GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
LLM-KV-Cache-Q

Observations
1) KIVI는 간단한 task에선 👍🏻, 복잡한 task에선 👎🏻
simple task 👍🏻
-
기존 방법(KIVI, KVQuant, FlexGen)들은 간단한 작업에서 low-precision에서 잘 동작함.
(multiple-choice QA, text classification, 또는 간단한 summarization과 같은 natural language understanding 작업) -
simple tasks의 경우, 모델이 생성해야 할 토큰 수가 적으며, correct prediction에 필요한 정보는 대개 일부 중요한 contextual tokens에서 유도될 수 있다.
따라서, 상대적으로 큰 approximation error가 존재하더라도 목표 토큰의 생성에 큰 영향을 미치지 않는다.
complex task 👎🏻
-
그러나, longer responses를 생성하거나 reasoning이 필요한 complex generative tasks에 적용할 경우, 뚜렷한 성능 저하가 발생함.
예를 들어, mathematical problem-solving (Cobbe et al., 2021) 및 chain-of-thought (CoT) reasoning (Wei et al., 2023)과 같은 작업에서는 성능이 크게 저하됨.
특히 high compression ratio (예: 4-bit/2-bit quantization 또는 dropping > 50% tokens (Ge et al., 2023)) 환경에서 이러한 현상이 더욱 두드러짐.
이러한 성능 저하는 본래의 KV와 압축된 KV 사이에서 발생하는 non-trivial한 approximation error 때문으로 볼 수 있음. -
반면, complex tasks에서는 모델이 longer sequences를 생성해야 하며, prompt 내에 densely correlated information이 포함되는 경우가 많다 (예: CoT reasoning).
이러한 환경에서는 autoregressive decoding이 각 단계에서 approximation error를 누적시키며, 상대적으로 작은 오류라도 generation steps을 거듭할수록 그 부정적인 영향이 증폭된다.
결과적으로, 이후 generation이 점점 더 악화되어 성능이 저하된다. -
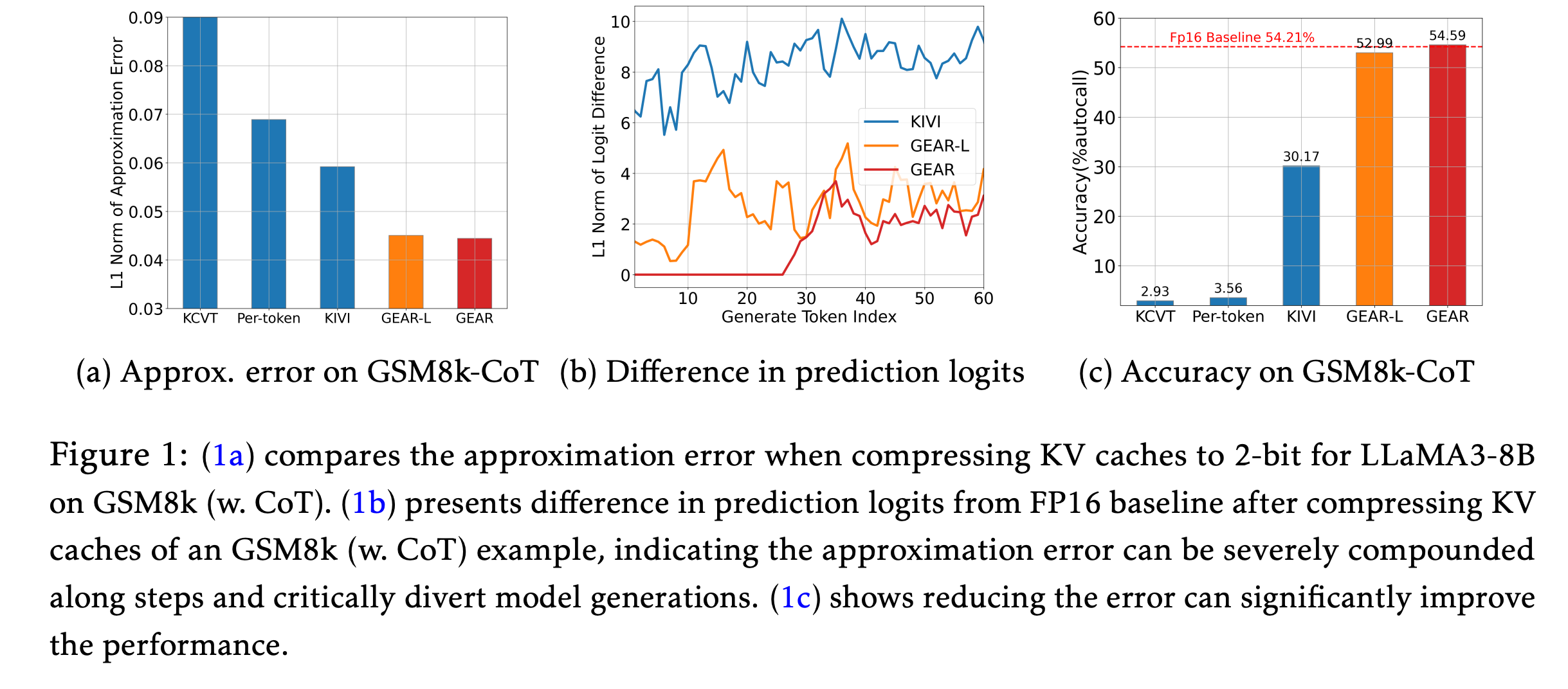
()
(a): Quant 방법에 따라 GSM8k에서 보이는 approximation error와,
(b): 누적된 error로 인해 token generation이 어떻게 편차를 보이며,
(c): accuracy를 크게 저하시킬 수 있는지를 보여준다.
따라서, 본 문제의 핵심은 high compression ratios 환경에서의 높은 approximation errors이며, 이를 해결하는 것이 중요한 과제이다.
