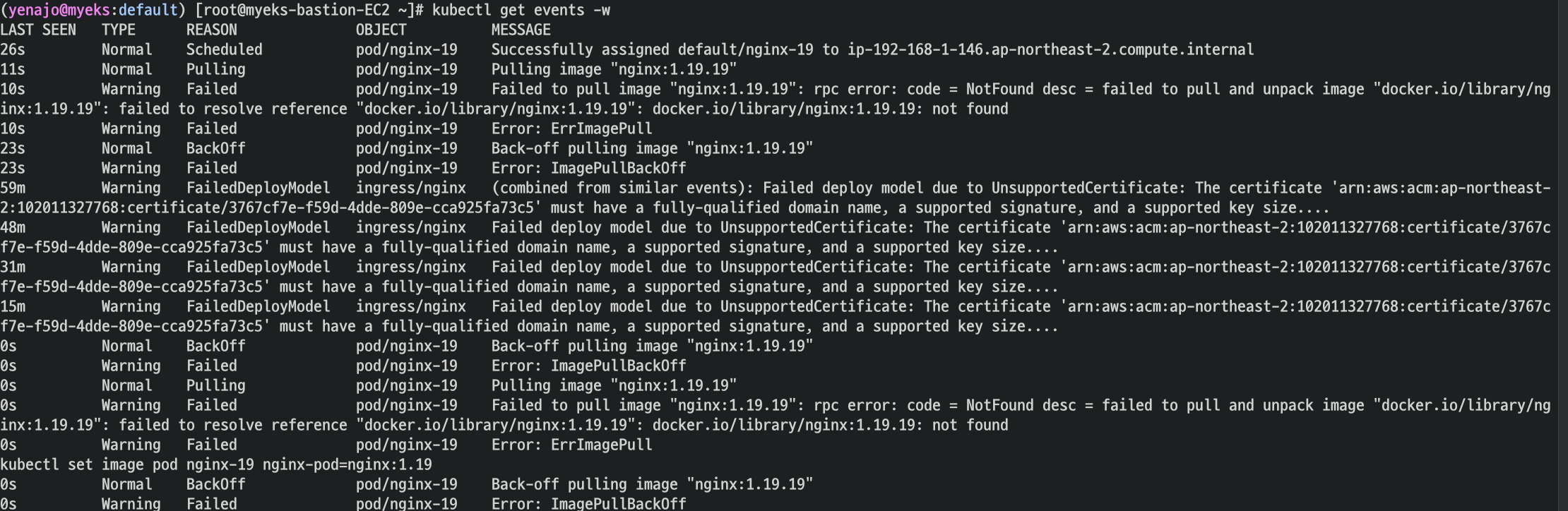
이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!

Botkube
이거는 영상 보니 엄청 편리해보이는데 webhook 채널에 botkube가 보이지 않는다 ㅠ 나중에 꼭 써봐야겠다
프로메테우스-스택
- 프로메테우스 오퍼레이터 : 프로메테우스 및 프로메테우스 오퍼레이터를 이용하여 메트릭 수집과 알람 기능 실습
