PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
1. 요약
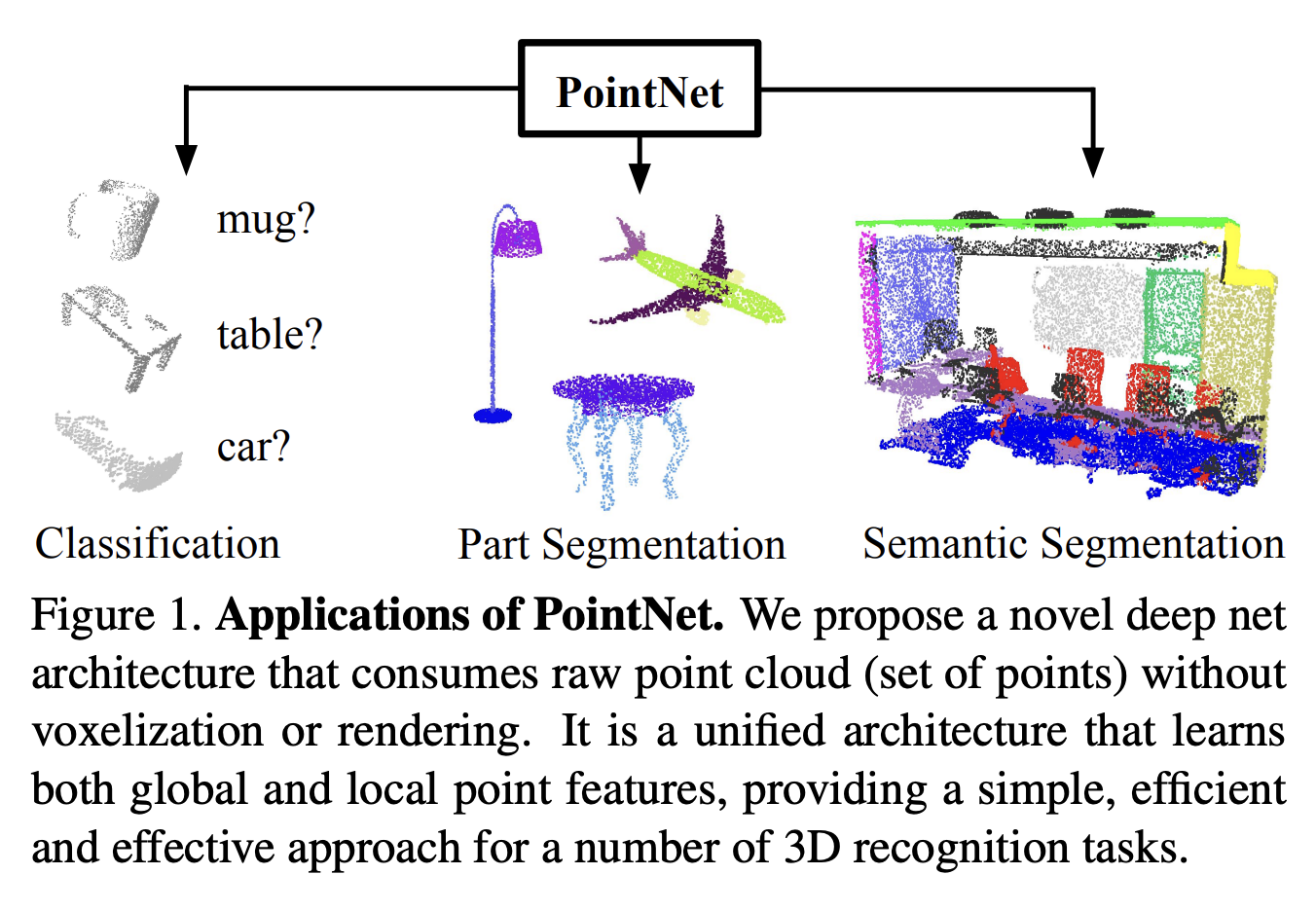
- Point colud는 geometric data structure에서 중요하지만 불규칙적인 형식때문에 3D voxel grid나 이미지 집합으로 바꾸는데 불필요하게 큰 용량으로 렌더링
- Convolution architecture에는 규칙적인 3D voxel이나 이미지 데이터 형식이 필요하기 때문
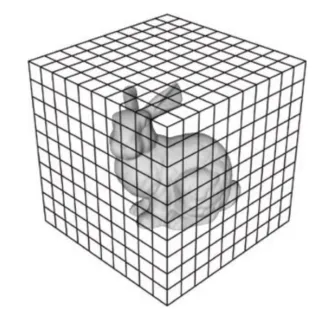
-> voxel로 변환시 불필요한 공간 낭비가 되는 것을 볼 수 있음(이미지: https://medium.com/@parkie0517/pointnet-deep-learning-on-point-sets-for-3d-classification-and-segmentation-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-a623ee58b359) - 이를 해결하기 위해 raw point cloud를 입력으로, permutation invariance를 잘 하는 PointNet을 제안