Key contributions
Overview
-
3 components to decompose & compress KV matricees
-
1) a quantized matrix
apply an existing quantization method(KIVI-like) to quantize the majority (e.g., 98%) of entries of similar magnitudes to ultrea-low precision.
KCVT라고 명명하고 이걸 씀. -
2) a low-rank matrix
then, introduce low-rank matrix to approximate the quantization residuals
(to approximate the quantization error) -
3) a sparse matric
finally, employ a sparse matrix to capture outliers.
⭐ sparse matrix는 outlier만 값을 갖고, 나머지는 0 값을 갖는 matrix
-
such a composite approximation decouples the coherent parts from incoherent parts of the approximation error:
- the low-rank matrix captures the majority of coherent basis of quantization error
- while the sparse matrix rectifies the incoherency existing in individual outliers.
-
we find that using both sparse and low-rank components is necessary for GEAR to establish the best performance, highlighting their complementary nature.
- Lite version GEAR-L
: low-rank approximation alone for quantization can still effectively reduce the approximation error,
yielding both significant efficiency and performance improvement.
- Lite version GEAR-L
Goal Formulation
-
Goal: tensor 𝑋 ∈ {𝐾𝑡,𝑉𝑡}가 주어졌을 때, compressed counterpart를 사용하여 𝑋의 approximation error를 최소화하는 것이다.
-
한 가지 component만으로는 goal 달성 불가
-
simple startegy는
세 가지 compression methods 각각을 개별적으로 적용하여
𝑋를 근사하고, 그 거리를 최소화하는 것이다.
예를 들어, top singular values/vectors를 사용하여 𝐿을 구성하거나,
largest magnitudes를 가지는 항목들로 𝑆를 구성할 수 있다. -
() 그러나 이러한 세 가지 방법 중 하나에만 의존하는 경우, 모두 high compression ratios에서 substantially increased error를 초래하므로 high compression ratios를 달성할 수 없다.
(또한, 는 matrix approximation에서 서로 다른 구성 요소를 포착하는 방식으로 작동할 수 있다.)
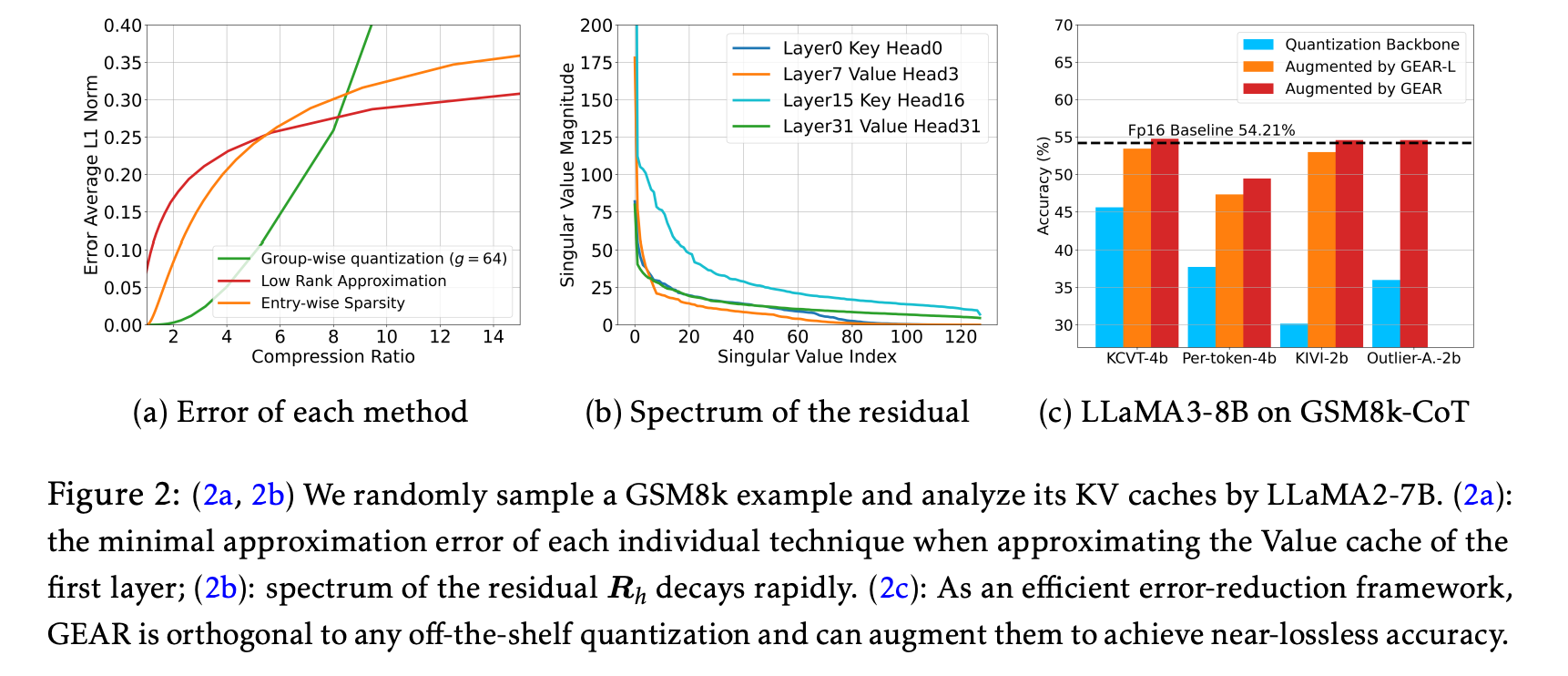
-
이 motivation을 바탕으로, 세 가지 component를 통합하는 방안을 탐색한다.
-
-
✅ Goal: 다음의 approximation error를 최소화 하는 것.
