Settings

-
1) PTQ of LLaMA3
-
Model: LLaMA3-8B, LLaMA3-70B
-
9 PTQ methods: RTN, GPTQ, AWQ, SmoothQuant, PB-LLM, QuIP, DB-LLM, BiLLM, SliM-LLM
-
Dataset: WikiText2, PTB, 일부분의 C4 dataset.
-
Metric: Perpleixty
-
5 zero-shot evaluation tasks: PIQA, Winogrande, ARC-e, ARC-c, Hellaswag
-
-
2) Q of LLMs via LoRA-FineTuning (LoRA-FT)
- Quantization 이후 Fien-Tuning
- 2 LoRA-FT methods: QLoRA, IR-QLoRA
- dataset: 5-shot MMLU benchmark, 5 zero-shot evaluation tasks.
-
3) PTQ of LLaMA3-based LMMs
- Model: LLaVA-Next-8B
- 위 모델의 LLaMA3 부분에 PTQ 적용.
- GPTQ, AWQ
- Dataset: 6 visual language benchmarks
(AI2D, ChartQA, DocVQA, MME, MMBench)
실험 결과
3) PTQ of LLaMA3-based LMMs
-
quantized LLaMA3 모델을 MLLM 모델 내에서 visual QA 작업에 test.
-
-
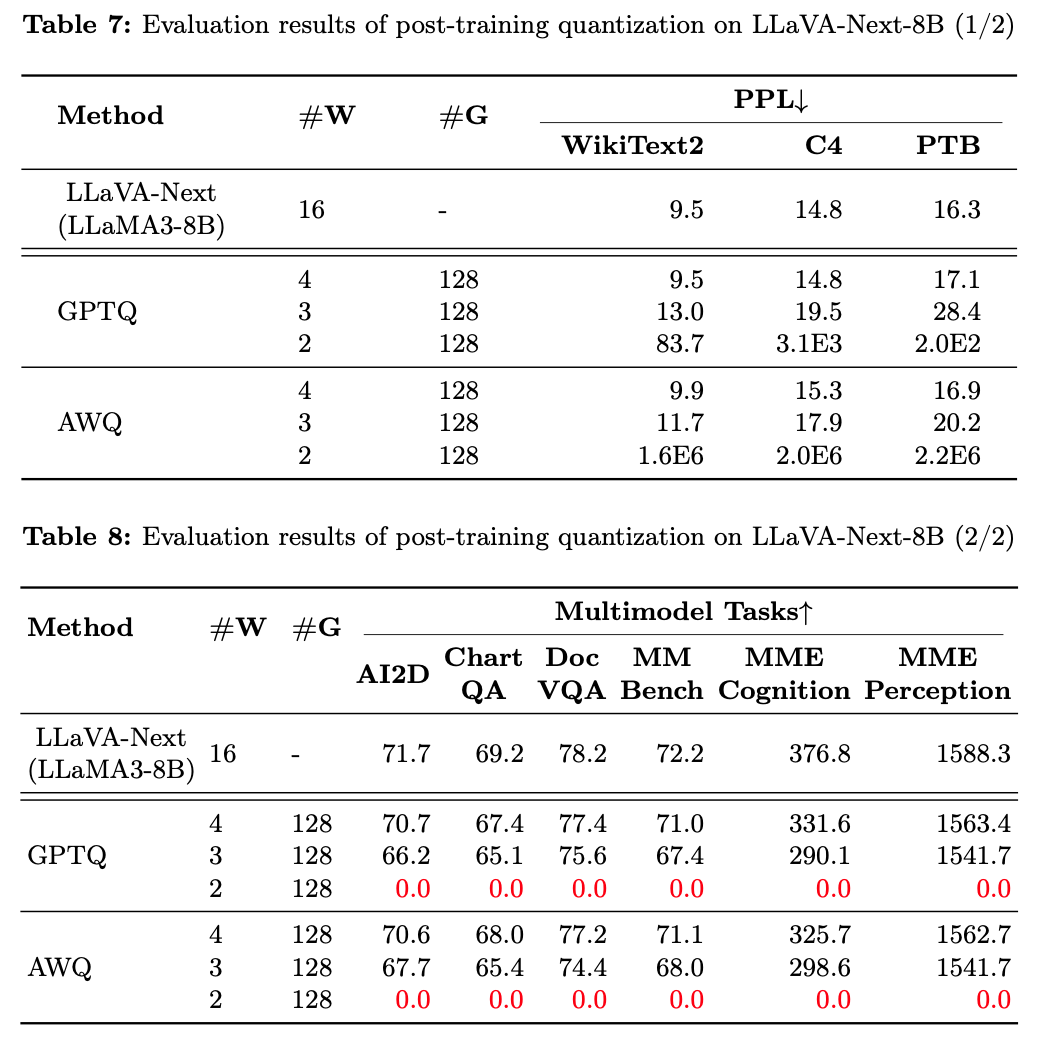
Table 7에 나타난 대로, 두 가지 PTQ 방법(AWQ, GPTQ) 하에서
4-bit MLLM은 multimodal benchmarks에서 2% 미만의 성능 손실을 보임.
