
Abstract
AWQ finds that not all weights in an LLM are equally important.
Protecting only 1% salient weights can greatly reduce quantization error.
To identify salient weight channels, we should refer to the activation distribution, not weights.
AWQ mathematically derive that scaling up the salient channels can reduce the quantization error.
AWQ employs an equivalent transformation to scale the salient weight channels to protect them.
The scale is determined by collecting the activation statistics offline.
AWQ does not rely on any backpropagation or reconstruction, so it generalizes to different domains and modalities without overfitting the calibration set.
Methods
Improving LLM Quantization by Preserving 1% Salient Weights
-
LLM의 weight가 다 동등하게 importance를 갖지 않음을 관찰함.
-
weight의 importance를 결정하기 위해 널리 사용되는 method는 weight의 magnitude 또는 L2-norm으로 결정하는 것.
-
하지만, 저자는 large norm의 weight channel을 Quantization할 때 skip하는 것은 quantized performance 향상이 random selection과 유사할 정도로 미미함을 발견.
-
activation magnitude를 토대로 weights의 importance를 결정하는 방법은 오직 0.1~1%의 channel만 (FP16으로) 살려도, performacne 크게 향상.
-
limitations: 0.1%의 weights만 FP16으로 살리는 것은 mixed precision이 필요하므로, system 구현에 있어 한계가 존재.
Protecting Salient Weights by Activation-aware Scaling
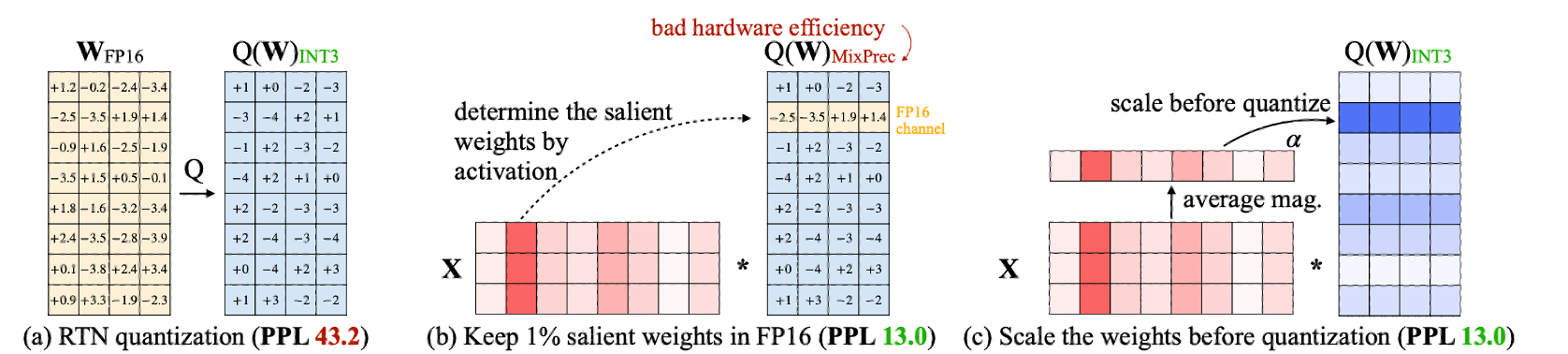
- per-channel scaling을 통해, salient weight의 Q error를 줄이고 hardware inefficieny issue가 없는 대체 방법을 제안.