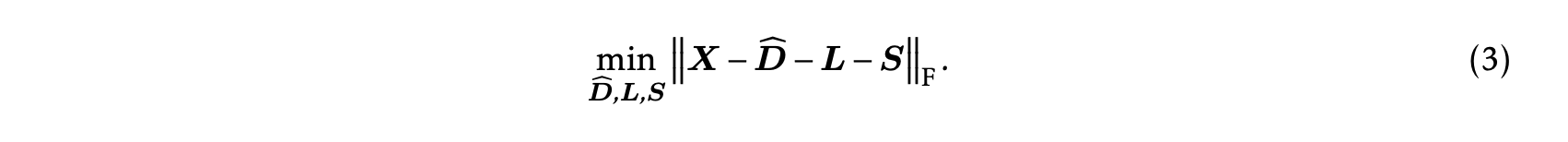
- 식 (3) 을 최소화하는 하나의 흥미로운 아이디어는 quantization, singular-value decomposition (SVD), 그리고 outlier extraction을 번갈아 가며 수행하고, 세 개의 matrices 를 반복적으로 업데이트하여 minimal error에 도달하는 것이다.
- 이 아이디어는 (, Li et al. 2023)에서 유사한 목표를 위해 도입되었으며, weight quantization의 정확한 초기화를 최적화하는 데 활용되었다.
- 그러나, inference system은 엄격한 speed requirements를 가지며,
이러한 iterative updates로 인해 발생하는 significant latency는 generative inference에 적용하기에는 적절하지 않다.
따라서, 우리는 approximation error (3)을 최소화하기 위한 efficient solution을 제안한다.
Method 1) sparse matrix 로 outlier filtering
⭐ sparse matrix는 outlier만 값을 갖고, 나머지는 0 값을 갖는 matrix
-
Inspiration 🫶🏻: SqueezeLLM
weight quantization 연구(Kim et al., 2023)에 영감을 받아,
quantized backbone 와 sparse matrix 가 KV cache compression에서 서로를 보완하는 역할을 한다는 점을 관찰했다.
구체적으로, quantization scheme은 outlier entries로 인해 non-trivial quantization errors를 초래할 수 있다.
✅ 따라서, 한 가지 직관적인 전략은 quantization 전에 이러한 outliers를 filter out하는 것이다. -
per-vector outlier filtering
-
per-channel Key quantization 및 per-token Value quantization의 grouping과 align하기 위해, per-vector outlier filtering을 사용한다.
-
입력 tensor (또는 )가 주어졌을 때,
각 channel (또는 token) vector에서 max값 및 min값의 상위/하위 에 해당하는 항목을 추출하고,
이를 full precision으로 유지한 채 sparse matrix 에 저장한다. -
이때, 는 다음과 같이 정의된다:
(: sparse ratio로, GEAR에는 를 사용.)
-
그런 다음, 추출된 행렬에 quantization을 수행하여 quantized backbone 를 얻는다:
-
-
SmoothQuant와의 차이점? & Low-rank matrix 사용 필요성
-
Outlier extraction technique은 (Kim et al., 2023)에 의해 training-dependent non-uniform weight quantization을 보완하는 방식으로 적용되었다.
반면, GEAR는 이를 KV cache에서 tuning-free uniform quantization과 결합하는 가능성을 탐색한다. -
중요한 점은, weights와 비교할 때, KV cache compression은 보다 많은 outliers를 포함할 수 있으므로 accurate quantization이 더욱 어려운 문제라는 것이다 (, Xiao et al., 2023).
또한, Section 4.3의 empirical results에 따르면,
outlier-aware quantization은 ultra-low precision compression(예: 2-bit)을 complex generative tasks에서 달성하는 데 어려움을 겪는다. -
높은 compression ratio를 효과적으로 구현하려면 sparse matrix에 저장된 많은 수의 outliers를 추출하는 것이 필요하다.
그러나, 두 개의 index vector와 한 개의 value vector를 full precision으로 저장하는 것은 considerable memory overheads를 초래한다.
왜 두 개의 index vector와 한 개의 value vector를 저장하나?
-
-
이러한 결과는, S를 활용하면 approximation error를 줄일 수는 있지만, 여전히 완전히 해결하기에는 부족하다!! (아래에서 이를 해결하기 위한 방법을 제시)
Method 2) head-wise Low-rank decomposition
-
✅ 짚고 넘어갈 부분
-
우리는 와 만으로는 원래 행렬 를 잘 복원하기엔 한계가 있음을 관찰했다.
-
어떻게 더 잘 복원할 수 있을까? 생각을 해봤을 때, 부족한 정보를 추가하되, 메모리 사용량은 여전히 잘 유지할 수 있으면 좋겠다.
-
잔차(residual) 은 “quantization으로 인해 제대로 표현하지 못한 부분”이라고 볼 수 있다.
-
그래서 이 부분의 핵심 아이디어는, residual을 low-rank approximation하여, “residual에 남아 있는 중요한 정보”만 적은 비용으로 복원함으로써 quantizatoin error를 보완해보자! 이다.
-
뒤에서 살펴보겠지만, residual 를 low-rank(즉, singular value가 큰 몇 개 성분만 따로 뽑아 근사)한 을 활용하여,
기존: , approximation error 에서,
보완: 이 되어, approximiaton error가 로 줄어든다. -
그러면 을 그대로 사용해버리지 왜 low-rank approximation을 할까? 라는 생각이 들 수도 있다.
그런데, 이는 quantization error를 줄이기 위해 16bit 데이터를 쓰지 왜 4bit 데이터로 줄이냐는 질문과 같다고 생각해보면 이해가 간다.
R을 그대로 다 쓰는건 메모리 사용량도 많고, 그건 compressio이 아니다. R에서 중요한 정보를 살리면서 compression하기 위해, R을 low-rank approximation해서 사용하겠다!로 이해하면 되겠다.