즉, 모델 크기를 줄이면서도 효율적으로 visual-language 작업을 수행. -
3-bit에서는 성능 손실이 5%에서 20% 범위로 나타남.
특히, MME Cognition 작업에서 20.75%로 가장 높은 손실을 기록. -
2-bit LLaVA-Next-8B는 GPTQ 또는 AWQ 방법을 사용하더라도 여섯 가지 multimodal QA 작업에서 완전한 기능 collapse.
점수가 0으로 떨어짐.
-
-
Figure 2에서 Figure 6까지는 AWQ를 사용하여 다양한 bit-width에서 quantized된 LLaVA-Next-8B의 실제 visual-language 결과.
-

-

-

-

-

-
4-bit quantized 모델은 여전히 이미지에서 정확한 설명을 생성할 수 있는 반면,
-
3-bit 모델은 전체적인 multimodal 이해에서는 뛰어나지만 세부 사항의 손실을 겪음.
-
특히, Figure 2에서,
- 4-bit와 3-bit 모델이 사람들과 그들의 행동을 묘사하는 것은 16-bit 모델과 대체로 일치.
- 또한, 4-bit 모델은 "Big companies"라는 추상적 의미 이해에서 16-bit 모델과 일치하지만,
3-bit 모델은 "Big companies"를 구멍의 크기를 설명하는 용어로 잘못 해석. - 2-bit quantization에서는 합리적인 답변을 생성하는 데 어려움을 겪으며, 반복적인 문자 응답을 나타냄.
