LLM-W-only-Q
1.[23.03]GPTQ

GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS
2024년 7월 17일
2.[22.08]Optimal Brain Compression

1. Q할 weight를 고르는 방법 제시 (Q error 최소화 weight) 2. 나머지 weight를 update함으로써 보상하는 방법 제시
2024년 7월 26일
3.[23.06] OWQ: Outlier-Aware Weight Q for Efficient Fine-Tuning and Inference of LLM

GPTQ + LLM.int8()
2024년 8월 12일
4.SqueezeLLM

Sensitivity-based non-uniform QDense-and-Sparse decompositionsparse part: stores outliers and sensitivity weight values in an sparse format.dense part
2024년 9월 20일
5.AI and Memory Wall
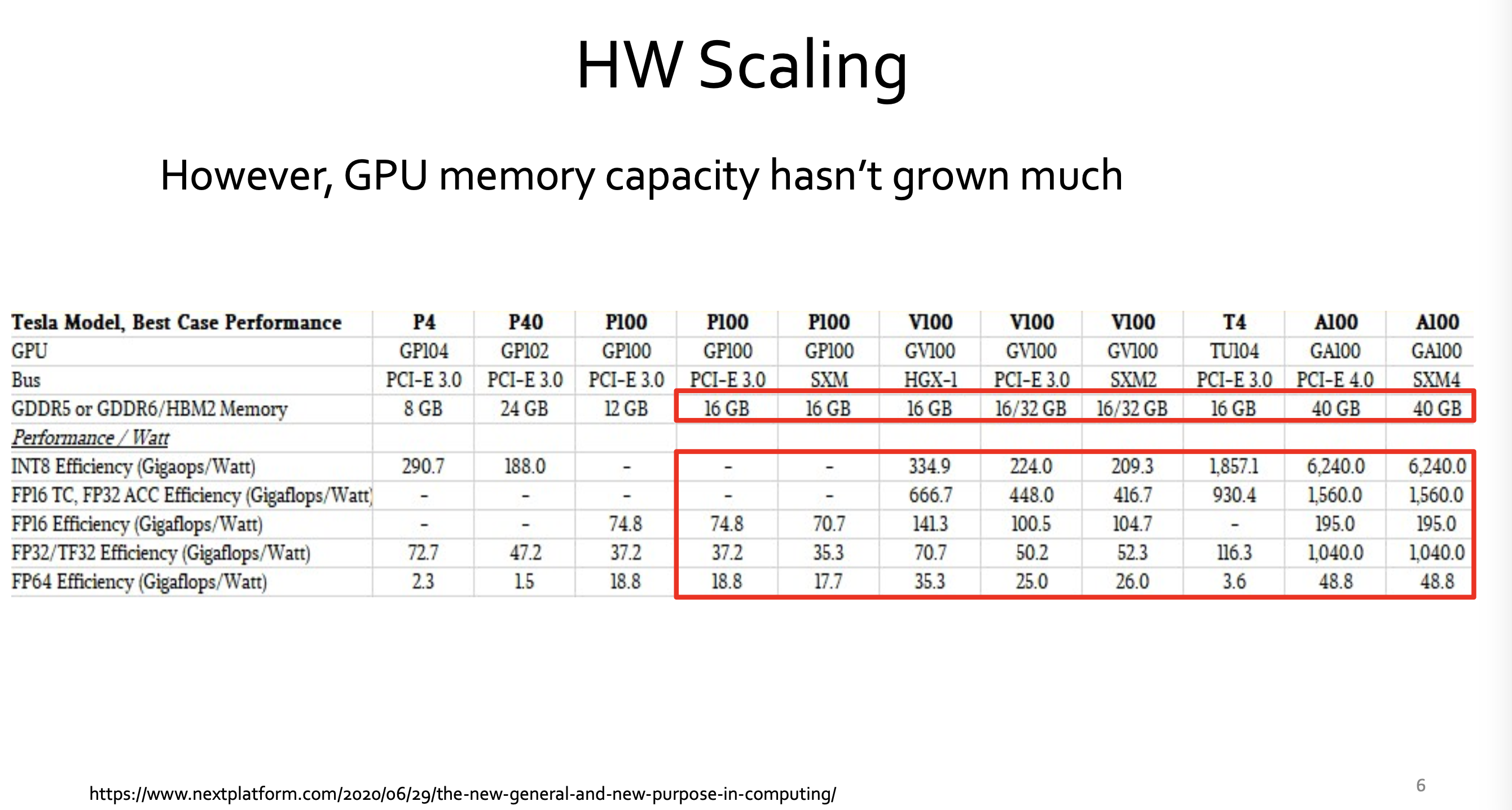
2024.03 arXiv, Gholami keyword: memory bandwidth, bottleneck LLM의 main performance bottlenck은 (기존 computing에서) memory bandwidth이 되어가고 있다. (특히 LLM se
2024년 9월 21일
6.AWQ

AWQ
2024년 11월 18일