-
-
head-wise low-rank decomposition을
✅ residual 에 적용할 것을 제안한다.- head-wise로 decompose하는 이유는,
다양한 attention heads가 서로 다른 channel ranges 내에서 contextual information을 인코딩한다는 연구(Tenney et al., 2019; Voita et al., 2019; Zhang et al., 2024)에 기반한다.
- head-wise로 decompose하는 이유는,
-
구체적으로, 먼저 을 channel dimension을 기준으로 reshape하여, 개의 multi-head sub-matrices를 얻는다:
여기서 는 head 의 residual을 나타낸다.
-
Low-rank decomposition을 쓸 수 있는 이유
-
의 singular value decomposition(SVD)이 다음과 같이 주어진다고 가정하자:
여기서 는 singular values이며,
는 각각 대응하는 singular vectors이다. -
()
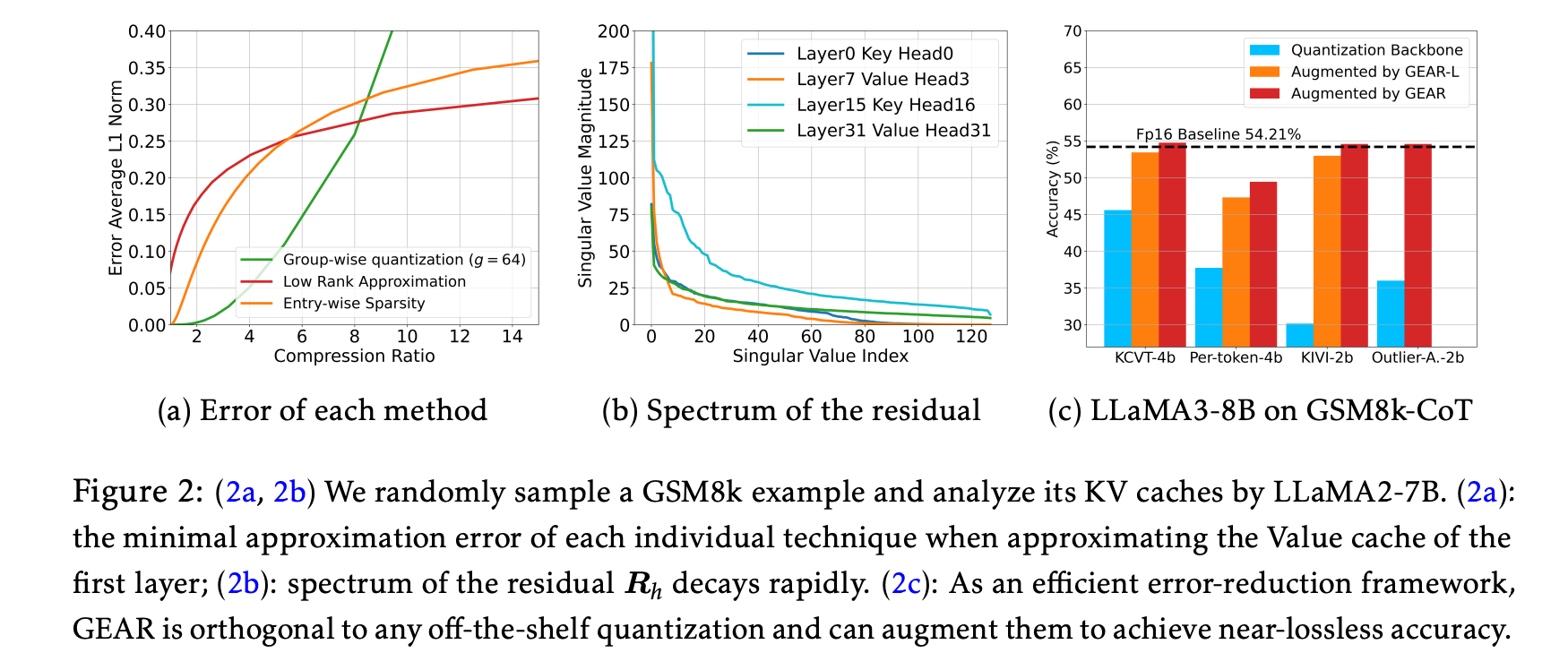
-
✅ singular value의 magnitude가 뒤쪽 index로 가면서 급격하게 떨어짐. 이는 Top- 개 singular value들이 전체 정보(residual)의 대부분을 설명한다는 의미임.
-
✅ 그에 대응하는 singular vectors들 역시 이 “가장 많이 공통으로 드러나는 부분”을 잡아내므로,
token 간에 공유되는 유사한 방향(벡터 패턴)을 잘 포착하게 됨.
이를 “coherent component”라고 부르는 이유도 이 vector들이 ‘서로 들어맞는(=coherent)’ 패턴을 추출하기 때문. -
✅ 따라서 논문에서 제안하는 방식대로, residual 행렬을 SVD로 분해했을 때, 상위 r개(예: r=4) singular value와 그에 대응되는 singular vector들만 뽑아서 복원해도, residual 행렬의 정보가 대부분 살아남.
이것이 바로 “low-rank approximation”이며, 큰 singular values/vectors들이 “공통성분(coherent component)을 대부분 설명한다”는 점을 이용한 것.
결국 이렇게 하면 잔차를 통째로 다 저장하지 않아도 되므로(압축), 메모리를 절약하면서도 복원오차가 매우 작게 유지되는 효과가 생기는 것.
-
-
-
이러한 Top singular values and vectors를 활용하면, residual 내의 coherent information을 효과적으로 capture하고 recover할 수 있다. 그리고 이를 통해, quantization residual에 대한 효과적인 approximation을 수행할 수 있다.
-
이를 위해, 다음과 같은 matrix 를 도입한다:
여기서 는 low-rank matrix로 정의된다:
여기서, , 이며, 은 보다 훨씬 작은 값이다.