- 이는 순수 언어 작업에서 2-bit 모델이 여전히 논리적으로 일관된 문장을 생성할 수 있다는 이전 연구와는 대조적입니다. MLLM 작업에서는 2-bit 모델이 기대에 가까운 결과를 생성하지 못함.
- 이는 현재 LLM에서의 PTQ 방법(AWQ, GPTQ)이ultra-low bit MLLM 모델에서는 동일하게 효과적이지 않다는 것을 보여주며, 이 큰 도전에 대해 더 나은 quantization 솔루션을 제안할 필요가 있음을 시사함.
-
-
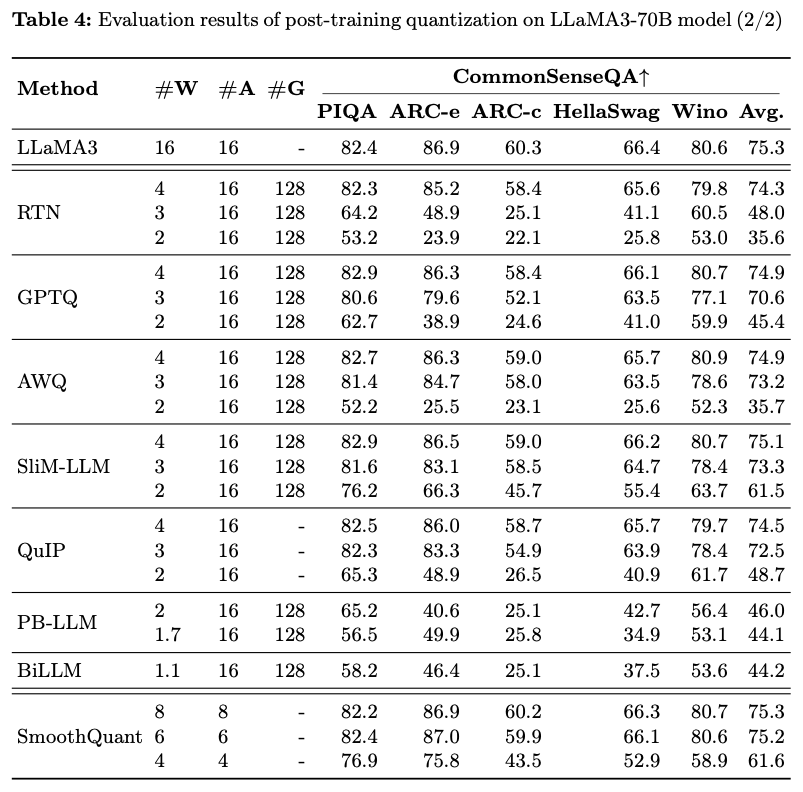
1) PTQ of LLaMA3
- LLaMA3 8B
- GPTQ는 2-3 bits 이하에서, accuracy가 심각하게 collapse
- SmoothQuant는 6-bit, 8-bit weights and activations에서 accuracy를 잘 유지하지만,
4-bit에서 collapse 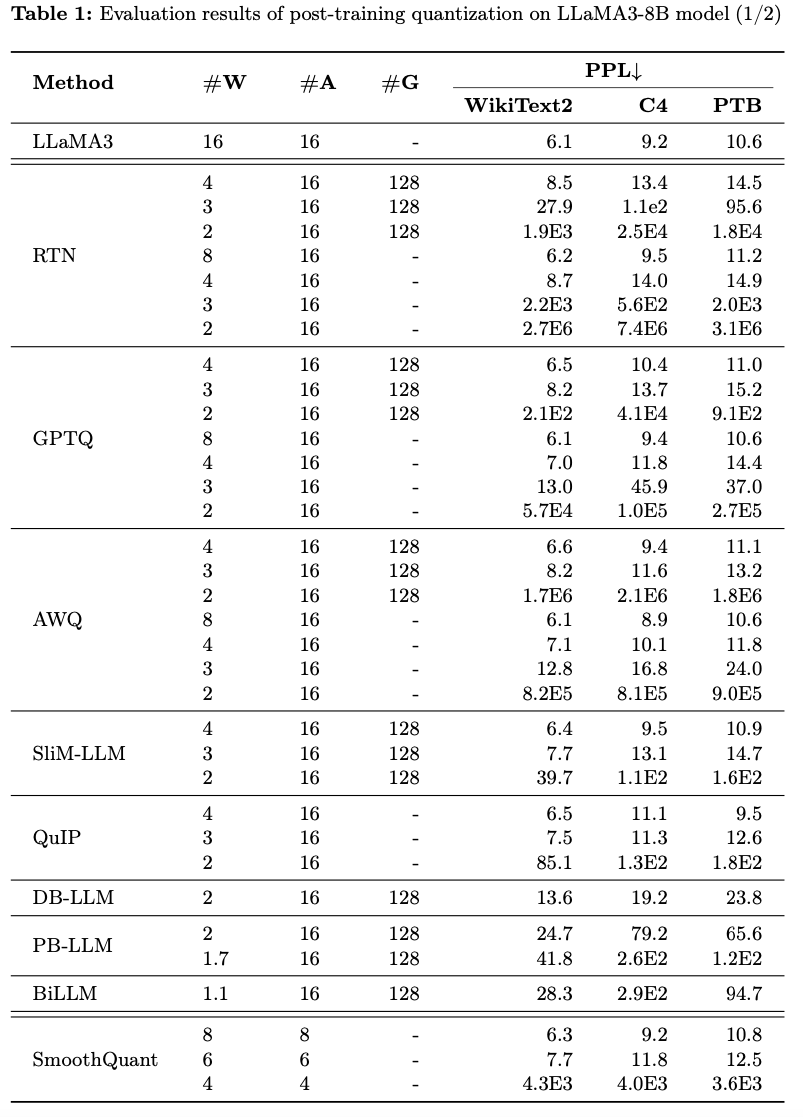
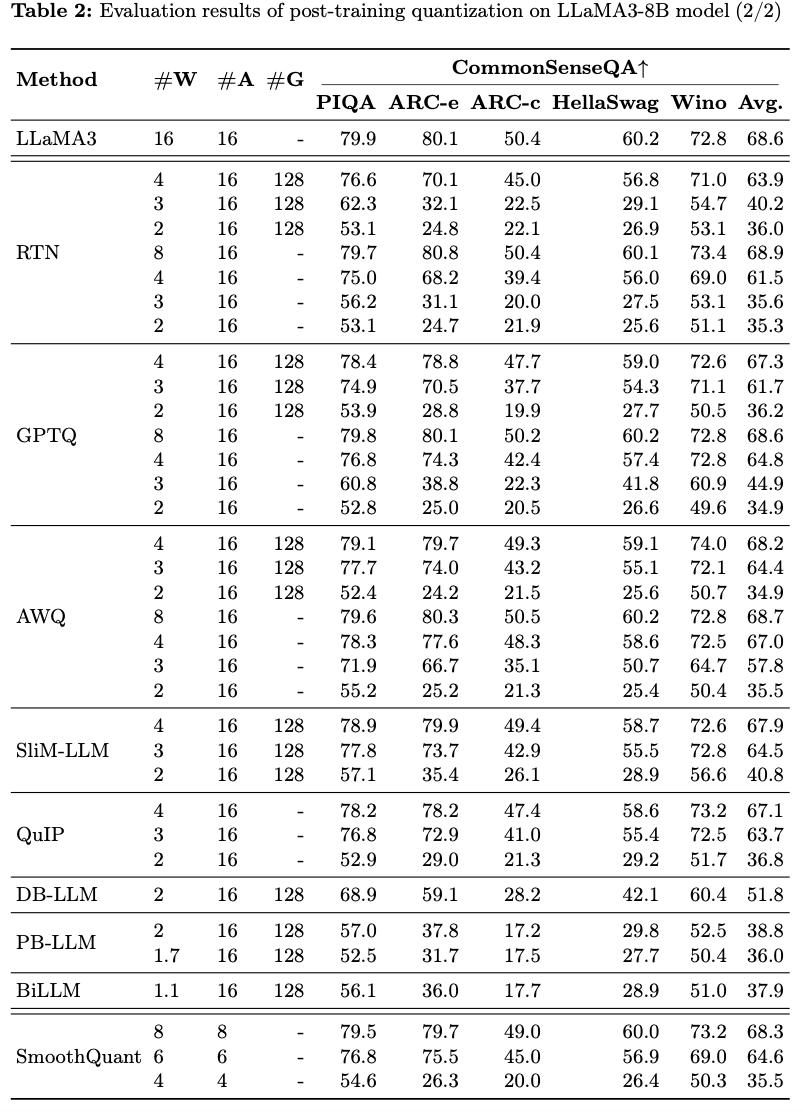
- LLaMA3 70B
- 여러 Q methods에 대해서 robust함.
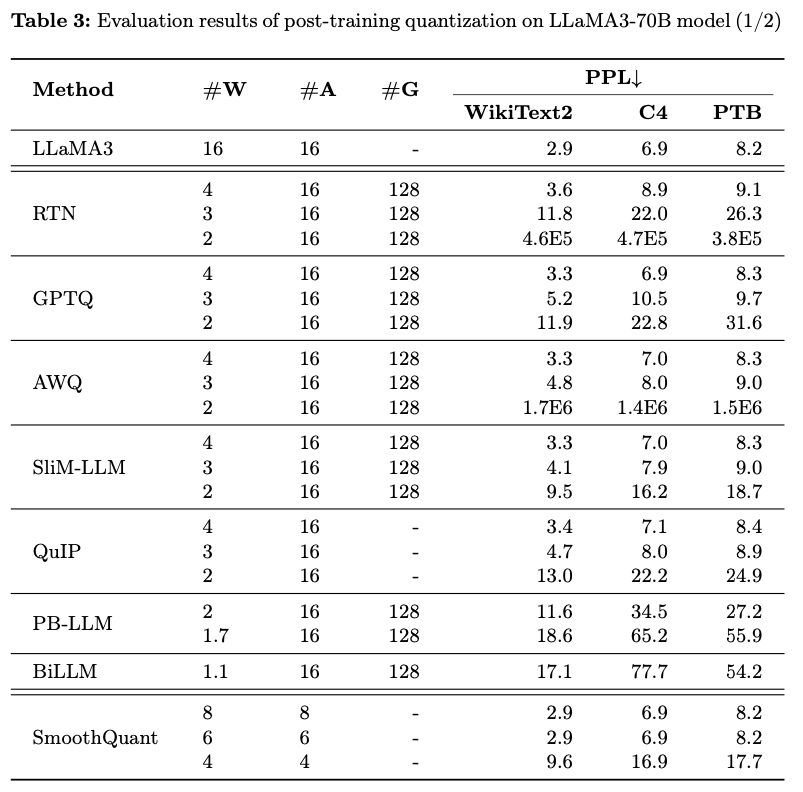
- LLaMA3 8B
-
2) Q of LLMs via LoRA-FineTuning
-
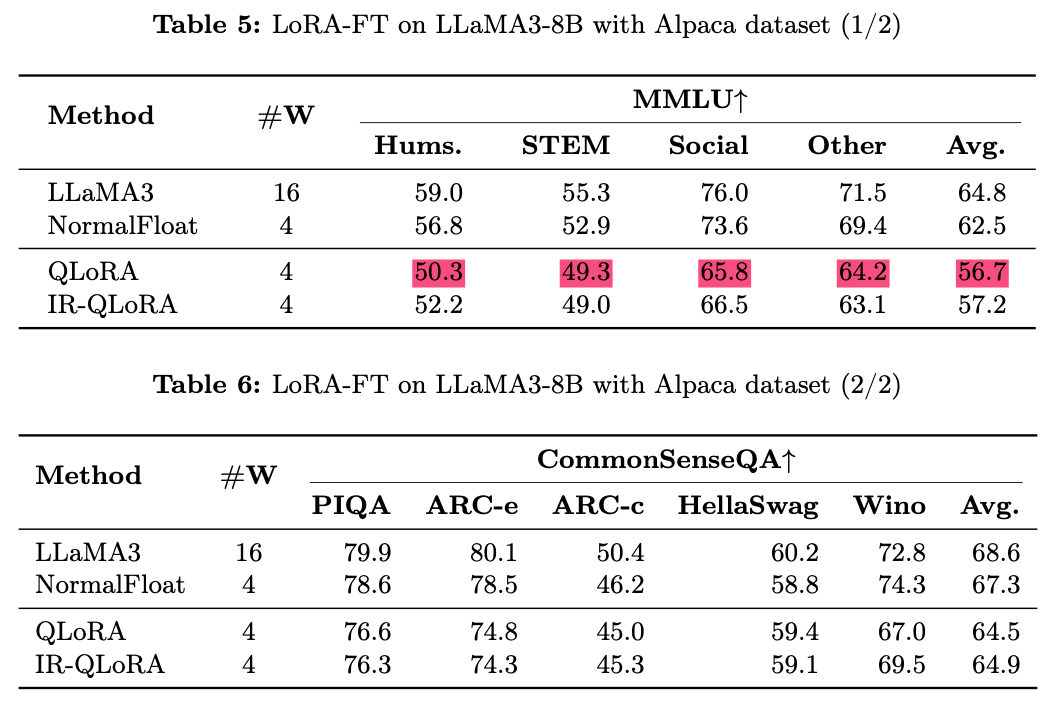
MMLU dataset에서, LoRA-FT quantization 하에서의 LLaMA3-8B와 관련된 가장 주목할 만한 관찰은
