
Quantization을 QAT, PTQ로 크게 분류했다.
QAT
-
LLM QAT(Liu et al, 2023b, CoRR)
-
standard QAT framework을 direct하게 LLMs에 구현
-
LLM 자체에서 데이터를 생성하여 knowledge를 distillation하고, 이를 바탕으로 quantized된 LLM을 original LLM의 output distribution에 맞게 training시킴.
-
-
BitDistiller(Du et al, 2024, CoRR)
-
QAT와 self-distillation을 merge하여 sub-4-bit precision에서 LLM 성능 향상.
-
Tailored asymmetric quantization, clipping, Confidence-Aware Kullback-Leibler Divergence objective를 사용하여 faster convergence와 superior result 달성.
-
-
OneBit(Xu et al., 2024, CoRR)
- LLM weight matrices에 대한 1-bit quantization을 구현하기 위해 1-bit parameter representation 방법과 parameter initialization 방법 제안.
Remark 1
QAT는 quantization accuracy degradation을 완화시킬 수 있지만, LLMs의 수백~수천억 parameter를 retraining하기 위한 부담이 있다. practical solution은 PEFT(Parameter-Efficient Fine-Tuning)을 QAT의 retraining 과정에 사용하는 것이다.
- QLORA (Dettmers et al., 2023, NeurIPS), PEQA (Kim et al., 2023a, NeurIPS), LoftQ (Li et al., 2023a, CoRR)
- Quantization과 PEFT를 combine하여 model fine-tuning 효율성 향상.
- task-dependent한 문제점.
- L4Q (Jeon et al., 2024, CoRR)
- LoRA-wise learned quantization step size를 leverage하여 LLM에 대한 generality 향상 시도.
PTQ
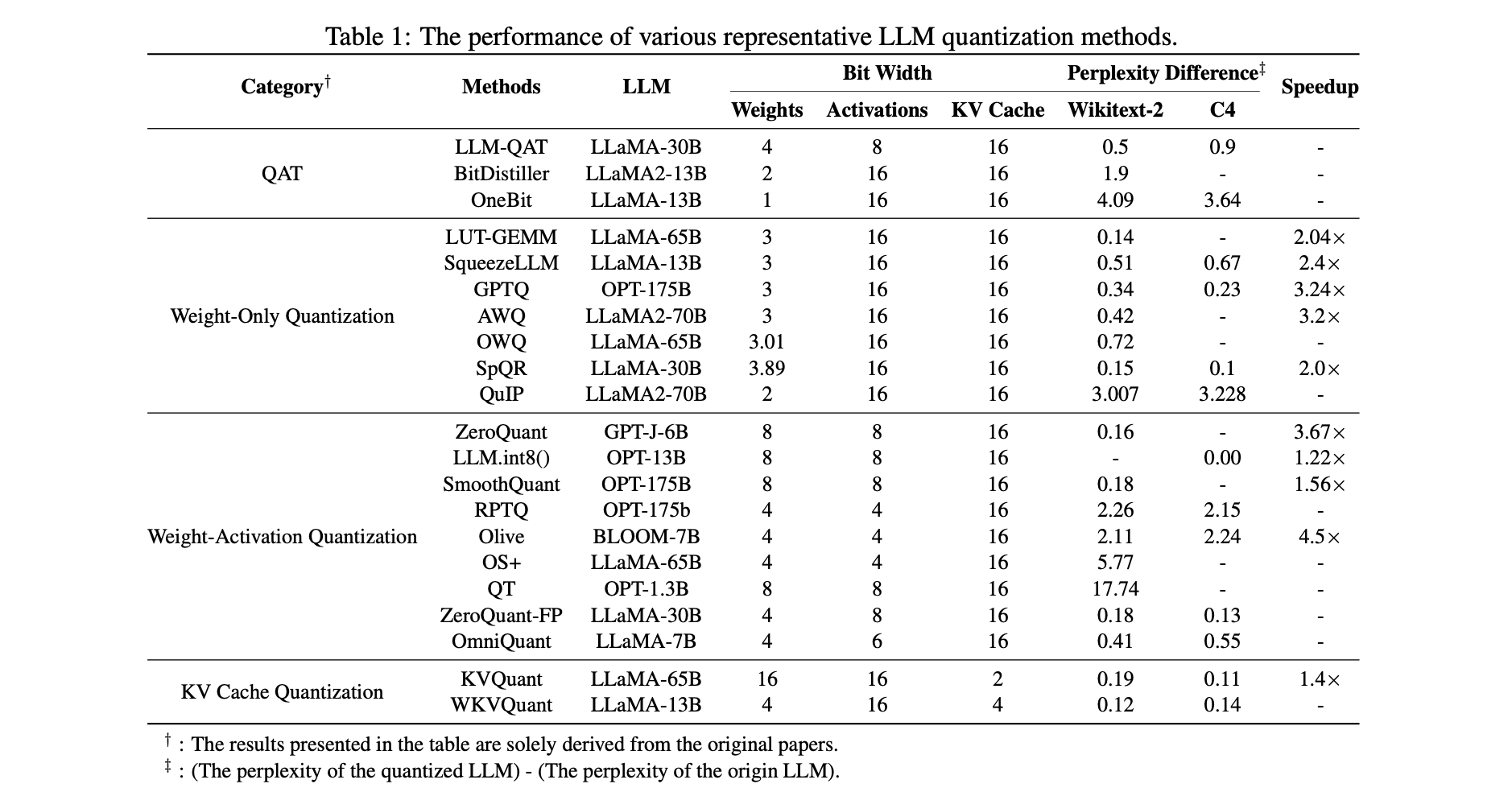
LLMs PTQ하는 방법을 quantization 대상에 따라 세 그룹으로 분류했다.