-
예를 들어, , 일 때, 만으로도 near-lossless high-ratio compression이 가능하다.
-
의 경우, power iteration algorithm(Vogels et al., 2019)을 사용하며,
이 알고리즘은 를 신속하게 계산하고,
top- singular values/vectors 을 정확하게 근사할 수 있도록 보장한다.
-
-
Multi-batch setting에서는, low-rank approximation을 batch-wise 및 head-wise로 적용한다.
Experiments
Ablation study on sparsity ratio(s) and rank(r)
-
setup
- task: GSM8k (w/ CoT)
- model: LLaMA3-8B
- GEAR 2bit, GEAR-L 2bit
-
()
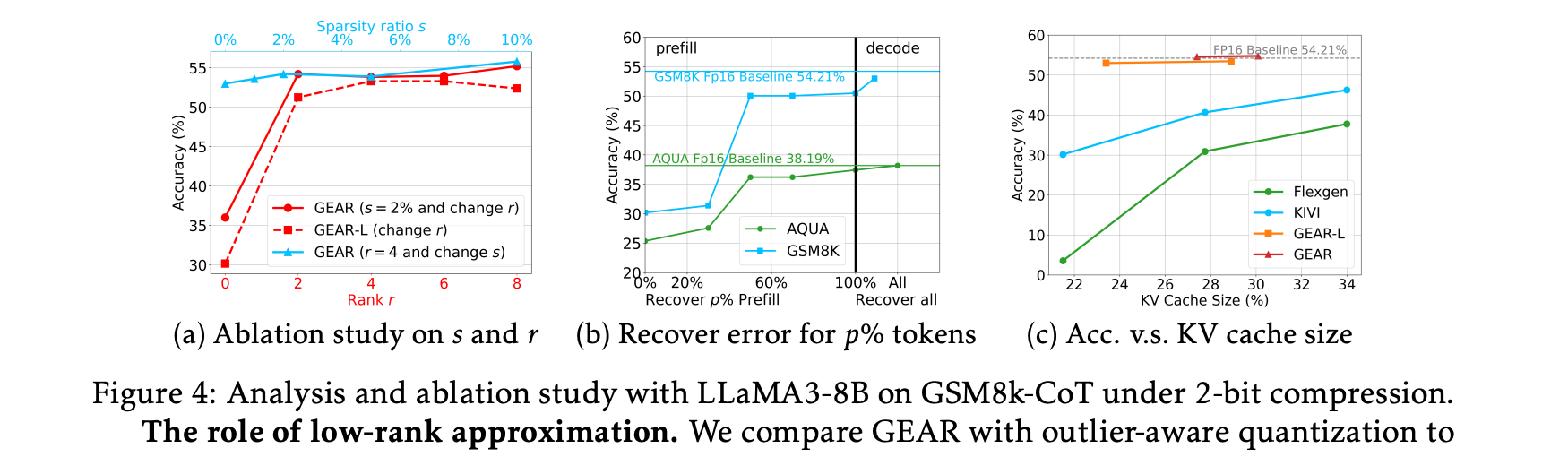
- 또는 을 변화시켰을 때, GEAR는 큰 sparse ratio나 low-rank components 없이도 잘 작동함.
- (GEAR) 및 (GEAR, GEAR-L)과 같은 작은 값으로도 near-lossless 2-bit compression 달성.
- 또는 을 더 증가시키면 accuracy가 향상될 수 있으나, 그 효과는 미미하며, 대신 memory overheads가 증가.
- ✅ 중요한 점은, 를 제거할 경우, GEAR 및 GEAR-L의 성능이 크게 저하된다는 것.
이는 error reduction에서 low-rank approximation이 매우 중요한 역할을 함을 알 수 있음. - ✅ 반면, sparse matrices(for outlier)를 제거할 경우, 성능이 저하되긴 하지만 큰 영향을 미치지는 않음.
이는 quantization 과정에서 entry grouping을 통해 outlier entries로부터 발생하는 incoherent error를 어느 정도 보정할 수 있기 때문.
-
✅ The role of low-rank approximation
-
GEAR를 outlier-aware quantization과 비교하여, low-rank approximation의 중요성을 분석함.