Alpaca [22] dataset에 대한 low-rank finetuning이 quantization으로 인해 발생한 오류를 보상할 수 없을 뿐만 아니라,
오히려 성능 저하를 더 심각하게 만든다는 것 -
구체적으로, 다양한 LoRA-FT quantization 방법들은
LoRA-FT 없이 4-bit로 quantization된 경우와 비교했을 때,
4-bit 이하에서 quantization된 LLaMA3에서 더 나쁜 성능을 보임.- 이는 LLaMA와 LLaMA2에서 관찰된 유사한 현상과 극명한 대조를 이룸.
- 이전 모델들에서는 4-bit low-rank finetuned quantized 버전이
MMLU에서 original FP16 counterpart를 쉽게 능가할 수 있었음. - 직관적 분석에 따르면, 이 현상의 주된 이유는 LLaMA3의 massive pre-scale training으로 인한 강력한 성능 때문.
- 이는 original model의 quantization으로 인한 성능 손실이
low-rank parameters를 가진 작은 데이터셋으로의 finetuning으로는 보상될 수 없음을 의미.
-
fine-tuning으로 보상할 수 없는 quantization으로 인한 상당한 성능 하락에도 불구하고,
4-bit LoRA-FT quantized LLaMA3-8B는
다양한 quantization 방법에서 LLaMA-7B와 LLaMA2-7B를 크게 능가. -