- Thanos 타노스 : 프로메테우스 확장성과 고가용성 제공
설치, 확인
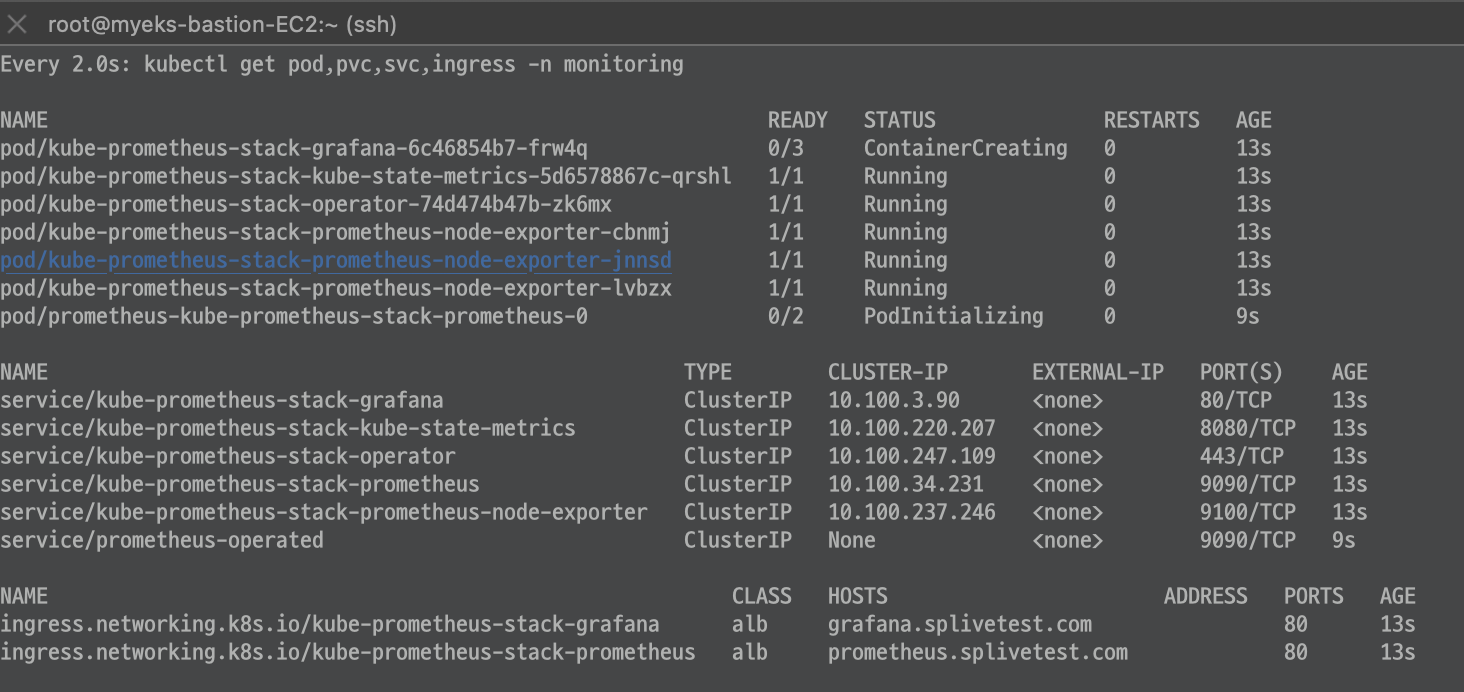

프로메테우스 기본 사용 : 모니터링 그래프
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
-
아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter -
노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics
프로메테우스 ingress 도메인으로 웹 접속
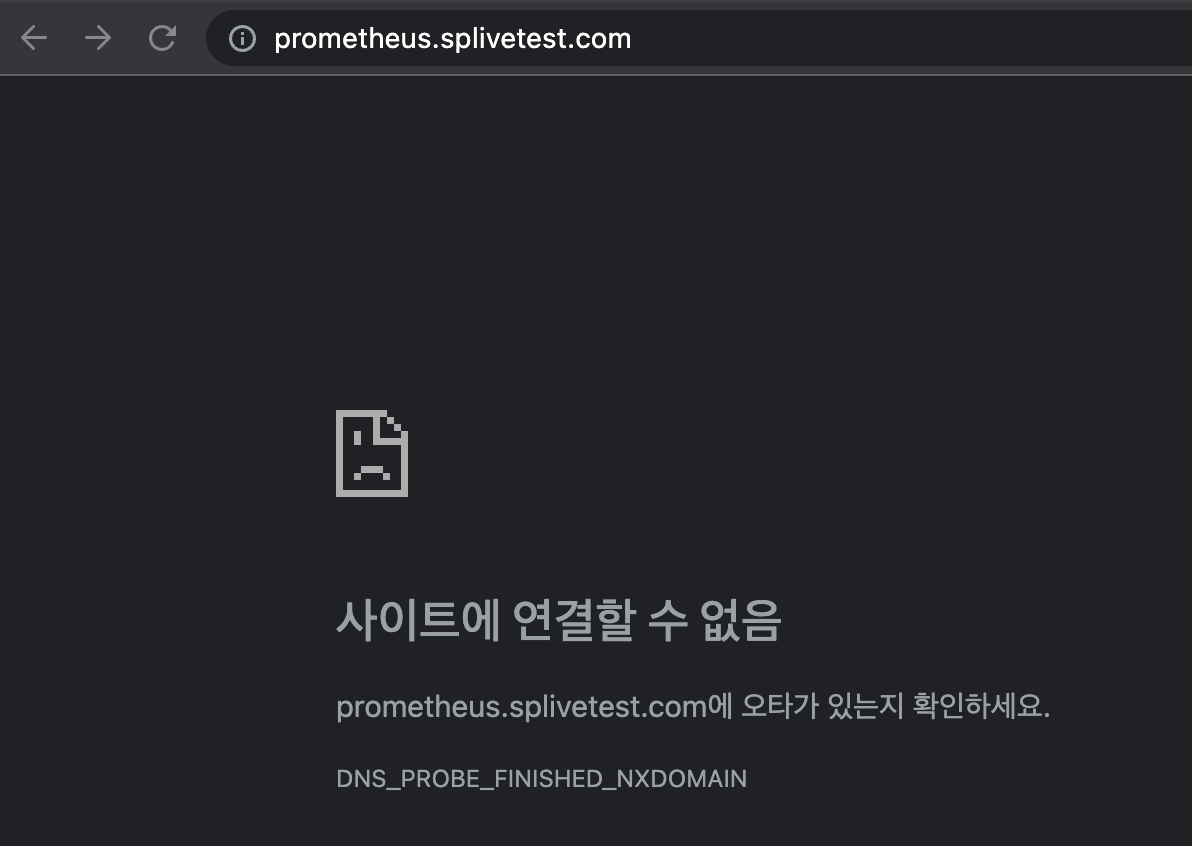
인증서 설정을 잘못했는지 뜨지 않습니다..
수정해서 다시 확인해보겠습니다
그라파나 Grafana
- 그라파나 ? TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