-
()
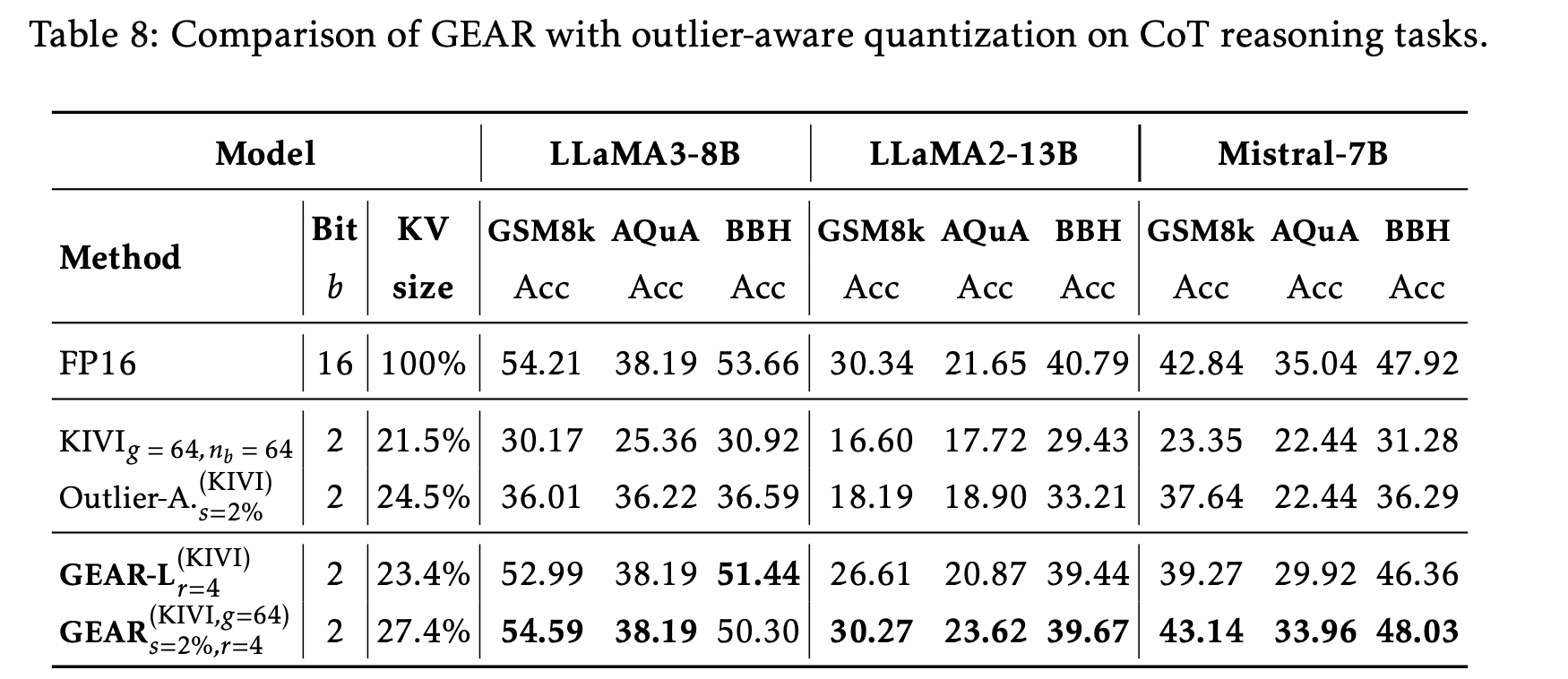
-
결과적으로, outlier extraction만을 이용한 quantization은 성능을 향상시킬 수는 있지만,
GEAR가 달성하는 near-lossless 2-bit performance에는 도달하지 못한다는 것을 확인할 수 있다. -
즉, outlier-aware quantization은 high-ratio compression을 달성하는 데 한계가 있으며,
이 approximation error를 완전히 보정하는 핵심 요소임을 보여줌.
-
-
low-rank approximation을 적용하는 token 수 조정 실험
-
GEAR-L에서 low-rank approximation을 적용하는 token 수를 조정하여, error reduction의 효과를 분석
-
tokens을 다음과 같이 두 개의 그룹으로 나누어서 실험.
-Prefill phrase에서의 input tokens
-Decoding phase에서의 generated tokens -
기본적으로 GEAR는 모든 tokens에 대해 quantization error를 보정하지만,
대신 최근 prefill tokens의 상위 만 선택하여 low-rank approximation을 적용도 가능함. -
() 를 변화시켰을 때 GEAR-L의 성능을 보여줌.
그 결과, low-rank approximation이 적용되는 tokens의 수가 줄어들수록 성능이 저하됨을 확인함.
-
-
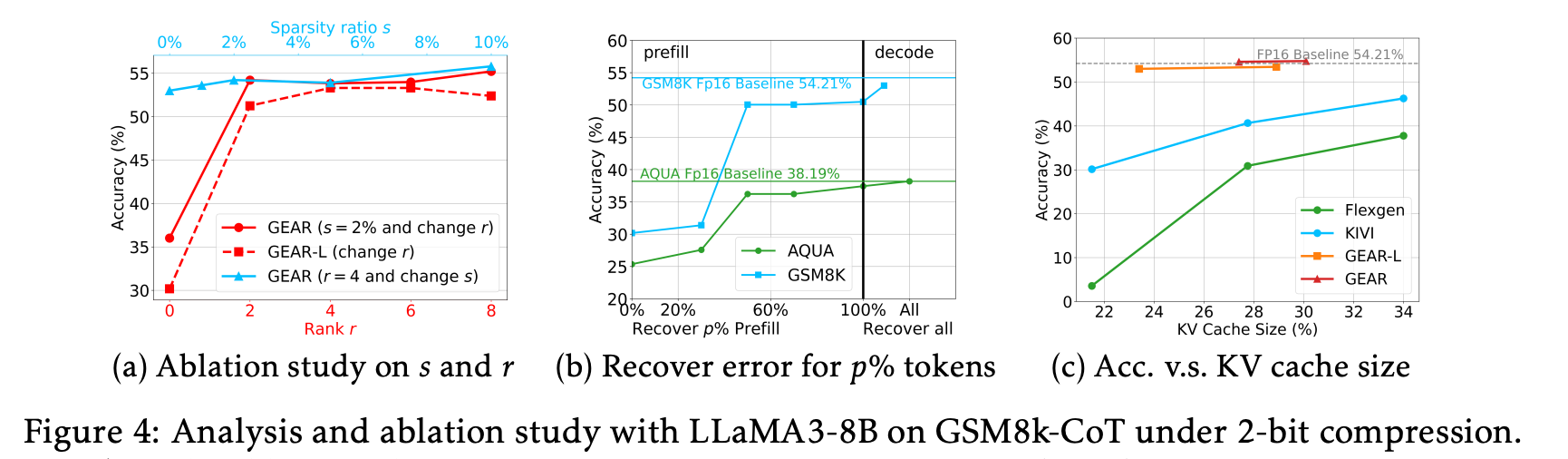
KV compression size에 따른 성능 비교
() LLaMA3-8B의 KV caches를 서로 다른 remaining size로 압축하였을 때, GEAR 및 GEAR-L은 다른 quantization baseline보다 일관되게 우수한 성능을 보임.