예를 들어, QLoRA 방법을 사용할 때,
4-bit LLaMA3-8B의 평균 정확도는 57.0 (FP16: 64.8)으로,
4-bit LLaMA-7B의 38.4 (FP16: 34.6)를 18.6 포인트 앞서고,
4-bit LLaMA2-7B의 43.9 (FP16: 45.5)를 13.1 포인트 앞섭니다.
Accurate LoRA-Finetuning Quantization of LLMs via Information Retention(2024)
QA-LoRA: Quantization-aware Low-Rank adaptation of LLMs(2023)
이는 LLaMA3 시대에 새로운 LoRA-FT quantization 패러다임이 필요함을 시사함. -
CommonSenseQA benchmark에서도 유사한 현상이 발생
- LoRA-FT 없이 4-bit로 quantization된 counterpart와 비교했을 때,
QLoRA와 IR-QLoRA를 사용해 fine-tuning된 모델들의 성능도 하락
(예: QLoRA 평균 2.8% vs IR-QLoRA 평균 2.4%) - 이는 LLaMA3에서 high-quality datasets 사용의 중요성을 더욱 입증하며,
Alpaca와 같은 general dataset이 다른 task에서 모델의 성능 향상에 기여하지 않음을 보여줌.
- LoRA-FT 없이 4-bit로 quantization된 counterpart와 비교했을 때,
-
-