- permutation invariance: 입력 벡터 요소의 순서와 상관없이 같은 출력을 생성하는 모델 - point cloud를 다룰 때는 아래와 같은 어려움을 해결하고 진행해야 함
1. 어떠한 순서가 들어가도 출력은 불변해야 한다.: Symmetry Function for Unordered Input- Segmentation에서는 이웃 point 간의 연관성을 파악해야 한다. Local and Global Information Aggregation
- rigid transformation이 있어도 point set은 변하면 안된다.: Joint Alignment Network
2. PointNet
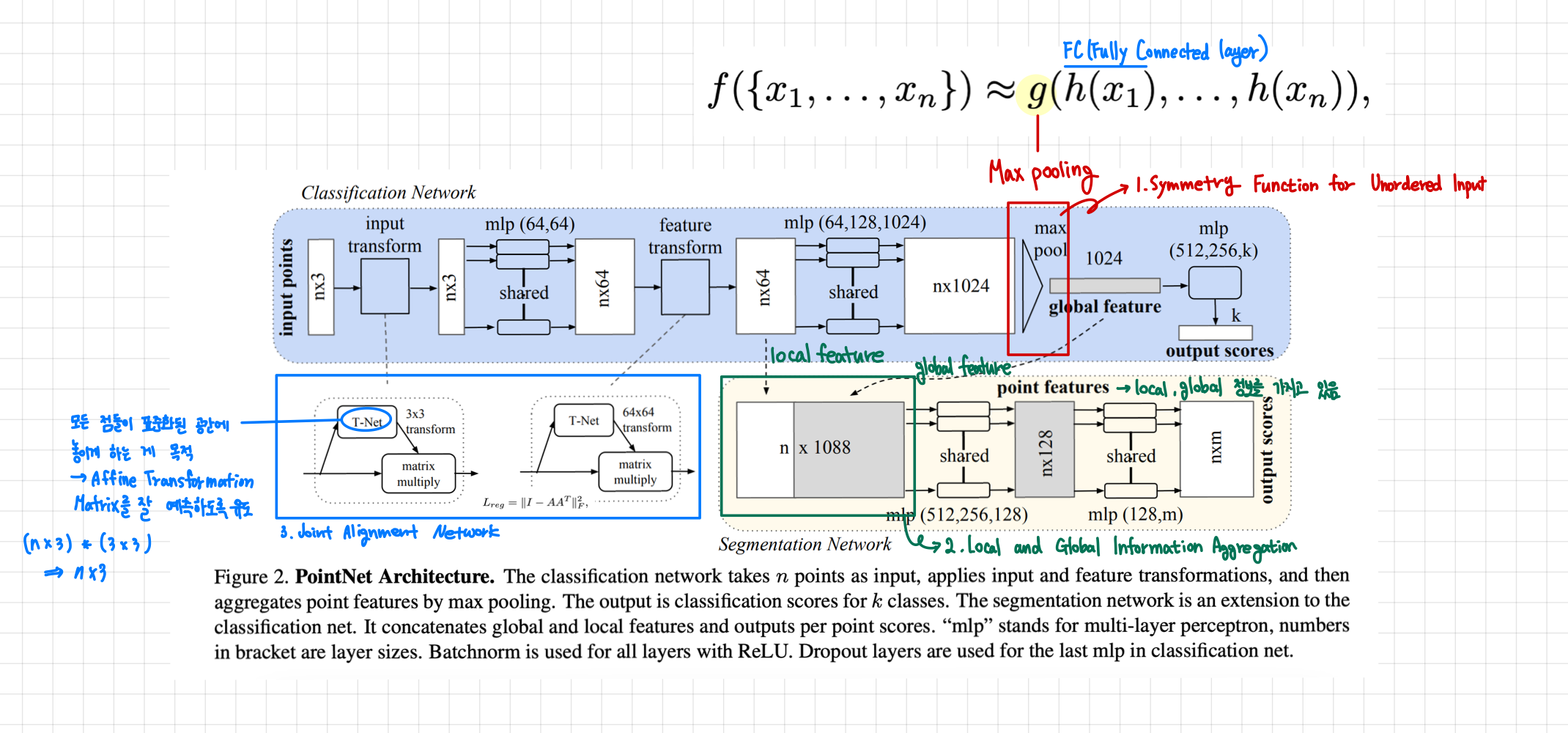
- 입력: raw point cloud data
- 출력: class label or per point segment/part labels
2.1. Symmetry Function for Unordered Input
- 해결하고자 하는 문제: 불규칙적이고 순서가 정해지지 않은 Point cloud를 어떻게 입력하든 결과는 Invariance해야 한다.