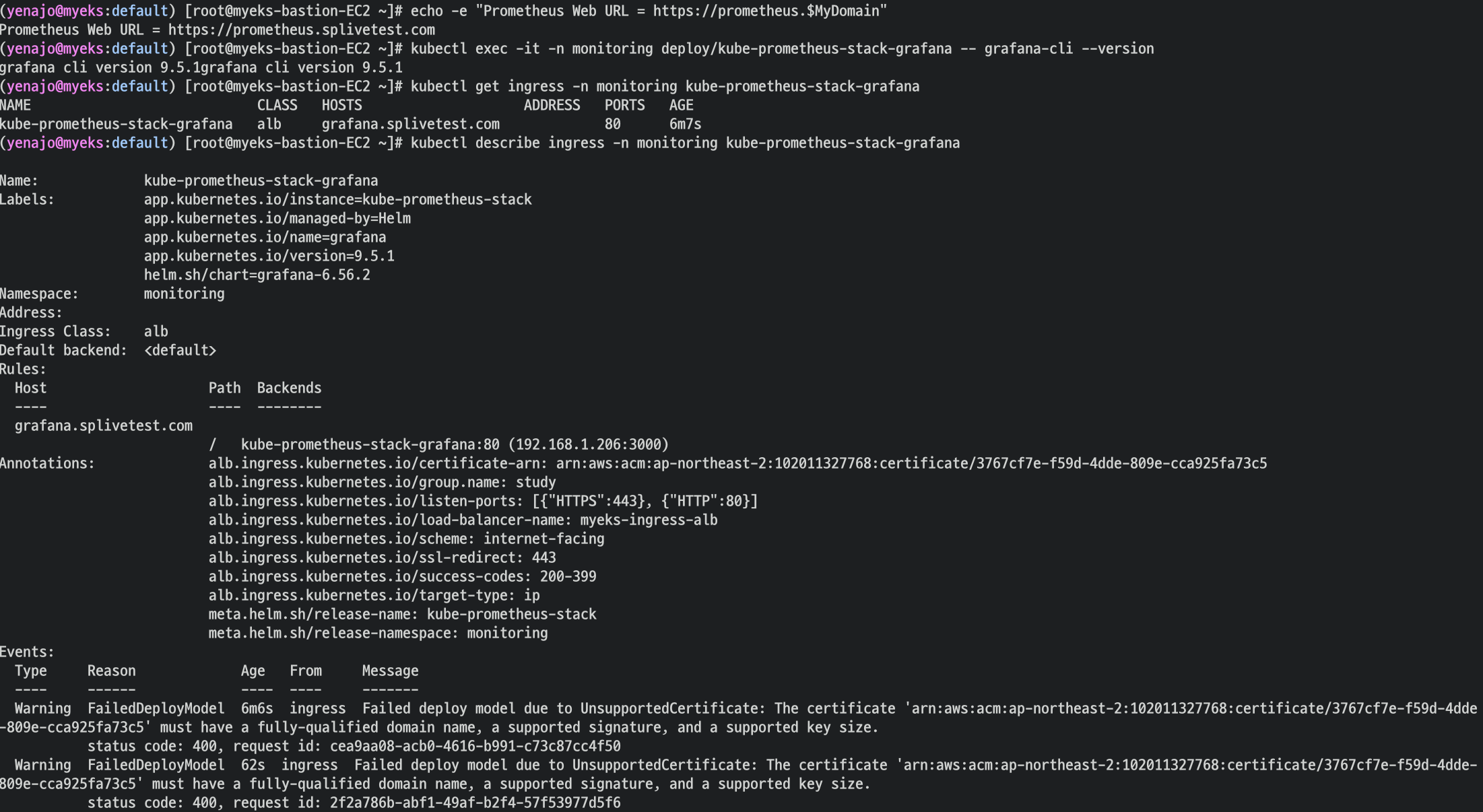
서비스 주소 확인

테스트 pod 배포
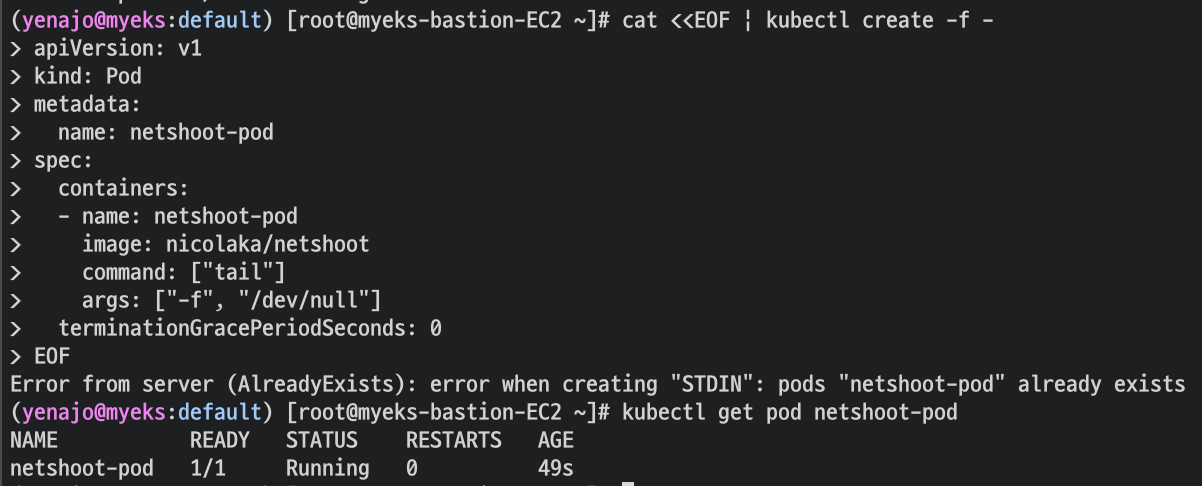
접속 확인

잘못된 설정으로 프로메테우스랑 그라파나 테스트를 해보지 못한거같습니다
다들 바쁘신데도 불구하고 자료 만들어 주셨는데 ㅠ_ㅠ 과제를 너무 데드라인에 임박해서 하는 바람에 우선 제출은 하지만 꼭 다시 해보겠습니다...ㅠㅠ
다음부턴 미리미리 과제를 진행하도록 하겠습니다ㅠㅠ