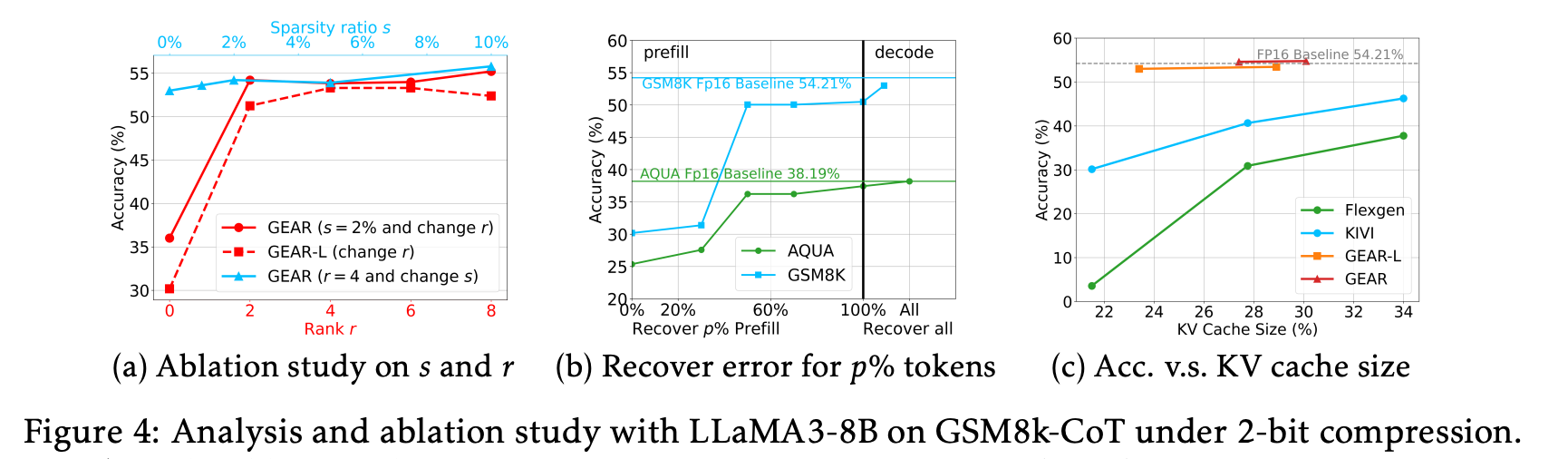
hard CoT reasoning tasks
- setup
- model: LLaMA3-8B, LLaMA2-13B, Mistral-7B
- task: CoT generative tasks(GSM8k, AQuA, BBH)
- 8-shot CoT demonstrations
- GSM8k, AQuA, BBH의 평균 prefill length를 각각 900, 1304, 1021로 설정
부가 내용
Sparse Matrix Format
-
1. Sparse Matrix ( S ) 표현 방식
Sparse matrix는 일반적으로 압축 표현(compressed representation)을 사용하여 저장됨.
이때, 보통 COO (Coordinate Format) 또는 CSR (Compressed Sparse Row) 같은 형식이 사용.
이러한 형식에서는 outlier들이 존재하는 위치 (index vectors)와 해당 위치의 값 (value vector)만 저장함. -
2. 두 개의 Index Vectors
-
Sparse matrix ( S )에서 outliers의 위치를 저장하기 위해 두 개의 인덱스 벡터(index vectors)가 필요함.
-
첫 번째 index vector: Row indices → outlier 값이 어느 행(row)에 있는지 저장
-
두 번째 index vector: Column indices → outlier 값이 어느 열(column)에 있는지 저장
-
-
즉, sparse matrix ( S )에서 outliers의 좌표를 (row index, column index) 쌍으로 저장하는 방식임.
-
-
3. 한 개의 Value Vector
- Sparse matrix 에서 outliers의 실제 값(value)을 full precision으로 저장하는 벡터임.
KCVT
-
KIVI를 quantization backbone으로 사용하는데, KIVI 보다는 덜 fine-grained한 grouping을 사용하여, KCVT라고 부르고 이를 사용함.
-
KCVT(KIVI의 coarse-grained 버전)
논문에서 말하는 KCVT는 KIVI처럼 ‘per-channel Key’ + ‘per-token Value’ 방식은 동일하지만,
“group size를 크게(=coarse-grained)” 잡아서 스케일/제로포인트 저장 오버헤드를 크게 줄인 방식.-
Key: “per-channel” quant 자체는 KIVI와 동일하지만, group size를 channel 전체(예: 𝑛 ) 로 잡음.
즉, 한 channel 내 모든 Key entry(길이가 𝑛)를 하나의 group으로 보고, 거기에 대해 scale/zero point를 하나씩만 유지. -
Value: “per-token” quant도 마찬가지로, 한 token의 Value 벡터 전체 차원 𝑑 를 하나의 group으로 취급.
그 결과, 한 token마다 scale/zero point가 1개씩만 있으면 됨.
-
straming buffer strategy
-
GEAR는 decoding 과정에서 inference speed를 크게 향상시키기 위해 streaming buffer strategy를 도입하였다.
구체적으로, long-sequence generation을 수행할 때, GEAR는 새롭게 생성된 tokens의 KV vectors를 full precision으로 작은 buffer 에 저장한다.
이 buffer의 크기는 로 설정되며 (예: ), buffer가 용량을 초과할 때마다 (즉, 매 개의 decoding steps마다), GEAR는 new tokens에 대해서만 compression을 수행한다.
이후, low-rank approximation은 새롭게 생성된 tokens에 대해서만 적용된다. -
KIVI (Liu et al., 2024)에서는 이와 유사하게, buffering approach를 사용하여 residual tokens을 cache에 저장한 후, 그룹이 완성될 때까지 유지하는 방식을 제안하였다.