- 접근 방법
1) 순서를 정하는 건? -> point cloud는 순서가 없기 때문에 순서를 정하는 것은 모순
2) RNN을 사용하는 건? -> point cloud는 NLP와 다르게 방대한 양이기 때문에 학습하는 데 한계가 존재
3) 대칭 함수를 사용하는 건? -> 정의역의 순서가 바껴도 출력값이 동일하기 때문에 채택- 대칭 함수: f(x1, x2) = f(x2, x1)과 같이 정의역의 순서가 바껴도 출력값이 동일한 함수를 의미
- 여기서 사용하는 방법은 바로 Max pooling을 사용하여 출력값을 불변하게 유도
- 쉽게 말해서 Max pooling을 사용하면 (1,2,3)이 들어오든 (3,2,1)이 들어오든 순서에 상관없이 동일하게 3을 출력한다는 점이 포인트
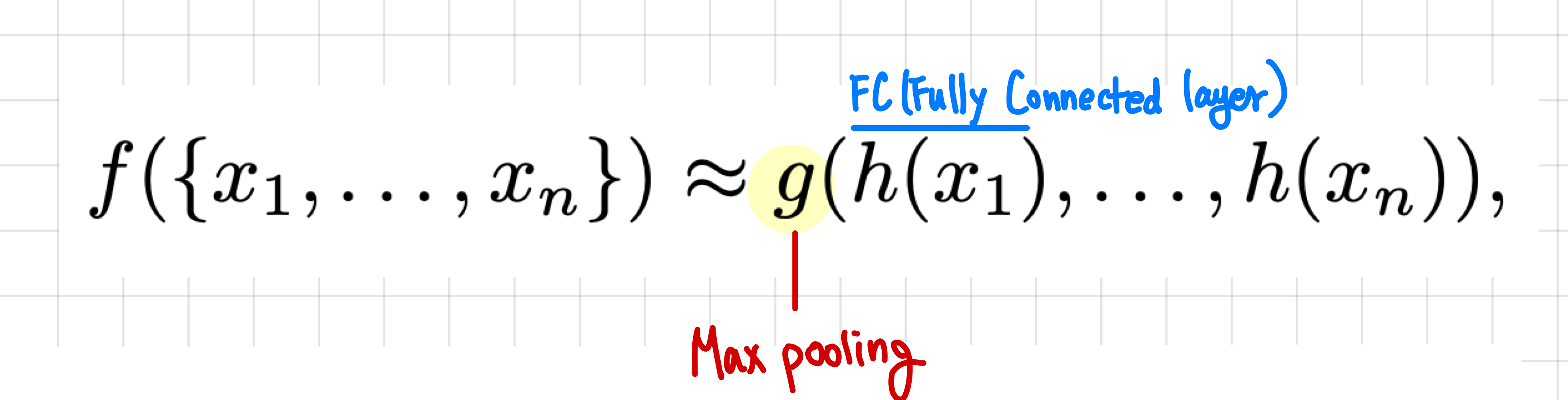
2.2. Local and Global Information Aggregation
- 해결하고자 하는 문제: segmentation을 진행하려면 이미지의 global 정보 뿐만 아니라 이웃 간의 local 정보도 알고 있어야 한다.
- 2.1.에서 추출한 global feature와 중간 layer인 local feature를 concatenate한 point features를 통해 segmentation 진행
- 즉, point feature는 global과 local 정보가 담겨 있기 때문에 segmentation이 가능
2.3. Joint Alignment Network
- 해결하고자 하는 문제: point cloud가 rigid transformation을 해서 원본 point cloud와 다르더라도 결과는 Invariance 해야 한다.
- 해결 아이디어: 표준화 된 공간에 매핑하자!