-
1.Weight-Only Q
-
가장 보편적이고 널리 사용되는 방법.
-
Activation quantization은 일반적으로 weight quantization보다 더 sensitive함. weight-only quantization이 lower bit-width를 달성할 수 있음.
-
Weight-only quantization의 한계
- Quantized weights는 activations와 multiplication 전에 dequantization이 필요하다. 이는 inference 동안 additional computational overhead를 불가피하게 일으키므로, Specific hardware가 지원하는 accelerated low-bit operation의 이점을 활용할 수 없음.
-
-
2.Weight-Activation Q
-
3.KV Cache Q
-
KV Cache Q는 attention layer의 keys와 values를 저장하는 KV cache를 target으로 삼는다.
-
KV Cache는 memory를 많이 잡아 먹으며, 긴 token들을 포함하는 input stream의 bottleneck이 된다.
-
KV Cache Q를 통해 throughput을 향상하고, 더 긴 token들을 갖는 input을 효율적으로 처리할 수 있다.
-
Weight-Only Quantization
-
LUT-GEMM (Park et al., 2024, ICLR )
- Binary-coding quantization (BCQ(Rastegari et al., 2016)) format을 사용해서LLMs의 parameters를 binary parameters와 scaling factors set으로 factorize하여, Weight-only quantization에서 quantized matrix multiplications 가속화.
-
GPTQ (Frantar et al., 2023, ICLR)
- Optimal Brain Quantization (OBQ(Frantar and Alistarh, 2022)),에 기반한 layer-wise quantization method 제안.
- Inverse Hessian information으로 weights를 update하고 LLMs를 3/4-bit로 quantize.
-
QuIP (Chee et al., 2023, NeurIPS)
- calibation set에서 random하게 뽑은 data에서 uniform하게 추출된 vectors로부터, Hessian matrix의 LDL decomposition를 활용하여 weights를 adjust.
- Weight와 Hessian matrices에 random orthogonal matrices의 Kronecker product를 곱하여 weight와 Hessian matrices 사이의 incoherence 보장.
- 2-bits로 LLMs를 성공적으로 quantization.
LLM의 weight-only Q에서 quantizatoin error를 더욱 minimize하기 위해, 많은 연구에서 sensitive weights를 identify하고, sensitive weights를 high precision에 저장한다.
-
AWQ (Lin et al., 2023, arXiv)
- LLM performance에 가장 큰 영향을 미치는 상위 1% weights를 high-precision으로 저장.
- Per-channel scaling method를 통해 optimal scaling factors를 identify. (여기서 "channel"은 model이 갖는 individual dimensions or feature maps을 말한다.)
-
OWQ (Lee et al., 2024, AAAI)
- Activation outliers에 sensitive한 weights를 high-precision으로 저장.
- 나머지 non-sensitive weights를 quantize.
-
SpQR (Dettmers et al., 2024, ICLR)
- Original predictions와 quantized predictions 간의 L2 error를 weight sensitivity metric으로 사용.
-
SqueezeLLM (Kim et al., 2023b, arXiv)
- Sensitivity에 기반한 weights clusters algorithm 도입.
- K-means centroids를 quantized weight values로 사용하여 sensitive weights 식별.
