가장 간단한 버전으로 구현 요약
1. 신경망으로 U-Net을 사용한다.
2. Forward Process를 정의한다.

2-1) variance schedule: scheduling
def linear_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start, beta_end, timesteps)2-2) noising (at time step )
def q_sample(x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqert_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumpord_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise2-3) Loss Function을 정의한다.
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
if noise is None:
noise = torch.randn_like(x_start)
# noised image
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
# predicted noise. 여기서 denoise_model은 U-Net
predicted_noise = denoise_model(x_noisy, t)
# l1_loss를 사용할 경우
loss = F.l1_loss(noise, predicted_noise)
return loss3. Reverse Process를 정의한다.

1) time step 의 pure noise에서 Gaussian distribution을 sampling한다.
2) denoising
time step T부터 0까지, 신경망을 사용해서, 신경망이 학습한 conditional probability를 이용해 점진적으로 denoise한다.
mean을reparameterization하여 만든 우리의 noise predictor를 이용해서,
우리는 조금 더 denoised 된 image 을 얻을 수 있다.
이 과정을 통해 real data distribution 에서 생성된 것과 유사한 새로운 image를 얻게된다.
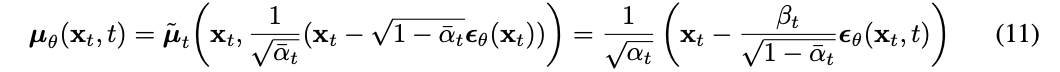
@torch.no_grad()
def p_sample(model, x, t, t_index):
betas_t = extract(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
# 1/sqrt(\alpha_t)
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# Equation 11 in the paper
# Use our model (noise predictor) to predict the mean
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
if t_index == 0:
return model_mean
else:
posterior_variance_t = extract(
posterior_variance, t, x.shape
)
noise = torch.randn_like(x)
# Algorithm2 line 4:
return model_mean + torch.sqrt(posterior_variance_t) * noise4. Model Training
epochs = 6
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
# Algorithm 1 line 3: sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = p_losses(denoise_model=model, x_start=batch, t=t, loss_type="huber")
if step % 100 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
5. Sampling(Inference)
# Algorithm 2 (includint returning all images)
@torch.no_grad()
def p_sample_loop(model, shape):
device = next(model.parameters()).device
b = shape[0]
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc = 'sampling loop time step', total=timesteps):
img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)
imgs.append(img.cpu().numpy())
return imgs
@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size)) 결과 시각화
# show a random one
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")