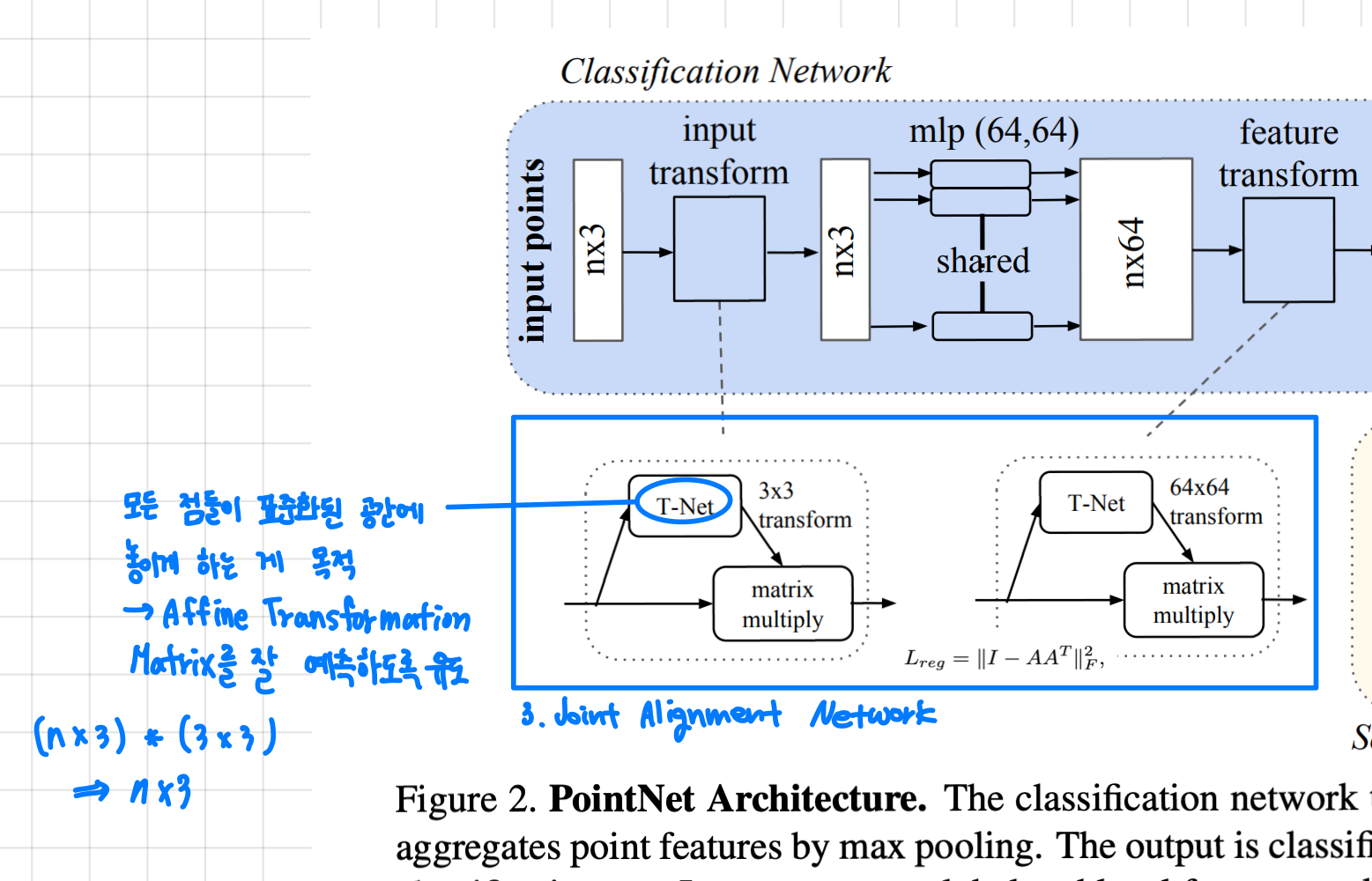
- input transform: 첫 번째 T-Net으로 nx3으로 들어오는 입력에 3x3 affine transformation matrix를 예측하여 input points를 표준화([nx3] * 3x3 = [nx3])
- feature transform: 두 번째 T-Net으로 MLP(FC)를 거친 nx64 feature map에 64x64 transformation matirx를 예측하여 nx64 feature map을 표준화([nx64] * 64x64 = [nx64])
- 이 때 feature transform 단계에서 예측하는 transformation matrix는 64x64로 크기 때문에 학습하기 어려워서 정규화 항을 추가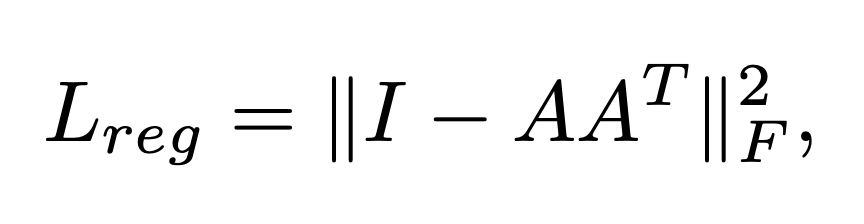
- feature transformation matrix를 orthogonal matrix에 가까워지도록 유도
- orthogonal matrix는 입력 정보를 잃지 않기 때문에 적절
[참고]
https://arxiv.org/pdf/1612.00593
https://lee-jaewon.github.io/deep_learning_study/pointnet/
https://velog.io/@se0yeon00/pointNet-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
https://talktato.tistory.com/42