- Sensitive weights를 efficient sparse format으로 저장하고 다른 weights를 quantize.
- LLMs를 3-bit로 quantize하여 FP16 baseline 대비 2배 이상의 speedup 달성.
Weight-Activation Quantization
-
ZeroQuant (Yao et al., 2022, NeurIPS 2022)
-
LLMs에 대한 첫 weight-activation quantization 구현
-
Weight에는 group-wise quantization, activation에는 token-wise quantization 사용
-
LLMs의 weights와 activations를 INT8로 precision 감소
-
LLMs는 activations에서 outliers를 가지는데, outlier를 갖는 activvation을 direct하게 quantization하는 경우, LLMs의 성능이 많이 저하된다.
최근엔 quantizatoin error를 줄이기 위해 이러한 outlier들을 다루기 위한 시도를 하고 있다.
-
LLM.int8() (Dettmers et al., 2022, NeurIPS 2022)
-
Outlier feature dimensions를 high-precision으로 저장하고,
-
서로 다른 features에 대해 vector-wise quantization 사용 (matrix multiplication 내부의 각 inner product에 별도의 normalization constants 할당)
-
LLMs의 weights와 activations를 어떠한 성능 저하 없이 8-bit로 quantize
-
-
SmoothQuant (Xiao et al., 2023, ICML 2023)
-
발견: 서로 다른 token들이 activation channels에서 유사한 variation을 가짐을 발견
-
제안 방법: per-channel scaling transformation을 설계하여, activation outliers를 smoothing
-
-
RPTQ (Yuan et al., 2023a, arXiv)
-
발견: 서로 다른 channels 간 value range의 큰 차이 발견
-
제안 방법: Channel reordering method(activation의 channels를 cluster하고 재정렬, 각 cluster 내 values에 동일한 quantization parameters 사용)를 통합
-
적용 대상:layer normalization과 linear layer weights에 적용하여 channels 간 numerical range 차이의 영향 효율적으로 감소.
-
-
OliVe (Guo et al., 2023, ISCA 2023)
-
Outliers가 normal values보다 중요하다고 판단
-
Outlier-victim pair (OVP) quantization 사용하여 low hardware overhead로 outlier values를 locally 처리
-
-
OS+ (Wei et al., 2023, EMNLP 2023):
-
Outliers가 특정 asymmetric channels에 집중되어 있음을 발견
-
Channel-wise shifting으로 asymmetry의 영향 제거
-
Channel-wise scaling으로 outliers의 분포 균형
-
-
LLM-FP4 (Liu et al., 2023a, EMNLP 2023):
-
Floating-point formats (FP8, FP4) 사용하여 전통적 integer quantization의 한계 극복
-
Exponent bits와 clipping range가 FP quantization 성능에 중요한 요소임을 지적
-
Optimal exponent bias와 maximal quantization value를 결정하는 search-based framework 도입
-
-
OmniQuant (Shao et al., 2024b, ICLR 2024):
-
Activation outliers 처리를 위해 quantization의 challenge를 activation에서 weights로 shift.
-
Clipping threshold를 최적화하여 weights의 extreme values 조정
-
KV Cache Quantization
LLMs의 input tokens 수가 증가함에 따라, KV cache의 memory usage가 증가한다.
최근엔 LLM의 memory footpring를 줄이고 inference를 accelerate하기 위한 연구가 시작되고 있다.
- KVQuant (Hooper et al., 2024, arXiv):
- 여러 KV Cache Quantization 방법 제안
- Per-Channel Key Quantization
- PreRoPE Key Quantization
- Non-Uniform KV cache quantization
- 10 million context length LLM inference 구현
- 여러 KV Cache Quantization 방법 제안
-
KIVI (Liu et al., 2024, arXiv):
-
KV cache 내 element distribution의 심층 분석 수행
-
Key caches는 per-channel로, value caches는 per-token으로 quantize해야 함을 발견
-
Fine-tuning 없이 KV cache를 2 bits로 quantization 성공
-
-
WKVQuant (Yue et al., 2024, arXiv):
-
Past-only quantization을 통합하여 attention computations 개선
-
Two-dimensional quantization strategy로 KV caches의 distribution 효과적 관리
-
Cross-block reconstruction regularization으로 parameters 최적화
-
Weights와 KV caches 모두 quantization
-
Weight-activation quantization에 견줄만한 memory 절약 달성
-
Weight-only quantization에 근접하는 성능 수준 유지
-