따라서, residual buffer size는 group size의 배수로 설정해야 한다. -
반면, KCVT의 coarse-grained grouping에서는 buffer size를 자유롭게 설정할 수 있으며, inference speed를 증가시키면서도 non-trivial memory overheads를 방지하기 위해 과 같은 작은 크기를 선택하였다.
-
GEAR의 알고리즘을 Appendix 7의 Algorithm 1에 상세히 정리함.
Implementation details
-
-
Key와 Value에서 straming buffer를 사용해, 새롭게 생성된 Key/Value cache가 매 steps마다 compress함.
-
decoding 중 streaming buffer를 활용하기 때문에, low-rank approximation은 매 steps마다 buffered tokens에 대해서만 수행되며, 이때 ultra low-rank ()를 사용.
-
-
low-rank matrices()의 forward pass를 별도의 경로에서 수행하도록 하였으며,
먼저 down projection(예: )을 계산한 후,
이어 up projection(예: )을 수행함으로써 forward pass의 computational complexity를 줄임. -
GEAR의 경우, ✅ prefill phase에서 sparsity ratio 를 2%로, rank 로 고정.
✅ decoding phase의 새로운 tokens group에 대해 rank를 로 설정. -
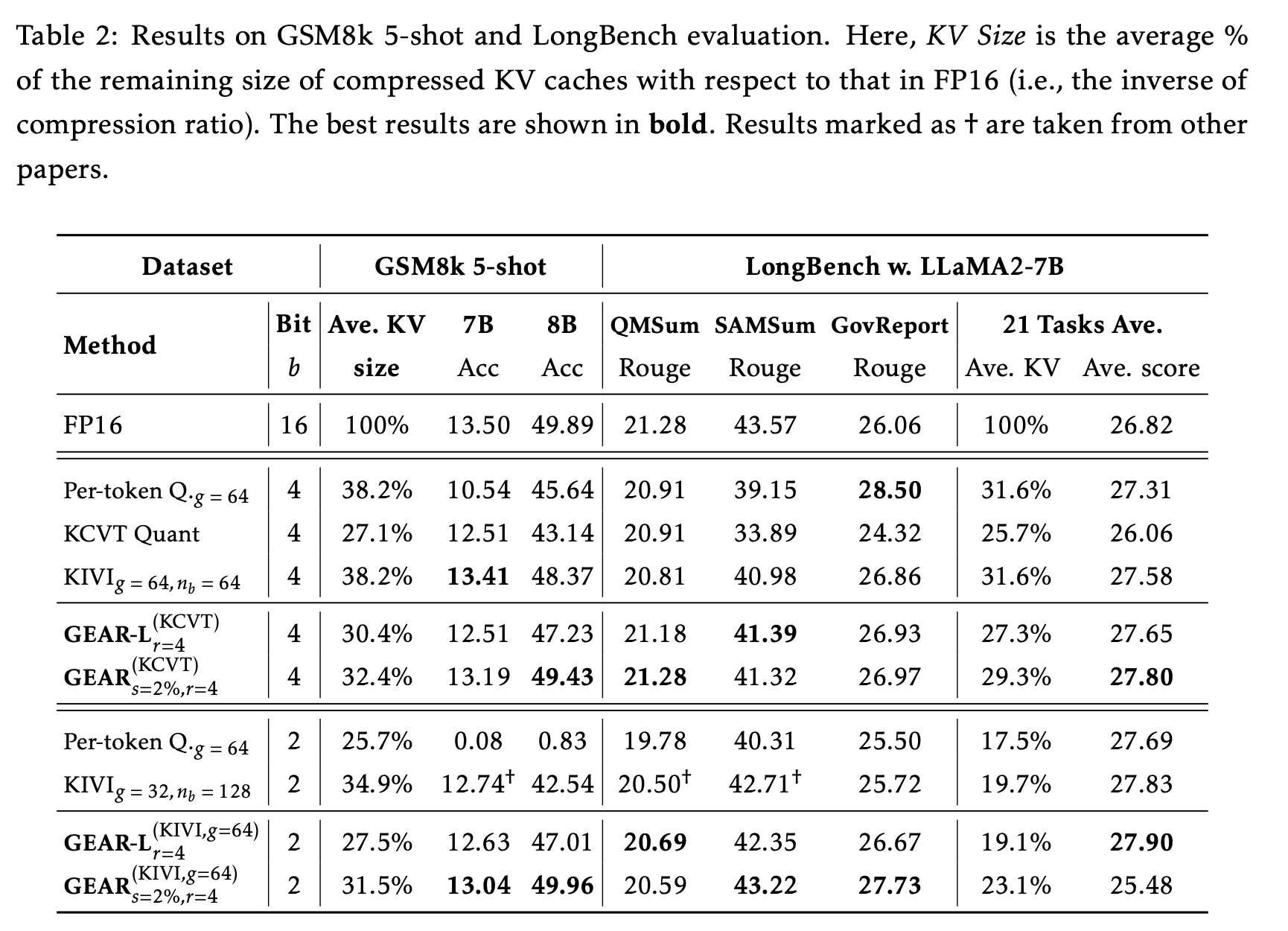
결국 KIVI 써야 되네 크크
-
KCVT quantization => 4-bit 👌🏻, 2-bit ❌
KCVT quantization이 효율적인 4-bit compression을 달성할 수 있음을 확인하였으며,
이에 따라 GEAR의 4-bit quantization backbone으로 사용함. -
KIVI 🦸🏻♂️ => 2-bit
그러나, 2-bit compression의 경우, 성능이 크게 저하되었으며,
이를 보완하기 위해 fine-grained grouping이 필요하였다.
따라서, KIVI를 2-bit quantization backbone으로 사용함.
-
-
KIVI 논문에서 제시된 바와 같이,
KIVI는 group size 및 residual length 에 민감하지 않으므로,
우리는 GEAR와 KIVI에서 group size를 64로 설정하고,
residual length를 64로 설정하여 KV size overhead를 줄임.
